目录
[1. 快速入门(5分钟速览)](#1. 快速入门(5分钟速览)⚡ 推荐先看)⚡ 推荐先看
[2. 问题分析:默认关联的性能陷阱](#2. 问题分析:默认关联的性能陷阱)
[3. 关联子查询与去关联原理](#3. 关联子查询与去关联原理)
[4. 优化案例:使用 NO_DECORRELATE 去关联](#4. 优化案例:使用 NO_DECORRELATE 去关联)
[5. Apply 操作符的风险点](#5. Apply 操作符的风险点)
[6. 优化决策:何时该去关联,何时不该去关联](#6. 优化决策:何时该去关联,何时不该去关联)
[7. 最佳实践与总结](#7. 最佳实践与总结)
1. 快速入门(5分钟速览)
🎯 核心问题
您的查询是否遇到以下情况?
-
✅ 使用了
NOT EXISTS或EXISTS子查询 -
✅ 外部查询结果集很小(< 100 行)
-
✅ 子查询表较大(> 10万行)
-
✅ 查询执行时间不理想
如果是,继续阅读!本案例可能帮您优化数倍性能。
⚡ 快速解决方案
只需在子查询中添加一个 Hint:
sql
-- 优化前(慢)
SELECT
au.*
FROM
app_user au
WHERE
NOT EXISTS (SELECT 1 FROM operation_account_record oar WHERE oar.is_sop = 1 AND au.id = oar.user_id)
AND au.last_online_time BETWEEN '2025-11-05 00:00:00'
AND '2025-11-05 23:59:59'
ORDER BY
au.last_online_time DESC, au.id desc
LIMIT 10;
-- 优化后(快)
SELECT
au.*
FROM
app_user au
WHERE
NOT EXISTS (SELECT /*+ NO_DECORRELATE() */ 1 FROM operation_account_record oar WHERE oar.is_sop = 1 AND au.id = oar.user_id)
AND au.last_online_time BETWEEN '2025-11-05 00:00:00'
AND '2025-11-05 23:59:59'
ORDER BY
au.last_online_time DESC, au.id desc
LIMIT 10;📊 真实优化效果
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 执行时间 | 67.1ms | 15.6ms | 4.3倍 ⬆️ |
| 扫描行数 | 136,851 | 26 | 5,263倍 ⬇️ |
| 内存占用 | 11.8 MB | 760 Bytes | 16,280倍 ⬇️ |
⚠️ 使用前提
在使用 NO_DECORRELATE 之前,请确认:
-
外部查询结果集确实很小(建议 < 100 行)
-
子查询表确实很大(> 10万行)
-
子查询有高效的索引支持
-
使用
EXPLAIN ANALYZE验证过效果
1. 实战案例背景
1.1 业务场景
在用户活跃度分析系统中,需要查询特定时间段内活跃的用户信息,同时需要排除运营账号
1.2 表结构说明
sql
-- 用户表(主表)
CREATE TABLE `app_user` (
`id` BIGINT NOT NULL,
`user_name` VARCHAR (64) DEFAULT NULL,
`last_online_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
INDEX `idx_last_online_time` (`last_online_time`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin;
-- 运营账户记录表(子查询表,数据量大)
CREATE TABLE `operation_account_record` (
