最近用到了 Flutter 做跨平台项目,比较好奇跨平台项目是怎么能够在 Android 设备上显示出来的,就有了今天的文章,因为之前写的 Android 图形显示系统 ,也算是承上启下了吧,毕竟这么多年没更啦
1. 核心架构基础:Android 图形栈与数据流
理解任何 Android UI 组件的渲染过程,都必须从操作系统的底层图形架构开始,特别是缓冲区管理、Surface 抽象以及系统合成器的功能。
1.1. Android 渲染数据流:BufferQueue, Surface 与 Layer 模型
Android 图形系统基于生产者-消费者模型。 在这种模型中,应用或其渲染引擎被视为生产者,而系统合成器 SurfaceFlinger 则充当消费者。具体大家可以看之前的文章:显示原理
简要示意图如下: 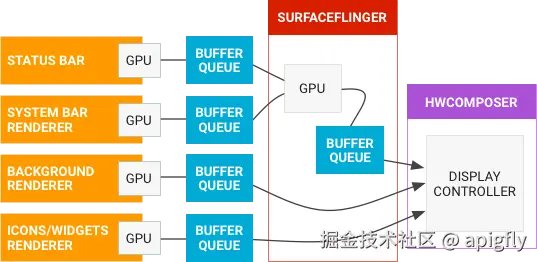
BufferQueue
数据交换的核心。这是一个先进先出(FIFO)队列,位于 libgui IPC 库中,用于跨进程安全地传输图形缓冲区。
生产者负责向队列中写入已渲染的帧,而消费者则从队列中取出帧进行合成。 这种机制的设计目标是确保数据的原子性传输和同步。
消费者通常是 Android 的核心合成器 SurfaceFlinger,但也可以是其他组件,例如 SurfaceView、SurfaceTexture 或 ImageReader。
Surface
Surface 对象是应用进程用于与 BufferQueue 交互的高级 API 接口。 它本身并不存储像素数据,而是持有一个对底层 IGraphicBufferProducer 接口的引用。 这个接口允许应用跨进程将渲染完成的图形缓冲区排队等待消费。
Layer
Layer 是 SurfaceFlinger 内部用于合成的基本单位。 它与 Surface 不同,Surface 专注于像素内容的生产,而 Layer 专注于该内容的合成方式。 一个 Layer 封装了合成所需的全部元数据和状态信息,包括:Z 轴顺序(决定遮挡关系)、可见性、混合模式(Alpha 混合)、裁剪区域、完整的 2D/3D 转换矩阵(Translation, Rotation, Scale)。
零拷贝优化
现代 Android 图形系统严重依赖 AHardwareBuffer (API 26+) 来实现高性能、低延迟的图形数据传输。
AHardwareBuffer 代表一种硬件支持的缓冲区,可以高效地在不同系统组件和进程之间共享,通常用于实现零拷贝操作。
AHardwareBuffer支持多层纹理数组和立方体贴图的定义,特别适用于 Vulkan 后端或跨进程图形传输
WebView 的进程外光栅化(OOPR)就需要利用AHardwareBuffer机制实现高效的缓冲区共享。
生产者与消费者的"距离"与隔离 BufferQueue 机制的核心价值在于,它使得生产者和消费者能够在不同的线程甚至不同的进程中独立、并行地运行。这种隔离性是 Android 实现流畅 UI 和高保真媒体播放的关键:
- 线程隔离(距离近): 生产者(如应用中的 RenderThread 或 GLSurfaceView 的专用渲染线程)可以在高频下(如 60FPS)渲染,而不会阻塞接收该缓冲区的消费者(通常是
SurfaceFlinger)。这确保了渲染任务不会拖累应用的主 UI 线程。 - 进程隔离(距离远):
Surface对象实现了Parcelable接口,因此可以安全地通过Binder IPC机制跨越进程边界传输。这种能力使得一个独立进程的渲染结果能够直接提交给另一个进程中的接收者(例如SurfaceFlinger或SurfaceView)。
SF 之外的消费者 (应用程序主动选择的数据处理流)
- SurfaceTexture (GPU 纹理消费者):
- 场景: 实时相机预览、将视频流作为纹理应用到 3D 游戏或 AR 场景中。
- 机制:
SurfaceTexture充当BufferQueue的消费者。它接收生产者(如相机驱动或视频解码器)提交的帧数据,并将其转换为一个 OpenGL ES 纹理 ,供应用内的 GLES 线程绑定和使用。这允许开发者在 GPU 上直接处理这些数据(例如应用滤镜、进行几何变换),而无需将数据提交给 SurfaceFlinger 进行系统合成 。这种路径允许应用在本地 GPU 上完成渲染和处理,但最终如果需要显示,应用通常需要将这个处理后的纹理 绘制到自己的主Surface上(最终仍由 SF 合成)。
- ImageReader (数据处理消费者):
- 场景: 截屏、图像分析(如人脸识别)、自定义相机捕获原始帧。
- 机制: ImageReader 也充当 BufferQueue 的消费者。它允许应用程序从队列中获取图像数据(Image 对象),通常是原始像素数据。数据随后被发送到应用的 CPU/NDK 层,用于进一步的软件处理、分析或保存,完全绕过了 Android 的硬件加速显示路径,是纯粹的数据获取和处理通道。
