🔥 AI 即插即用 | 你的CV涨点模块"军火库"已开源!🔥
大家好!为了方便大家在CV科研和项目中高效涨点,我创建并维护了一个即插即用模块的GitHub代码仓库。
仓库里不仅有:
- 核心模块即插即用代码
- 论文精读总结
- 架构图深度解析
- 全文逐句翻译与应用实例
更有海量SOTA模型的创新模块汇总,致力于打造一个"AI即插即用"的百宝箱,方便大家快速实验、组合创新!
🚀 GitHub 仓库链接 :https://github.com/AITricks/AITricks
觉得有帮助的话,欢迎大家 Star, Fork, PR 一键三连,共同维护!
即插即用涨点系列 (八):AMDNet 详解!AAAI 2025 SOTA,MLP 融合多尺度分解(MDM)与 AMS 的涨点新范式。
论文原文 (Paper) :https://arxiv.org/pdf/2406.03751
官方代码 (Code) :https://github.com/TROUBADOUR000/AMD
论文精度:AMDNet
1. 核心思想
- 本文提出了一种名为 **AMD(自适应多尺度分解)**的 MLP-based 框架,专用于时间序列预测(TSF)。
- 其核心思想是,现实世界的时间序列具有复杂的**"多尺度纠缠"(multi-scale entanglement)**特性,而现有的 Transformer 方法(计算昂贵且易过拟合)和 MLP 方法(过于简单)都无法有效建模这一点。
- AMD 框架通过 MDM 模块 将时间序列分解 为多个不同尺度的子序列,通过 DDI 模块 高效建模这些子序列的时序和通道依赖,最后通过 AMS 模块 (一个 MoE 混合专家模型)对这些不同尺度的预测进行自适应加权。
- 这种"分解-交互-自适应合成"的策略,使得 AMD 作为一个 MLP-based 架构,在保持高效率(线性复杂度)的同时,首次在性能上全面超越了 SOTA Transformer 模型(如 PatchTST, iTransformer)。
2. 背景与动机
-
文本角度总结
时间序列预测(TSF)领域目前由 Transformer-based 和 MLP-based 两类方法主导,但两者都存在显著缺陷:
- Transformer-based 方法(如 PatchTST) :
- 优点:擅长捕捉长程依赖。
- 缺点(效率瓶颈) :自注意力机制具有 O ( N 2 ) O(N^2) O(N2) 的平方计算复杂度,导致训练效率低、内存消耗大。
- 缺点(语义鸿沟) :自注意力机制倾向于过度关注"突变点" (Mutation Points),而忽视了平滑的、连续的时序动态 (temporal dynamics),导致过拟合(如图 1 所示)。
- MLP-based 方法(如 DLinear) :
- 优点:计算效率极高(线性复杂度),擅长建模时序动态。
- 缺点(语义鸿沟) :由于其简单的线性映射,存在"信息瓶颈 "(information bottleneck),难以捕捉和区分现实世界中复杂且纠缠在一起的多尺度时间模式(例如,每小时的天气波动 vs. 每月的气候趋势)。
本文的动机 :设计一个新框架,既能拥有 MLP 的高效率 和时序建模能力 ,又能克服其"信息瓶颈",使其能像 Transformer 一样捕捉和建模复杂的多尺度模式。
- Transformer-based 方法(如 PatchTST) :
-
动机图解分析(Figure 1 & 4):
-
图表 A (Figure 1):揭示"多尺度纠缠"与"过拟合"问题
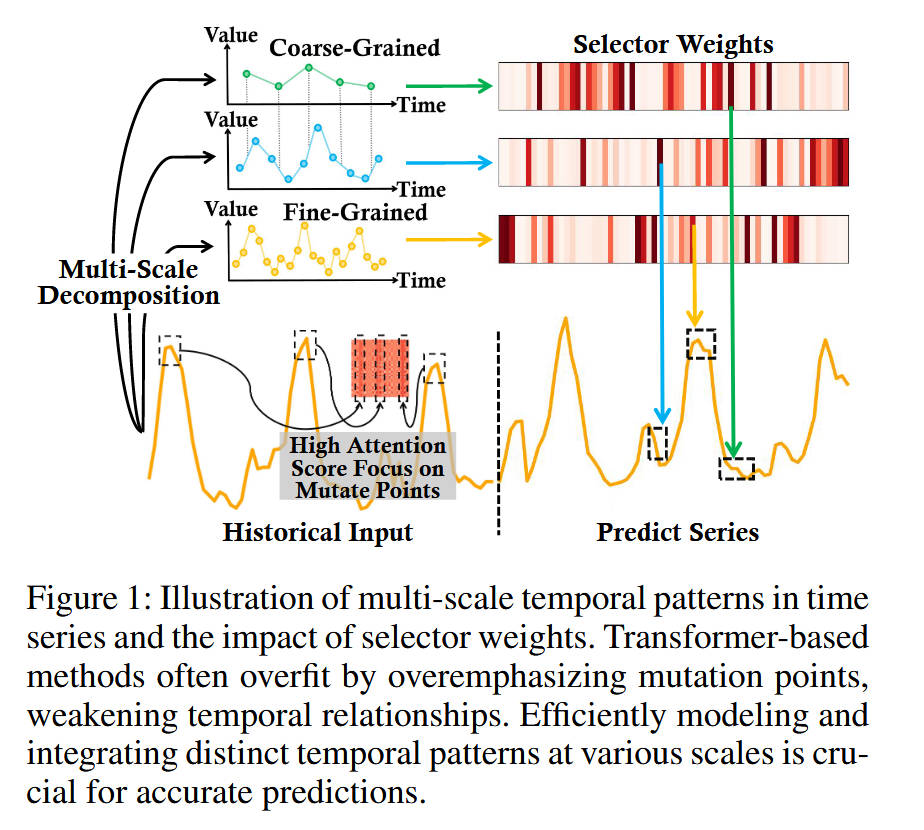
- "看图说话": 这张图是本文的核心动机。左侧的"Historical Input"被(概念上)分解为三种不同尺度的序列:"Coarse-Grained"(粗粒度/趋势)、"Fine-Grained"(细粒度/噪声)和中尺度。
- 分析(语义鸿沟): 现实世界(如右侧
Predict Series)的未来变化是由所有这些尺度的纠缠共同决定的。而现有的 MLP 太简单,无法有效分离这些尺度。 - 分析(效率瓶颈/过拟合): 图的左下角展示了 Transformer 的问题。
High Attention Score(高注意力分数)过度聚焦于"Mutate Points"(突变点/异常值)。这导致模型学到的是"噪声"而非"模式",从而在预测(Predict Series)时产生过拟合,无法捕捉到真实的周期性。 - 结论: Figure 1 提出了两个核心挑战:1) 必须对信号进行多尺度分解 ;2) 必须自适应地聚合这些尺度,而不是像 Transformer 那样过拟合于突变点。
-
图表 B (Figure 4):揭示"通道依赖"的"效率瓶颈"
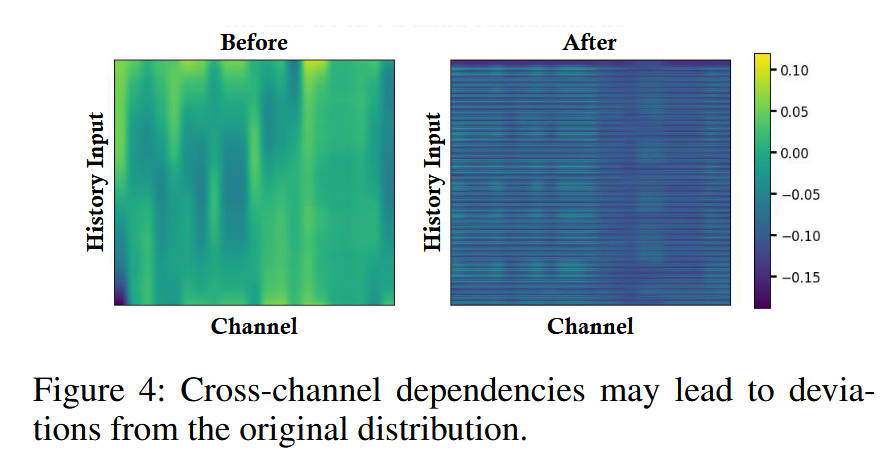
- "看图说话": 这张图对比了引入"跨通道依赖"(Cross-channel dependencies)前后的特征分布热力图。
- 分析: "Before"(左图)是仅考虑时序依赖的特征分布。"After"(右图)是在引入跨通道依赖(即让不同变量相互影响)后的分布。可以清晰地看到,"After"的特征分布被过度平滑 了,导致其偏离了原始分布。
- 结论: 这揭示了一个"效率瓶颈"或"语义鸿沟":在多元时间序列中,天真地混合所有通道(变量)的信息是有害的 ,因为它会引入不相关变量的"噪声",污染目标变量的特征。这直接催生了本文
DDI模块的设计------它必须有一个**控制机制( β \beta β 缩放系数)**来"缓解"这种有害的通道交互。
-
3. 主要贡献点
- 提出 AMD 框架: 提出了一个新颖的、完全基于 MLP 的自适应多尺度分解框架(AMD)。它摒弃了 Transformer 的自注意力机制,通过"分解-交互-合成"三阶段解决了 MLP 无法处理多尺度模式的"信息瓶颈"问题。
- 发明 MDM 模块(多尺度分解混合):
- 这是分解 阶段。
MDM模块使用平均下采样 (AvgPooling)将单条时间序列分解为 h h h 个不同尺度( τ 1 , ... , τ h \tau_1, \dots, \tau_h τ1,...,τh)的子序列(即时间模式)。 - 接着,它通过一个从粗到细(coarse-to-fine)的残差 MLP 路径( ξ i = τ i + M L P ( ξ i + 1 ) \xi_i = \tau_i + MLP(\xi_{i+1}) ξi=τi+MLP(ξi+1))来混合 这些尺度,使得细粒度特征( τ 1 \tau_1 τ1)能够感知到粗粒度( ξ 2 \xi_2 ξ2)的上下文。
