目录
- 一、异常的概念及其使用
-
- [1.1 异常的概念](#1.1 异常的概念)
- [1.2 异常的抛出与捕获](#1.2 异常的抛出与捕获)
- [1.3 栈展开](#1.3 栈展开)
- [1.4 查找匹配的处理代码](#1.4 查找匹配的处理代码)
- [1.5 异常重新抛出](#1.5 异常重新抛出)
- [1.6 异常安全问题](#1.6 异常安全问题)
- [1.7 异常规范](#1.7 异常规范)
- 二、标准库的异常
个人主页:矢望
一、异常的概念及其使用
1.1 异常的概念
异常处理机制允许程序中独立开发的部分能够将在运行时就出现的问题进行通信并做出相应的处理,异常使得我们能够将问题的检测与解决问题的过程分开,程序的一部分负责检测问题的出现,然后解决问题的任务传递给程序的另一部分,检测环节无须知道问题的处理模块的所有细节。
C语言主要通过错误码的形式处理错误,错误码本质就是对错误信息进行分类编号,拿到错误码以后还要去查询错误信息,比较麻烦。在C++中异常时抛出一个对象,这个对象可以涵盖更全面的各种信息。
1.2 异常的抛出与捕获
程序出现问题时,我们通过throw抛出一个对象来引发一个异常,该对象的类型以及当前的调用链决定了应该由哪个catch的处理代码来处理该异常。
被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那一个。根据抛出对象的类型和内容,程序的抛出异常部分告知异常处理部分到底发生了什么错误。
cpp
#include <iostream>
using namespace std;
double Divide(int a, int b)
{
try
{
// 当b == 0时抛出异常
if (b == 0)
{
string s("Divide by zero condition!");
throw s; // 抛出异常
}
else
{
return a * 1.0 / b;
}
}
catch (int errid) // 捕获的类型不匹配
{
cout << "Divide(): " << errid << endl;
}
return 0;
}
void func()
{
int a, b;
cin >> a >> b;
cout << Divide(a, b) << endl;
cout << "hello world" << endl;
}
int main()
{
try
{
func();
}
catch(string& s)
{
cout << "main(): " << s << endl;
}
return 0;
}上面程序在主函数中调用了func函数,func函数中调用了Divide函数,这就是一条调用链,下面我们将模拟除0错误,看看会调用那个catch。

由于距离抛异常最近的catch捕获的类型与throw的类型不匹配所以就直接跳到匹配的catch也就是main函数中的。
当throw执行时,throw后面的语句将不再被执行。程序的执行从throw位置跳到与之匹配的catch模块,catch可能是同一函数中的一个局部的catch,也可能是调用链中另一个函数中的catch,控制权从throw位置转移到了catch位置。