SF 跨进程/跨线程能力的常见示例 (显示场景)
- 视频播放 (SurfaceView 场景):
- 生产者: 视频解码器(通常是运行在独立进程中的硬件或系统服务)。
- 消费者: SurfaceFlinger。
- 优势: 解码器将视频帧直接绘制到从 SurfaceView 获得的 Surface 上。由于 SurfaceFlinger 直接从 BufferQueue 获取缓冲区,整个过程完全绕过了应用的主 CPU/GPU 管线。这实现了零拷贝的数据路径,对高吞吐量的视频帧传输至关重要,确保了低延迟和低功耗。
- 多窗口/系统 UI 合成 (SurfaceFlinger 核心功能):
- 生产者: 应用 A 的主渲染 Layer (Native View/Compose 的 RenderThread 提交);应用 B 的独立 Layer;系统状态栏和导航栏 Layer。
- 消费者: SurfaceFlinger。
- 优势: SurfaceFlinger 接收来自多个不同应用进程 和系统进程的独立 Layer,并管理它们的 Z 轴顺序、位置和变换。这种隔离确保了即使一个应用崩溃,也不会影响其他应用或系统 UI 的显示。
- 进程外 WebView 渲染 (OOPR 模式):
- 生产者: 沙箱隔离的 Chrome Render Process(一个独立进程)。
- 消费者: SurfaceFlinger。
- 优势: WebView 的内容渲染发生在应用主进程之外。渲染进程将结果提交到专用的 Surface 缓冲区,SurfaceFlinger 将其作为独立 Layer 合成。这提供了极佳的安全性和稳定性隔离,即使 Web 内容中的 JavaScript 导致渲染进程崩溃,主机应用也可以通过回调机制恢复。
1.2. 系统合成器:SurfaceFlinger 与硬件合成器 (HWC) 的角色
SurfaceFlinger (SF) 是 Android 的核心系统服务,充当所有可见 UI 元素的最终合成器。
SurfaceFlinger (SF) 的职责
SF 接收来自所有可见窗口和系统 UI 组件的图形缓冲区,这些缓冲区通过 Layer 的形式提交给 SF 。
SF 的任务是:
- 管理所有
Layer的 Z 轴顺序、位置、变换和剪裁。 - 根据
Layer的属性(例如透明度、相对 Z 轴、圆角等)决定如何进行合成。 - 将最终合成的结果发送给显示硬件。
SurfaceFlinger 的核心地位
无论采用哪种渲染技术栈(Native View, Compose, Flutter, WebView, GLSurfaceView),它们最终都必须通过各自的 Surface 接口向 BufferQueue 提交渲染完成的图形缓冲区。
因此,可以确定,在 Android 平台上,所有五种技术路线的渲染结果,都会以独立的或应用主 Layer 的形式,统一由 SurfaceFlinger 来接收和处理,这是它们最终得以在屏幕上显示的必经之路。
硬件合成器 (HWC) 优化
为了最大化性能和降低功耗,SurfaceFlinger 倾向于将合成任务卸载给硬件合成器(Hardware Composer, HWC)。
HWC 是一个 SoC 厂商实现的 HAL(硬件抽象层)模块,能够直接处理 Layer 的合成,通常以零拷贝的方式操作缓冲区。这极大地提高了效率。
只有当 Layer 具有复杂的混合、变换或特效,HWC 无法直接处理时,SF 才会退回到使用 GPU 进行合成(GPU Compositing),这会增加系统的渲染开销。
1.3. 绘制指令模式对比:即时与保留
UI 框架在生成绘图指令时,主要遵循两种模式:保留模式 (Retained Mode) 和即时模式 (Immediate Mode)。
保留模式 (Retained Mode)
在这种模式下,UI 元素的结构和属性被存储为一个场景图或对象层级结构(在 Android Native/Compose 中称为 RenderNode 或 Display List)。当 UI 状态发生变化时,系统只需更新场景图中发生变化的部分,而不是重新执行所有绘图指令。这种模式非常适合动态或频繁变化的 UI,因为它允许更灵活和高效的更新 。Android Native Views 和 Jetpack Compose 都是基于保留模式的实现。
即时模式 (Immediate Mode)
在这种模式下,每一次帧更新,应用程序都需要重新发送完整的绘图指令序列。系统不存储 UI 状态图。即时模式要求开发者对底层的图形 API(如 OpenGL ES 或 Skia Canvas)有更直接的控制。它在静态 UI 中可能资源占用较少,但在动态 UI 中可能性能较差,除非底层引擎进行了高效优化(如 Flutter 的 Skia)。
GLSurfaceView 和 Flutter 的核心渲染流程属于即时模式。