- 这是分解 阶段。
- 发明 DDI 模块(双重依赖交互):
- 这是交互 阶段。
DDI是一个高效的 MLP 块,用于处理MDM混合后的特征。 - 它通过两个并行的 MLP(一个作用于时间步,一个作用于通道)来同时建模"时序依赖"(temporal dependencies)和"通道依赖"(channel dependencies)。
- 关键是,它引入了一个缩放系数 β \beta β 来控制通道交互的强度,防止不相关的变量相互干扰(解决了 Figure 4 所示的问题)。
- 这是交互 阶段。
- 发明 AMS 模块(自适应多预测器合成):
- 这是合成 阶段,也是本文最核心的创新。它本质上是一个**混合专家(MoE)**架构。
AMS包含两个组件:一个 **TP-Selector(门控网络)**和 m m m 个并行的Predictor(专家网络)。TP-Selector负责分析MDM提供的多尺度信息,动态生成"选择器权重" S S S(即决定每个尺度/模式对未来预测的"重要性")。- m m m 个
Predictor则分别对DDI处理后的特征进行独立预测。 - 最终输出是所有 m m m 个预测的加权和 ( Y ^ = ∑ S j ⋅ P r e d i c t o r j ( v ) \hat{Y} = \sum S_j \cdot Predictor_j(v) Y^=∑Sj⋅Predictorj(v))。这种 MoE 机制使得 AMD 能自适应地聚焦于"主导的时间模式",而忽略噪声和突变点(解决了 Figure 1 所示的 Transformer 过拟合问题)。
4. 方法细节
-
整体网络架构(Figure 2):
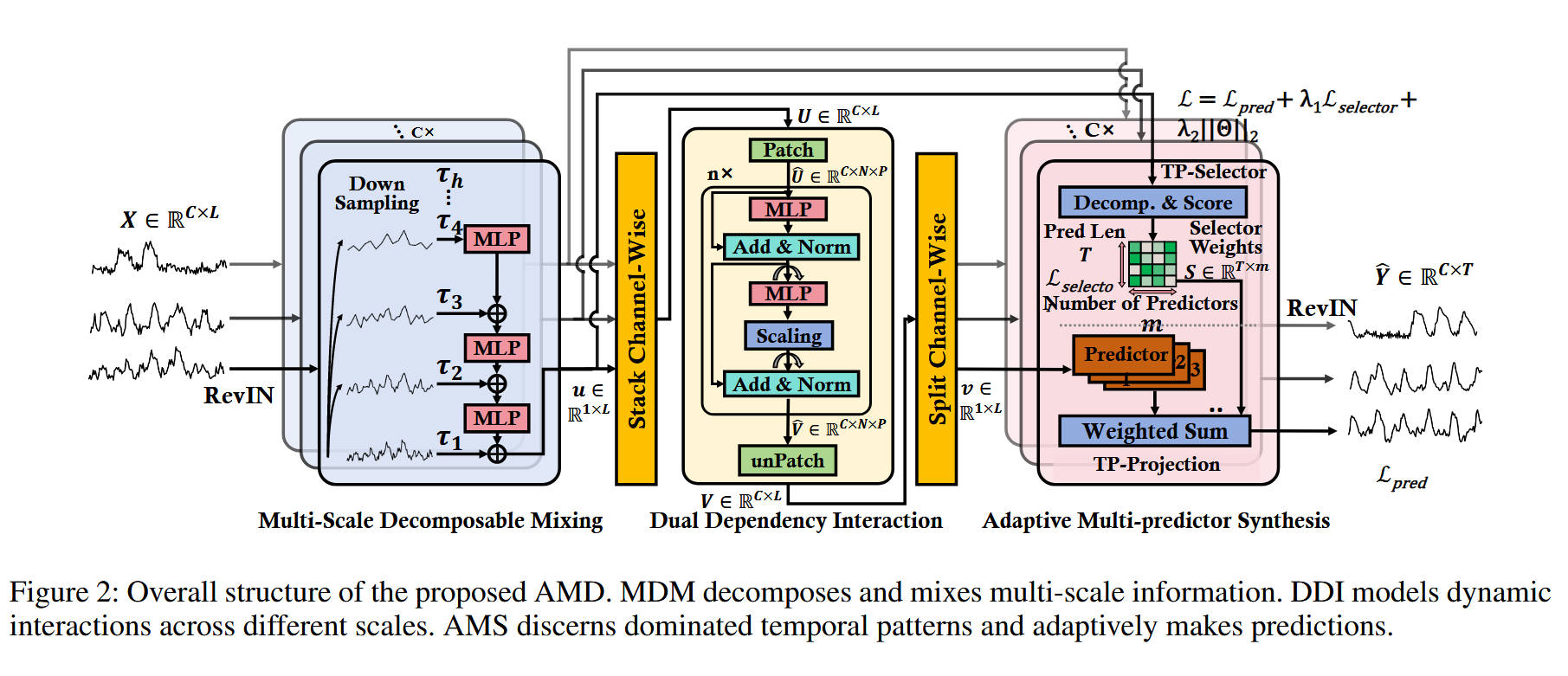
- 模型名称: AMD (Adaptive Multi-Scale Decomposition)
- 数据流: 这是一个**三阶段的串行(Sequential)**架构,完全由 MLP 及其变体构成。
- 输入: X X X( C × L C \times L C×L),首先经过
RevIN(可逆实例归一化)处理。 - 阶段 1:
Multi-Scale Decomposable Mixing(MDM 块 - 分解):- 输入 X X X(逐通道处理,得到 u u u)进入该模块。
- 下采样: 输入 τ 1 \tau_1 τ1 (原始序列) 被
Down Sampling(AvgPooling) 递归 h h h 次,产生 h h h 个不同尺度的序列 τ 1 , τ 2 , ... , τ h \tau_1, \tau_2, \dots, \tau_h τ1,τ2,...,τh。 - 混合: 从最粗粒度的 τ h \tau_h τh 开始,通过
MLP向上(从粗到细)进行残差混合。 ξ h = τ h \xi_h = \tau_h ξh=τh,然后 ξ i = τ i + M L P ( ξ i + 1 ) \xi_i = \tau_i + MLP(\xi_{i+1}) ξi=τi+MLP(ξi+1)。 - 输出: 最终混合了所有尺度信息的特征 ξ 1 \xi_1 ξ1(记为 u u u)被输出。
- 阶段 2:
Dual Dependency Interaction(DDI 块 - 交互):- 堆叠: 来自 MDM 的 C C C 个 u u u( 1 × L 1 \times L 1×L)被堆叠 (Stack Channel-Wise)成一个 U U U( C × L C \times L C×L)矩阵。
- 打补丁 (Patch): U U U 被切分为 N N N 个 Patch。
- 混合: 执行 MLP-Mixer 风格的双重依赖交互(时序 MLP + 通道 MLP + β \beta β 缩放)。
- 输出: 得到 V V V( C × L C \times L C×L),并拆分 (Split Channel-Wise)为 C C C 个 v v v( 1 × L 1 \times L 1×L)输出。
- 阶段 3:
Adaptive Multi-predictor Synthesis(AMS 块 - 合成):- 这是一个 MoE 模块,同时接收 来自 MDM 的 u u u 和来自 DDI 的 v v v。
- 门控路径(TP-Selector): u u u(来自 MDM)进入
TP-Selector。Decomp. & Score模块(包含TopK和Softmax)生成Selector WeightsS S S( m × T m \times T m×T 矩阵, m m m 为专家数, T T T 为预测长度)。 - 专家路径(TP-Projection): v v v(来自 DDI)进入
TP-Projection。它被并行 送入 m m m 个Predictor块(每个都是 MLP)。 - 聚合: m m m 个预测结果根据
Selector WeightsS S S 进行加权求和(Weighted Sum) ,得到最终的 1 × T 1 \times T 1×T 预测 y ~ \tilde{y} y~。
- 输出: 所有通道的预测 Y ^ \hat{Y} Y^ 经过
RevIN(反归一化)得到最终结果。 - 损失函数: L t o t a l = L p r e d + λ 1 L s e l e c t o r + λ 2 ∣ ∣ Θ ∣ ∣ 2 \mathcal{L}{total} = \mathcal{L}{pred} + \lambda_1 \mathcal{L}{selector} + \lambda_2 ||\Theta||2 Ltotal=Lpred+λ1Lselector+λ2∣∣Θ∣∣2。 L p r e d \mathcal{L}{pred} Lpred 是预测的 MSE 损失, L s e l e c t o r \mathcal{L}{selector} Lselector 是一个 MoE 负载均衡损失,用于防止门控网络"过拟合"于少数几个专家。
-
核心创新模块详解:
-
对于 模块 A:MDM (Multi-Scale Decomposable Mixing)
