利用现有的云端或自部署大模型,配合AI应用框架,我们能快速搭建属于自己的企业级AI应用,JAVA应用体系中,Spring AI和LangChain4j都是目前较为成熟的框架方案。
在这些封装级框架基础上,如何实践,如何搭架适合业务需求的AI应用级框架,是每一个企业或业务总线会考虑的问题。本文将以Spring AI为基础,搭建一套简单的可按需拓展的AI助手为例展开实践描述。
注:本实践基于能源管理运营行业,AI定位趋向于为客服AI助手,涉及内容仅基础应用实现和接口参考,无关具体业务和更详细的架构描述;本文实践的"智能体"更准确描述应为简版工作流。
github开源工程:https://github.com/endcy/base-ai-assistant
基于spring-boot、spring-ai、spring-ai-alibaba实现的RAG、MCP、Agent智能体基础服务框架应用;智能客服、智能运维、智能助手、简单工作流/垂直领域智能体的基础应用架构版本,按需拓展。
基础界面&API示例
注:接口随项目需求自定义实现,当前部分接口仅供测试验证参考。
管理和API演示界面(部分接口应用)

文档内容管理

接口调用
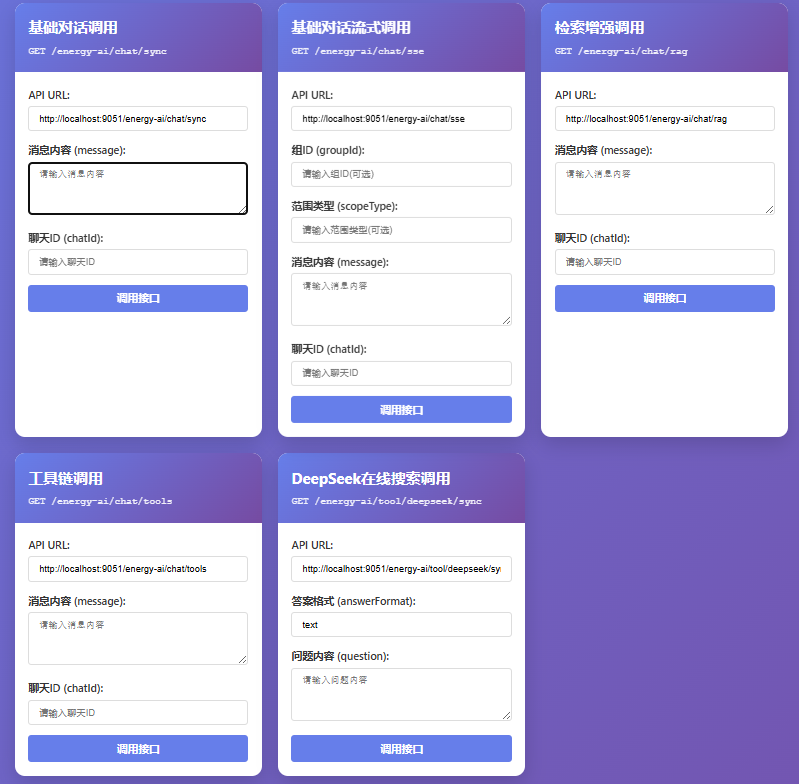
注:上述页面为静态html文件,由AI生成。
应用背景
在具备一定业务量的平台系统中,无论是客户对接还是普通用户服务(下文统称用户),客服功能/模块必不可缺,基于普通的QA文档点选、对外电话客服、在线服务号沟通,甚至是工单系统,可能没办法统一精准、及时解决各类问题,服务大打折扣。在更大体量的平台应用中,用户可能提出更加专业,甚至是具有一定分析工作量的问题,很显然普通的客服手段,解决问题能力似乎捉襟见肘或者需加大真实人力投入,成本提升明显。
拥有一款智能的客服,能显著降低运营成本,提高系统服务对接吞吐量,让产品到运营整体周期闭环,更重要的是拥有AI赋能,拓展价值无限可能,可显著提高产品市场竞争力。
|-------------|-----------|----------|----------------|------------|
| 客服类型 | 用户友善度 | 执行效率 | 解决问题范围 | 使用维护成本 |
| 电话客服 | 不够友善且难等待 | 视人工专业情况 | 所有问题 | 无 |
| 文档点选 | 十分不友善 | 效率较高但效果差 | 仅支持常见问题记录 | 低 |