绘制模式 (Immediate vs. Retained) 特性对比
| 特性 | 保留模式 (Retained Mode) | 即时模式 (Immediate Mode) |
|---|---|---|
| 核心机制 | 场景图/显示列表 (RenderNode) 存储状态 | 立即执行绘图指令,不存储状态 |
| 更新效率 | 高效 (仅重绘变动部分) | 依赖框架/引擎 (Skia 优化了底层效率) |
| 线程隔离 | RenderThread 机制提供原生的 CPU/GPU 隔离 | 需用户/引擎自行实现专用 Raster/GLES 线程 |
| 代表技术 | Android Native View, Jetpack Compose | Flutter (Skia), GLSurfaceView |
2. 保留模式下的原生 UI 渲染管线:Native View 与 Compose
Android 原生 UI 框架(无论是基于 View 还是 Compose)都依赖于 AOSP 的保留模式渲染架构,核心在于 RenderThread。
2.1. Android 原生 View 渲染流程:Record, Execute 与 RenderThread
当 View 层次结构需要更新时,渲染流程在应用进程内分两个主要阶段进行:
1. UI 线程:记录 (Record) 阶段
UI 线程(或主线程)负责所有的业务逻辑、布局计算(Measure 和 Layout),以及绘图指令的记录。在硬件加速开启的前提下,View#draw(Canvas)的调用不会直接执行 GPU 渲染,而是将绘图操作记录到关联的 RenderNode(即 Display List)中。
- 性能风险: 尽管记录 Display List 通常很快,但如果应用代码在此阶段涉及复杂的 CPU 密集型操作,例如绘制到 Bitmap(这会触发 CPU 软件渲染),则会占用 UI 线程时间,可能导致帧率下降(Jank指标)。
2. RenderThread:执行 (Execute) 阶段
RenderThread 是一个系统管理的新线程,自 Android Lollipop 引入,旨在将 GPU 相关的重型工作负载从 UI 线程分离出来。
- JANK 隔离:
RenderThread的核心价值在于,即使 UI 线程被阻塞(例如,因垃圾回收或复杂业务逻辑),它仍能继续执行先前提交的 Display List,从而保持动画、触摸反馈和Material Design特效(如涟漪效果)的平滑运行。 - 执行与优化:
RenderThread接收 UI 线程提交的RenderNode,负责对指令进行优化(例如,批处理),将它们翻译成低级的 GPU API 调用(GLES 或 Vulkan),并最终通过eglSwapBuffers()提交到Surface的BufferQueue中。 - 潜在的性能陷阱: 某些
Canvas操作,如绘制非常大的或复杂的Path对象,在 UI 线程上的记录成本很低,但在RenderThread执行时可能触发昂贵的 CPU 或 GPU 计算,导致RenderThread成为新的瓶颈。系统分析工具(如 Systrace)常用于识别这类问题。
渲染驱动逻辑与 VSync 依赖
- 渲染线程: 专用
RenderThread。 - 驱动机制: 强依赖 VSync 信号。 当应用需要渲染时,系统会向
Choreographer注册一个回调,等待VSync信号的到来。 - 频率控制: 渲染频率主要由系统
VSync 频率(通常 60Hz 或 120Hz)控制。应用通过View.invalidate()标记View为脏,但实际的绘制执行始终与VSync同步,以避免画面撕裂。
原生 View 渲染流程
时序图: 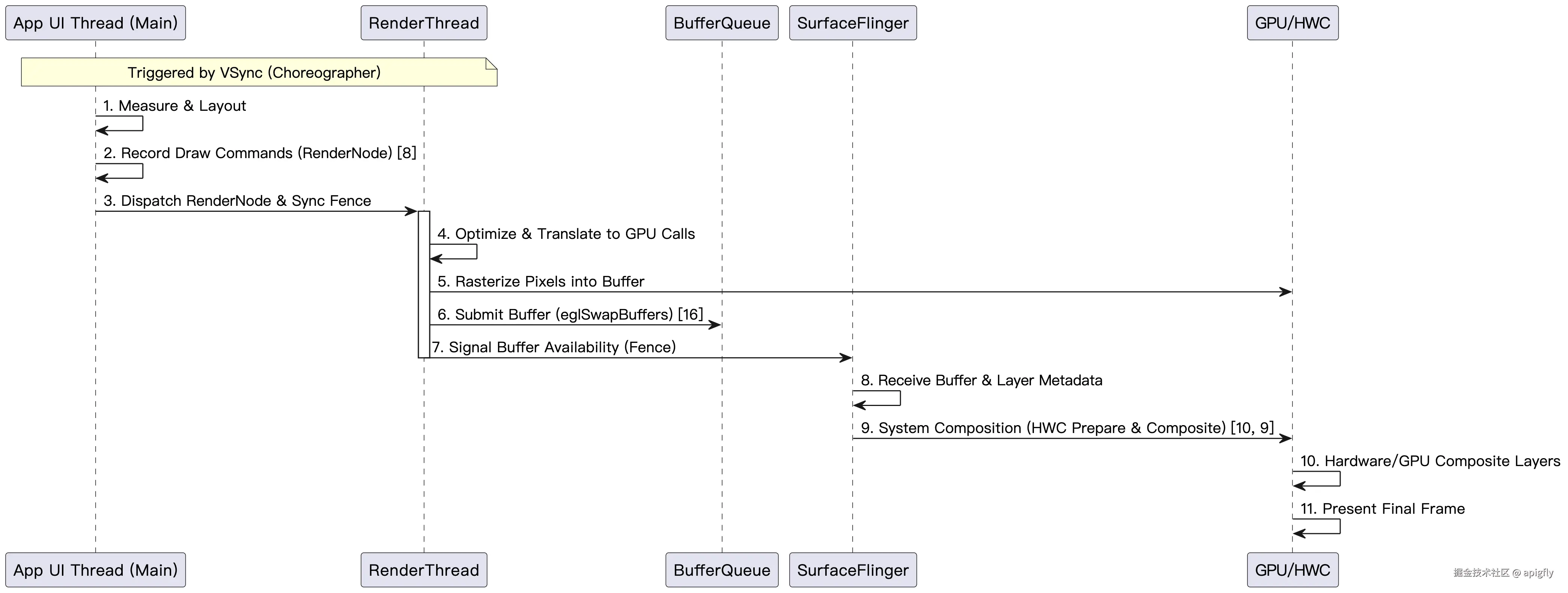
该流程描述了 Native View 从输入事件到最终显示的序列:
- Application UI Thread: 执行
View层次结构的Measure&Layout阶段,确定所有组件的尺寸和位置。 - Application UI Thread: 执行
Record阶段,调用View#draw,将所有绘图操作(如绘制文本、形状)记录到RenderNode (Display List)中。 - Application UI Thread -> RenderThread: 分发记录好的
RenderNode数据到独立的 RenderThread。 - RenderThread: 优化
RenderNode中的指令,将其转化为低级 GPU 调用 (GLES 或 Vulkan)。 - RenderThread -> GPU: 发出 光栅化指令 ,在
VSync信号驱动下,在应用独占的缓冲区中绘制 View 的像素内容。此步骤在应用进程内完成所有 UI 元素的绘制。 - RenderThread -> SurfaceFlinger: 通过