这里还有两个重要的含义:1、沿着调用链的函数可能提早退出。2、一旦程序开始执行异常处理程序,沿着调用链创建的对象都将销毁。
cpp
#include <iostream>
using namespace std;
double Divide(int a, int b)
{
try
{
// 当b == 0时抛出异常
if (b == 0)
{
string s("Divide by zero condition!");
throw s; // 抛出异常
}
else
{
return a * 1.0 / b;
}
}
catch (string& errid) // 捕获的类型匹配
{
cout << "Divide(): " << errid << endl;
}
return 0;
}
void func()
{
int a, b;
cin >> a >> b;
cout << Divide(a, b) << endl;
cout << "hello world" << endl;
}
int main()
{
try
{
func();
}
catch(string& s)
{
cout << "main(): " << s << endl;
}
return 0;
}我对上次的代码进行了修改将离抛异常位置最近的catch改成了匹配的,从上次的执行结果我们可以知道,程序直接跳过了func中的剩余代码,并没有打印hello world,也就说明了当throw执行时,throw后面的语句将不再被执行。我们在来看这次的场景:
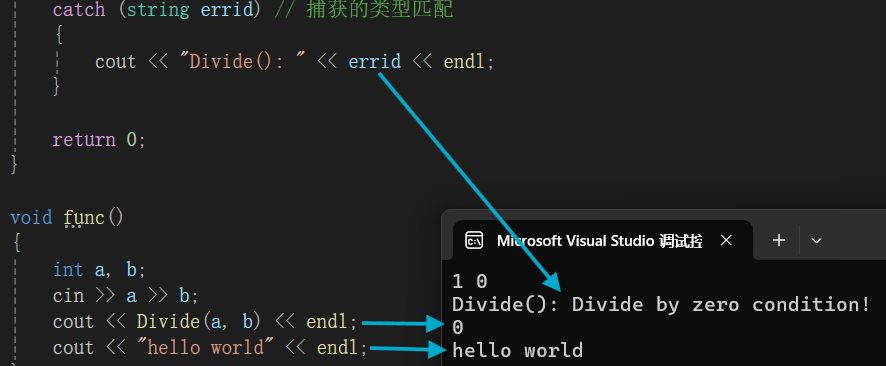
这次抛出的异常被捕获之后,后面的代码被正常执行。
注意 :抛出异常对象后,会生成一个异常对象的拷贝,因为抛出的异常对象可能是一个局部对象,所以会生成一个拷贝对象,这个拷贝的对象会在catch子句后销毁。(这里的处理类似于函数的传值返回)。当然不用担心效率问题,在现在的C++版本中,编译器会尝试移动构造等等方式,甚至编译器直接在被异常处理机制保留的内存中构造异常对象。
1.3 栈展开
这里会对1.2的内容进行更进一步的理解。
抛出异常后,程序暂停当前函数的执行,开始寻找与之匹配的catch子句,首先检查throw本身是否在try块内部,如果在则查找匹配的catch语句,如果有匹配的,则跳到catch的地方进行处理。注意 :可能抛异常的地方必须在try块的内部,如果没有在内部,即使是抛出异常也不可能被捕获。
如果当前函数中没有try/catch子句,或者有try/catch子句但是类型不匹配,则退出当前函数,继续在外层调用函数链中查找,上述查找的catch过程被称为栈展开。
如果到达main函数,依旧没有找到匹配的catch子句,程序会调用标准库的 terminate 函数终止程序。如果成功捕获异常则会继续运行后面的代码。
如果找到匹配的 catch 子句并处理异常后,程序会继续执行 catch 子句后面的代码。
