OUC AI Lab 第六章:基于卷积的注意力机制
详解深度学习的中的即插即用模块
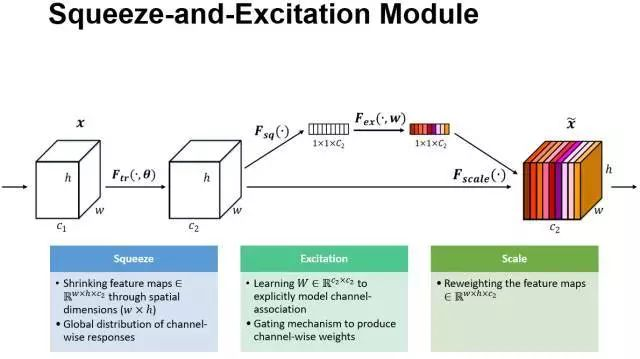
1.SENet
SENet在第四章已经学习过了
2.Non-local Neural Networks模块
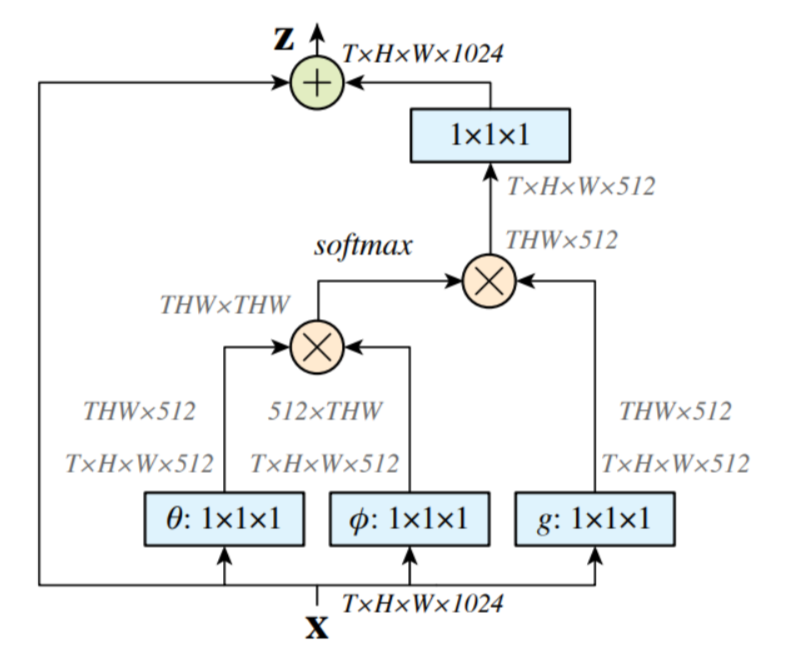
网络中的注意力模块如图所示,事实上这个模块非常像transformer里的注意力机制,其中的θ,Φ和g就相当于是transformer中的q、k、v,有关transformer的内容在下一章再介绍。在这里,x就是经过各种网络的特征,形状为T,H,W,1024,将这个x分三份分别经过θ,Φ和g这三个1x1的卷积层就得到了我们想要的三个特征,在transformer中,经过θ得到的每一行向量可以理解为"我在找什么",例如输入的是"我去上学",经过θ后"我"会对应着1024维的向量,其中每一维可以理解为"我在找什么",例如第一维是"我周围有名词吗?",第二维是"我周围有动词吗?"