EGLSurface调用eglSwapBuffers(),将绘制完成的缓冲区提交给系统合成器SF。 - SurfaceFlinger/HWC: 接收应用缓冲区,进行 系统级合成 (Composition) 和最终显示。
HWC确定最佳合成路径,将此Layer与状态栏、导航栏、其他应用窗口等所有Layer合并,并最终显示到屏幕上。
2.2. Jetpack Compose 渲染管线:声明式与 GraphicsLayer 优化
Jetpack Compose 采用了声明式 UI 模型,其渲染管线遵循 Composition(节点创建)、Measure、Layout,最终到达 Drawing 阶段。尽管其编程范式发生了根本性变化,但在 Android 平台上,Compose 最终仍复用 Native View 的底层硬件加速机制。
Draw 阶段与 Canvas 的关联
Compose 框架在 Draw 阶段,底层仍然依赖于 View 系统的 Canvas API 进行实际的像素操作 。
然而,Compose 通过 DrawScope 抽象简化了传统的 View 绘图模型,例如替开发者管理复杂的 Paint 对象配置,确保性能优化。
GraphicsLayer 与 RenderNode 的复用
Compose通过 Modifier.graphicsLayer 引入了与 Native View 中 RenderNode 相似的概念 。
使用 graphicsLayer 意味着 Composable 组件的绘图指令会被捕获并缓存到一个 Layer 中 。
- 性能收益: 这种缓存机制允许渲染管线高效地重发这些绘图指令,尤其适用于频繁的几何变换、透明度变化或缩放动画。一旦指令被捕获,RenderThread 可以在不依赖 UI 线程重新执行 Composable 代码的情况下,重复执行这些已缓存的指令。
Offscreen Rasterization (离屏光栅化)
graphicsLayer 的进一步优化是离屏光栅化,也被称为纹理缓存。
在这种情况下,RenderThread 会执行 RenderNode 中的指令,并将结果捕获到一个离屏 GPU 纹理中。
在后续的帧中,RenderThread 只需要发送一个简单的指令:"绘制这个纹理",这极大减少了 CPU 和 GPU 的重复计算,尤其对于复杂的、不常变化的组件(如 LazyList 中滚动的条目)的性能优化至关重要。
渲染管线性能瓶颈聚焦
原生 View 和 Compose 共享 RenderThread 执行管线,这表明它们的 GPU 性能优化途径是相似的。它们的主要性能差异体现在 UI 线程的记录阶段:
- 原生 View 的性能瓶颈通常集中在传统的 View 层次结构遍历和 Measure/Layout 效率上。
- Compose 的性能瓶颈则集中在 Composition/Recomposition 逻辑的效率和状态管理上。
即使 RenderThread 隔离了 GPU 执行,如果 Composition 或 Layout 阶段耗时超过每帧预算(例如 16ms),UI 线程的阻塞仍会导致新的 RenderNode 无法及时提交,从而引发 JANK。因此,无论是 Native 还是 Compose,优化策略的重点都必须放在减少 UI 线程的负载上。
渲染驱动逻辑与 VSync 依赖
- 渲染线程: 共享 AOSP 的 RenderThread。
- 驱动机制: 强依赖 VSync 信号。 Compose 状态(State)变化触发 UI 线程的重组和布局计算。RenderThread 的光栅化执行(绘制)同样严格对齐 VSync 脉冲。
- 频率控制: 无法直接控制。频率由系统 VSync 确定。Compose 仅在需要时(状态改变)才触发新的帧提交。
Jetpack Compose 渲染流程
时序图:

该流程描述了 Compose 从状态变化到渲染的序列:
- UI Thread (Composition/Layout): 执行 Composition 阶段,根据状态(State)变化确定需要创建、更新或跳过哪些 UI 节点。
- UI Thread (Composition/Layout): 执行 Measure & Layout 阶段,确定所有 Composable 组件的最终尺寸和屏幕位置。
- UI Thread (Composition/Layout): 执行 Draw Phase,捕获绘图操作,并将其存储在 GraphicsLayer 中。
- UI Thread -> RenderThread: 将封装了绘图指令的 RenderNode/GraphicsLayer 提交给 RenderThread。
- RenderThread -> GPU: RenderThread 在 VSync 驱动下,在 GPU 上执行光栅化指令,包括处理离屏纹理缓存等优化,在应用 Surface 缓冲区中绘制 Composable UI 像素。
