近几年一些大型游戏开始支持光线追踪渲染 ,在设置中开启光追后,画质能有明显的提升。但要实现这种实时的光追渲染 并不简单,其不仅需要游戏中编写了相关的算法及程序 ,更需要你的电脑硬件支持。
但光追算法特殊,且计算量大,普通GPU是无法达成实时渲染要求的,目前各处理器厂商都是搭配专门的实时光线追踪加速硬件 进行支持,比如NVIDIA的RT Cores,AMD的Ray Accelerator等等。
这篇文章我们主要理清实时光追加速硬件的大致结构和其实现原理 ,会偏向于广度,略过一些详细部分。因为光线追踪加速硬件是对光线追踪算法的实现,所以下面先对光线追踪算法 做一些提及,再梳理硬件的知识。
1 光线追踪技术
光线追踪是一种模拟现实世界,光线在场景中多次反射、折射 的一个过程。所以光追算法里,物体所受光照除了主要来自光源直接照射外,还来自其它间接的光线。若能考虑到足够数量的间接光线,就可以得到更真实的渲染效果。
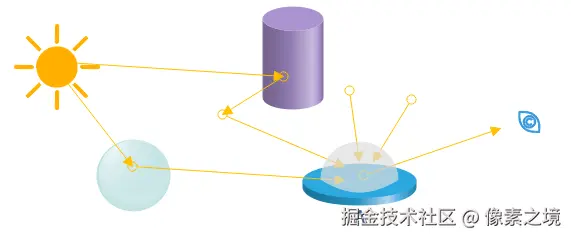
光线追踪属于全局光照技术的一种,起初较为完善的是"基于Whitted"风格的光线追踪,后续学者们在其基础上改善,衍生出许多其它算法,如:光子映射、梅特波利斯光照传输、双向路径追踪等。它们核心的步骤如下:
- 构建场景树 :将场景按空间、物体(三角形组成)划分为一颗树形数据保存,方便第2步使用。
- 光线求交 :光线从光源出发,在场景树中查找,判断是与哪一个物体相交,计算具体的交点。
- 光照效果计算:在相交点处要计算光线的辐射强度、亮度,进行微面元模拟、菲涅尔效果等等,记录这条光线光照效果。
- 生成次级光线 :交点处要根据物体材质产生次级光线(反射、折射、阴影光线),光线能量衰减到阈值,或者进入摄像机后结束。
- 着色计算:每条光线都重复2,3,4步骤,直到所有的光线在场景中完成传播和计算。每个点的着色由其上方半空间内所有光线积分得到。
耗时的部分:
- 光线与基元的求交:每秒数十亿的光线,数百万的三角形场景,每条光线要计算与哪个三角形相交,这个数量非常庞大。
- 点的着色:每个光线相交点需要计算辐射度、能量衰减、菲涅尔效果等,最终每个像素点还要对其上半空间的光线进行积分(一条光线包括其从光源多次反射折射)得到最终颜色。这一系列计算非常复杂。
以上说的只是大概思想,具体算法会有所变化,再对应到光追硬件又会有所简化,具体在提到相关硬件架构时细述。
2 光线追踪管线
光线追踪管线是对光线追踪技术 实现过程的一个抽象,总体使用基于Whitted风格的光线追踪。现有的光追硬件多数都按照一个过程实现。
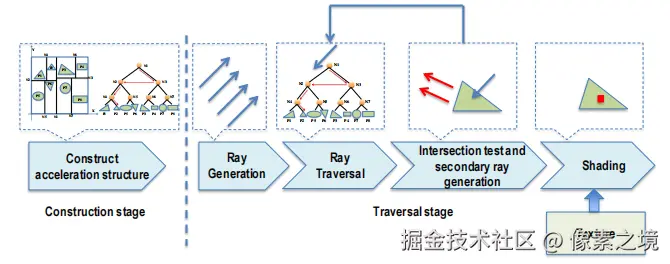
- 加速结构构建 :将给定的场景按照空间、基元(三角形)划分成一颗树形结构。
- 主光线生成:相机向各像素点投射指定数量的光线。
- 光线遍历 :生成的主光线和次级光线(相交后折射/反射等产生)要在第一步生成的加速结构中遍历,判断与哪个叶子空间相交。
- 光线求交:遍历得到的叶子空间中可能包含多个基元,要继续计算与哪个基于相交及交点坐标,并产生次级光线。
- 着色:每个像素根据当前点材质、纹理、有贡献的光线,进行最终的着色计算。
3 实时光线追踪硬件
实时光线追踪硬件架构可以按专用性分成两类:
- 一类是混合架构,结合CPU,GPU,优化算法、辅以部分硬件等方式实现。更多的可编程性,早期和移动端采用的较多。
- 另一类是专用架构,从一开始就是为光线追踪而设计,功能多用新的硬件直接实现,性能更佳。
