
笔记整理:张艺汶,研究方向为大语言模型、AI for Science
论文链接:https://aclanthology.org/2025.findings-acl.1077/
发表会议:ACL 2025
1. 动机
时序知识图谱以(主体、关系、客体、时间戳)形式存储事实,可用于预测未来事实,在金融、医疗、政治等时间敏感场景中具有重要价值。然而,现有方法存在显著缺陷:
-
传统方法(如基于图神经网络、循环神经网络的模型)聚焦于适配单个 TKG,忽视跨场景泛化能力;
-
近期基于大语言模型(LLMs)的方法虽提升了泛化性,但需同时学习 TKG 中两类纠缠的知识 ------通用模式 (不同场景共享的不变时序结构)与场景信息(特定场景的实体、关系等事实知识),导致学习过程相互干扰,限制了泛化性能。
为解决上述问题,本文提出通用到特定(General-to-Specific, G2S)学习框架,通过解耦两类知识的学习过程,增强 LLMs 在 TKG 预测任务中的泛化能力。
2. 贡献
本文的主要贡献有:
-
知识解耦识别:明确 TKG 中通用模式与场景信息的纠缠特性,并提出多种匿名化策略,实现两类知识的有效解耦;
-
框架创新:设计两阶段 G2S 框架,通用学习阶段专注于跨 TKG 通用模式的学习,特定学习阶段注入场景信息,避免两类知识学习的相互干扰,提升泛化能力;
-
实验验证:在标准、零样本、低资源三种设置下开展广泛实验,验证了 G2S 框架的有效性,为 TKG 预测的泛化性研究提供了可靠范式。
3. 方法
G2S 框架核心是通过两阶段学习解耦通用模式与场景信息。
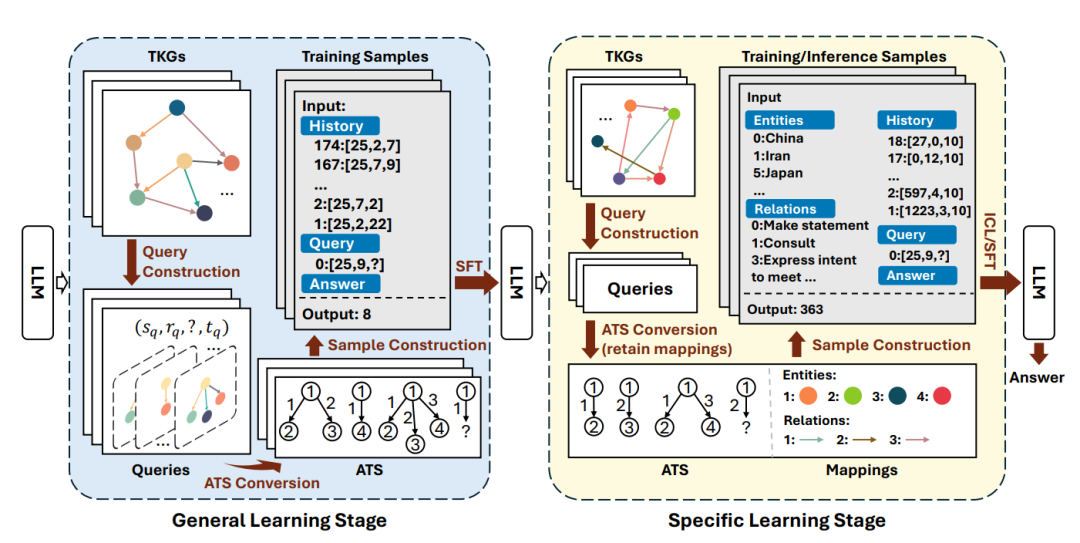
通用学习阶段
目标:屏蔽场景信息,让模型学习跨 TKG 的通用时序模式,包含三步关键操作:
-
查询构建:对每个 TKG 事实(s, r, o, t)构造两类查询 ------ 预测客体(s, r, ?, t)和预测主语(?, r, o, t);选取与查询相关的单跳历史事实,按时间戳升序排序后保留最新 L 个事实(本文 L=50);
-
匿名时序结构转换:将实体、关系、时间戳转换为抽象 ID,消除场景特异性。
-
时间戳 ID:设为查询时间与历史事实时间的间隔(A (t) = t_q - t),避免训练与测试时间周期差异导致的偏差;