| 异步工单/社交渠道客服 | 十分不友善 | 效率极低 | 所有问题 | 高 |
| 在线人工客服 | 简洁友善 | 视人工专业情况 | 所有问题 | 中 |
| AI客服 | 简洁友善 | 效率较高 | 所有问题(视文档维护积累量) | 前期高后期低 |
基础需求分析
-
用户基础QA问
-
客户增量文档维护和检
-
用户实时信息查
-
运维信息分
-
特定场景的数据决策
基础版本功能
-
基础对话
-
DeepSeek在线搜索对话
-
本地模型调用
-
在线AI应用调用
-
在线LLM调用
-
在线知识库检索增强
-
本地文档检索增强
-
数据库文档检索增强
-
数据库文档管理
-
mcp验证
-
工具链验证
系统总体设计
总体流程设计
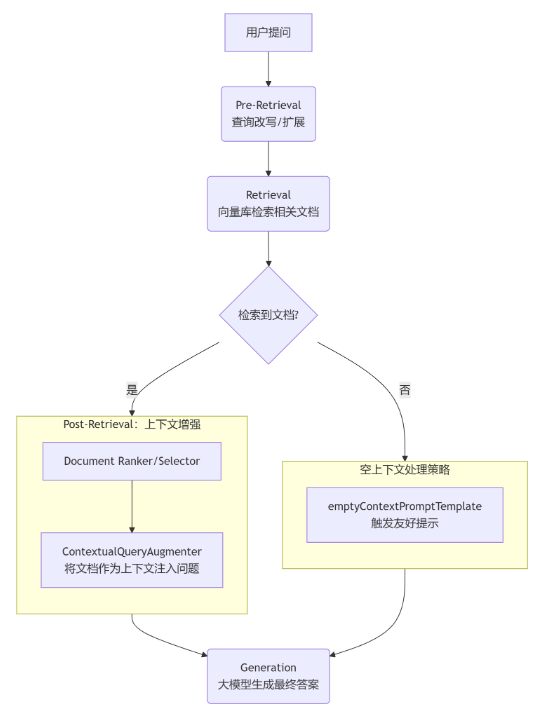
用户提问到输出回答内容,中间涉及意图分析、MCP数据补充、RAG检索增强、提示词工程、大模型调用输出等,完整流程图如下。
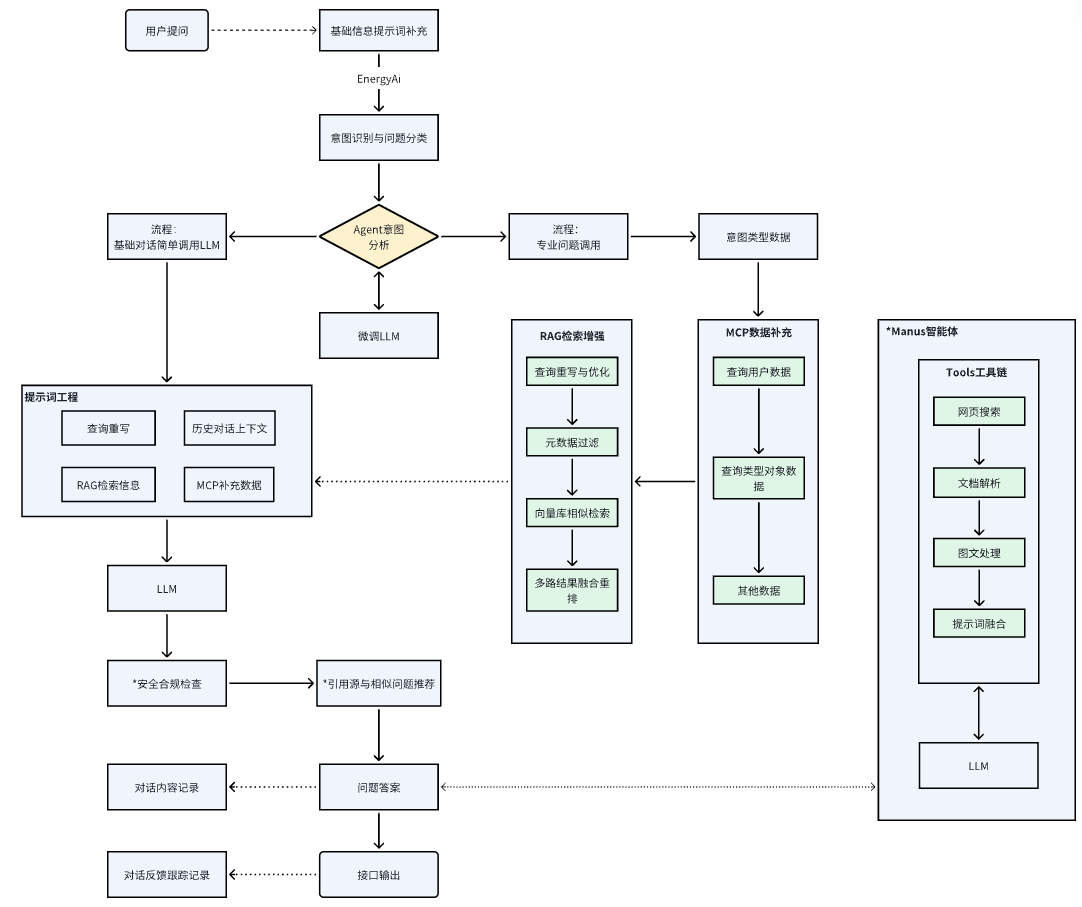