- RenderThread -> SurfaceFlinger: 调用缓冲区交换函数,提交渲染完成的帧缓冲区。
- SurfaceFlinger: 接收缓冲区,执行系统级合成,并最终交给 HWC 进行显示。
3. 即时模式与专用渲染管线:Flutter 与 GLSurfaceView
与依赖 AOSP RenderThread 的 Native/Compose 不同,Flutter 和 GLSurfaceView 使用即时模式渲染,并创建了独立于 AOSP 图形栈的专用渲染环境。
3.1. Flutter View 渲染管线
Flutter 在 Android 上运行于一个名为 Flutter Embedder 的 C++ 组件中,并管理着一组专用的线程:平台线程(负责与宿主 OS 通信)、UI 线程(运行 Dart 逻辑和 Widget 树构建),以及关键的 Raster Thread(栅格化线程)。
双线程模型
Flutter 的高性能渲染基于其严格隔离的双线程模型:
- Dart UI Thread: 负责处理应用逻辑、Widget 构建、Element Tree 维护、Render Tree 创建以及布局计算。
- Flutter Raster Thread (也称 GPU Thread): 这是一个专用的 C++ 线程,负责将 Dart UI Thread 生成的 Layer Tree 传递给 Flutter 引擎。Flutter 引擎在此线程上将高层级绘图指令翻译成低层级的 GPU/CPU 指令,执行光栅化,并利用 GPU 加速,确保高效渲染。
Flutter 的 UI 线程负责构建高层次的 Layer Tree。然后,Raster Thread 专门负责消耗这个 Layer Tree,并使用其集成的 Skia 或更新的 Impeller 渲染引擎生成低级图形命令。
Impeller 旨在通过提前编译着色器等方式,进一步优化移动 GPU 性能
即时模式与底层优化
Flutter Android Embedder 负责与 Android 系统进行底层交互。它为 Flutter 的输出获取一个专用的 Android Surface,为 Raster Thread 设置必要的 EGL 或 Vulkan 上下文,并处理低级的缓冲区提交逻辑。
Skia/Impeller 最终将整个应用 UI 渲染到一个 Surface 中,作为 Android 系统的一个独立 Layer 提交给 SurfaceFlinger。
虽然 Flutter 在 Dart 侧的 Widget 构建和 Render Tree 创建可以被视为每帧都可能重新发生的即时模式行为,但 Skia/Impeller 在底层对这些指令进行高度优化、批处理和硬件加速。
渲染架构的独立性
Flutter Raster Thread 的存在绕过了 AOSP 的 RenderThread 机制。这赋予了 Flutter Engine 对渲染管线的完全控制权和跨平台性能的确定性。
这种架构决策避免了与原生 View 系统的复杂交互,但代价是在集成原生组件时需要引入额外的桥接层和合成模式,如 Platform Views。
渲染驱动逻辑与 VSync 依赖
- 渲染线程: 独立于 AOSP 的
Raster Thread(C++ 实现)。 - 驱动机制:
Flutter Engine内部具备自己的调度器,但它会监听和对齐平台 VSync 信号 ,以确保渲染帧与显示器的刷新率同步(目标 60 FPS 或 120 FPS)。渲染工作在 UI Thread 和Raster Thread之间分工。 - 频率控制: 由
Skia/Impeller控制,同步于系统VSync频率。
Flutter Platform Views 的集成方案深度对比
Flutter Engine 作为一个完全独立的渲染引擎,当需要嵌入原生 Android View(如 MapView 或 WebView)时,必须采用特殊的机制来桥接 Flutter 的 Raster Thread 与 Android 的 Surface 机制。
Flutter 提供了两种核心渲染机制,选择哪一种取决于对原生组件保真度、Flutter 动画性能以及是否需要 Flutter 侧变换的需求。
| 模式 | 适用场景/优势 | 限制/劣势 | 选择判断 |
|---|---|---|---|
| Hybrid Composition (HC) | 原生视图保真度和性能至上: 适用于对输入处理、本地视图生命周期和渲染保真度要求极高(接近原生体验)的组件。它提供最佳的 Android View 性能和保真度 | 牺牲 Flutter 性能: 由于 SurfaceFlinger 需要进行系统级合成,Flutter UI 的 FPS 会有所降低 不支持 Flutter 侧变换: 无法对嵌入的原生视图应用所有 Flutter Widget 的几何变换、透明度或裁剪效果。 | 原生 View 包含 SurfaceView (如视频、相机),且原生视图性能优先于 Flutter 动画流畅度。 |
