导读
你是否曾想象过,如果AI不仅能生成视频,还能像人类一样"想象"世界的演变、预测动作的后果、甚至进行多步推理与规划,会是怎样的情景?
来自MBZUAI的PAN团队最新发布的PAN世界模型 ,正是这样一个突破性尝试。它不仅在视觉生成上表现出色,更在交互性、长时域一致性和因果推理方面迈出了关键一步。>>更多资讯可加入CV技术群获取了解哦
数据荒:CV 人最大的"隐形成本"
SOTA 模型年年换,但有一条血泪守恒定律一直没变:
"数据不够,trick 来凑;trick 凑不动,就换方向。"
- 做视频动作检测? 网上 10 k 段短视频,7 k 段打台球,2 k 段猫咪开箱。
- 做长时序规划? 公开最长 3 秒,一帧丢球,下一帧球已经进洞,中间全靠脑补。
- 做因果推理? 现有数据集只有"结果"没有"反事实",想测"如果当时没踢那一脚"------对不起,没有。
PAN 的出现,相当于给 CV 圈送了一台"剧情续写机":
给定一张图 + 一句自然语言动作,它就能自回归地"拍"出任意长度、任意域、物理合理的视频,而且对象 ID、几何关系、光照一致性在线保持。
换句话说,你缺什么数据,就让 PAN 给你"演"什么。
PAN的结构拆解
PAN的核心创新在于其生成式潜在预测(Generative Latent Prediction, GLP) 架构,将世界模拟分为三个层次:
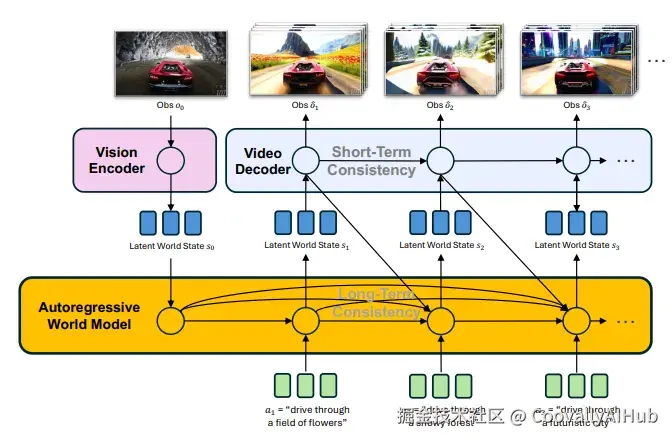
它包含一个基于LLM的自回归世界模型主干负责长时域模拟,和一个视频扩散解码器负责观测预测。
- 视觉编码器: 将图像或视频帧编码为结构化潜在表示。
- 自回归世界模型主干: 基于大语言模型(Qwen2.5-VL),在潜在空间中模拟世界状态的演变。
- 视频扩散解码器: 将潜在状态解码为高质量、时间连贯的视频观测。
这种设计使得PAN能够在潜在空间中进行"思考",并在像素空间中"呈现",实现了推理与生成的统一。
- 关键技术亮点
Flow Matching 损失: 取代传统 L2,直接回归 Rectified Flow 的 velocity,高频细节不爆炸