MCP应用适合于RAG之外的数据增强,作为AI与外部系统的"通用接口",实现工具标准化调用,定义MCP功能可以包含例如用户需要获取天气数据、获取节假日信息等等功能,也可用于类似做数据预测前的条件数据查询,如目标温度湿度等时序数据、电网定价信息等等。
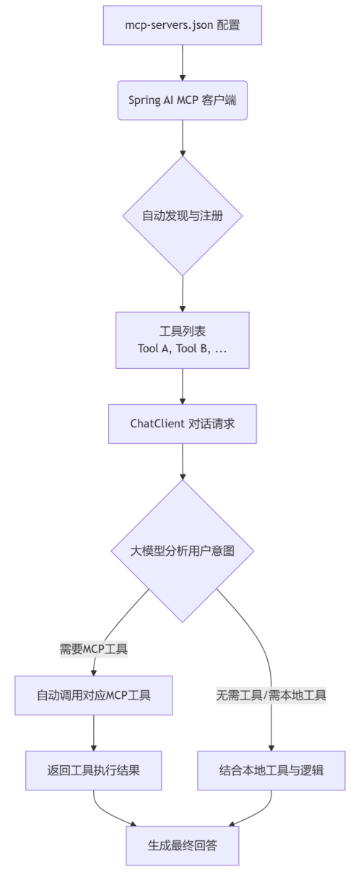
MCP和Tools的关系:
-
MCP是一种标准化的通信协议,Spring AI通过McpSyncToolCallbackProvider等实现类将MCP协议的工具映射为ToolCallback接口的实现。
-
Tools是调用工具的定义,无论底层使用什么协议(MCP、Function Calling等),由LLM意图识别之后框架自动选择调用。
Tools及MCP定义的要点
-
清晰的工具描述:
@Tool和@ToolParam的description务必准确、清晰,这是大模型判断是否调用和如何填参的主要依据。 -
严格的参数模式:正确定义工具的输入参数以生成框架可读 JSON Schema,确保大模型能生成格式正确的参数。
-
合理的工具设计:每个工具应功能单一且明确,避免过于复杂的功能,这有助于大模型做出更精准的决策。
数据架构设计
数据库文档管理使用的数据库可选,这里使用其他工程已用的MYSQL作为内容管理库,PGSQL作为文档向量库,其中文档支持本地md文档,自定义拓展也可支持其他格式文档。