-
实体 / 关系 ID:提供三种策略 ------ 频率 ID(FID,按频率排序)、全局 ID(GID,数据集原始 ID)、随机 ID(RID,随机分配);
-
样本构建:输入格式为 "历史事实 + 查询",历史事实按 "A (t):A (s), A (r), A (o)" 组织,查询按 "0:A (s), A (r), ?" 组织,输出为正确答案的匿名 ID;若答案实体未出现在历史事实中,输出 "None"。
特定学习阶段
目标:注入场景信息,适配具体 TKG,与通用学习阶段的核心差异在于:
-
场景信息映射:保留实体 / 关系与匿名 ID 的映射关系,在输入开头添加 "实体映射"(A (e): e)和 "关系映射"(A (r): r)模块;
-
双学习模式:支持两种适配模式 ------ 上下文学习(ICL,不使用训练样本,仅通过输入映射学习场景信息)、监督微调(SFT,利用训练样本更新模型参数)。
训练与推理细节
-
训练目标:最小化生成 token 序列与真实序列的交叉熵损失(L = CE (O, Ō));
-
骨干模型与优化:采用 LLaMA3-8B 作为基础模型,结合低秩适配(LoRA)技术实现高效微调;
-
推理策略:单步生成,以 LLM 输出 token 的生成概率作为排序分数(score (o) = Pr (o | Input)),过滤重复预测后保留 Top-10 结果。
4. 实验
4.1 实验设置
-
数据集:使用 5 个主流 TKG 数据集(表 7,文档 1-211),其中 GDELT 和 WIKI 用于通用学习阶段训练,ICEWS14、ICEWS18、YAGO 用于特定学习阶段与评估
-
基线模型:分为两类 ------ 传统方法(RE-GCN、xERTE、TANGO 等)、LLM-based 方法(GPT-NeoX-ICL、Llama2-ICL、Llama3-ICL、GenTKG)
-
评估指标:采用 H@1/3/10(正确答案位于 Top-1/3/10 的查询比例),采用时间感知过滤设置(移除预测中除正确答案外的无效实体)
-
实验场景:
-
-
标准设置:特定学习阶段使用全量训练数据;
-
零样本设置:特定学习阶段不使用训练数据;