我们主要讲述的是一个大致结构,所以会提到多种架构的知识。以下是一个偏专用型光追架构的示意图。
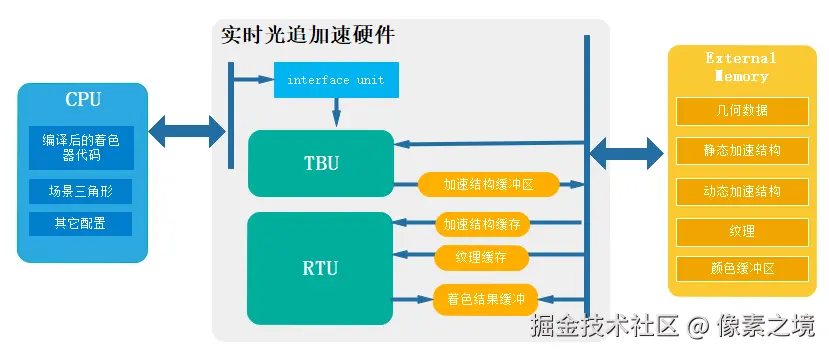
CPU:应用程序主体仍然在cpu运行,但编译后的着色器代码、场景数据、参数等要经过系统总线发送到光追加速硬件上执行。
- 着色器 :有自定义光线生成着色器 (初始主光线生成)、相交着色器 (自定义几何体的相交检测)、命中/未命中等着色器。若光追硬件支持,那么着色器程序在使用硬件厂商提供的编译器编译之后发送。
- 场景三角形 :3d场景由众多三角形构成,需要将其发送到光追硬件用于构建加速结构。
- 其它配置:场景物体上用到的纹理贴图、摄像机位置、光源位置等配置。
TBU :(Tree Building Unit)构建器,根据kd-Tree算法或BVH算法构建一个树形加速结构 ,每一帧都需要根据场景的变化构建或更新加速结构,其结果在RTU上使用。
RTU:(Ray Tracing Unit)光追单元,光线的生成、遍历、相交计算、着色计算在这个单元进行。
External Memory:一个共享内存,使用的几何数据、加速结构等存储在这里。
4 TBU详细
因为场景可能是动态变化 的,所以每一帧,TBU都要构建出对应场景的加速结构,这是实现实时光追的一个重要前提条件。
混合架构中不含TBU单元,而是利用CPU和一些其它方式实现,具体如下:
- 树的构建 :混合架构中构建加速结构会让CPU实现,因为CPU的多级缓存 和优秀的控制流,这两点适合树的构建过程。
- 树的更新 :若每帧都让CPU构建再传到光追硬件,这样的方式非常缓慢。还需要配合一个
GTU(树更新单元)拟合变化的部分,再配合一些树改造、算法调整等方式达到实时构建的要求。
硬件TBU一般有kd-tree或BVH算法实现的两种,这两者只要进行足够调优都能达到相近的性能。它们通常不支持编程,但为了支持动态更新场景 ,TBU会支持三条特殊指令:"更新节点"、"处理叶子"和"加载顶点"。CPU只需将变化了的部分几何数据发给TBU即可。
使用TBU硬件来构建加速结构的情况一般比使用CPU/GPU构建的速度快4倍左右。
4.1 使用SAH+BVH的TBU
下面先大致介绍一下BVH算法,再叙述相关硬件结构,方便理解。

BVH(Bounding Volume Hierarchy)包围体层次结构
- 先对场景空间进行二分,再对分割出的子场景进行二分。
- 每次分割递归时要为当前子空间中的所有几何体计算一个可以包围它们的包围盒(通常使用BBAA包围盒------立方体)。
- 一直分割到只剩一个或少量几个物体为止。
- 分割和计算所得包围盒存储在一个树形结构的数据中。
SAH(Surface Area Heuristic):一种划分方法。进行空间二分时,根据包围盒的表面积和光线与包围盒相交的概率来选择划分点,以最小化求交计算的成本。
构建器整体架构如下图(a)所示: 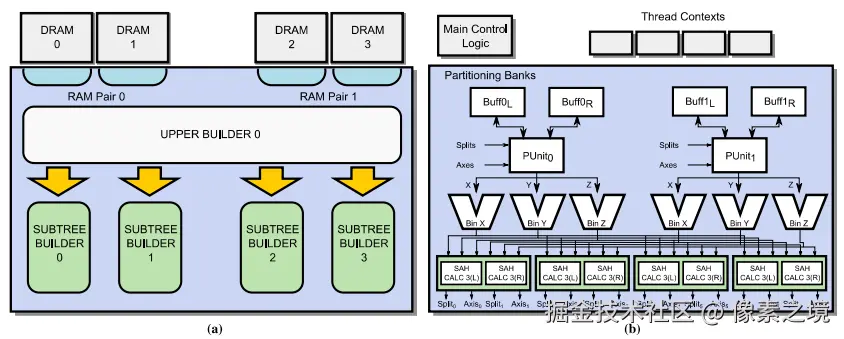
DRAM:动态存储器。在构建开始之前,场景图元会被分配到各个DRAM对中。
upper builder(上层构建器) :直接读写DRAM中的图元数据,负责构建层次结构的上层。
- 该构建器包含划分单元、分箱单元以及一对 SAH计算器(详细参考下面的子树构建器)
- 上层构建器的工作较少,只有一个线程负责。