`id` BIGINT NOT NULL,
`user_id` BIGINT NOT NULL,
`is_sop` TINYINT NOT NULL,
`gmt_create` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
KEY `idx_user` (`user_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin;1.3 数据规模
| 表名 | 数据量 | 说明 |
|---|---|---|
| app_user | 15万 | 用户主表 |
| operation_account_record | 13.6万 | 运营账户记录表 |
| 符合时间条件的 app_user | 约100条 | 单日活跃用户少(并且有limit限制) |
1.4 原始 SQL 语句
sql
SELECT
au.*
FROM
app_user au
WHERE
NOT EXISTS (SELECT 1 FROM operation_account_record oar WHERE oar.is_sop = 1 AND au.id = oar.user_id)
AND au.last_online_time BETWEEN '2025-11-05 00:00:00'
AND '2025-11-05 23:59:59'
ORDER BY
au.last_online_time DESC, au.id desc
LIMIT 10;查询意图:
-
查询 2025-11-05 当天活跃的用户
-
排除非运营账号用户(通过 NOT EXISTS)
-
按最后在线时间倒序排列
-
只取前 10 条记录
2. 问题分析:默认关联的性能陷阱
2.1 TiDB 优化器的自动关联
TiDB 优化器默认会尝试为关联子查询 用 Semi Join 作为默认的执行方式,将 NOT EXISTS 转换为 Anti Semi Join 或 Anti Left Outer Semi Join 的形式。
2.2 关联后的执行逻辑
TiDB 自动关联后,执行逻辑变为:
sql
-- 优化器内部转换的等价逻辑(简化表示)
SELECT
au.*
FROM
app_user au
LEFT JOIN (SELECT user_id FROM operation_account_record WHERE is_sop = 1) oar ON au.id = oar.user_id
WHERE
oar.user_id IS NULL
AND au.last_online_time BETWEEN '2025-11-05 00:00:00'
AND '2025-11-05 23:59:59'
ORDER BY
au.last_online_time DESC,
au.id
LIMIT 10;2.3 性能问题根源
❌ 问题 1:全表扫描构建哈希表
执行计划显示:
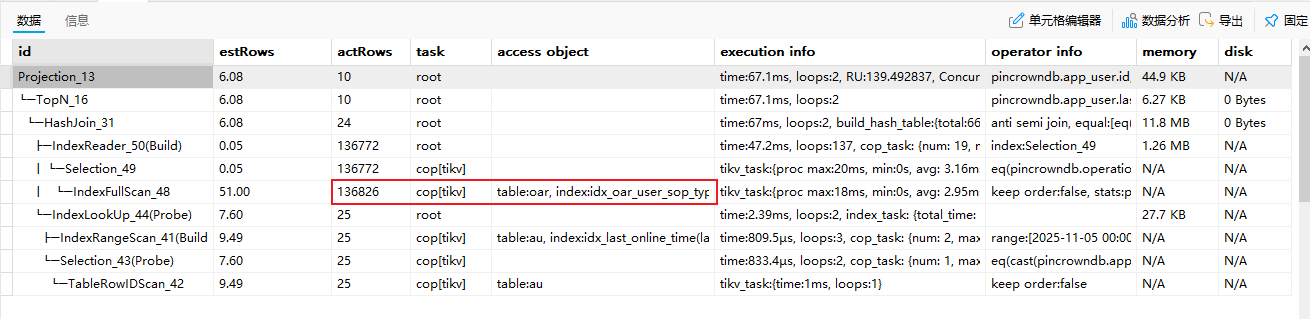
关键问题:
-
operation_account_record表被索引全扫描(IndexFullScan),扫描 13.6 万行数据 -
构建哈希表用于 HashJoin,即使外部查询只需要 10 行数据
-
子查询表远大于主表,去关联导致大量无效计算
❌ 问题 2:资源消耗分析
| 资源类型 | 消耗情况 | 说明 |
|---|---|---|
| 执行时间 | 67.1毫秒 | 扫描 13.6 万行数据 |
| CPU | 高负载 | 全表扫描 + 哈希表构建 |
| 内存 | 约 11.8MB | 存储 13.6万行的 operation_account_record 结果 |
| 磁盘 I/O | 大量读取 | 全索引表扫描产生大量 I/O |
❌ 问题 3:数据倾斜加剧问题
-- 查看数据分布
SELECT is_sop, COUNT(*)
FROM operation_account_record
GROUP BY is_sop;
+--------+-----------+