Causal Swin-DPM: 一种新颖的滑动窗口去噪机制,确保长时域生成中的平滑过渡,避免误差累积。
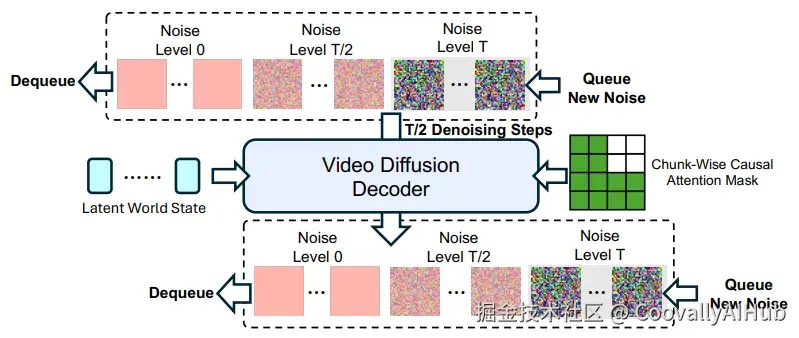
它通过一个滑动时序窗口同时处理两个处于不同噪声水平的视频块,并使用因果注意力掩码,确保生成连贯且防止未来信息泄露。
生成式监督: 通过重构未来帧来约束潜在状态的演变,避免模型"偷懒"或崩溃。这与JEPA等仅匹配潜在向量的方法有根本区别,保证了学习到的动态与现实世界变化对应。
多阶段训练策略: 先分模块训练,再联合优化,确保各组件稳定协同。
实验结果:全面领先
PAN在三大评测维度上表现卓越:
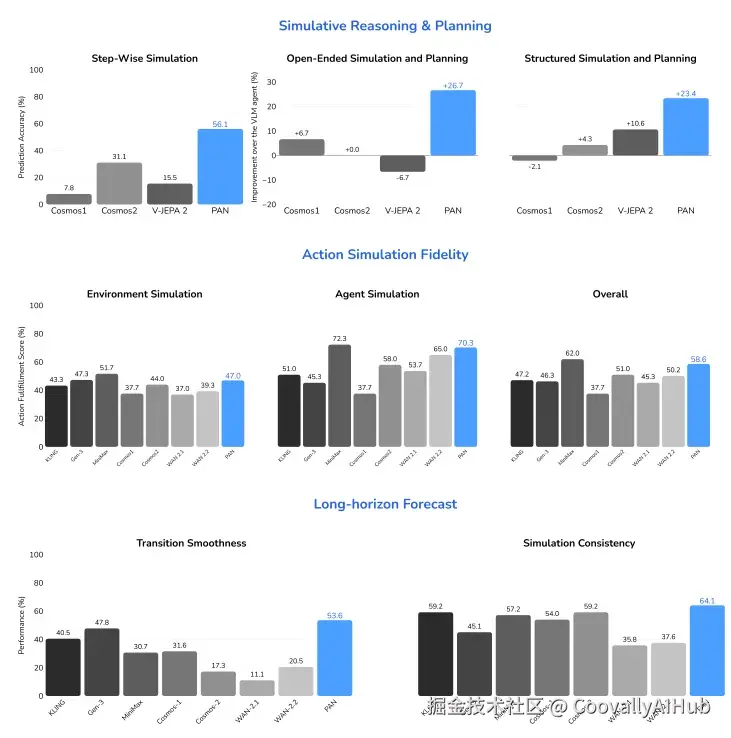
PAN在开源模型中全面领先,并与顶尖商业模型性能相当。
动作模拟保真度: 在开放源代码模型中排名第一,甚至超越部分商业模型。
长时域预测: 在过渡平滑性和一致性上显著优于基线模型。
模拟推理与规划: 与VLM智能体结合,在开放环境和结构化任务中提升成功率超过20%。
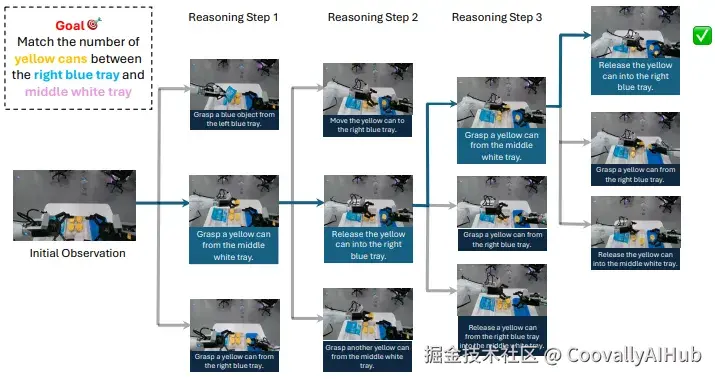
智能体提出候选动作,世界模型模拟结果,智能体再根据模拟结果选择最佳动作,循环直至达成目标。
- 生动的模拟实例

实例1:交互式长序列模拟。模型根据自然语言指令(如"用白色刷子将粉色碗中的食材抹到蛋糕上"),进行一系列连贯的烘焙操作,整个过程状态一致,没有漂移。
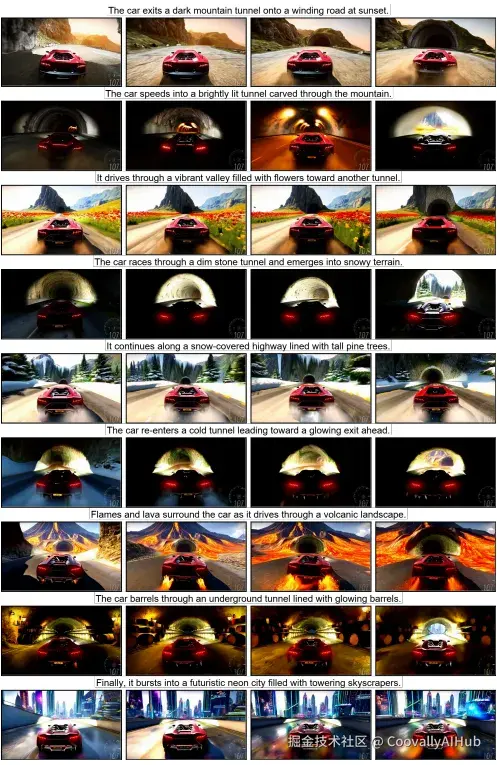
实例2:多样动作与世界模拟。一辆车根据指令穿越多种截然不同的环境(如日落下的山路、火山地貌、霓虹都市),展示了模型在遵循指令的同时,在不同世界间泛化的强大能力。
告别数据荒与繁琐流程:Coovally平台训练实战
然而,生成的数据最终需要用于训练和验证模型。面对海量数据和复杂模型,如何高效启动一个训练任务,依然是横在众多研究者面前的难题。