- 理念: 将复杂的时序信号分解为多个不同尺度的简单子模式,然后以"从粗到细"的方式将它们重新组合,使高频细节(细粒度)感知到低频趋势(粗粒度)。
- 数据流:
- 分解 (Decomposition): τ 1 = X c h a n n e l \tau_1 = X_{channel} τ1=Xchannel, τ i = A v g P o o l i n g ( τ i − 1 ) \tau_i = AvgPooling(\tau_{i-1}) τi=AvgPooling(τi−1)。这一步(
Down Sampling)创建了一个特征金字塔,捕捉了从精细( τ 1 \tau_1 τ1)到粗糙( τ h \tau_h τh)的多种时间模式。 - 混合 (Mixing): ξ h = τ h \xi_h = \tau_h ξh=τh。 ξ i = τ i + M L P ( ξ i + 1 ) \xi_{i} = \tau_{i} + MLP(\xi_{i+1}) ξi=τi+MLP(ξi+1)。
- 分解 (Decomposition): τ 1 = X c h a n n e l \tau_1 = X_{channel} τ1=Xchannel, τ i = A v g P o o l i n g ( τ i − 1 ) \tau_i = AvgPooling(\tau_{i-1}) τi=AvgPooling(τi−1)。这一步(
- 设计目的: 这是对传统分解(如趋势-季节分解)的巨大改进。它不是简单地相加,而是通过一个残差 MLP 来学习跨尺度交互 。这使得模型能够理解"月度趋势( ξ i + 1 \xi_{i+1} ξi+1)如何非线性地影响日度波动( τ i \tau_i τi)",从而生成一个对所有尺度都"知情"的特征 u u u。
-
对于 模块 B:DDI (Dual Dependency Interaction)
- 理念: 高效地(用 MLP)同时建模时序(Temporal)和通道(Channel)依赖,同时防止通道间噪声干扰。
- 数据流:
- 输入 U U U ( C × L C \times L C×L) → \rightarrow → Patching → \rightarrow → U ^ \hat{U} U^ ( C × N × P C \times N \times P C×N×P)。
- 时序混合 (Eq 5): Z = U ^ + M L P ( V ^ p r e v ) Z = \hat{U} + MLP(\hat{V}_{prev}) Z=U^+MLP(V^prev)。一个 MLP 在 P P P 维度(时间步)上操作,捕捉时间依赖性。
- 通道混合 (Eq 6): V ^ = Z + β ⋅ M L P ( Z T ) T \hat{V} = Z + \beta \cdot MLP(Z^T)^T V^=Z+β⋅MLP(ZT)T。另一个 MLP 在 C C C 维度(通道)上 操作(通过转置 T T T 实现),捕捉通道依赖性。
- 关键创新 ( β \beta β): β \beta β 是一个缩放系数 (scaling rate)。它控制了通道混合( M L P ( Z T ) T MLP(Z^T)^T MLP(ZT)T)对最终特征 V ^ \hat{V} V^ 的贡献度。
- 设计目的: β \beta β 的存在是为了解决 Figure 4 所示的"分布偏移"问题。如果 β \beta β 很大,模型会过度依赖通道相关性(可能引入噪声);如果 β \beta β 很小,模型会退化为"通道独立"(CI)模式,更关注时序。这使得 DDI 模块可以自适应地平衡"时序"和"通道"信息。
-
对于 模块 C:AMS (Adaptive Multi-predictor Synthesis)
- 理念: 这是一个 MoE(混合专家)模块,用于自适应地聚合来自不同尺度(由 MDM 提取)的预测。
- 数据流:
- 门控(Gating) :
TP-Selector接收 MDM 的输出 u u u( 1 × L 1 \times L 1×L)。它通过一个Decomp. & Score模块(包含 MLP 和 TopK)来分析 u u u 中蕴含的多尺度模式。 Selector WeightsS S S( m × T m \times T m×T)被生成。 S j , t Sj, t Sj,t 代表第 j j j 个专家(Predictor)对于预测未来第 t t t 个时间步的"可信度"或"权重"。- 专家(Experts) :
TP-Projection接收 DDI 的输出 v v v( 1 × L 1 \times L 1×L)。 v v v 被并行 送入 m m m 个独立的PredictorMLP 中。每个Predictor_j都专精于一种特定的时间模式,并输出一个完整的 1 × T 1 \times T 1×T 预测。 - 合成(Synthesis) :最终预测 y ~ \tilde{y} y~( 1 × T 1 \times T 1×T)是这 m m m 个专家预测的加权平均 : y ~ = ∑ j = 0 m S j ⋅ P r e d i c t o r j ( v ) \tilde{y} = \sum_{j=0}^{m} S_j \cdot Predictor_j(v) y~=∑j=0mSj⋅Predictorj(v)。
- 门控(Gating) :
- 设计目的:
AMS解决了 Figure 1 所示的"过拟合突变点"问题。Transformer 可能会被某个突变点"欺骗",而AMS则通过TP-Selector来"投票"。Selector会识别出"突变点"只是一种细粒度模式(例如Predictor 1),而"全局趋势"是另一种粗粒度模式(例如Predictor 2)。通过自适应加权 S S S ,AMS能够更鲁棒地组合这些模式,从而做出更平滑、更准确的预测。
-
-
理念与机制总结:
- AMD 框架在理念上是对 MLP-based TSF 方法的一次重大升级。
- DLinear/RLinear 证明了"单尺度"的 MLP 已经很强。
- TimeMixer 证明了"多尺度分解 + 简单平均"的 MLP 更强。
- AMD(本文) 则证明了"多尺度分解(MDM) + 自适应加权(AMS/MoE)"的 MLP 才是最强的。
- AMD 通过