经过Φ得到的每一行向量可以理解为每个字携带的信息,而经过reshape的这两个矩阵相称就可以得到一个相似性矩阵,softmax后再乘g,就相当于进行了加权聚合,这时每个位置的特征都融入了所有其他相关位置的信息,实现了长距离依赖的建模。
我认为transformer最厉害的创新点就在于使每个词都能看到整个句子中的所有词,经过两个相乘将位置信息,上下文信息和内容信息都看到了。
3. CBAM
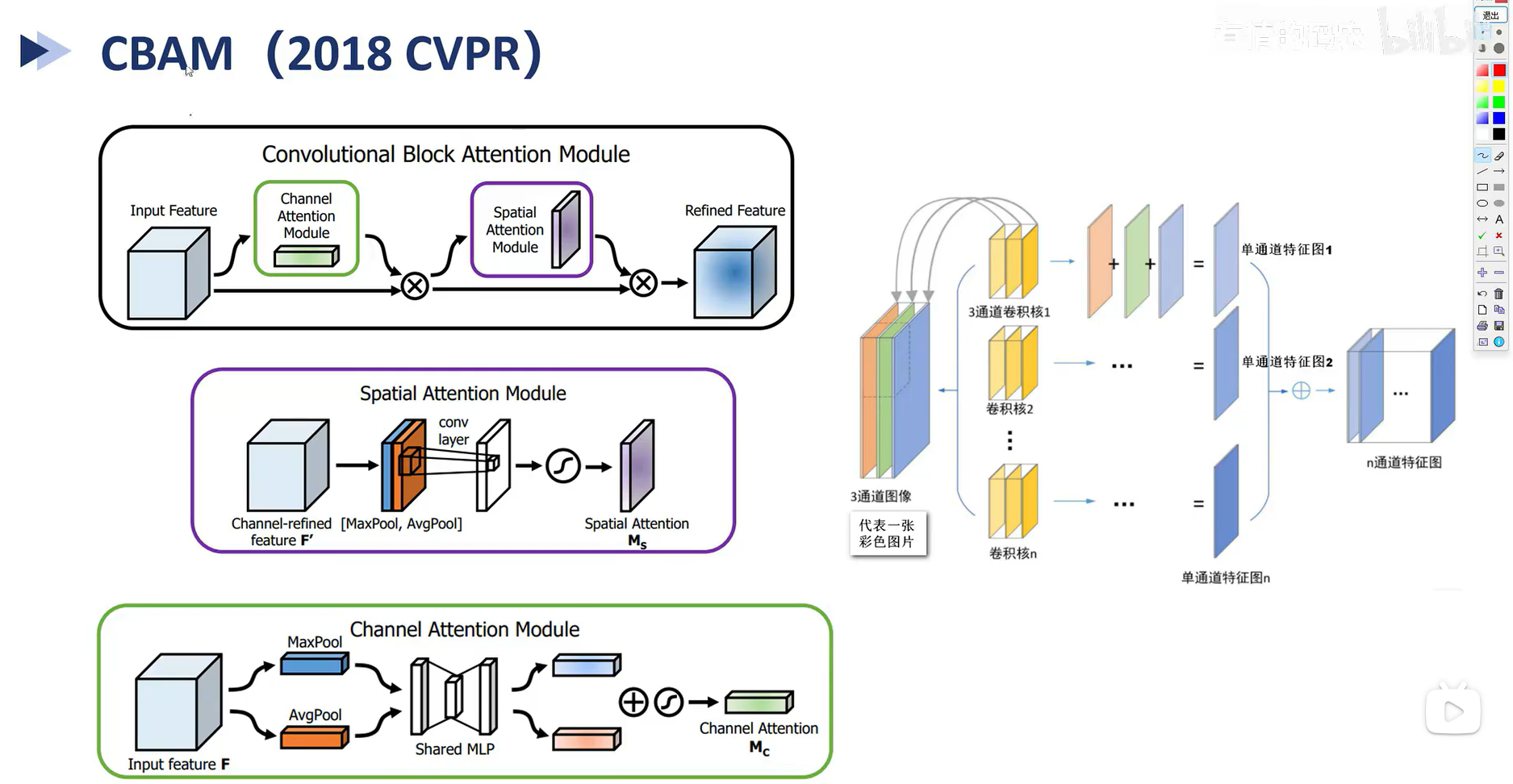
上图中右侧是普通的卷积神经网络,每个卷积核中有in channel个分别对输入的channel进行卷积,然后想加得到一个channel
而CBAM主要是考虑到在普通卷积网络中各个channel间的信息没有很好的交流,所以设计了两个模块,channel Attention Module就类似于SENet,不过SENet只用了平均池化,而这里分别在channel纬度上进行平均池化和最大池化,也就是将batch,channel,h,w变为batch,channel,1,1,然后经过变化相加softamat,最后乘到input feature上就完成了