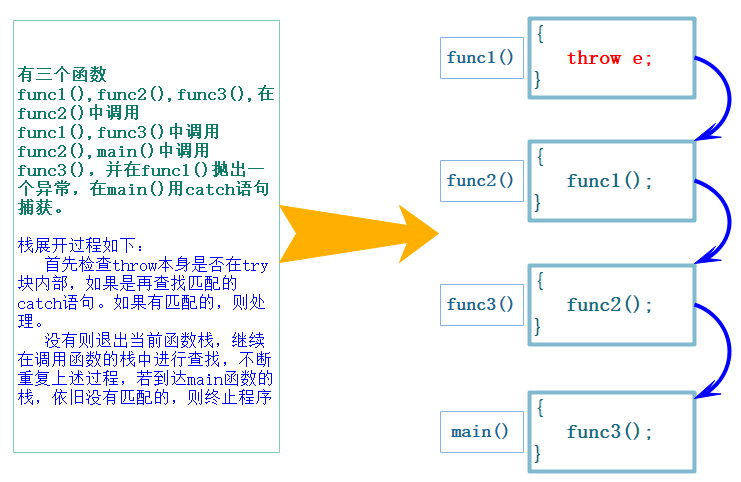
1.4 查找匹配的处理代码
一般情况下抛出对象和catch是类型完全匹配的,如果有多个类型匹配的,就选择离它位置更近的那个。
允许从非常量向常量的类型转换,也就是权限缩小,例如:抛出的异常类型是string,catch时候使用const string&接收;允许数组转换成指向数组元素类型的指针,函数被转换成指向函数的指针;允许从派生类向基类类型的转换,这个点非常实用,实际中继承体系基本都是用这个方式设计的。
以基类和派生类进行举例:
cpp
// 一般⼤型项⽬程序才会使用异常,下面我们模拟设计一个服务的几个模块
// 每个模块的继承都是Exception的派生类,每个模块可以添加自己的数据
// 最后捕获时,我们捕获基类就可以
class Exception
{
public:
Exception(const string& errmsg, int id)
:_errmsg(errmsg)
, _id(id)
{ }
virtual string what() const
{
return _errmsg;
}
int getid() const
{
return _id;
}
protected:
string _errmsg;
int _id;
};
class CacheException : public Exception
{
public:
CacheException(const string& errmsg, int id)
:Exception(errmsg, id)
{ }
virtual string what() const
{
string str = "CacheException:";
str += _errmsg;
return str;
}
};
class HttpException : public Exception
{
public:
HttpException(const string& errmsg, int id, const string& type)
:Exception(errmsg, id)
, _type(type)
{ }
virtual string what() const
{
string str = "HttpException:";
str += _type;
str += ":";
str += _errmsg;
return str;
}
private:
const string _type;
};
void CacheMgr()
{
if (rand() % 5 == 0)
{
throw CacheException("权限不足", 100);
}
else if (rand() % 6 == 0)
{
throw CacheException("数据不存在", 101);
}
else
{
cout << "CacheMgr 调用成功" << endl;
}
}
void HttpServer()
{
if (rand() % 3 == 0)
{