MDM将复杂问题分解 为 h h h 个尺度,然后通过AMS(一个 MoE)自适应地合成 m m m 个专家的答案。DDI则在此过程中充当了一个高效的特征交互(时序+通道)模块。 - 这种"分解-征服-自适应合成"的策略,使得 AMD 作为一个 MLP 家族成员,成功解决了 MLP 的"信息瓶颈"和 Transformer 的"过拟合"问题。
-
图解总结:
- Figure 1 提出了问题:时间序列具有"多尺度纠缠"特性,而 Transformer 会"过拟合突变点"。
- Figure 4 提出了问题:盲目的"跨通道"依赖会引入噪声,导致"特征分布偏移"。
- Figure 2(左,MDM) 提供了解决方案 1 :通过多尺度分解 (AvgPooling)和从粗到细的 MLP 混合,显式地建模"多尺度纠缠"。
- Figure 2(中,DDI) 提供了解决方案 2 :通过引入缩放系数 β \beta β ,来控制时序混合和通道混合的平衡,解决了"通道噪声"问题。
- Figure 2(右,AMS) 提供了解决方案 3 :通过 MoE 架构(
TP-Selector+Predictors),对 m m m 个专家的预测进行自适应加权,而不是简单平均。这使得模型能聚焦于"主导模式",避免了对"突变点"的过拟合。
5. 即插即用模块的作用
-
本文的
MDM和AMS模块被明确设计并验证为**即插即用(Plug-and-play)**的组件。 -
作用: 它们可以作为一个**"性能增强包",被集成到其他现有的 TSF(尤其是 MLP-based)模型**中。
-
适用场景:
- 增强现有的 MLP-based 模型(如 DLinear, MTS-Mixers):
- 应用: 如 Table 4 所示,作者将
DLinear和MTS-Mixers作为基线,并在其架构中插入 了MDM和AMS模块。 - 优势: 实验证明,
DLinear + MDM & AMS和MTS-Mixers + MDM & AMS的性能(MSE/MAE)相比原始模型均有显著提升。 - 结论: 这表明
MDM提供了原始模型所缺乏的多尺度分解能力 ,而AMS提供了更强大的自适应聚合能力。
- 应用: 如 Table 4 所示,作者将
- 替换 Transformer 中的注意力机制:
- 应用: 理论上,可以将 Transformer 骨干网络(如 PatchTST)中的"自注意力"块替换为
MDM + DDI + AMS的组合。 - 优势: 这将把一个 O ( N 2 ) O(N^2) O(N2) 复杂度的模型转换 为一个 O ( N ) O(N) O(N) 线性复杂度的模型,同时(如实验所示)可能带来性能提升,因为它用 MoE 的自适应聚合替代了自注意力的过拟合倾向。
- 应用: 理论上,可以将 Transformer 骨干网络(如 PatchTST)中的"自注意力"块替换为
- 增强现有的 MLP-based 模型(如 DLinear, MTS-Mixers):
6. 即插即用模块
python
"""
即插即用模块集合 - AMD架构的核心组件
这些模块可以独立使用或组合使用,用于时间序列预测任务
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class RevIN(nn.Module):
"""
可逆实例归一化模块 (Reversible Instance Normalization)
用于时间序列的归一化和反归一化,提高模型的泛化能力
"""
def __init__(self, num_features: int, eps=1e-5, affine=True):
"""
:param num_features: 特征或通道数
:param eps: 数值稳定性参数
:param affine: 是否使用可学习的仿射参数
"""
super(RevIN, self).__init__()
self.num_features = num_features
self.eps = eps
self.affine = affine
if self.affine:
self._init_params()
def forward(self, x, mode: str, target_slice=None):
if mode == 'norm':
self._get_statistics(x)
x = self._normalize(x)
elif mode == 'denorm':
x = self._denormalize(x, target_slice)
else:
raise NotImplementedError
return x
def _init_params(self):
self.affine_weight = nn.Parameter(torch.ones(self.num_features))
self.affine_bias = nn.Parameter(torch.zeros(self.num_features))
def _get_statistics(self, x):
dim2reduce = tuple(range(1, x.ndim - 1))
self.mean = torch.mean(x, dim=dim2reduce, keepdim=True).detach()
self.stdev = torch.sqrt(torch.var(x, dim=dim2reduce, keepdim=True, unbiased=False) + self.eps).detach()
def _normalize(self, x):
x = x - self.mean
x = x / self.stdev
if self.affine:
x = x * self.affine_weight
x = x + self.affine_bias
return x
def _denormalize(self, x, target_slice=None):
if self.affine:
x = x - self.affine_bias[target_slice]
x = x / (self.affine_weight + self.eps * self.eps)[target_slice]
x = x * self.stdev[:, :, target_slice]
x = x + self.mean[:, :, target_slice]
return x