Spatial Attention Module 是在空间纬度上进行平均池化和最大池化,将原本batch,channel,h,w变为batch,1,h,w,拼接后使用in_channel=2,out_channel=1的卷积层,再乘到input feature上就完成了。
4. DANet
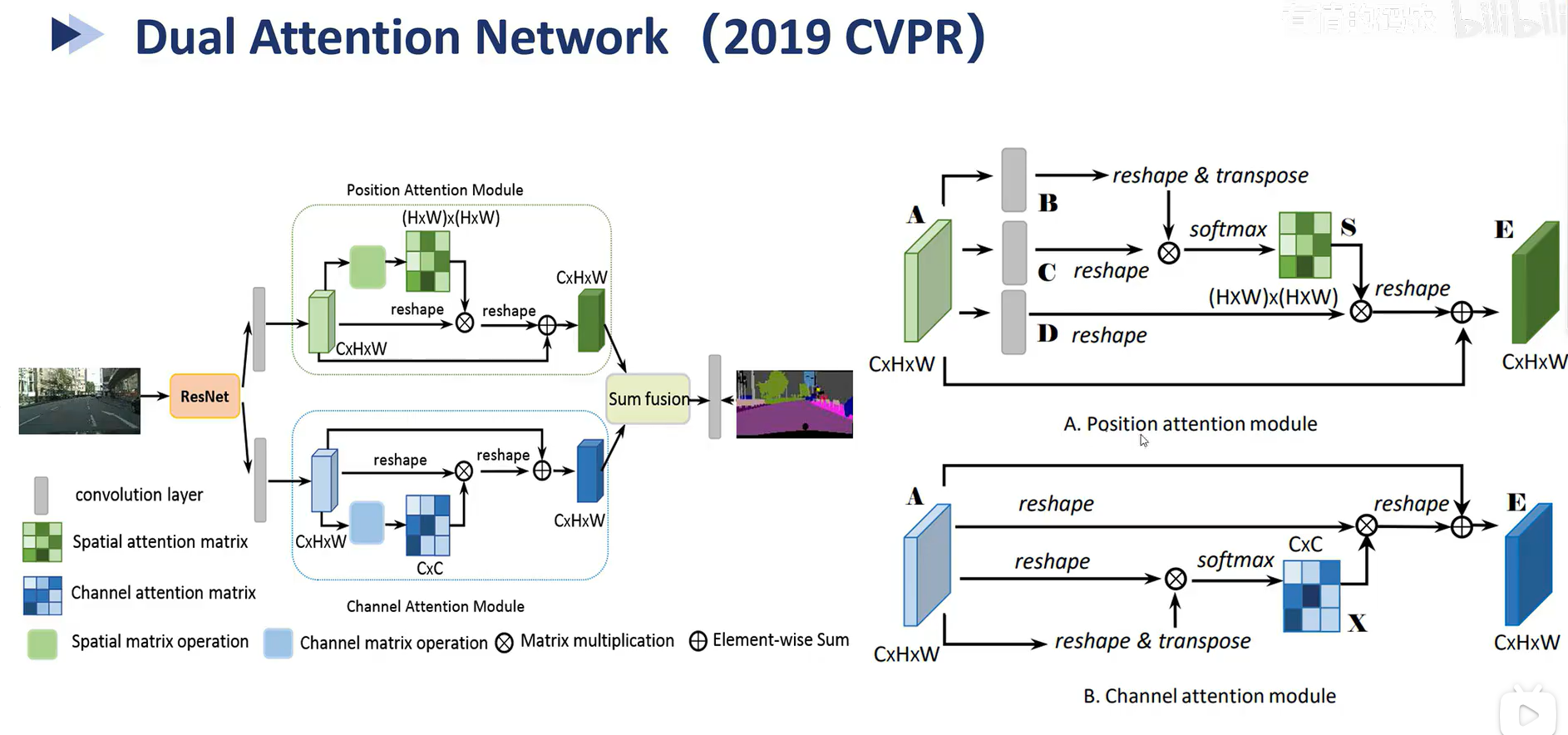
Dual Attention Network也非常简单,你要问思想是什么,那就是对CBAM的改进,CBAM是并行,先计算通道纬度的注意力,再计算空间纬度的注意力,那么这个网络就是并行的计算注意力。
如何计算的也非常简单,上图中的A就是将形状为batch,channel,h,w的输入分为三份B,C和D,全部reshape为batch,channel,h*w。
B再调整为batch,h*w,channel,乘C,得到batch,h*w,h*w,D再乘这个结果,得到batch,channel,h*w,再次reshape恢复到原来的纬度
B这个模块就是把一开始相乘的顺序改成了batch,channel,h*w乘batch,channel,h*w。