TL;DR
- 场景:实时/时序 OLAP,亿级明细,低延迟看板与多维分析。
- 结论:按时间 Chunk→Segment 列存 + Roll-up + Bitmap 索引 + mmap + 多级缓存;索引服务 Overlord/MiddleManager/Peon 负责摄入与任务。
- 产出:存储/查询机制要点、检查清单、常见坑位修复思路。

数据存储
Druid的数据存储架构
Druid中的数据存储采用分层逻辑结构,主要包含以下几个层次:
1. DataSource(数据源)
- 概念类比:DataSource类似于关系型数据库(RDBMS)中的Table或数据表
- 功能定位:作为数据的顶层容器,一个DataSource包含特定业务领域的所有相关数据
- 示例:电商网站可能创建"user_behavior"、"product_inventory"等DataSource来存储不同业务数据
2. Chunk(时间块)
- 时间分区:每个DataSource的数据按照时间范围划分,形成Chunk
- 分区粒度:可根据业务需求配置不同的时间粒度:
- 常见配置:天(1d)、小时(1h)、周(1w)等
- 示例:按天分区时,2023-01-01就是一个独立的Chunk
- 查询优势:这种按时间划分的结构使时间范围查询非常高效
3. Segment(数据段)
- 物理存储:Segment是数据的实际物理存储单元,每个Segment都是一个独立文件
- 数据规模:一个Segment通常包含几百万行数据(约500万行)
- 文件特性:Segment文件采用列式存储格式,具有压缩和索引特性
- 并行处理:Druid可以并行加载和处理多个Segment
数据分布机制
- 时间顺序:Segment严格按照时间先后顺序组织在Chunk中
- 分布式存储:Segment会被分布式存储在Druid集群的多个节点上
- 副本机制:为确保高可用,每个Segment会有多个副本(通常2-3个)存储在不同节点
查询优化
- 时间过滤:查询时系统首先确定涉及的时间范围(Chunk)