class MDM(nn.Module):
"""
多尺度可分解混合模块 (Multi-Scale Decomposable Mixing)
将输入分解为多个尺度并进行混合,捕获不同时间尺度的信息
"""
def __init__(self, input_shape, k=3, c=2, layernorm=True):
"""
:param input_shape: 输入形状 [seq_len, feature_num]
:param k: 多尺度层数
:param c: 尺度缩放因子
:param layernorm: 是否使用层归一化
"""
super(MDM, self).__init__()
self.seq_len = input_shape[0]
self.k = k
if self.k > 0:
self.k_list = [c ** i for i in range(k, 0, -1)]
self.avg_pools = nn.ModuleList([nn.AvgPool1d(kernel_size=k, stride=k) for k in self.k_list])
self.linears = nn.ModuleList(
[
nn.Sequential(nn.Linear(self.seq_len // k, self.seq_len // k),
nn.GELU(),
nn.Linear(self.seq_len // k, self.seq_len * c // k),
)
for k in self.k_list
]
)
self.layernorm = layernorm
if self.layernorm:
self.norm = nn.BatchNorm1d(input_shape[0] * input_shape[-1])
def forward(self, x):
"""
:param x: [batch_size, feature_num, seq_len]
:return: [batch_size, feature_num, seq_len]
"""
if self.layernorm:
x = self.norm(torch.flatten(x, 1, -1)).reshape(x.shape)
if self.k == 0:
return x
# x [batch_size, feature_num, seq_len]
sample_x = []
for i, k in enumerate(self.k_list):
sample_x.append(self.avg_pools[i](x))
sample_x.append(x)
n = len(sample_x)
for i in range(n - 1):
tmp = self.linears[i](sample_x[i])
sample_x[i + 1] = torch.add(sample_x[i + 1], tmp, alpha=1.0)
# [batch_size, feature_num, seq_len]
return sample_x[n - 1]
class DDI(nn.Module):
"""
双依赖交互模块 (Dual Dependency Interaction)
建模不同尺度之间的动态交互关系
"""
def __init__(self, input_shape, dropout=0.2, patch=12, alpha=0.0, layernorm=True):
"""
:param input_shape: 输入形状 [seq_len, feature_num]
:param dropout: dropout率
:param patch: patch大小
:param alpha: 特征交互权重
:param layernorm: 是否使用层归一化
"""
super(DDI, self).__init__()
# input_shape[0] = seq_len input_shape[1] = feature_num
self.input_shape = input_shape
if alpha > 0.0:
self.ff_dim = 2 ** math.ceil(math.log2(self.input_shape[-1]))
self.fc_block = nn.Sequential(
nn.Linear(self.input_shape[-1], self.ff_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(self.ff_dim, self.input_shape[-1]),
nn.GELU(),
nn.Dropout(dropout),
)
self.n_history = 1
self.alpha = alpha
self.patch = patch
self.layernorm = layernorm
if self.layernorm:
self.norm = nn.BatchNorm1d(self.input_shape[0] * self.input_shape[-1])
self.norm1 = nn.BatchNorm1d(self.n_history * patch * self.input_shape[-1])
if self.alpha > 0.0:
self.norm2 = nn.BatchNorm1d(self.patch * self.input_shape[-1])
self.agg = nn.Linear(self.n_history * self.patch, self.patch)
self.dropout_t = nn.Dropout(dropout)
def forward(self, x):
"""
:param x: [batch_size, feature_num, seq_len]
:return: [batch_size, feature_num, seq_len]
"""
# [batch_size, feature_num, seq_len]
if self.layernorm:
x = self.norm(torch.flatten(x, 1, -1)).reshape(x.shape)
output = torch.zeros_like(x)