throw HttpException("请求资源不存在", 100, "get");
}
else if (rand() % 4 == 0)
{
throw HttpException("权限不足", 101, "post");
}
else
{
cout << "HttpServer调用成功" << endl;
}
CacheMgr();
}
int main()
{
srand(time(0));
int cnt = 3;
while (cnt)
{
cnt--;
try
{
HttpServer();
}
catch (const Exception& e) // 这⾥捕获基类,基类对象和派⽣类对象都可以被捕获
{
cout << e.what() << endl; // 多态
}
cout << endl;
}
return 0;
}上面的程序中基类是Exception,子类:CacheException、HttpException,进行模拟了一个服务的几个模块,在子类模块中可以添加自己的异常数据,到时候捕获的时候,用基类去接收抛出的异常就行。
其中使用了随机数来模拟每个模块可能会出现的异常。
运行 :
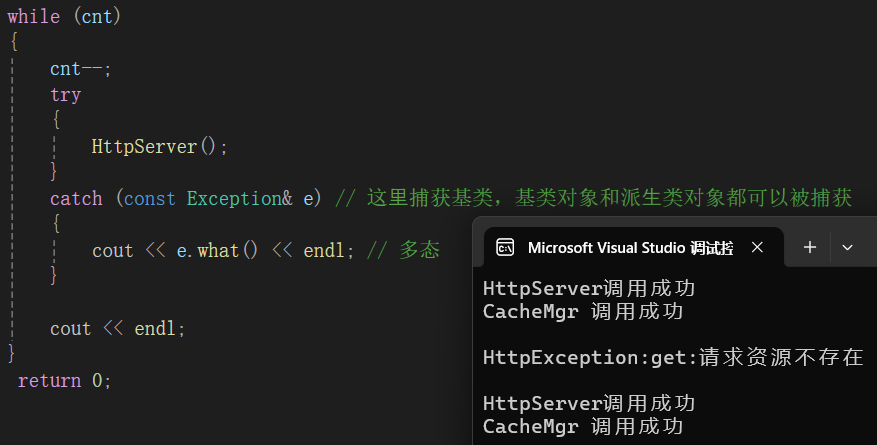
这就很实用。
但是这个程序不够好,有终止程序的风险,如果负责一个模块的小组忘记继承基类了,那么当他们小组负责的模块抛出异常的时候,catch是不匹配的,这就会导致程序的终止。
下面我们假设HttpException这个类没有继承基类:
cpp
class HttpException
{
public:
HttpException(const string& errmsg, int id, const string& type)
//:Exception(errmsg, id)
: _type(type)
{ }
virtual string what() const
{
string str = "HttpException:";
str += _type;
str += ":";
//str += _errmsg;
return str;
}
private:
const string _type;
};运行 :
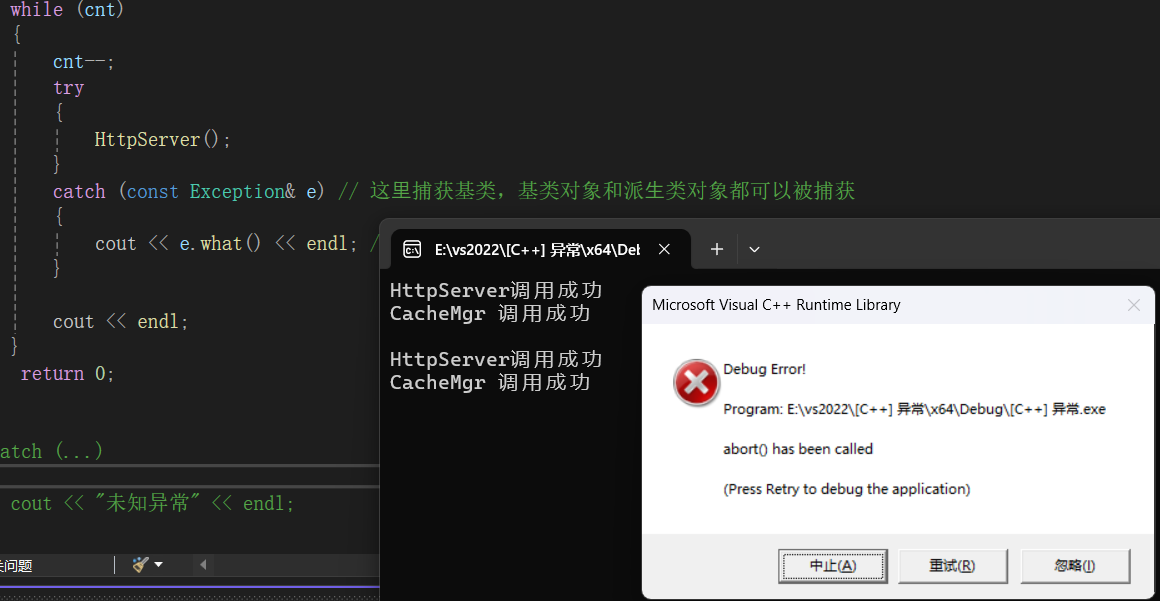
直接就导致程序终止了,如果造成了事故这是很可怕的。所以一定要把所有抛出的异常全部捕获。
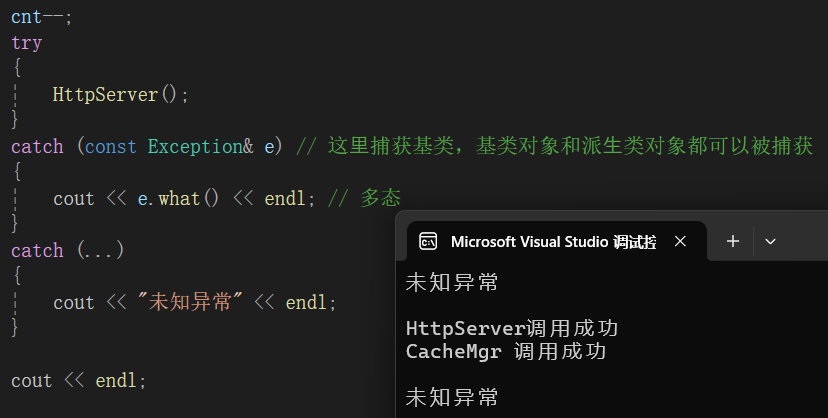
如果到main函数,异常仍旧没有被匹配就会终止程序,不是发生严重错误的情况下,我们是不期望程序终止,所以一般main函数中最后都会使用catch(...),它可以捕获任意类型的异常,但是是不知道异常错误是什么。
cpp
while (cnt)
{
cnt--;
try
{
HttpServer();
}
catch (const Exception& e) // 这⾥捕获基类,基类对象和派⽣类对象都可以被捕获
{
cout << e.what() << endl; // 多态
}
catch (...)