| Texture Layer (TLHC) | Flutter 动画和变换能力至上: 适用于需要对嵌入的 View 进行旋转、缩放、裁剪或应用透明度效果的场景。它提供最佳的 Flutter 渲染性能。 | 原生视图滚动可能出现卡顿 (Jank): 由于将原生 View 渲染到纹理需要额外的处理延迟,快速滚动(如内嵌的 WebView)可能出现卡顿 17。SurfaceView 组件在此模式下表现不佳。 | 需要对原生 View 应用 Flutter 侧变换(如 3D 旋转、裁剪),且原生 View 内容更新频率不高或不需要使用 SurfaceView。 |
默认机制与自动选择
- Texture Layer Hybrid Composition (TLHC) 是目前 Flutter 框架中推荐且默认的 Platform View 渲染模式。
- 回退机制: 当原生视图树中包含 SurfaceView 组件时(例如视频播放器、相机预览等),TLHC 模式会遇到困难,系统可能会自动回退到 Hybrid Composition (HC) 模式。
Flutter 渲染架构 (流程描述)
时序图:
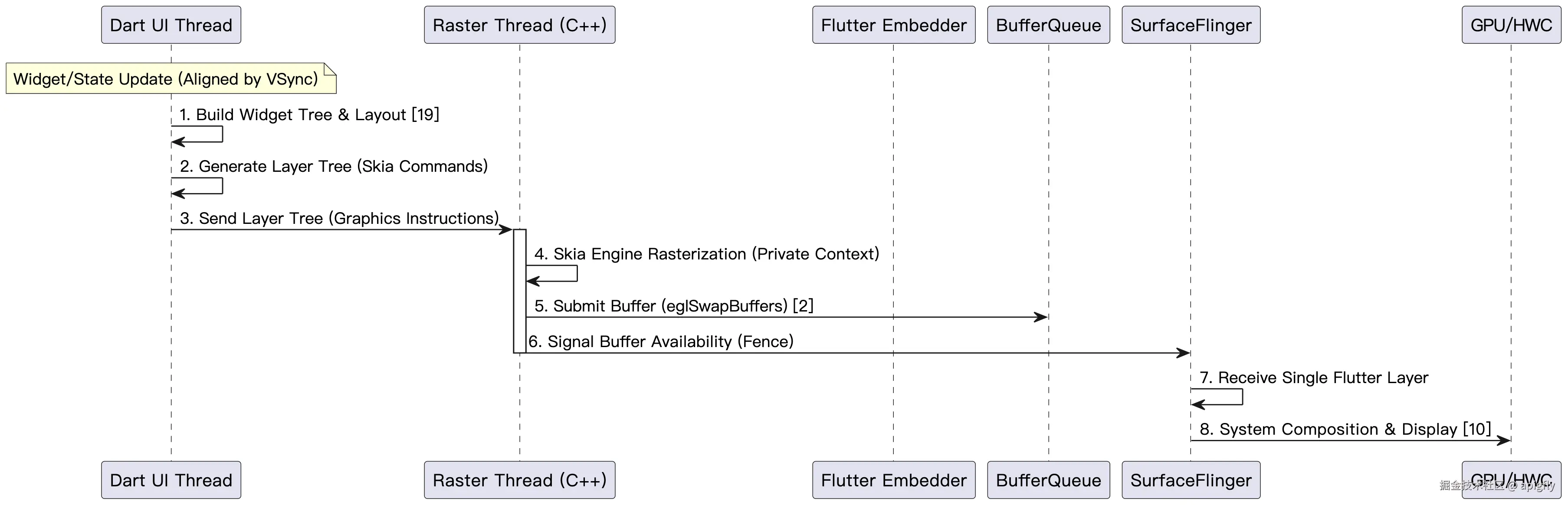
该流程描述了 Flutter 引擎的渲染序列:
- Dart UI Thread (Engine): 执行 Widget Tree 的构建,转换为 Element Tree。
- Dart UI Thread (Engine): 在 VSync 信号开始时,执行 Layout 阶段,计算 Render Tree,最终生成包含 Skia/Impeller 绘图指令的 Layer Tree。
- Dart UI Thread -> Raster Thread (Skia/GPU Thread): 将 Layer Tree 传输到独立的 Raster Thread。
- Raster Thread (Skia/GPU Thread) -> GPU: Skia 引擎 在其专用线程上执行 光栅化,将 Layer Tree 指令转换为低级 GPU 调用,在 Flutter 的 Surface 缓冲区中绘制整个 UI 像素内容。
- Raster Thread -> SurfaceFlinger (System): 提交应用 Surface 缓冲区,作为单一 Layer 提交给系统。
- SurfaceFlinger (System): 接收 Flutter 的 Layer,进行系统级合成,并最终交给 HWC 显示。
3.2. GLSurfaceView:面向 GLES 的低层级控制
GLSurfaceView 为需要进行高性能、自定义 GLES 渲染的应用提供了一个直接的接口,如游戏或视频处理。
EGL 环境与线程要求
GLSurfaceView 的主要功能是管理 GLES 渲染所需的 EGL 环境。这包括在生命周期回调中创建 EGLContext 和 EGLSurface 实例。
- 专用 GLES 线程:
GLES规范要求所有的绘图操作必须在特定的GLES线程上执行,绝对不能在 UI 线程上执行。GLSurfaceView内部创建了一个专用的渲染线程来满足这一要求,确保了重型 GPU 负载与应用主线程的彻底隔离。
即时模式与缓冲区控制
开发者在 GLES 线程中执行即时模式的绘图指令。当一帧渲染完成后,必须通过调用 eglSwapBuffers() 来明确地提交当前缓冲区。这个方法名源于传统的双缓冲机制,它将渲染好的后台缓冲区提交到前台供消费者使用。
- 帧率控制: 默认情况下,
GLSurfaceView可能以显示器的刷新率(例如 60fps)连续渲染。然而,通过设置RENDERMODE_WHEN_DIRTY,开发者可以只在 UI 逻辑或输入事件明确要求时才请求渲染 (requestRender()),这对于非实时动画或静态场景的电源和性能优化至关重要。
渲染驱动逻辑与 VSync 依赖
- 渲染线程: 专用 Dedicated GLES Thread。
- 驱动机制: 可控模式。
- RENDERMODE_CONTINUOUSLY: 渲染循环持续运行,默认与
VSync对齐,尝试达到最高刷新率。 - RENDERMODE_WHEN_DIRTY: 渲染循环仅在应用明确调用 requestRender() 时执行一帧。
- RENDERMODE_CONTINUOUSLY: 渲染循环持续运行,默认与
- 频率控制: 开发者完全控制。 可以选择连续渲染(高频/Vsync 约束)或事件驱动渲染(低频/按需)。
GLSurfaceView 渲染流程
时序图: 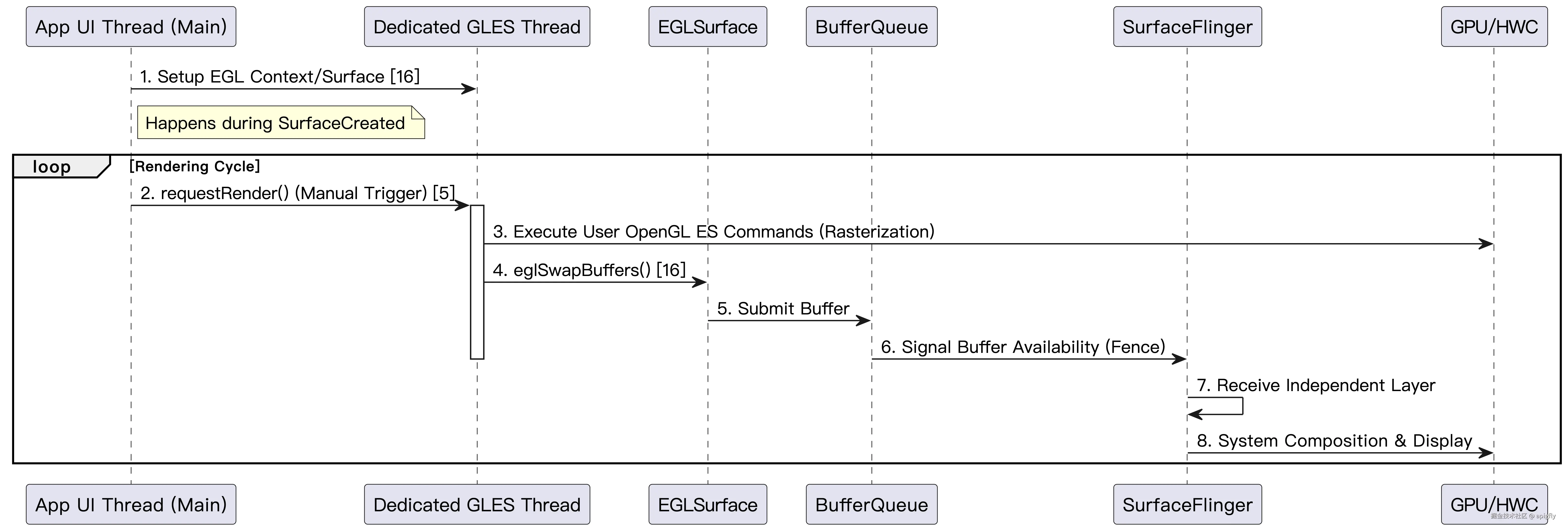
该流程描述了 GLSurfaceView 的渲染序列:
- Application UI Thread -> Dedicated GLES Thread: UI 线程在生命周期回调中,请求