output[:, :, :self.n_history * self.patch] = x[:, :, :self.n_history * self.patch].clone()
for i in range(self.n_history * self.patch, self.input_shape[0], self.patch):
# input [batch_size, feature_num, self.n_history * patch]
input = output[:, :, i - self.n_history * self.patch: i]
# input [batch_size, feature_num, self.n_history * patch]
input = self.norm1(torch.flatten(input, 1, -1)).reshape(input.shape)
# aggregation
# [batch_size, feature_num, patch]
input = F.gelu(self.agg(input)) # self.n_history * patch -> patch
input = self.dropout_t(input)
# input [batch_size, feature_num, patch]
# input = torch.squeeze(input, dim=-1)
tmp = input + x[:, :, i: i + self.patch]
res = tmp
# [batch_size, feature_num, patch]
if self.alpha > 0.0:
tmp = self.norm2(torch.flatten(tmp, 1, -1)).reshape(tmp.shape)
tmp = torch.transpose(tmp, 1, 2)
# [batch_size, patch, feature_num]
tmp = self.fc_block(tmp)
tmp = torch.transpose(tmp, 1, 2)
output[:, :, i: i + self.patch] = res + self.alpha * tmp
# [batch_size, feature_num, seq_len]
return output
class TopKGating(nn.Module):
"""
Top-K门控机制
用于选择最重要的专家进行预测
"""
def __init__(self, input_dim, num_experts, top_k=2, noise_epsilon=1e-5):
"""
:param input_dim: 输入维度
:param num_experts: 专家数量
:param top_k: 选择的top-k专家数
:param noise_epsilon: 噪声epsilon
"""
super(TopKGating, self).__init__()
self.gate = nn.Linear(input_dim, num_experts)
self.top_k = top_k
self.noise_epsilon = noise_epsilon
self.num_experts = num_experts
self.w_noise = nn.Parameter(torch.zeros(num_experts, num_experts), requires_grad=True)
self.softplus = nn.Softplus()
self.softmax = nn.Softmax(1)
def decompostion_tp(self, x, alpha=10):
"""
Top-K分解函数
:param x: [batch_size, num_experts]
:param alpha: 分解参数
:return: [batch_size, num_experts]
"""
# x [batch_size, seq_len]
output = torch.zeros_like(x)
# [batch_size]
kth_largest_val, _ = torch.kthvalue(x, self.num_experts - self.top_k + 1)
# [batch_size, num_expert]
kth_largest_mat = kth_largest_val.unsqueeze(1).expand(-1, self.num_experts)
mask = x < kth_largest_mat
x = self.softmax(x)
output[mask] = alpha * torch.log(x[mask] + 1)
output[~mask] = alpha * (torch.exp(x[~mask]) - 1)
# [batch_size, seq_len]
return output
def forward(self, x):
"""
:param x: [batch_size, seq_len]
:return: [batch_size, num_experts] 门控权重
"""
# [batch_size, seq_len]
x = self.gate(x)
clean_logits = x
# [batch_size, num_experts]
if self.training:
raw_noise_stddev = x @ self.w_noise
noise_stddev = ((self.softplus(raw_noise_stddev) + self.noise_epsilon))
noisy_logits = clean_logits + (torch.randn_like(clean_logits) * noise_stddev)
logits = noisy_logits
else:
logits = clean_logits
logits = self.decompostion_tp(logits)
gates = self.softmax(logits)
return gates
class Expert(nn.Module):
"""
专家网络
单个预测器,用于处理特定的时间模式
"""
def __init__(self, input_dim, output_dim, hidden_dim, dropout=0.2):