- Segment筛选:然后只加载相关Chunk中的Segment文件
- 性能优势:这种机制大幅减少了需要扫描的数据量,特别适合时间序列数据分析场景
实际应用示例
- 监控系统:每分钟生成一个Segment,每小时形成一个Chunk
- IoT数据处理:按设备ID+时间双重维度组织Segment
- 广告分析:每天创建一个Chunk,按广告主ID进一步细分Segment
通过这种分层存储结构,Druid能够高效处理大规模时间序列数据,同时保持良好的查询性能。
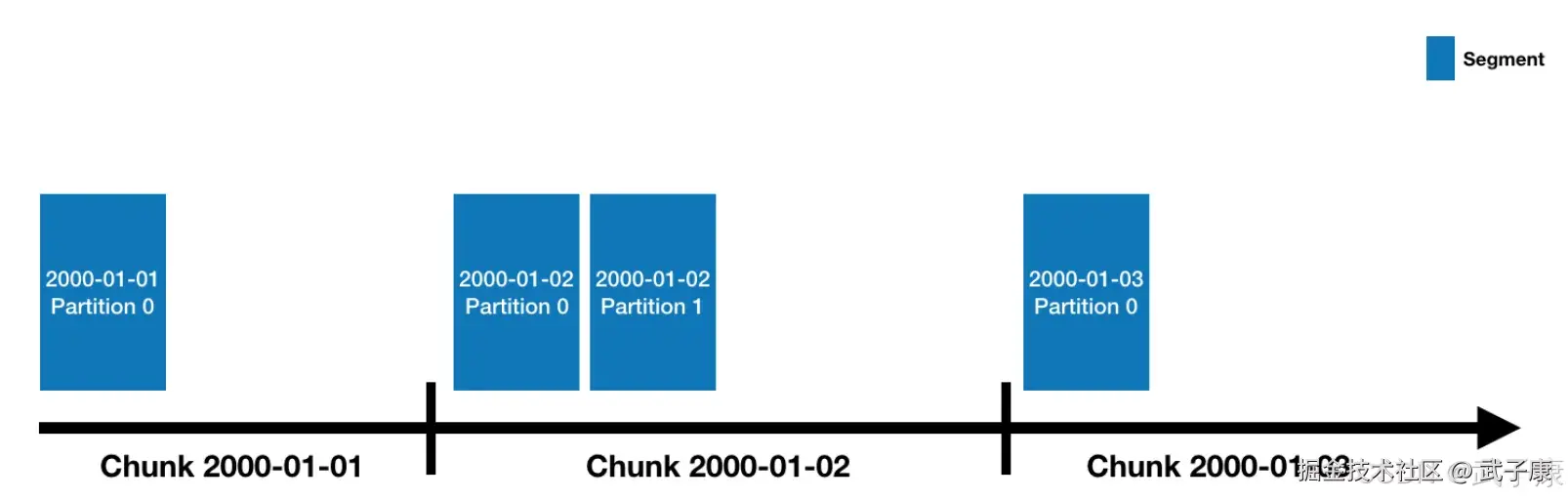
数据分区
- Druid处理的是事件数据,每条数据都会带有一个时间戳,可以使用时间进行分区
- 上图指定了分区粒度为天,那么每天的数据都会被单独存储和查询
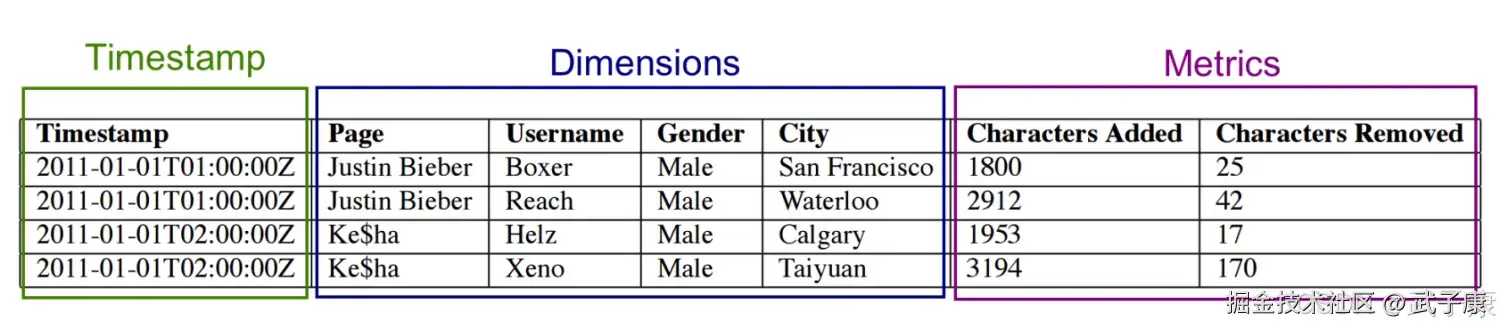
Segment内部存储
- Druid采用列式存储,每列数据都是在独立的结构中存储
- Segment中的数据类型主要分为三种:
- 类型1 时间戳:每一行数据,都必须有一个TimeStamp,Druid一定会基于事件戳来分片
- 类型2 维度列:用来过滤Fliter或者组合GroupBY的列,通过是String、Float、Double、Int类型
- 类型3 指标列:用来进行聚合计算的列,指定的聚合函数 sum、average等
 MiddleManger节点接受到Ingestion的任务之后,开始创建Segment:
MiddleManger节点接受到Ingestion的任务之后,开始创建Segment:
- 转换成列式存储格式
- 用bitmap来建立索引(对所有的dimension列建立索引)
- 使用各种压缩算法
- 算法1:所有的使用 LZ4 压缩
- 算法2:所有的字符串采用字典编码、标识以达到最小化存储
- 算法3:对位图索引使用位图压缩