工程中数据库支持多数据源。
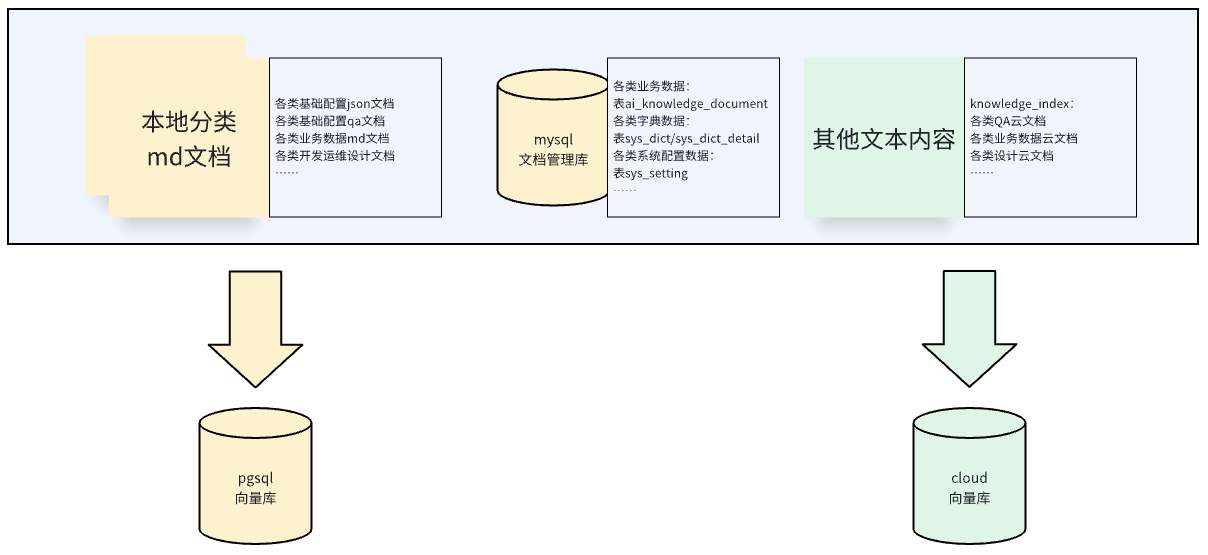
上述数据云文档为在线文档库的数据管理。实际使用过程中,localVectorStore和pgVectorStore文档向量数据,可能和cloudVectorStore(云知识库)数据存在冲突,为避免维护困难,工程中通过开关实现分开验证。
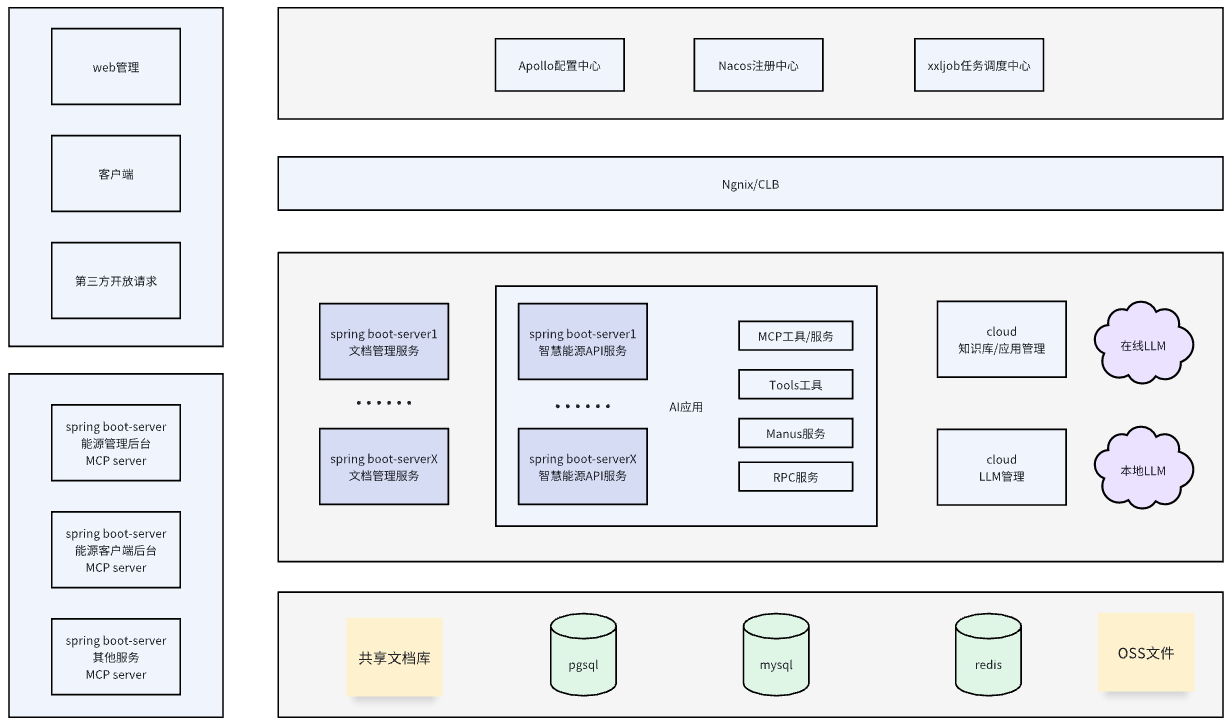
程序架构设计
本项目采用Spring Boot + Spring AI为基础底座,微服务应用的形式管理,支持水平扩容。
- 注册中心采用Nacos/阿里云MSE;
- 配置中心采用Apollo,可自定义按需变更为Nacos;
- 任务调度中心框架xxl-job;
- mysql/pgsql多数据源支持;
- 微服务调用框架支持Dubbo、Feign;
- 微服务熔断工具支持resilience4j。
程序架构设计图如下:
RAG检索增强设计
为啥不用类似Dify、RagFlow、Anything-LLM等本地RAG知识文档库的LLM工具?