"""
:param input_dim: 输入维度
:param output_dim: 输出维度
:param hidden_dim: 隐藏层维度
:param dropout: dropout率
"""
super(Expert, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
"""
:param x: [batch_size, input_dim]
:return: [batch_size, output_dim]
"""
return self.net(x)
class AMS(nn.Module):
"""
自适应多预测器合成模块 (Adaptive Multi-predictor Synthesis)
根据时间模式自适应选择并组合多个预测器
"""
def __init__(self, input_shape, pred_len, ff_dim=2048, dropout=0.2, loss_coef=1.0, num_experts=4, top_k=2):
"""
:param input_shape: 输入形状 [seq_len, feature_num]
:param pred_len: 预测长度
:param ff_dim: 前馈网络维度
:param dropout: dropout率
:param loss_coef: 损失系数
:param num_experts: 专家数量
:param top_k: top-k专家数
"""
super(AMS, self).__init__()
# input_shape[0] = seq_len input_shape[1] = feature_num
self.num_experts = num_experts
self.top_k = top_k
self.pred_len = pred_len
self.gating = TopKGating(input_shape[0], num_experts, top_k)
self.experts = nn.ModuleList(
[Expert(input_shape[0], pred_len, hidden_dim=ff_dim, dropout=dropout) for _ in range(num_experts)])
self.loss_coef = loss_coef
assert (self.top_k <= self.num_experts)
def cv_squared(self, x):
"""
计算变异系数的平方,用于负载均衡损失
"""
eps = 1e-10
# if only num_experts = 1
if x.shape[0] == 1:
return torch.tensor([0], device=x.device, dtype=x.dtype)
return x.float().var() / (x.float().mean() ** 2 + eps)
def forward(self, x, time_embedding):
"""
:param x: [batch_size, feature_num, seq_len]
:param time_embedding: [batch_size, feature_num, seq_len] 时间嵌入
:return: output [batch_size, feature_num, pred_len], loss 负载均衡损失
"""
# [batch_size, feature_num, seq_len]
batch_size = x.shape[0]
feature_num = x.shape[1]
# [feature_num, batch_size, seq_len]
x = torch.transpose(x, 0, 1)
time_embedding = torch.transpose(time_embedding, 0, 1)
output = torch.zeros(feature_num, batch_size, self.pred_len).to(x.device)
loss = 0
for i in range(feature_num):
input = x[i]
time_info = time_embedding[i]
# x[i] [batch_size, seq_len]
gates = self.gating(time_info)
# expert_outputs [batch_size, num_experts, pred_len]
expert_outputs = torch.zeros(self.num_experts, batch_size, self.pred_len).to(x.device)
for j in range(self.num_experts):
expert_outputs[j, :, :] = self.experts[j](input)
expert_outputs = torch.transpose(expert_outputs, 0, 1)
# gates [batch_size, num_experts, pred_len]
gates = gates.unsqueeze(-1).expand(-1, -1, self.pred_len)
# batch_output [batch_size, pred_len]
batch_output = (gates * expert_outputs).sum(1)
output[i, :, :] = batch_output
importance = gates.sum(0)
loss += self.loss_coef * self.cv_squared(importance)
# [feature_num, batch_size, seq_len]
output = torch.transpose(output, 0, 1)
# [batch_size, feature_num, seq_len]
return output, loss
def test_modules():
"""
测试所有即插即用模块的功能
"""
print("=" * 60)
print("开始测试即插即用模块...")