Segment创建完成之后,Segment文件就是不可更改的,被写入到深度存储(目的是为了防止MiddleManager节点宕机后,Segment丢失)。然后Segment加载到Historicaljiedian,Historical节点可以直接加载到内存中。 同时,Metadata store 也会记录下这个新创建的Segment的信息,如结构、尺寸、深度存储的位置等等 Coordinator节点需要这些元数据来协调数据的查找。
索引服务
索引服务是数据导入并创建Segment数据文件的服务 索引服务是一个高可用的分布式服务,采用主从结构作为架构模式,索引服务由三大组件构成:
- overlord 作为主节点
- MiddleManage作为从节点
- peon用于运行一个Task
索引服务架构图如下图所示: 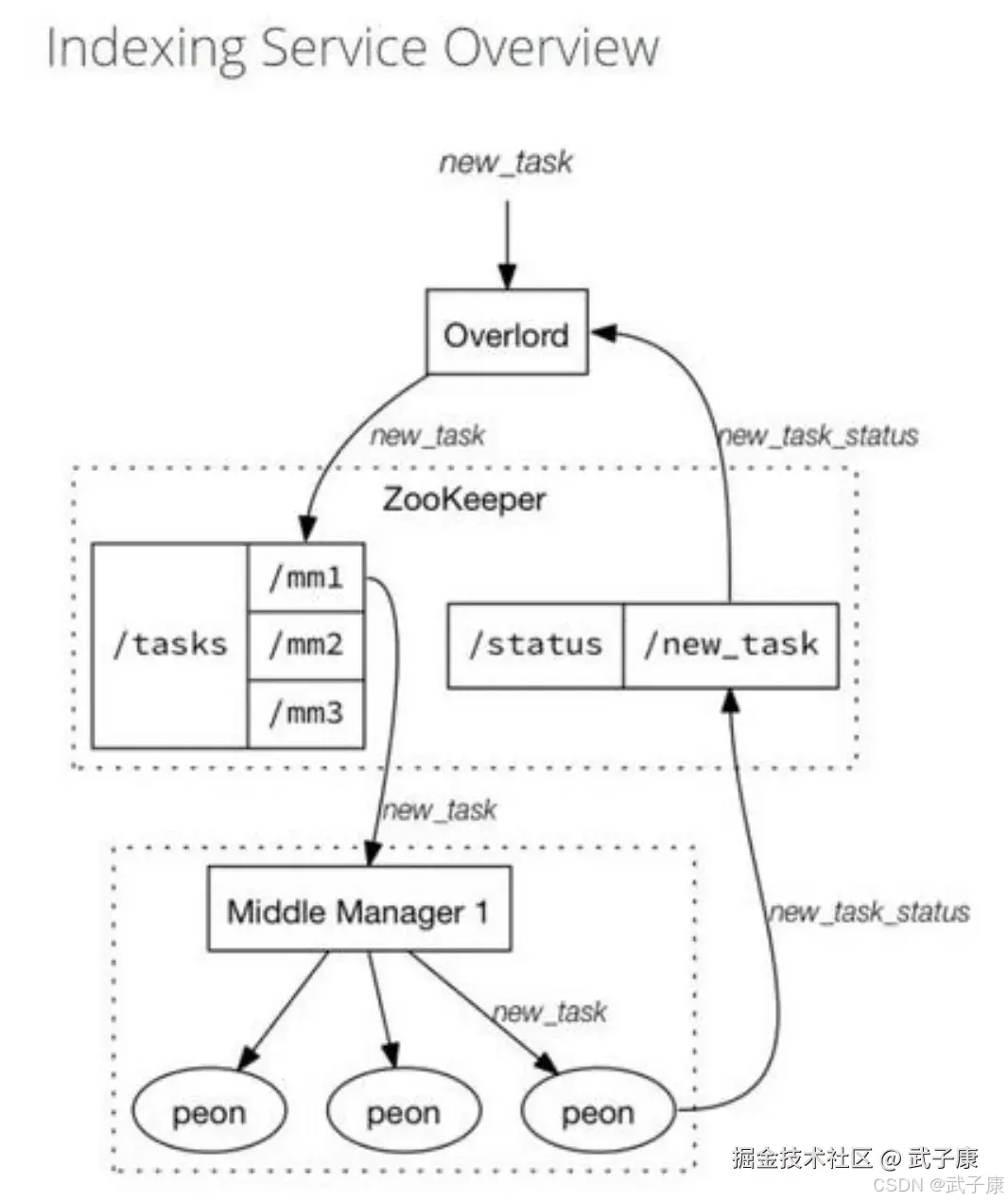
服务构成
Overlord组件
负责创建Task、分发Task到MiddleManger上运行,为Task创建锁以及跟踪Task运行状态并反馈给用户
MiddleManager组件
作为从节点,负责接收主节点分配的任务,然后为每个Task启动一个独立的JVM进程来完成具体的任务
Peon(劳工)组件
由 MiddleManager 启动的一个进程用于一个Task任务的运行
对比YARN
- Overlord 类似 ResourceManager 负责集群资源管理和任务分配
- MiddleManager 类似 NodeManager 负责接收任务和管理本节点的资源
- Peon 类似 Container 执行节点上具体的任务
Task类型
- index hadoop task:Hadoop索引任务,利用Hadoop集群执行MapReduce任务以完成Segment数据文件的创建,适合体量较大的Segments数据文件的创建任务
- index kafka task:用于Kafka数据的实时摄入,通过Kafka索引任务可以在Overlord上配置一个KafkaSupervisor,通过管理Kafka索引任务的创建和生命周期来完成Kafka数据的摄取
- merge task:合并索引任务,将多个Segment数据文件按照指定的聚合方法合并为一个segments数据文件