| is_sop | COUNT(*) |
+--------+-----------+
| 0 | 54 | -- 4%
| 1 | 136773 | -- 96%
+--------+-----------+is_sop = 1 占 96%,需扫描整个表来过滤数据。
2.4 根本原因总结
核心矛盾:
外部查询结果集很小(10 行)
子查询表数据量较大(13.6 万行)
关联强制子查询先执行,导致处理了 99.99% 的无用数据
3. 关联子查询与去关联原理
3.1 什么是关联子查询
关联子查询(Correlated Subquery):子查询中引用了外部查询的列,导致子查询必须对外部查询的每一行执行一次。
示例:关联子查询
SELECT
*
FROM
t1
WHERE
t1.a < (SELECT sum(t2.a) FROM t2 WHERE t2.b = t1.b) -- ⬅️ 引用外部查询 t1表 的 b列执行特点:
-
子查询引用外部的 t1
.b -
外部查询每扫描一行,子查询执行一次
-
执行次数 = 外部查询行数
3.2 什么是关联子查询优化
在TiDB中子查询默认会以 Semi Join(关联查询)中提到的 Semi Join 作为默认的执行方式,同时对于一些特殊的子查询,TiDB 会做一些逻辑上的替换使得查询可以获得更好的执行性能。
原始 SQL:
EXPLAIN SELECT
*
FROM
t1
WHERE
id IN (SELECT t1_id FROM t2 WHERE t1_id != t1.int_col);
执行特点:
- TiDB 之所以要进行这样的改写,是因为关联子查询每次子查询执行时都是要和它的外部查询结果绑定的。在上面的例子中,如果 t1.a 有一千万个值,那这个子查询就要被重复执行一千万次,因为 t2.b=t1.b 这个条件会随着 t1.a 值的不同而发生变化。当通过一些手段将关联依赖解除后,这个子查询就只需要被执行一次了。
3.3 什么是去关联
去关联( NO_DECORRELATE):3.2 中改写的弊端在于,在关联没有被解除时,优化器是可以使用关联列上的索引的。也就是说,虽然这个子查询可能被重复执行多次,但是每次都可以使用索引过滤数据。而解除关联的变换上,通常是会导致关联列的位置发生改变而导致虽然子查询只被执行了一次,但是单次执行的时间会比没有解除关联时的单次执行时间长。
样例 SQL:
sql
SELECT
au.*
FROM
app_user au
WHERE
NOT EXISTS (SELECT /*+ NO_DECORRELATE() */ 1 FROM operation_account_record oar WHERE oar.is_sop = 1 AND au.id = oar.user_id)
AND au.last_online_time BETWEEN '2025-11-05 00:00:00'
AND '2025-11-05 23:59:59'
ORDER BY
au.last_online_time DESC, au.id desc
LIMIT 10;3.4 去关联与关联对比
假设数据规模:
-
table_a:100 行 -
table_b:100 万行
Semi Join优化:
执行次数:100行数据匹配 + 1次子查询100W数据
总成本:100行 + (扫描100万行) = 101次操作(其中一次性能耗费严重)去关联后:
子查询执行:100次
总成本:100行 + (100次索引查找) = 200次操作3.5 关键对比总结
| 对比维度 | 去关联(Apply) | 不去关联(Semi Join) |
|---|---|---|
| 子查询执行次数 | N 次(外部查询行数) | 1 次 |
| 适用场景 | 外部查询行数少 | 外部查询行数多 |
| 索引利用 | 每次都能用索引 | 可能无法用索引 |
| 内存消耗 | 低 | 高(构建哈希表) |
| CPU 消耗 | 低到中 | 高(全表扫描) |
| 本案例性能 | 15.6ms ✅ | 67.1ms ❌ |