变化不频繁的文档或特定文档如单纯运维工具文档,适合使用上述框架RAG工具,但无论他们解析结构化还是非结构化文档,本质上都是解析内容后加入向量库,但文档维护无法做到saas一样灵活,且针对线上应用,理论上格式没那么多遍,使用内容管理而不是一股脑上传文档的维护效果更好,就可预见的功能需求而言,Spring AI + DB可用性更高,更契合需求要求。
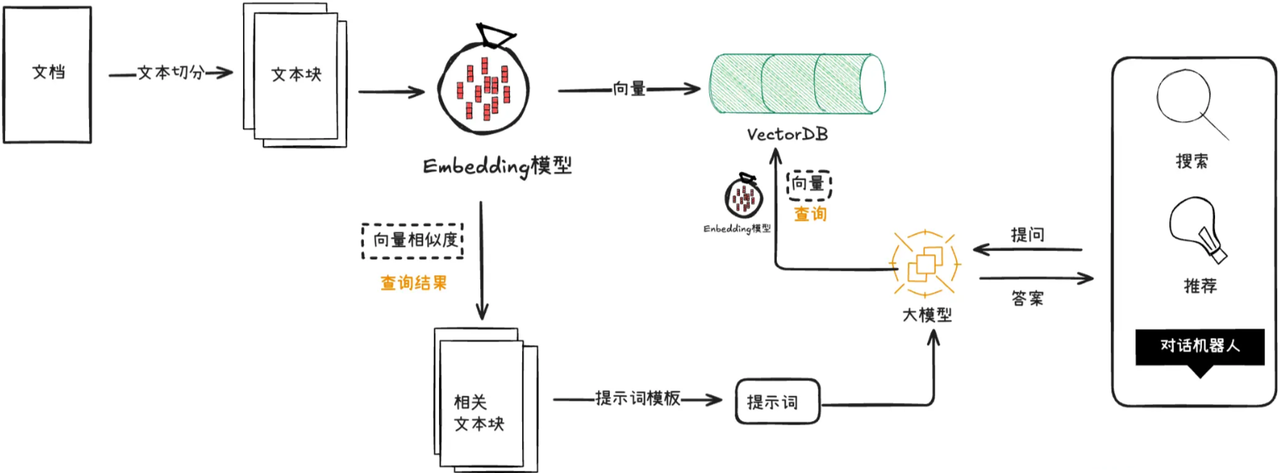
参考"数据架构设计",Rag文档来源支持多样化,云知识库文档由云服务自动解析加载向量,这里仅讨论本地文档和知识管理数据库的文档RAG流程。
文档分割器
定义DocumentTokenTextSplitter初始化文档分割器,分为三种选型实现,本工程使用自定义优化实现。
-
基于固定token范围的TokenTextSplitter分割器,指定token上下浮动分片,英文的文档效果好点,中文文档基本有效;
-
基于语义断句的SentenceSplitter分割器,效果不佳,基于格式严格的英文的文档效果好点,中文文档可用性大打折扣;
-
自定义实现ChineseEnhancedTextSplitter分割器,优化TokenTextSplitter的实现,主要优化标点符号分隔(CHINESE_SEPARATORS参数按需更新),支持中文更加友好。
文档向量库
-
pg向量库PgVectorStore,存储管理后端维护的知识库文档表文档向量数据;
-
内存向量库SimpleVectorStore,存储指定路径分类或指定resources目录的本地文档向量;
-
云文档检索库DashScopeDocumentRetriever,针对云文档库文档检索,向量由云文档应用管理;
查询改写
查询改写即优化查询的表达形式,提升检索效果,能一定程度提高当前查询的检索召回率和精度,本工程使用QueryTransformer配合ChatModel,定义QueryRewriter,将用户问题文本变更为更易查询的RAG目标参数文本。
文档召回配置
配置ai.rag相关参数,实现自定义配置类ChatRagProperties,设定rag参数,默认向量相似度0.6,召回数为3;
自定义多条件Filter.Expression生成工具,支持多条件的元数据查询。
架构LLM工具选型
大模型
dashscope大模型
支持定义阿里百炼平台云端模型,可按需更新为其他平台,模型暂选定qwen3-max,按需更新。
模型token量暂无监控,由运维跟踪。
ollama本地模型
按需部署需要的模型,验证阶段使用qwen3:8b ,本地运行因为涉及硬件配置的考虑,可按需更新。线上基于线上ollama的运行环境,如需要独立部署大模型,可租赁GPU资源,参考阿里团队建议,生产使用部署最少需32b参数及以上的模型。
模型微调
在用户问题的意图识别,以及其他分类时,微调模型更加精准和高效,不浪费云端模型token,最重要的是垂直领域做简单分类正是微调模型的强项。针对本地的qwen3模型,适当做微调处理,微调方案按需选择,如阿里百炼微调、LLaMA-Factory、ModelScope(swift)等等,一般租借云显卡和环境进行微调。
微调模型语料可参考各开源datasets,根据格式将内容更新为自己的语料库,语料收集较为繁杂,但是微调必不可少的前期步骤。
语料数据集是关键!!!语料数据集是关键!!!语料数据集是关键!!!