- kill task:销毁索引任务,将执行时间范围内的数据从Druid集群的深度存储中删除
Druid高性能查询机制详解
Druid之所以能够实现低延迟、高性能的查询,主要依赖于以下五个关键技术点:
1. 数据预聚合
Druid在数据摄入阶段就进行预聚合处理,这显著减少了查询时需要处理的数据量。系统支持多种聚合方式:
- 计数(count)
- 求和(sum)
- 最大值(max)
- 最小值(min)
- 近似基数(hyperloglog)等 例如,针对网站访问日志数据,Druid可以在数据摄入时就预先计算好每分钟的PV、UV等指标,避免查询时进行全量计算。
2. 列式存储与数据压缩
Druid采用列式存储架构,配合多种压缩算法:
- 字符串类型:字典编码(dictionary encoding)压缩
- 数值类型:
- 位压缩(bit compression)
- LZ4压缩
- ZSTD压缩 这种存储方式不仅减少了I/O操作,还能显著提高压缩率,例如时间戳列通常可以获得10倍以上的压缩比。
3. Bitmap索引
Druid为每个维度列都建立了Bitmap索引:
- 对每个维度值生成对应的bitmap
- 支持快速的AND/OR/NOT等位运算
- 特别适合高基数维度的过滤查询 例如,对"浏览器类型"维度进行"Chrome OR Firefox"的查询,可以直接通过bitmap的OR运算快速定位到相关数据行。
4. 内存文件映射(mmap)
Druid使用mmap技术来访问磁盘数据:
- 将索引文件和数据文件映射到内存地址空间
- 操作系统自动管理内存页的加载和回收
- 避免传统I/O的系统调用开销
- 支持热数据的自动缓存 这种机制使得查询可以像访问内存一样快速,同时由操作系统智能管理缓存。
5. 查询结果缓存
Druid实现了多级缓存机制:
- 中间结果缓存:存储部分查询结果
- 查询结果缓存:完整查询结果的缓存
- 支持基于时间的缓存失效策略
- 对于相同查询模式的重复请求可立即返回 例如,仪表盘常见的"最近1小时数据"查询,在缓存有效期内可直接返回结果,无需重新计算。