subtree builder(子树构建器):如上右图(b)所示,负责构建上层构建器传来的子树。
- Buffer(图元缓冲区):有一排成对的buffer,每对中的一个Buffer先接收上层构建器划分来的图元,另一个缓冲区则保持为空。
- PUnit(分区单元) :从Buffer读取图元向量,它们的分割点由
Bin unit和SAH计算得出,根据结果,分区单元对其Buffer中的图元进行划分,将结果写入另一个Buffer。在下一次递归划分时,两个Buffer的作用互换。 - Bin Unit(分箱单元) :每个
PUnit连接到三个Bin Unit------Bin x/y/z它们分别处理图元AABB(包围盒)各轴的中心点,最后输出在三个轴上选择的分箱位置,以及用于计算这些分箱位置的原始图元AABB。 - SAH Calc(实现SAH算法的计算器) :
Bin Unit输出的AABB及其选择的分箱位置被输入到SAH计算器中,这些计算器为每个轴上的每个分箱累积一个AABB和一个计数器。一旦所有图元都被累积,SAH计算器就会评估每个可能划分的SAH成本,并输出找到的最低成本划分,将划分信息反馈到PUnit。 - Main Control Logic(主控逻辑):用于控制子树逻辑的运行、各单元的执行顺序、缓冲区的负载均衡等。
- 子树的多线程:上层构建器是一个线程执行,划分到各子树后,每个子树都会生成一个新的线程来执行。一个线程由1个寄存器(存储当前划分图元在buffer中的开始与结束地址),1个划分方案(SAH计算得的划分信息),1个栈(划分图元时辅助操作用)和栈顶指针等组成。
4.2 PLOCTree:另一种实现BVH的TBU
PLOCTree是一种基于并行局部有序聚类(Parallel Locally-Ordered Clustering,PLOC)算法的树构建加速器。PLOC算法从树的底部开始构建,对所有图元的AABB包围盒进行聚类(距离较近的一些图元归为一类,为它们计算1个新的包围盒),逐层使用该方法,最终只有一个包围盒时整颗树构建完成。

- 从左侧输入所有图元的AABB包围盒。
- 为每个包围盒的
x,y,z坐标生成莫顿码,使用排序器按莫顿码排序(排序上相邻的其空间位置上也相邻) - 将这些包围盒分给多个扫描流水线,每个流水线有1个扫描窗口将扫描的包围盒存入窗口缓冲区。
- 将2R+1个输入到2R个距离评估器 中(
Distance Metric Evaluator DME)。 - 比较树 (
Comparator Tree)接收来自DME组的2R个距离作为输入,并输出具有最低距离的AABB的相对索引 - 后处理模块 (
Postprocessing)从比较树的结果中将最相近的两个AABB合并,用一个新的AABB表示,再次从最左侧输入进行第二轮处理。
4.3 FastTree:一个实现kd-tree算法的TBU
BVH算法的一个固有问题是:同一级别的两个节点在空间上可能重叠(包围盒的重叠),因此在定位到命中之前可能会访问大量节点。kd树算法没有存储包围盒,不存在这个问题,但在处理图元时需要额外的处理步骤。
FastTree架构图及功能描述如下: 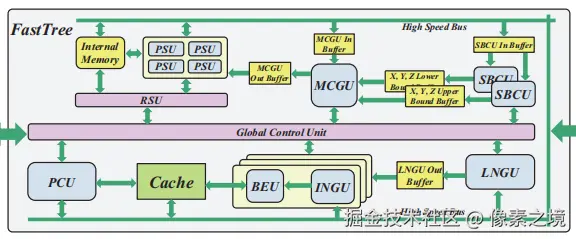
- SBCU(场景边界计算单元) :从右上角批量输入的图元中计算它们的
x, y, z最大最小值更新为边界值。 - MCGU(莫顿码生成单元):计算输入图元的包围盒,并为每个图元生成莫顿码。