print("=" * 60)
# 设置随机种子
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}\n")
# 测试参数
batch_size = 4
seq_len = 96
feature_num = 7
pred_len = 24
# 1. 测试 RevIN
print("1. 测试 RevIN 模块")
print("-" * 60)
revin = RevIN(num_features=feature_num).to(device)
x_revin = torch.randn(batch_size, seq_len, feature_num).to(device)
x_norm = revin(x_revin, mode='norm')
x_denorm = revin(x_norm, mode='denorm', target_slice=slice(None))
print(f"输入形状: {x_revin.shape}")
print(f"归一化后形状: {x_norm.shape}")
print(f"反归一化后形状: {x_denorm.shape}")
print(f"RevIN 测试通过 ✓\n")
# 2. 测试 MDM
print("2. 测试 MDM 模块")
print("-" * 60)
mdm = MDM(input_shape=(seq_len, feature_num), k=3, c=2, layernorm=True).to(device)
x_mdm = torch.randn(batch_size, feature_num, seq_len).to(device)
x_mdm_out = mdm(x_mdm)
print(f"输入形状: {x_mdm.shape}")
print(f"输出形状: {x_mdm_out.shape}")
print(f"MDM 测试通过 ✓\n")
# 3. 测试 DDI
print("3. 测试 DDI 模块")
print("-" * 60)
ddi = DDI(input_shape=(seq_len, feature_num), dropout=0.1, patch=12, alpha=0.5, layernorm=True).to(device)
x_ddi = torch.randn(batch_size, feature_num, seq_len).to(device)
x_ddi_out = ddi(x_ddi)
print(f"输入形状: {x_ddi.shape}")
print(f"输出形状: {x_ddi_out.shape}")
print(f"DDI 测试通过 ✓\n")
# 4. 测试 TopKGating
print("4. 测试 TopKGating 模块")
print("-" * 60)
topk_gating = TopKGating(input_dim=seq_len, num_experts=4, top_k=2).to(device)
x_gating = torch.randn(batch_size, seq_len).to(device)
gates = topk_gating(x_gating)
print(f"输入形状: {x_gating.shape}")
print(f"门控权重形状: {gates.shape}")
print(f"门控权重和: {gates.sum(dim=1)}") # 应该接近1.0
print(f"TopKGating 测试通过 ✓\n")
# 5. 测试 Expert
print("5. 测试 Expert 模块")
print("-" * 60)
expert = Expert(input_dim=seq_len, output_dim=pred_len, hidden_dim=512, dropout=0.1).to(device)
x_expert = torch.randn(batch_size, seq_len).to(device)
x_expert_out = expert(x_expert)
print(f"输入形状: {x_expert.shape}")
print(f"输出形状: {x_expert_out.shape}")
print(f"Expert 测试通过 ✓\n")
# 6. 测试 AMS
print("6. 测试 AMS 模块")
print("-" * 60)
ams = AMS(input_shape=(seq_len, feature_num), pred_len=pred_len,
ff_dim=512, dropout=0.1, num_experts=4, top_k=2).to(device)
x_ams = torch.randn(batch_size, feature_num, seq_len).to(device)
time_emb = torch.randn(batch_size, feature_num, seq_len).to(device)
x_ams_out, moe_loss = ams(x_ams, time_emb)
print(f"输入形状: {x_ams.shape}")
print(f"时间嵌入形状: {time_emb.shape}")
print(f"输出形状: {x_ams_out.shape}")
print(f"MoE损失: {moe_loss.item():.6f}")
print(f"AMS 测试通过 ✓\n")
# 7. 测试模块组合
print("7. 测试模块组合 (完整流程)")
print("-" * 60)
# 模拟完整的前向传播流程
x_combined = torch.randn(batch_size, seq_len, feature_num).to(device)
# RevIN归一化
x_combined = revin(x_combined, mode='norm')
# 转置为 [batch, feature, seq]
x_combined = x_combined.transpose(1, 2)
# MDM处理
time_embedding = mdm(x_combined)
# DDI处理
x_combined = ddi(x_combined)
# AMS预测
pred, loss = ams(x_combined, time_embedding)
# 转回 [batch, pred_len, feature]
pred = pred.transpose(1, 2)
# RevIN反归一化
pred = revin(pred, mode='denorm', target_slice=slice(None))
print(f"组合输入形状: {x_combined.shape}")
print(f"组合输出形状: {pred.shape}")
print(f"组合MoE损失: {loss.item():.6f}")
print(f"模块组合测试通过 ✓\n")
print("=" * 60)
print("所有模块测试完成!✓")
print("=" * 60)
return True
if __name__ == '__main__':
# 运行测试
test_modules()