4. 优化案例:使用 NO_DECORRELATE 去关联
4.1 优化后的 SQL
sql
SELECT
au.*
FROM
app_user au
WHERE
NOT EXISTS (SELECT /*+ NO_DECORRELATE() */ 1 FROM operation_account_record oar WHERE oar.is_sop = 1 AND au.id = oar.user_id)
AND au.last_online_time BETWEEN '2025-11-05 00:00:00'
AND '2025-11-05 23:59:59'
ORDER BY
au.last_online_time DESC, au.id desc
LIMIT 10;4.2 NO_DECORRELATE Hint 说明
语法:
SELECT /*+ NO_DECORRELATE() */ ...作用:
-
告诉 TiDB 优化器不要进行去关联子查询优化
-
保持原始的关联子查询形式
-
使用
Apply操作符执行子查询
4.3 优化后的执行计划
关键改进:
-
✅ 使用 Apply 操作符:子查询对每行外部数据执行一次
-
✅ 利用索引 idx_user :快速查找
(user_id)数据 -
✅ 执行次数可控:只执行 10 次(外部查询行数)
-
✅ 内存占用低:无需构建大哈希表
4.4 性能对比(真实数据)
| 指标 | 优化前(Semi Join) | 优化后(NO_DECORRELATE) | 提升 |
|---|---|---|---|
| 执行时间 | 67.1ms | 15.6ms | 4.3 倍 ⬆️ |
| 实际扫描行数 (actRows) | 136,827 + 10 | 10 + 10 | 6,841 倍 ⬇️ |
| 关键操作符 | HashJoin | Apply | Apply 更优 |
| Build 阶段耗时 | 51ms (IndexFullScan) | - | 无需构建 |
| 内存占用 | 11.8 MB (哈希表) | 760 Bytes | 15,000 倍 ⬇️ |
| 子查询执行方式 | 全表扫描一次 | 索引查找 10 次 | 索引更优 |
4.5 ⚠️ 重要提示:能用但请慎用
为什么说"慎用"?
虽然本案例中 NO_DECORRELATE 带来了巨大的性能提升,但需要注意:
-
数据规模变化风险
-
如果未来单日活跃用户从 100 增长到 10万,性能会反转
-
Apply 操作符执行次数 = 外部查询行数
-
-
索引依赖风险
-
如果
idx_user索引被删除或失效,性能会急剧下降 -
子查询将退化为全表扫描
-
-
查询条件变化风险
-
如果去掉时间条件,外部查询可能返回 50 万行
-
Apply 需要执行 50 万次子查询
-
使用前的检查清单:
- 外部查询结果集是否确实很小(< 1000 行)
- 子查询表数据量是否确实很大(> 100万行)
- 子查询是否有高效的索引支持
- 业务场景是否相对稳定(数据规模不会突变)
5. Apply 操作符的风险点
5.1 什么是 Apply 操作符
Apply 是一种嵌套循环连接(Nested Loop Join)的执行方式:
FOR each row in outer_table (驱动表):
执行子查询,使用 outer_row.column 作为参数
IF 子查询满足条件:
返回 outer_row特点:
-
子查询执行次数 = 驱动表行数
-
每次子查询可以使用外部行的值
-
可以充分利用子查询表的索引
5.2 Apply 的风险场景
⚠️ 风险 1:驱动表行数过多
问题案例:
-- ❌ 危险:外部查询返回 50 万行
SELECT /*+ NO_DECORRELATE() */ au.*
FROM app_user au
WHERE NOT EXISTS (
SELECT 1 FROM operation_account_record oar
WHERE oar.is_sop = 1 AND au.id = oar.user_id
)
-- 没有时间过滤条件!