- PSU(前缀和单元):计算数组的前缀和,配合RSU单元进行排序。
- RSU(基数排序单元):设计为多轮计数排序,用前缀和计算,依据莫顿码排序。
- LNGU(叶节点生成单元):获取排序数组中相邻的两个莫顿码码字,相距较近基元的做为一组叶节点,否则单独作为一个叶节点。
- INGU(内部节点生成单元):输入两个叶子节点的莫顿码,确定1个分割平面,将两个叶子节点划分到不同子空间,结果发送到位编码单元(BEU)。编码结果通过片上缓存写入片外存储器。
- PCU(路径压缩单元):输入每个节点的莫顿码,查找其父节点,判断父节点是否为必要节点,不是则舍弃,直到找到一个必要节点。
5 RTU详细
这里选用一个资料较详细的SGRT架构做主要讲解,适当拓展其它架构知识。
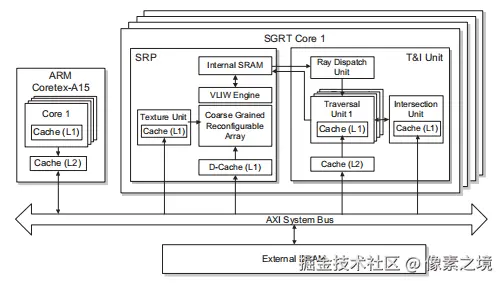
SGRT是一个移动端的实时光线追踪图形系统,属于混合型架构,没有TBU硬件,其加速结构在CPU构建。SGRT使用的静态场景测试,暂未添加树更新单元,但他的架构是为态场景设计的,只是暂未扩展,可做我们参考用。
SGRT拥有多个核心,每个核心都包含一个T&I(遍历与相交)单元和一个SRP(三星可重构处理器)单元。各部分详细结构及功能如下:
5.1 SRP结构
SRP使用的是Lee等人2011中开发的GPU着色器核心,用于执行光线生成 (初始生成的主光线、遍历、相交时产生的次级光线 )、相交等各种光线着色器程序 和着色计算。
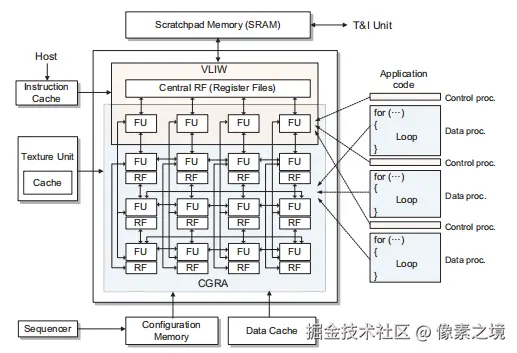
VLIW (超长指令字)引擎适用于通用计算,例如函数调用和分支选择。CGRA(粗粒度可重构阵列)使用SIMD架构(单指令多数据),用于高效执行密集型计算。
主机端调用SGRT提供的编译器 ,对着色器代码(光线生成、相交等)进行编译时,会针对VLIW,CGRA的特性进行处理,比如控制流语句在VLIW中执行,光线的计算在CGRA中执行。
Configuration Memory :SRP提供的为设计人员自定义的一些配置用来辅助实现功能。
FU (功能单元): 内部的组件包括:本地缓冲区 、算术逻辑单元 (ALU)、输入和输出多路复用器 以及寄存器文件(RF)。
5.2 光线生成与着色
SGRT架构的主光线生成直接由SRP执行光线生成着色器产生,在编译 时,SGRT提供的编译器会为各类型的光线执行不同的内核代码,并为它们添加着色代码。生成的光线会被放到缓冲区,以便被批量分配给T&I单元。
光线生成单元 :一些专用型光追架构中会单独用硬件实现主光线生成,可以为主光线按莫顿顺序(空间上排序)以提高缓存效率。还可以剔除在三角形背面生成的阴影光线,生成采样光线以支持分布式光线追踪和超级采样抗锯齿等。
着色 :部分硬件架构支持自定义着色代码 ,但SGRT架构的着色由编译时附加,具体如下:
- 在编译时对不同的光线类型和是否命中分类(阴影光线未命中、其它光线命中等),添加不同的着色内核代码。
- 其他光线且命中的情况是计算量最大的,编译时为其添加的内核代码中会包括:中心坐标计算法向量、是否生成次级光线、纹理映射、光照计算。
- 当前光线计算出的颜色被添加到着色缓冲区中的先前颜色上;最终颜色由从给定像素生成的所有光线的颜色值累加得到。
光照计算 :由于辐射度的计算方式复杂,实现成本高,且实现了的辐射度方法依然很难达到实时帧率要求,所以现在实时光追硬件中的光照计算几乎都使用更简单的Phong光照模型。