{
cout << "未知异常" << endl;
}
cout << endl;
}再次运行 :
1.5 异常重新抛出
有时catch到一个异常对象后,需要对错误进行分类,比如按照错误码分类。不同的异常需要不同的处理策略,其中的某种异常错误需要进行特殊的处理,其他错误则重新抛出异常给外层调用链处理。捕获异常后需要重新抛出,直接 throw 就可以把捕获的对象直接抛出。
也就是说不推荐直接捕获所有异常,直接捕获所有异常会丧失错误处理的精确性,应该根据具体业务需求设计精细的异常处理策略。比如在游戏场景下,出现网络错误,这时候可以重新尝试连接,如果网络错误异常被直接捕获而不尝试重新连接,这会导致很糟糕的用户体验,如游戏卡死、状态不同步,玩家数据丢失等。
下面程序模拟展示了聊天时发送消息时,网络错误异常等处理场景:
cpp
#include <iostream>
using namespace std;
class Exception
{
public:
Exception(const string& errmsg, int id)
:_errmsg(errmsg)
, _id(id)
{ }
virtual string what() const
{
return _errmsg;
}
int getid() const
{
return _id;
}
protected:
string _errmsg;
int _id;
};
class HttpException : public Exception
{
public:
HttpException(const string& errmsg, int id, const string& type)
:Exception(errmsg, id)
, _type(type)
{ }
virtual string what() const
{
string str = "HttpException:";
str += _type;
str += ":";
str += _errmsg;
return str;
}
private:
const string _type;
};
void _SeedMsg(const string& s)
{
if (rand() % 2 == 0)
{
throw HttpException("网络不稳定,发送失败", 102, "put");
}
else if (rand() % 7 == 0)
{
throw HttpException("你已不是对方的好友,发送失败", 103, "put");
}
else
{
cout << "发送成功" << endl;
}
}
void SendMsg(const string& s)
{
// 发送消息失败,则再重试3次
for (size_t i = 0; i < 4; i++)
{
try
{
_SeedMsg(s); // 出现 102 号错误,尝试重连
break;
}
catch (const Exception& e)
{
// 捕获异常,if中是102
// 捕获异常,else中不是102号错误,则将异常重新抛出
if (e.getid() == 102) // 判断错误码是不是 102
{
// 重试三次以后否失败了,则说明网络太差了,重新抛出异常