使用阿里百炼在线微调
参考 阿里云模型调优操作
使用Swift或其他平台微调
swift或其他微调平台微调,自行参考,过程存在一定难度但作为生产级应用很有必要,本文不做具体操作描述。
工具链工具库
AI工作流的执行包含了N个工具的串行或并行任务,大模型根据工具获取到的结果,执行后续操作,最终得到结果。优秀的工具库工具,是智能的前提,可使用MCP协议工具或本地工具,其中MCP包含网络发布的MCP或者自定义的MCP工具。
本工程验证实现的工具参考如下列表,建议按需直接复用网络上其他开发者写好和实践过的工具,进一步减少重复造轮子。
-
网页抓取工具
-
关键词在线搜索工具
-
文件读写操作工具
-
DeepSeek在线搜索工具
-
......
MCP框架选择
这里指的是,业务应用服务暴露mcp端点给本AI应用,前者开发mcp服务应该用到的框架。市场上存在两个java较为常用的 mcp-server 应用开发框架(ID类,封装后体验都比较简洁):
-
spring-ai-mcp,支持 java17 或以上
-
solon-ai-mcp,支持 java8 或以上(也支持集成到 springboot2, jfinal, vert.x 等第三方框架)
|-------|-------------------------------|-----------------------|
| 比较 | srping-ai-mcp | solon-ai-mcp |
| 开发 | 基于组件开发 | 基于组件开发 |
| 配置 | 通过 yaml 配置 | 组件,即是配置(也可引用 yaml 配置) |
| 发布 | 通过配置器发布为 ToolCallbackProvider | 组件,即是发布 |
| jdk要求 | jdk17或以上 | jdk8或以上 |
| 端点支持 | WebFlux支持多端点;普通MVC单端点 | 支持多端点(一个服务内) |
solon-ai-mcp的开发相对更简洁,三位一体且支持多端点。业务服务集群创建mcp服务时,应根据jdk版本或具体服务容器进行选择。
MCP开发特别注意事项
参考github描述
远程MCP开发流程
参考github描述
数据结构设计
知识文档数据
云文档知识库
使用ModeScope的应用加载和检索文档,即线上RAG应用,支持配置模型、元数据配置、文档分割方式等等配置,文档库需专人将知识内容文件化并手动上传和维护文档。
本工程使用Alibaba Spring Ai作为基础框架,所以默认支持阿里云百炼平台知识库应用。
本地知识库文档
本地也支持类似dify等rag框架的本地文档管理,实现了工程resources源文件的文档库、指定目录的文档库等实现。但局限于文档文件管理的复杂性,以及本系统无需支持过多的文档格式,所以该文档库方式也仅作为参考实现。

数据库知识文档
区别于云知识库以及本地各类格式文件的知识库文档,数据库知识文档数据是文件数据数据库存储的一种形式,更为方便管理,也便于展示和实时维护。前端定义支持图文的文档编辑器,将内容存储到后端对应数据表,数据表的每一行数据则对应一份文档。
该表信息属性中,内容的属性为 content ,文本内容描述,例如某个菜单页面操作指南、某个设计文档全内容或某个章节、某个业务数据信息描述(例如XXX站点信息)等等。
作为元数据的属性包含:id、scope_type、business_type、group_id、source_type、source_path等,作为元数据过滤或者补充信息展示等。
知识库文档表:ai_knowledge_document
|---------------|-----------------------------|--------------|-------|-------|
| 列名 | 注释 | 数据类型 | 非空 | 自增 |
| id | 自增主键 | bigint | TRUE | TRUE |
| scope_type | 知识领域类型 | varchar(255) | TRUE | FALSE |
| business_type | 业务领域类型 | varchar(255) | TRUE | FALSE |
| title | 内容标题 | varchar(255) | TRUE | FALSE |
| group_id | 内容分组id,如租户id | bigint | FALSE | FALSE |
| content | 精细化文档内容(Markdown/纯文本) | longtext | TRUE | FALSE |
| source_type | 来源类型(1-文档 2-数据库 3-api 0-未知) | varchar(255) | TRUE | FALSE |