5.3 T&I单元详细
光线的遍历与相交计算是整个光追管线中最耗资源的阶段 ,所以多数光追架构中都含有T&I单元,其硬件化程度高,多采用硬连线代替通用寄存器,且包含TRV和IST硬件。
SGRT的T&I由光线分配单元(RD) 、四个遍历单元(TRV) 和一个相交单元(IST) 组成。每个单元都通过一个内部缓冲区连接,缓冲区将光线从一个单元传递到其他单元。T&I单元和SRP通过基于FIFO的专用接口进行通信。
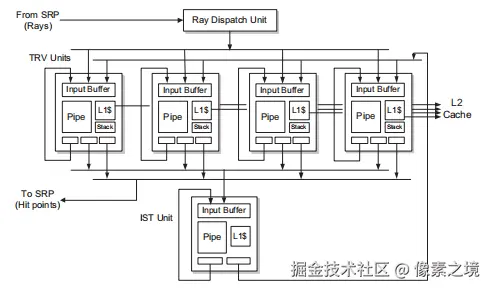
光线分配单元 (RD):从光线缓冲区中获取光线(主光线与次级光线),并首先将其分配给空闲的TRV(每个周期只提供一条光线)。
TRV :将所给的光线在TBU所构建的加速结构中遍历,查找到与当前光线相交的叶子节点(包含1个或多个基元)
- 每个TRV都由一个内存处理模块(输入缓冲区、RAU、L1缓存、短栈)和计算流水线组成。
- TRV流水线的输出分为三条路径:一条反馈回路路径返回输入缓冲区,用于对内部节点进行迭代访问;
- 一条输出路径用于在光线到达叶节点时将光线发送到
IST。 - 还有一条输出路径用于在光线完成
BVH树遍历后将光线发送到SRP(着色资源处理器) 。 TRV的计算流水线由4个浮点加法器、4个浮点乘法器和11个浮点比较器组成。
IST :计算当前光线与TRV所给的多个基元(一般是三角形)是否相交,及其交点。
- 其由一个内存处理模块(输入缓冲区、RAU、L1缓存)和计算流水线组成。
IST流水线的输出分为两条路径:一条反馈回路路径返回输入缓冲区,用于对同一叶节点中的三角形进行迭代测试;- 还有一条输出路径用于将光线发送到
TRV,以便访问下一个树节点。
三阶段相交计算 :较好的T&I硬件有三阶段相交测试单元,该单元将相交测试阶段分为三个阶段。
- 第一阶段是光线平面测试:判断光线是否与三角形所在的平面有交点,没有则终止。
- 第二阶段是重心坐标测试:判断光线是否与该三角形有交点,没有则终止。
- 第三阶段是最终的命中点计算:计算确切的相交坐标。
包追踪与单光线追踪:T&I可以设计为多条光线或单条光线一起进行处理,两者各有差别:
- 包追踪(多条光线):对与单个盒子相交的多条光线进行
SIMD(单指令多数据)并行化,但由于分支发散问题,它不适用于次级光线。一般会应用光线重新排序、排序或调度算法以提高光线连贯性。 - 单光线追踪:每条光线都被视为一个单独的线程,这意味着在处理非相干光线时可以获得更高的硬件利用率。对于不连贯光线而言,单光线追踪更稳健。
SGRT的T&I就采用这种方式。
5.4 计算架构
光线追踪过程会产生大量的光线,对这些光线需要高并行性的处理和计算,T&I的SIMD架构方式是较适合处理光线的方法之一。还有其它几种计算架构,以下是他们的使用情况:
SIMD:每条光线都由相同的遍历程序处理,但使用数据不同,这一点很适合使用SIMD结构。只是光线在场景中反射、折射,与基元相交、未相交等情况存在许多分支指令情况,纯SIMD机制无法提供足够的灵活性。
SIMD+SIMT :引入SIMT(单指令多线程)可以为一组SIMD硬件执行的作业中的分支指令提供更灵活的支持;与多线程集成,通过时间复用SIMD硬件来隐藏内存延迟。但这种模型不适合非相干光线追踪,因为它会导致分支发散 和共享内存争用。
MIMD (多指令多数据):每个核心都有自己的光线缓冲区,有独立的指令流和数据流,增加多组指令获取、解码和分发逻辑。MIMD架构提供了最佳的执行灵活性,但更复杂,硅面积占用多。