LIMIT 100;结论: 驱动表行数 过大 时,Apply 性能急剧下降。
⚠️ 风险 2:子查询缺少索引
问题案例:
-- ❌ 危险:子查询表没有合适的索引
SELECT au.*
FROM app_user au
WHERE au.last_online_time BETWEEN '2025-11-05 00:00:00' AND '2025-11-05 23:59:59'
AND NOT EXISTS (
SELECT /*+ NO_DECORRELATE() */ 1
FROM operation_account_record oar
WHERE oar.user_email = au.email -- ⚠️ user_email 没有索引
AND oar.is_sop = 1
);结论: 子查询必须有高效索引支持,否则 Apply 性能极差。
⚠️ 风险 3:子查询返回大量数据
问题案例:
-- ❌ 危险:子查询每次返回大量数据
SELECT au.*
FROM app_user au
WHERE au.last_online_time BETWEEN '2025-11-05 00:00:00' AND '2025-11-05 23:59:59'
AND EXISTS (
SELECT /*+ NO_DECORRELATE() */ 1
FROM operation_account_record oar
WHERE au.id = oar.user_id -- ⚠️ 每个用户有数千条操作记录
);优化建议: 使用 LIMIT 1 提前终止子查询
5.3 Apply 风险总结
| 风险类型 | 触发条件 | 影响程度 | 缓解措施 |
|---|---|---|---|
| 驱动表过大 | 外部查询过大时 | 🔴 严重 | 添加过滤条件减少驱动表行数 |
| 缺少索引 | 子查询无索引支持 | 🔴 严重 | 创建合适索引 |
| 子查询返回多行 | 未使用 LIMIT 1 | 🟡 中等 | EXISTS/NOT EXISTS 加 LIMIT 1 |
| 数据倾斜 | 个别行数据量极大 | 🟡 中等 | LIMIT 限制 |
| 无 LIMIT 优化 | 未使用 LIMIT | 🟢 轻微 | 尽量使用 LIMIT 限制结果 |
5.4 Apply 安全使用检查清单
在使用 NO_DECORRELATE 前,请确认以下条件:
- 外部查询结果集 < 1,000 行(建议 < 500 行)
- 子查询有高效索引(覆盖索引或复合索引)
- 子查询条件有高选择性(能快速过滤数据)
- EXISTS/NOT EXISTS 使用了 LIMIT 1(如果适用)
- 数据分布相对均匀(无极端数据倾斜)
- 使用 EXPLAIN ANALYZE 验证过性能
- 业务场景稳定(数据规模不会突变)
6. 优化决策:何时该去关联,何时不该去关联
6.1 决策矩阵
| 外部查询行数 | 子查询表大小 | 子查询索引 | 推荐方案 | 理由 |
|---|---|---|---|---|
| < 100 | > 100万 | ✅ 有高效索引 | NO_DECORRELATE | Apply + 索引最快 |
| < 1,000 | > 10万 | ✅ 有高效索引 | NO_DECORRELATE | Apply 仍然高效 |
| < 1,000 | > 10万 | ❌ 无索引 | 默认关联 | Apply 会全表扫描 N 次 |
| > 10,000 | 任意 | ✅ 有索引 | 默认关联 | Apply 执行次数过多 |
| > 10,000 | 任意 | ❌ 无索引 | 默认关联 | 全表扫描一次优于 N 次 |
| < 100 | < 1,000 | 任意 | 随意 | 数据量小,差异不大 |
6.2 决策流程图
开始
│
├─ 外部查询结果集大小?
│ ├─ < 500 行
│ │ ├─ 子查询表大小?
│ │ │ ├─ > 10万行
│ │ │ │ ├─ 子查询有高效索引?
│ │ │ │ │ ├─ 是 → ✅ 使用 NO_DECORRELATE
│ │ │ │ │ └─ 否 → ❌ 去关联
│ │ │ └─ < 10万行 → 随意(性能差异小)
│ │
│ ├─ 500 - 5,000 行
│ │ ├─ 子查询有覆盖索引?