为此,我们实测了Coovally AI平台,它恰好为解决上述痛点提供了"另一条腿":
海量数据集即开即用: Coovally平台上汇聚了400+开源数据集,覆盖图像分类、目标检测、语义分割等主流任务场景。你找不到的数据,或许就在这里。一键调用即可投入训练,彻底告别四处搜寻、下载和格式化数据的繁琐。
- 一站式模型训练: 在平台上,你可以一键调用YOLO、Transformer等热门架构,快速进行模型训练与验证。平台的设计实现了极致的简化:
- 免环境配置: 直接调用预置的PyTorch、TensorFlow等深度学习框架。
- 免复杂调参: 内置自动化训练流程,即使初学者也能轻松上手,产出可用模型。
- 高性能算力支持: 底层提供分布式训练加速,大幅缩短实验周期。
- 无缝部署: 训练完成的模型可直接导出,或通过API快速接入您的业务系统。
>> 点击下方链接,立即体验 Coovally <<
平台链接:www.coovally.com
Coovally平台还可以直接查看"实验日志"。提供直观的可视化训练界面,清晰设置参数,监控训练过程(Loss, mAP等指标实时可视化)。
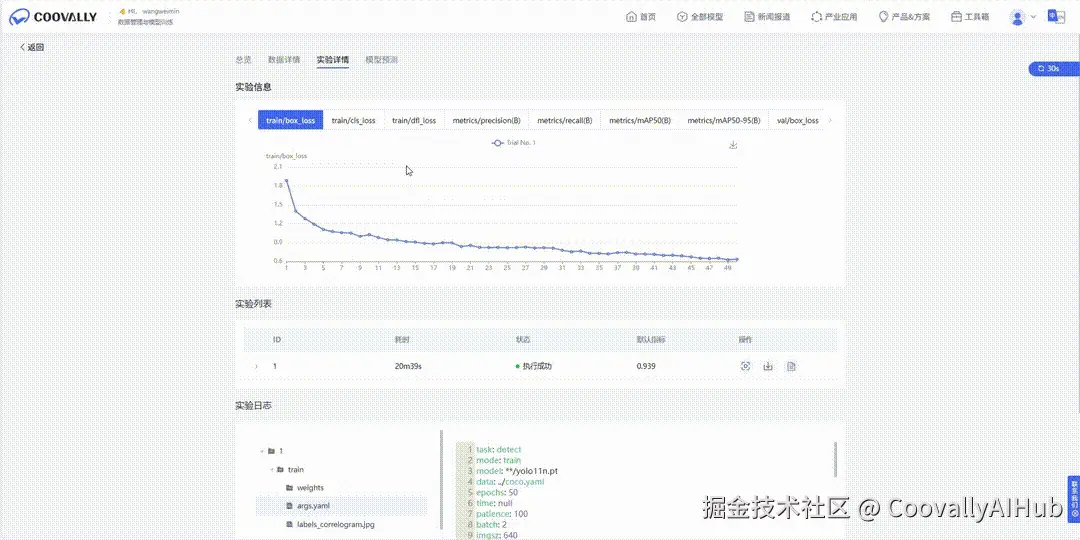
并行实验,效率倍增! 一键发起多个训练任务并行运行,结果一目了然,快速锁定候选者。支持分布式训练,充分利用硬件资源,大幅缩短训练时间。
局限 & 下一步:写给想发 Paper 的你
- 物理精度仍靠数据堆
碰撞-形变-流体还没显式约束,未来可引入可微物理引擎当正则。
- 动作空间自由≠评估自由
目前用 VLM 当"评委",主观偏差大;可程序化的物理度量(如关键点位移误差)是下一个突破点。
- Latent token 只有 256
对密集场景(满桌零件)可能欠表达,层次化离散-连续混合 latent 已在实验。
好了,论文拆得够细,但别忘了------再强大的世界模型也只是替我们"试错",真正的因果洞察还得靠人脑。
所以,今晚回实验室的路上,不妨抬头想想:
当世界模型能够把"数据稀缺"弥补之后,你的下一个算法创新,究竟该往哪里长?