6 总结
实时光追硬件 根据面向的场景不同,其硬件化程度有很大差异,一般面向专用集成电路、专用集成处理器的情况,硬件程度高,可能有专门实现的TBU、光线生成、着色单元等硬件。它们虽然有更好的性能,但可编程性少、灵活度低。
面向通用处理器 ,也就是大众用户的情况,则要有一定的灵活性,通常支持部分自定义着色器 程序。移动端限于空间、发热等条件,更多使用混合架构,即:树构建在CPU执行,配合一个异步构建的树更新单元 ,着色器的执行也可能与GPU共用。
PC端的相关研究较多,能达到更高的性能,好的实时光追硬件多会用TBU硬件、更适合光追的MIMD架构。光追硬件一般放到显卡中,作为GPU架构的一部分。
光追效果与性能 :光追渲染中,因为每个物体考虑到了更多的间接光线,所以画面效果更亮;阴影、镜面、倒影等效果更明显,更真实。高端光追硬件每秒可执行数亿~百亿根光线。
但实际应用中有高清像素、帧率的要求,高端的实时光追硬件也很容易产生噪点 ,一般会结合降噪算法 后处理,光流插帧 技术提升帧率等。软件端渲染一个场景时也不一定全用光追渲染,比如远处的场景使用传统光栅化渲染,近处场景用光追渲染,最后两者结合。
7 主要参考
- A Hardware Unit for Fast SAH-optimised BVH Construction
- PLOCTree: A Fast, High-Quality Hardware BVH Builder
- FastTree: A Hardware KD-Tree Construction Acceleration Engine for Real-Time Ray Tracing
- HART: A Hybrid Architecture for Ray Tracing Animated Scenes
- MergeTree: a HLBVH constructor for mobile systems
- MRTP: Mobile Ray Tracing Processor With Reconfigurable Stream Multi-Processors for High Datapath Utilization
- RayCore: A ray-tracing hardware architecture for mobile devices
- SGRT: A Mobile GPU Architecture for Real-Time Ray Tracing
- A Reconfigurable SIMT Processor for Mobile Ray Tracing With Contention Reduction in Shared Memory
- T&I Engine: Traversal and Intersection Engine for Hardware Accelerated Ray Tracing
- Toward Real-Time Ray Tracing: A Survey on Hardware Acceleration and Microarchitecture Techniques
- TRaX: A Multicore Hardware Architecture for Real-Time Ray Tracing
- 光线追踪硬件加速方案综述
- 《全局光照》