GLES线程设置EGL环境,创建EGLContext和EGLSurface实例。 - Application UI Thread -> Dedicated GLES Thread: UI 线程通过事件或动画循环,触发 GLES 线程调用
requestRender()或保持连续渲染模式。 - Dedicated GLES Thread -> GPU: 执行用户定义的 OpenGL ES 绘图命令(即时模式),直接利用 GPU 光栅化 3D/2D 内容到当前的 EGL 缓冲区。这是开发者对 GPU 绘图的最直接控制。
- Dedicated GLES Thread -> BufferQueue (EGLSurface): 调用
eglSwapBuffers(),将刚刚绘制的缓冲区提交给BufferQueue消费者。 - BufferQueue (EGLSurface) -> SurfaceFlinger (System): 缓冲区作为独立
Layer提交给系统合成器。 - SurfaceFlinger (System): 将
GLSurfaceView的独立 Layer 与其他系统 UI 合成,并通过 HWC 显示。
4. 混合与跨进程渲染:WebView 与 Platform Views
复杂的 UI 场景往往涉及不同渲染技术的混合,这要求系统合成器 SurfaceFlinger 介入处理多个独立渲染源的 Layer 合成。
4.1. 现代 WebView 渲染机制:Out-of-Process Rasterization (OOPR)
WebView 承载了复杂的 Web 渲染引擎(Chromium)。为了增强安全性和稳定性,现代 Android 系统(API 30 及以上)默认使用进程外光栅化 (OOPR) 模式。
在 Android API 30 (Android R) 之前,WebView 的渲染模式取决于具体的 Android 版本和设备的内存条件:
- 进程内渲染 (In-Process Renderer): 在 Android Lollipop (API 21) 到 Android Nougat (API 25) 期间,进程内渲染是默认模式。在这种模式下,
Chromium渲染引擎(包括布局和光栅化)与主机应用运行在同一个进程内,共享资源和内存空间。这导致 Web 内容的复杂操作可能直接阻塞应用的主 UI 线程。 - 进程外渲染的过渡 (Oreo - Q): 从 Android Oreo (API 26) 到 Android Q (API 29),系统通常会启用进程外渲染,但对于低内存设备,可能会回退到进程内渲染模式。
OOPR默认化 (Android R/API 30+): 由于 Android R 对内存管理的优化,WebView 在 Android R 及以上版本中总是默认使用进程外光栅化 (OOPR) 模式,确保了隔离性。
进程隔离与 Surface IPC
在 OOPR 模式下,实际的 Web 内容渲染工作发生在宿主应用进程之外的 Chrome Render Process 中。
- 数据流:
Chrome渲染进程将其渲染结果绘制到一个专用的 Surface 中。这个Surface对象通过Android的Binder IPC机制被传递和管理。渲染进程充当Surface的生产者,负责将渲染好的GraphicBuffer(或AHardwareBuffer) 提交给SurfaceFlinger。 - 宿主应用职责: 宿主应用的主进程只需要管理
WebView的生命周期、输入事件转发以及Surface的分配,渲染工作负载被完全卸载到远程进程,实现了极高的隔离性。
WebView 的绘制模式与崩溃隔离
绘制模式: 尽管 WebView 是作为 Android Native View 层次结构的一部分被托管,其内部的 Chromium 渲染引擎遵循 保留模式 (Retained Mode) 的原则。
Web 平台的 文档对象模型 (DOM) 充当了其保留状态的模型。浏览器维护 DOM 的状态,并可以在不需要 JavaScript 持续重新发送所有绘图指令的情况下进行渲染,这与 Android View 使用 RenderNode 的思路一致 。
崩溃隔离: WebView 的进程外光栅化(OOPR)旨在通过将渲染工作负载转移到沙箱隔离的进程中 ,从而提高稳定性和安全性。
然而,如果发生严重的渲染故障,例如未捕获的 JavaScript 异常导致 Chrome Render Process 崩溃,这仍然可能导致主机应用程序受到影响。
为了实现进程级别的鲁棒性,Android 平台在 API 26 及更高版本中提供了 WebViewClient#onRenderProcessGone 回调方法。通过重写此方法,主机应用可以在渲染进程崩溃时被通知,从而允许应用进行恢复操作,例如重新加载 WebView 或显示错误信息,防止整个应用程序崩溃。
渲染驱动逻辑与 VSync 依赖