if (i == 3) throw; // 捕获到什么异常就抛出什么
cout << "开始第" << i + 1 << "重试" << endl;
}
else
{
throw;
}
}
}
}
int main()
{
srand(time(0));
string str = "中!";
int cnt = 5;
while (cnt)
{
cnt--;
try
{
SendMsg(str);
}
catch (const Exception& e)
{
cout << e.what() << endl;
}
catch (...)
{
cout << "未知异常" << endl;
}
cout << endl;
}
return 0;
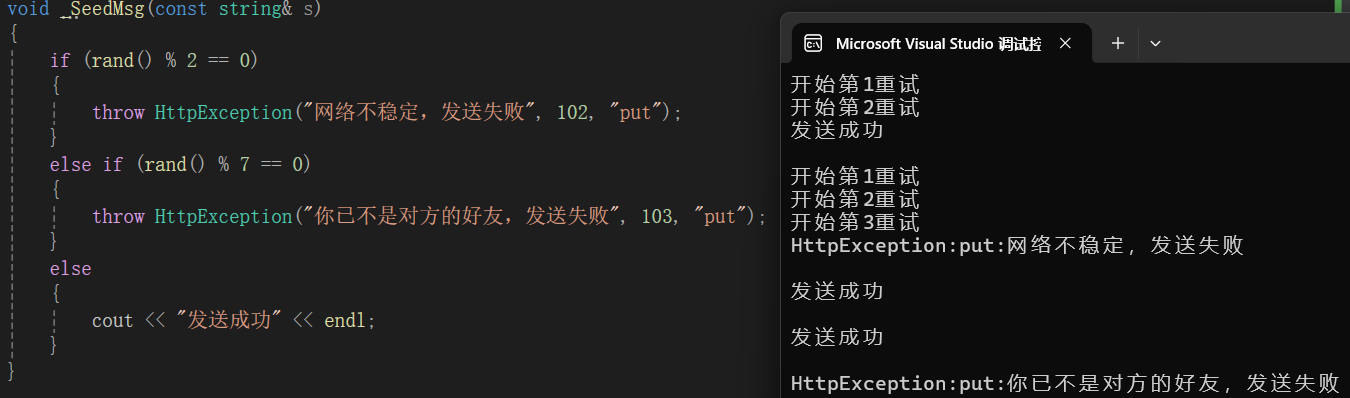
}上面程序中复用了之前展示的两个类,并且模拟发送消息的场景:
1.6 异常安全问题
异常抛出后,后面的代码就不再执行,前面申请了资源(内存、锁等),后面进行释放,但是中间可能会抛异常就会导致资源没有释放,这里由于异常就引发了资源泄漏,产生了安全性问题。所以中间我们需要捕获异常,释放资源,后面再重新抛出,当然下期智能指针博客的RAII方式解决这种问题是更好的。
其次析构函数中,如果抛出异常也要谨慎处理,比如析构函数要释放十个资源,释放到第五个时抛出异常,则也需要捕获处理,否则后面的五个资源就泄漏了。《Effctive C++》第8个条款也专门讲了这个问题,别让异常逃离析构函数。
cpp
double Divide(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
{
string s("Divide by zero condition!");
throw s; // 抛出异常
}
return a * 1.0 / b;
}
void func()
{
int* arr = new int[10];
int a, b;
cin >> a >> b;
cout << Divide(a, b) << endl;
cout << "delete[] arr" << endl;
delete[] arr;
}
int main()
{
try
{
func();
}
catch (string& s)
{
cout << "main(): " << s << endl;
}
return 0;
}这段程序没有发生除0错误时,资源正常释放:

发生除0错误时:
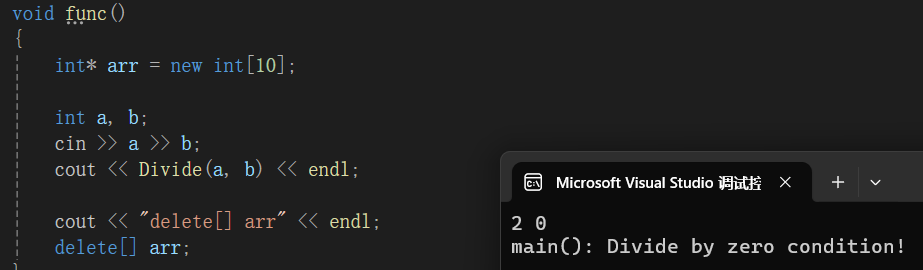
由于异常引发了内存泄漏,解决方案:
cpp
void func()
{
int* arr = new int[10];
try
{
int a, b;
cin >> a >> b;
cout << Divide(a, b) << endl;
}
catch (...)
{
// 捕获所有异常,释放内存
cout << "delete[] arr" << endl;
delete[] arr;
throw; // 将异常抛给上一个调用处理
}
cout << "delete[] arr" << endl;
delete[] arr;
}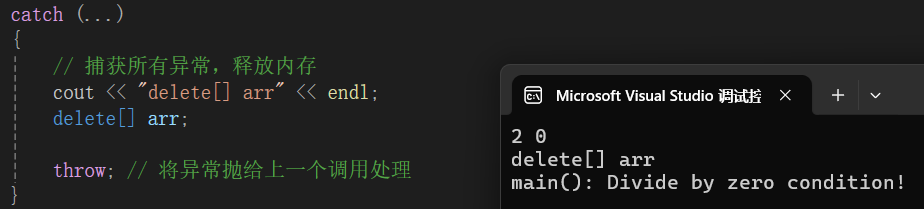