数据预聚合
- Druid 通过一恶搞RollUp的处理,将原始数据在注入的时候就进行了汇总处理
- RollUp可以压缩我们需要保存的数据量
- Druid会把选定的相同维度的数据进行聚合操作,可以存储的大小
- Druid可以通过queryGranularity来控制注入数据的粒度,最小的queryGranularity是millisecond(毫秒级别)
Roll-Up
聚合前: 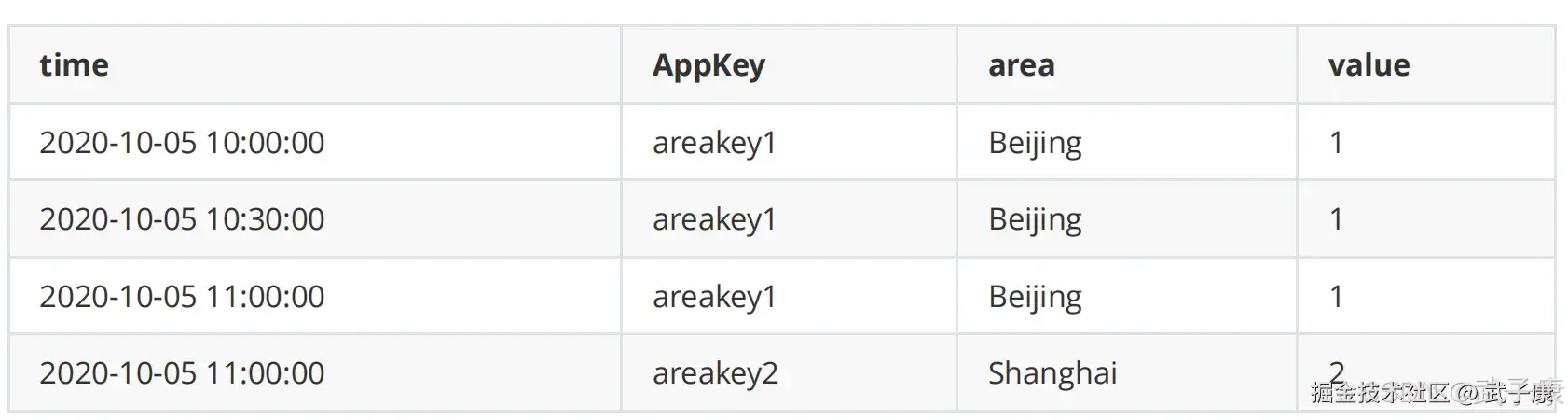 聚合后:
聚合后: 
位图索引
Druid在摄入的数据示例: 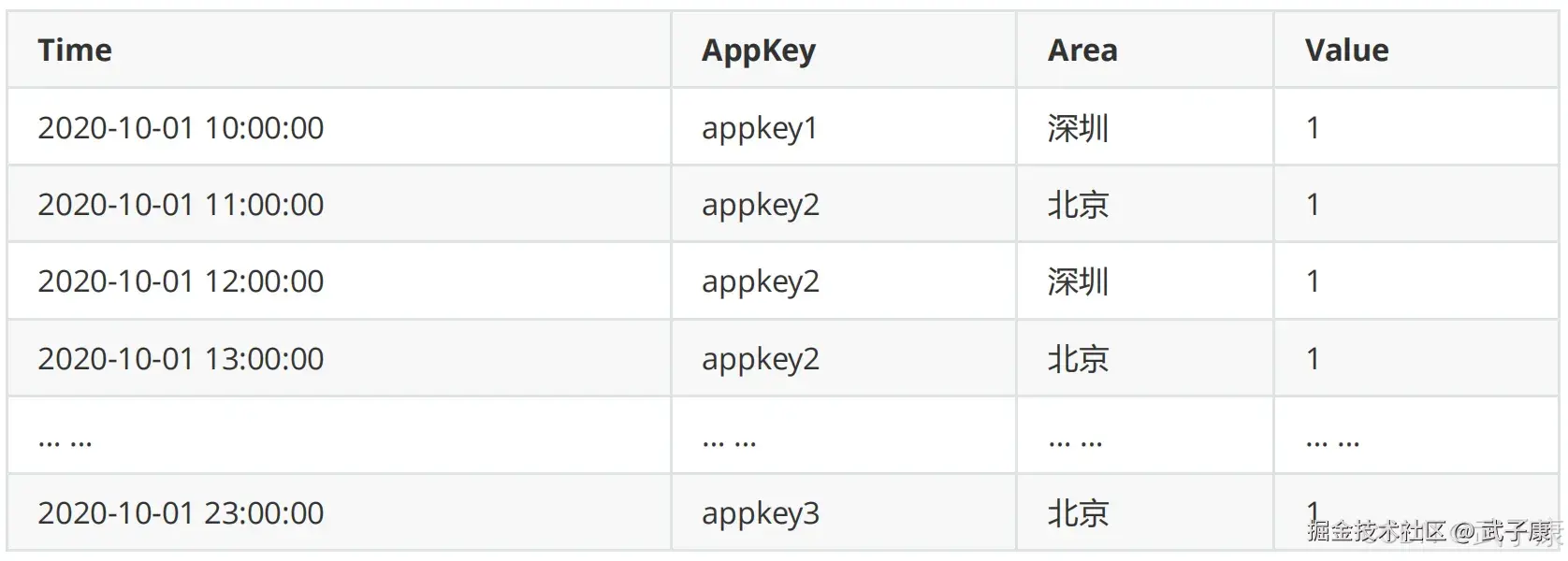
- 第一列为时间,Appkey和Area都是维度列,Value为指标列
- Druid会在导入阶段自动对数据进行RollUp,将维度相同组合的数据进行聚合处理
- 数据聚合的粒度根据业务需要确定
按天聚合后的数据如下:  Druid通过建立位图索引,实现快速数据查找。 BitMap索引主要为了加速查询时有条件过滤的场景,Druid生成索引文件的时候,对每个列的每个取值生成对应的BitMap集合:
Druid通过建立位图索引,实现快速数据查找。 BitMap索引主要为了加速查询时有条件过滤的场景,Druid生成索引文件的时候,对每个列的每个取值生成对应的BitMap集合: 
索引位图可以看作是:HashMap<String, BitMap>
- Key就是维度的值
- Value就是该表中对应的行是否有该维度的值
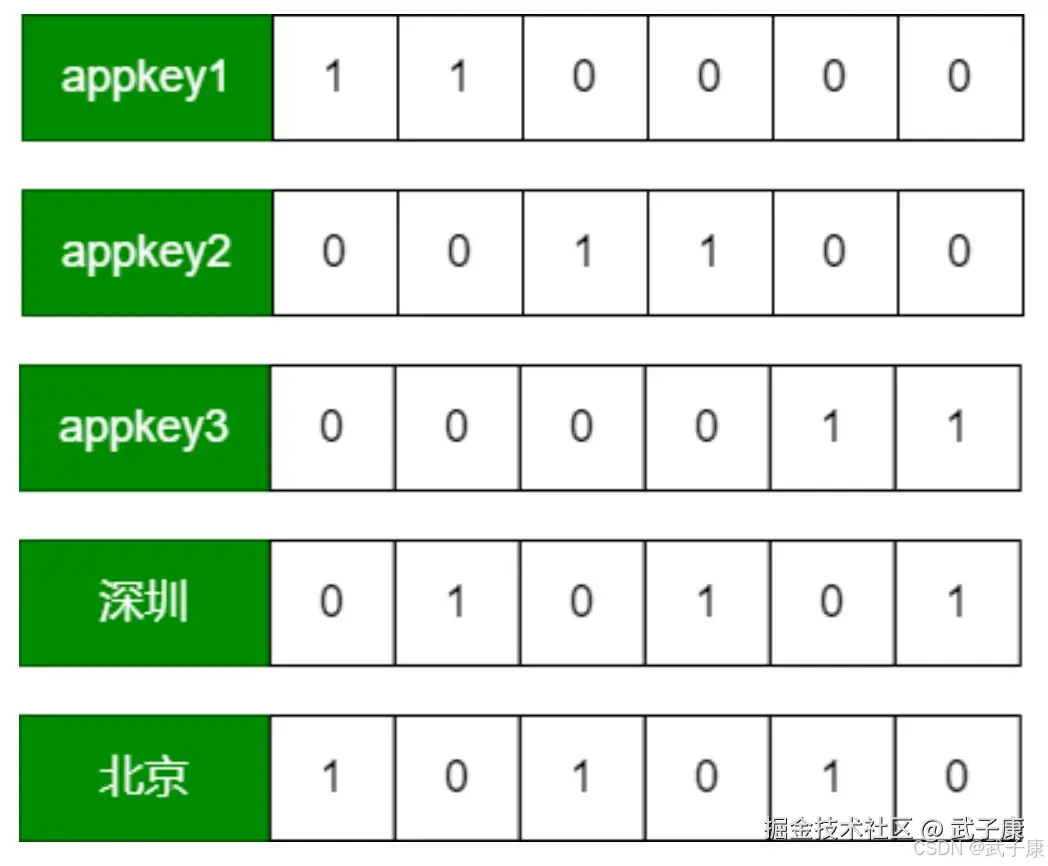
SQL查询
sql
SELECT sum(value) FROM tab1
WHERE time='2020-01-01'
AND appkey in ('appkey1', 'appkey2')
AND area='北京'执行过程分析:
- 根据时间段定位到Segment