- 渲染线程: 隔离的
Chrome Render Process内部的渲染线程。 - 驱动机制: 内部 VSync 对齐。 渲染进程的渲染循环独立运行,但会与系统 VSync 信号对齐。主机应用通过滚动、页面加载或 JavaScript 动画等触发更新,渲染进程负责高效地将新内容光栅化。
- 频率控制: 由 Chromium 引擎内部控制。主机应用无法直接调节其帧率。
SurfaceFlinger 的参与
由于 WebView 的内容是作为独立进程的输出,它必定是一个独立的 Layer 提交给 SurfaceFlinger。
- 性能影响: 尽管
OOPR提供了卓越的进程隔离,但它强制WebView成为一个独立Layer,无法内嵌到应用主界面的RenderNode中进行优化。这意味着WebView内容的任何更新都必须经过 SurfaceFlinger 的系统级合成步骤。这增加了系统合成的开销,尤其是在高频更新的场景下。
WebView OOPR 渲染流程
时序图: 
WebView OOPR 渲染架构 (流程描述) 该流程描述了 WebView 跨进程渲染的组件交互:
- App Host Process (WVHost): 调用 WebView.loadUrl() 或 loadData(),触发 Web 内容加载。
- App Host Process (WVHost) -> Chrome Render Process (WebEngine): Host 进程通过 Binder IPC 机制向 Chrome 渲染进程分发加载请求、生命周期控制和输入事件。
- Chrome Render Process (WebEngine): Web 引擎(Blink)在远程进程中执行页面解析、布局计算,并构建 Web Layer Tree。
- Chrome Render Process (WebEngine) -> GPU: 渲染进程的 GPU 线程执行 光栅化,将 Web 内容绘制到专用的 AHardwareBuffer 中。渲染帧率内部与 VSync 对齐。
- Chrome Render Process (WebEngine) -> Android Graphics Subsystem (SF/BQ): Chrome 进程通过 Surface 生产者接口,将渲染好的缓冲区提交到 BufferQueue。
- Android Graphics Subsystem (SF/BQ) -> SurfaceFlinger (System): SurfaceFlinger 接收 WebView 的独立 Layer。
- SurfaceFlinger (System): 执行系统级合成,将 WebView Layer 放置在正确的 Z 轴顺序和位置上,并最终显示。
5. 总结与建议
| 技术栈 | 系统集成度 | 线程隔离粒度 | 关键性能关注点 | 典型应用场景 |
|---|---|---|---|---|
| Native/Compose | 高 (共享 RenderThread) | CPU/GPU 隔离 (RT) | 优化 UI 线程的记录/重组负载。 | 标准 UI 界面,需要高度原生平台特性。 |
| Flutter | 低 (独立引擎) | 彻底隔离 (Raster Thread) | 跨平台一致性,减少 Platform View 的合成开销。 | 高性能、高自定义度 UI,跨平台项目。 |
| GLSurfaceView | 中 (独立 Surface) | 彻底隔离 (GLES Thread) | 自主控制 eglSwapBuffers 频率。 | 游戏引擎,实时视频流,自定义 3D 渲染。 |
| WebView | 中 (跨进程 Surface) | 彻底隔离 (OOPR) | 跨进程通信延迟和 SurfaceFlinger 的 Layer 合成开销。 | 嵌入复杂 HTML/JS 内容。 |
原生 UI 的瓶颈转移: 对于 Native View 和 Compose,AOSP 已经通过 RenderThread 解决了 GPU 执行阻塞 UI 线程的问题。然而,性能优化的重点已从 GPU 转移到 UI 线程的 记录/布局/重组 阶段。
独立 Surface 的开销: 无论采用 Flutter、WebView 还是 GLSurfaceView,当它们使用独立的 Surface 对象时,都不可避免地成为 SurfaceFlinger 的一个独立 Layer。虽然这提供了极佳的线程隔离,但也意味着每一次更新都必须经过系统合成器的处理。对于需要大量 Layer 合成或复杂混合的场景,这可能导致比 HWC 零拷贝合成更高的系统资源消耗。
高性能图形的选择: 对于需要实时(60fps 或 120fps)更新和完全控制图形管线的场景,GLSurfaceView 或 Flutter Engine 是最佳选择。它们通过专用的渲染线程实现了高确定性性能,将光栅化工作负载从 AOSP 的主渲染路径中完全解耦。