这个函数中,捕获异常后并不处理异常,异常还是交给外层处理,将申请的内存释放掉。
1.7 异常规范
对于用户和编译器,预先知道某个程序会不会抛出异常大有裨益,知道某个函数是否会抛出异常有助于简化调用函数的代码。
在C++98中,函数参数列表的后面接throw(),表示函数不抛异常,函数参数列表的后面接throw(类型1,类型2...)表示可能会抛出多种类型的异常,可能会抛出的类型用逗号分割。C++98的这种方式过于复杂,实践中并不好用。
在C++11中,它进行了简化,函数参数列表后面加noexcept表示不会抛出异常,啥都不加表示可能会抛出异常。
编译器并不会在编译时检查noexcept,如果一个函数用noexcept修饰了,但可能会抛出异常,编译器还是会顺利编译通过的(有些编译器可能会报出警告)。但一个声明了noexcept的函数抛出了异常,程序会调用 terminate 终止程序。
例如给之前的Divide函数加noexcept:
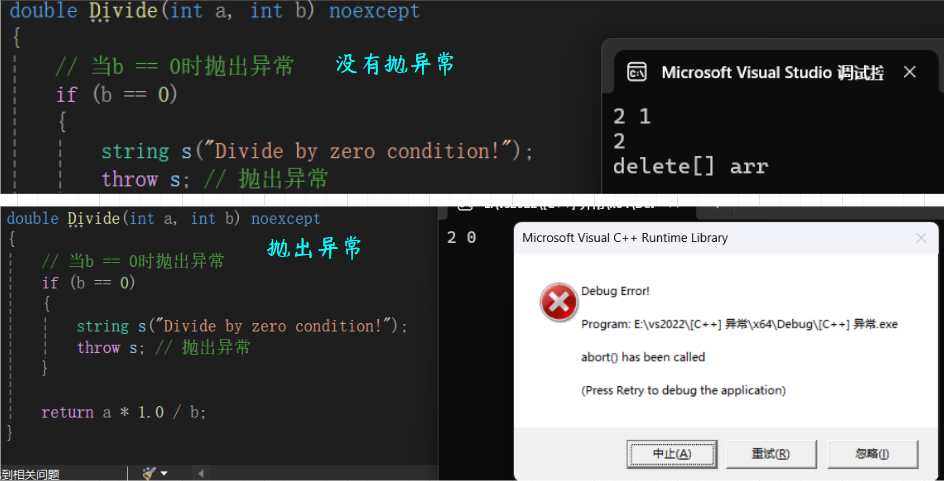
最佳实践 : 当你能保证函数不会抛出异常时,就加上 noexcept。这既是性能优化,也是更好的接口文档。
STL库中不会抛异常的会明确标出noexcept,可能抛异常的不会在后面加noexcept。
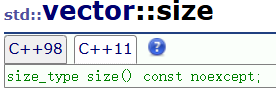
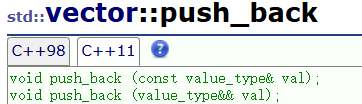
noexcept(expression)还可以作为一个运算符去检测一个表达式是否会抛出异常,可能会则返回false,不会就返回true。
cpp
vector<int> v;
cout << noexcept(v.size()) << endl;
cout << noexcept(v.push_back(1)) << endl;
注意:它并没有真的去执行括号中的语句,只是去检测。
二、标准库的异常
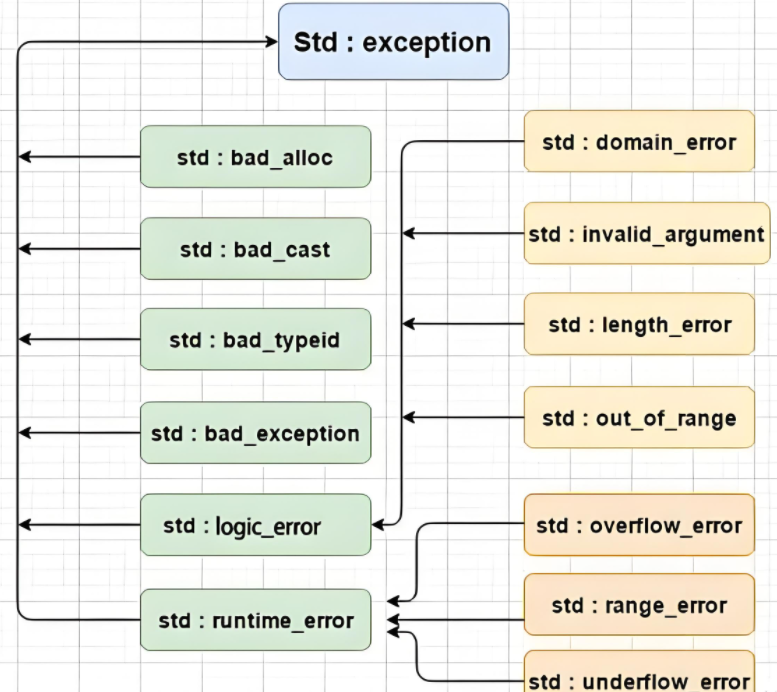
链接:std::exception。
C++标准库也定义了一套自己的一套异常继承体系库,基类是exception,所以我们日常写程序,只需要在主函数捕获exception即可,要获取异常信息,调用what函数,what是一个虚函数,派生类可以重写。
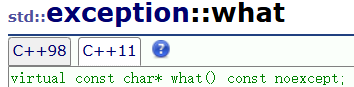
C++11中基类exception的声明:
cpp
class exception {
public:
exception () noexcept;
exception (const exception&) noexcept;
exception& operator= (const exception&) noexcept;
virtual ~exception();
virtual const char* what() const noexcept;
}
总结:
以上就是本期博客分享的全部内容啦!如果觉得文章还不错的话可以三连支持一下,你的支持就是我前进最大的动力!
技术的探索永无止境! 道阻且长,行则将至!后续我会给大家带来更多优质博客内容,欢迎关注我的CSDN账号,我们一同成长!
(~ ̄▽ ̄)~