│ │ │ ├─ 是 → 🔶 测试后决定
│ │ │ └─ 否 → ✅ 去关联
│ │
│ └─ > 5,000 行
│ └─ ✅ 去关联(Apply 执行次数过多)
│
└─ 使用 EXPLAIN ANALYZE 验证6.3 实用判断公式
去关联总成本:
外部查询成本 + (外部查询行数 × 单次子查询成本)关联总成本:
子查询全表扫描成本 + 哈希表构建成本 + JOIN成本决策规则:
IF 去关联总成本 < 关联总成本 × 0.8: # 留 20% 余量
使用 NO_DECORRELATE
ELSE:
使用关联(默认)7. 最佳实践与总结
7.1 核心原则
原则 1:数据规模决定策略
外部查询小 + 子表大 + 高效索引 → NO_DECORRELATE ✅
外部查询大 + 任意子表 → 关联 ✅
外部查询小 + 子表大 + 无索引 → 关联 ✅原则 2:索引是关键
Apply 成功的前提:
-
子查询必须有高效索引
-
覆盖索引最佳
索引检查清单:
- 子查询的关联列有索引
- 使用
EXPLAIN验证索引是否被使用
原则 3:测试验证优于理论推测
-- 始终使用 EXPLAIN ANALYZE 对比实际性能
EXPLAIN ANALYZE SELECT ... -- 原始查询
EXPLAIN ANALYZE SELECT /*+ NO_DECORRELATE() */ ... -- 优化查询7.2 优化检查清单
阶段 1:问题识别
- 查询执行时间 > 1 秒?
- 查询中是否包含
EXISTS/NOT EXISTS/IN子查询? - 子查询是否引用了外部查询的列?
- 使用
EXPLAIN查看是否有HashJoin或Apply操作符?
阶段 2:数据分析
- 统计外部查询的实际返回行数
- 统计子查询表的总行数
- 检查子查询的过滤条件选择性
- 分析数据分布是否均匀
阶段 3:索引评估
- 子查询关联列是否有索引?
- 索引是否为复合索引?
- 索引选择性是否足够高?
- 使用
EXPLAIN验证索引是否生效
阶段 4:优化实施
- 尝试添加
NO_DECORRELATEHint - 使用
EXPLAIN ANALYZE对比性能 - 检查内存和 CPU 使用情况
- 在测试环境充分验证
阶段 5:监控和维护
- 监控查询执行时间的变化
- 定期更新统计信息
ANALYZE TABLE - 关注数据规模的增长趋势
- 当数据规模变化时重新评估优化策略
7.3 关键要点总结
🎯 核心洞察(基于真实案例):
TiDB 的自动关联优化在大多数情况下是有益的,但当外部查询结果集很小 (本案例:25行)且子查询表很大(本案例:136,826行)时,去关联会导致处理大量无用数据,反而降低性能。
真实优化效果:
执行时间:67.1ms → 15.6ms(4.3 倍提升)
扫描行数:136,851 行 → 25 行(5,263 倍减少)
内存占用:11.8 MB → 760 Bytes(16,280 倍节省)
使用
NO_DECORRELATEHint 阻止去关联,保留 Apply 操作符,可以充分利用索引,实现显著的性能提升。
⚠️ 使用原则(经过实战验证):
数据规模是关键:外部查询 < 100 行,子表 > 10万行(本案例:29 vs 136,826)
索引是前提 :子查询必须有高效索引支持(本案例:
idx_user索引)测试是保障:始终使用 EXPLAIN ANALYZE 验证(本案例:实测 4.3 倍提升)
监控是持续:定期检查数据规模变化和查询性能
慎用原则 :明确适用场景,避免盲目使用
📚 学习要点:
✅ 理解关联子查询和去关联的原理
✅ 掌握 Apply 和 HashJoin 的执行逻辑
✅ 能够根据数据规模做出优化决策
✅ 了解 NO_DECORRELATE Hint 的适用场景
参考资料
-
TiDB 官方文档
-
性能调优参考
-
相关概念
-
关联子查询(Correlated Subquery)
-
去关联
-
Apply 算子
-
反连接(Anti Semi Join)
-
哈希连接(Hash Join)
-