- appkey in ('appkey1', 'appkey2') and area='北京' 查到各自的bitmap
- (appkey1 or appkey2)and 北京
- (110000 or 001100) and 101010 = 111100 and 101010 = 101000
- 符合条件的列为:第一行 & 第三行,这几行 sum(value)的和为40
GroupBy查询
sql
SELECT area, sum(value)
FROM tab1
WHERE time='2020-01-01'
AND appkey in ('appkey1', 'appkey2')
GROUP BY area该查询与上面的查询不同之处在与将符合条件的列:
- appkey1 or appkey2
- 110000 or 001100 = 111100
- 将第一行到第四行取出来
- 在内存中做分组聚合,结果为:北京40、深圳60
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 任务成功但查询为空 | interval/时区不匹配,segmentGranularity 与 queryGranularity 混淆 | 查看 task 日志中的 intervals;用 SQL 检查 __time 过滤 | 统一时区;修正 interval;重建 Segment |
| Task failed to acquire lock | 多任务写同一 timeChunk 锁冲突 | Overlord UI/日志看锁与并发 | 拆分 interval/分区;序列化写入或升维分区键 |
| Rejected segment / overshadowed | 版本/规则覆盖导致拒绝 | Coordinator 规则与 segment 版本对比 | 调整 Load/Drop 规则或重置 version,重新发布 |
| Historical 不加载新段 | 深度存储路径/凭据错误或规则未命中 | Historical 日志 "Failed to download segment";Rules 页 | 修正存储配置/权限;补充加载规则并回填 |