| source_path | 文件路径或API地址 | varchar(512) | FALSE | FALSE |
| doc_version | 文档版本号 | int | FALSE | FALSE |
| enable_public | 是否公开 | tinyint(1) | FALSE | FALSE |
| loaded | 是否已加载到向量库 | tinyint(1) | FALSE | FALSE |
| enabled | 是否可用 | tinyint(1) | FALSE | FALSE |
| expired_time | 过期时间 | datetime | FALSE | FALSE |
| create_user | 创建人 | bigint | FALSE | FALSE |
| create_time | 创建时间 | datetime | FALSE | FALSE |
| update_user | 更新人 | bigint | FALSE | FALSE |
| update_time | 更新时间 | datetime | FALSE | FALSE |
可按需拓展数据库知识文档属性,或新增其他知识库文档表。
对话内容数据
针对用户会话数据的存储,工程应该将用户对话持久化到文档或者数据表中。这里仅描述存储到数据库的对话信息实现的数据格式。由于上下文相关内容存储会十分冗余,所以不考虑存储rag检索的关联文档内容以及用户上下文信息。
用户对话记录表:ai_context_user_record
|---------------|--------------|--------------|-------|-------|
| 列名 | 注释 | 数据类型 | 非空 | 自增 |
| id | 主键 | bigint | TRUE | TRUE |
| chat_id | 对话id | bigint | TRUE | FALSE |
| user_id | 知识领域类型 | bigint | FALSE | FALSE |
| user_type | 1普通用户 2客户租户 | tinyint(1) | FALSE | FALSE |
| group_id | 用户分组id,如租户id | bigint | FALSE | FALSE |
| scope_type | 知识领域类型 | varchar(255) | FALSE | FALSE |
| business_type | 业务领域类型,意图分类 | varchar(255) | FALSE | FALSE |
| question | 用户对话问题 | longtext | TRUE | FALSE |
| content | 用户对话输出结果 | longtext | FALSE | FALSE |
| enabled | 是否展示 | tinyint(1) | FALSE | FALSE |
| create_time | 创建时间 | datetime | FALSE | FALSE |
| update_time | 更新时间 | datetime | FALSE | FALSE |
向量存储
知识文档向量化存储,用于用户问题使用文本向量相似度检索知识文档关联性查询,本工程使用本地结构或者pgsql向量库实现,向量库建表时使用通用的向量数据表结构,Spring AI或其他框架默认定义方式,仅元数据根据平台业务设计差异化区分。
一份文件知识文档、知识数据表行数据通过内容分割后,可对应多份向量数据。
|-----------|---------------|------|--------------------|---------|
| 列名 | 数据类型 | 非空 | 默认值 | 注释 |
| id | uuid | TRUE | uuid_generate_v4() | |
| content | text | TRUE | NULL | 原始文本内容 |
| metadata | json | TRUE | NULL | 元数据 |
| embedding | public.vector | TRUE | NULL | 1024维向量 |
示例工程声明
- 本示例应用仅展示基础功能的实现,更复杂的智能体、具体的工作流、更精细化的RAG等需根据实际业务情况按需更新;
- 开源工程中涉及的代码内容部分参考来源于网络,如部分工具Tool的定义等;
- 前端页面按需更新,本文展示的内容源于AI生成;
- 部分观点或代码描述内容等需根据依赖更新或者权威来源做更新解释,本文作者不再另行更新描述。