-
低资源设置:特定学习阶段使用 5%/20%/50% 的训练数据。
-
4.2 核心结果
-
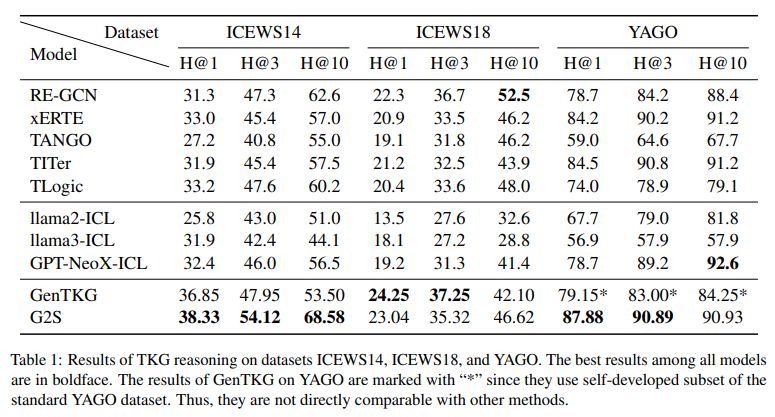
标准设置:G2S 在 ICEWS14(H@1=38.33%)和 YAGO(H@1=87.88%)上表现最优,在 ICEWS18(H@1=23.04%)上排名第二;G2S 与 GenTKG(SFT 类方法)整体优于 ICL 类方法,证明充足数据下 SFT 更易适配 TKG。
-
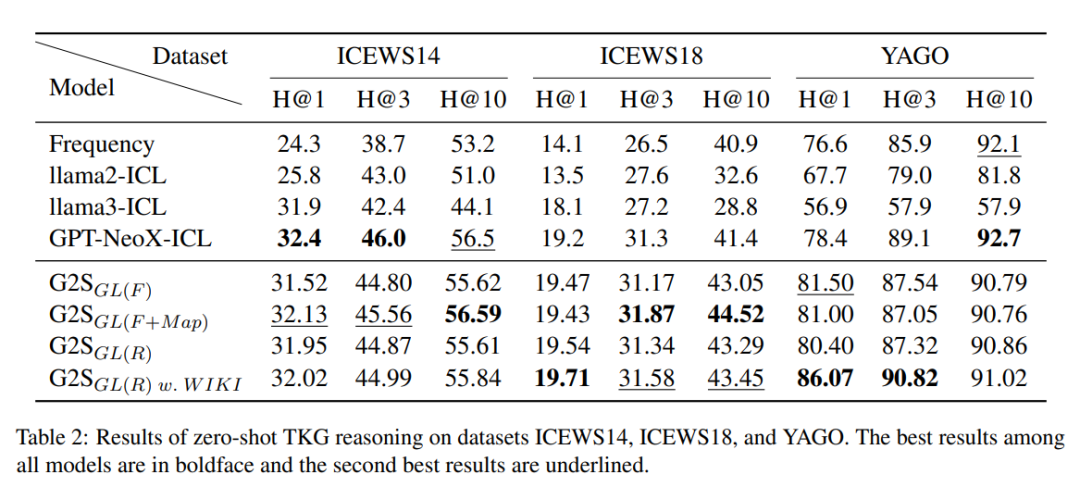
零样本设置: G2S(融合 GDELT 和 WIKI,RID 策略)与更大规模的 GPT-NeoX-20B 性能相当,在 YAGO 上表现更优(H@1=86.07%);FID 与 RID 策略性能接近,且均优于额外引入场景信息的 G2S_GL (F+Map),验证知识解耦的必要性。
-
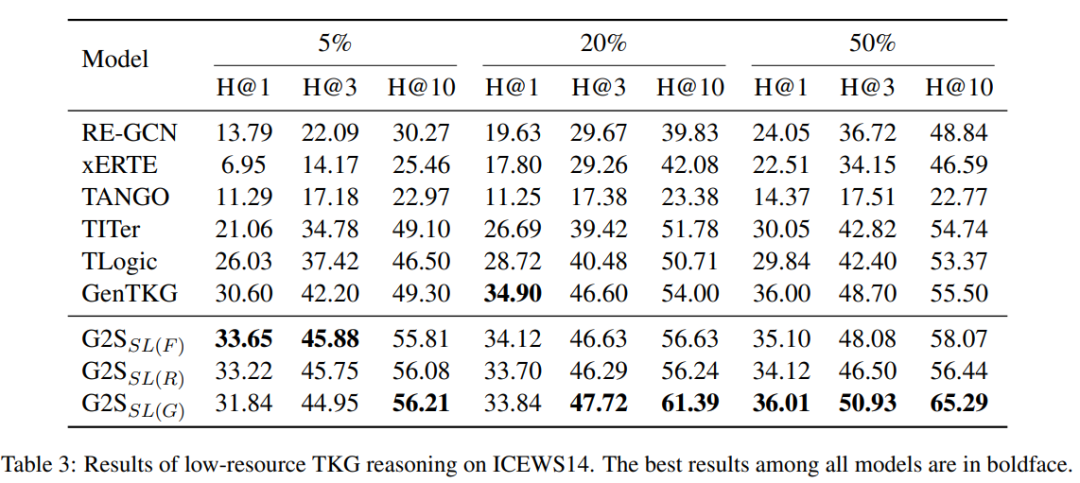
低资源设置:仅使用 5% 训练样本时,G2S 的三种变体(SL (F)/SL (R)/SL (G))均优于基线模型;随着训练样本增加,GID 策略逐渐超越 FID 和 RID,证明 GID 需更多数据学习实体 / 关系的静态映射。
-
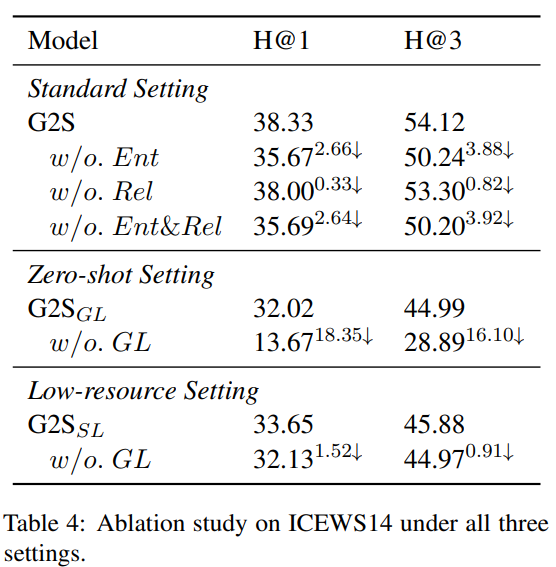
超参数分析: 移除实体映射(w/o. Ent)或关系映射(w/o. Rel)会导致性能下降,其中实体映射对性能影响更大;移除通用学习阶段(w/o. GL)后,零样本场景下 H@1 下降 18.35%,低资源场景下 H@1 下降 1.52%,验证两阶段框架的有效性。
5. 总结
本文提出的 G2S 框架通过两阶段学习解耦了 TKG 中通用模式与场景信息的学习过程:通用学习阶段通过匿名化策略让模型捕捉跨场景的通用时序模式,特定学习阶段通过映射注入场景信息适配具体任务。实验表明,G2S 在标准、零样本、低资源三种设置下均优于基线模型,有效提升了 LLMs 在 TKG 预测任务中的泛化能力。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文 ,进入 OpenKG 网站。