| Direct buffer memory OOM | MaxDirectMemorySize 偏小或并发过高 | 查看 hs_err / JVM 日志关键字 | 增大 Direct Memory;调小 processing.buffer/threads |
| GroupBy 内存不足/超时 | v2 spill 配置不足或数据倾斜 | Broker/Historical 日志与 query context | 开启/增大磁盘溢写;提升限额或改 Timeseries/TopN |
| 过滤命中差/慢 | 维度未建索引/高基数策略不当 | Segment metadata 查看列与索引 | 为常用维度建 bitmap / 使用 sketch;优化 schema |
| 无法解析时间 | 时间格式/字段映射错误 | timestampSpec 校验样例数据 | 修正 format/时区;设置 secondarySpec |
| Kafka 摄入落后 | 分区少/并行度低/变换耗时 | Supervisor 状态与 lag 指标 | 提升 task 并行与分区;下推过滤/精简 transform |
| Can not vectorize filter | 不可向量化函数/表达式 | Broker 日志报错点 | 替换函数或允许非向量化执行;评估代价 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-127 Qwen2.5-Omni 深解:Thinker-Talker 双核、TMRoPE 与流式语音
💻 Java篇持续更新中(长期更新)
Java-174 FastFDS 从单机到分布式文件存储:实战与架构取舍 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 正在更新,深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解