文章目录
【1】声音的本质
当你说话时,你的声带在振动。这种振动会推挤周围的空气,形成一种疏密相间的压力波 ------这种波,就是声音 ,学术上称为机械波 。
它的两个核心属性决定了我们听到的声音体验:
- 频率 :指每秒振动的次数,单位是赫兹(Hz)。它决定了声音的音调 。
- 振动快 -> 频率高 -> 音调高(如女高音)
- 振动慢 -> 频率低 -> 音调低(如男低音)
- 振幅 :指振动强度的物理量。它决定了声音的响度 (音量)。
- 振幅大 -> 能量高 -> 声音响
- 振幅小 -> 能量低 -> 声音轻
【2】基础知识
为了让计算机能处理声音,我们需要将自然界中的信号进行"翻译":
模拟信号 :在时间和幅度上都连续的信号。自然界中大多数信号,包括声音,最初都是模拟信号。
数字信号 :在时间和幅度上都离散的信号。这是计算机能够存储和处理的格式。
AT:
1.时间连续:在任意一个时间点都有确定的信号值。例如,温度和红绿灯的颜色在时间上都是连续的,因为它们在每一刻都有确定的读数或状态。
2.幅度连续:信号的取值变化是平滑、无间隔的,可以取无限个可能的数值。例如,温度可以从20℃无缝地变化到21℃,其间的所有值(如20.0001℃)都是可能的,因此它的幅度是连续的。而红绿灯的颜色状态只有有限的几种唇语识别系统处理的,正是这种离散的数字信号。
【3】如何将模拟信号变为数字信号?(PCM编码)
将模拟信号转换为数字信号的过程,被称为 PCM(脉冲编码调制) 编码。
下图展示了从连续模拟信号到离散数字信号的转换流程: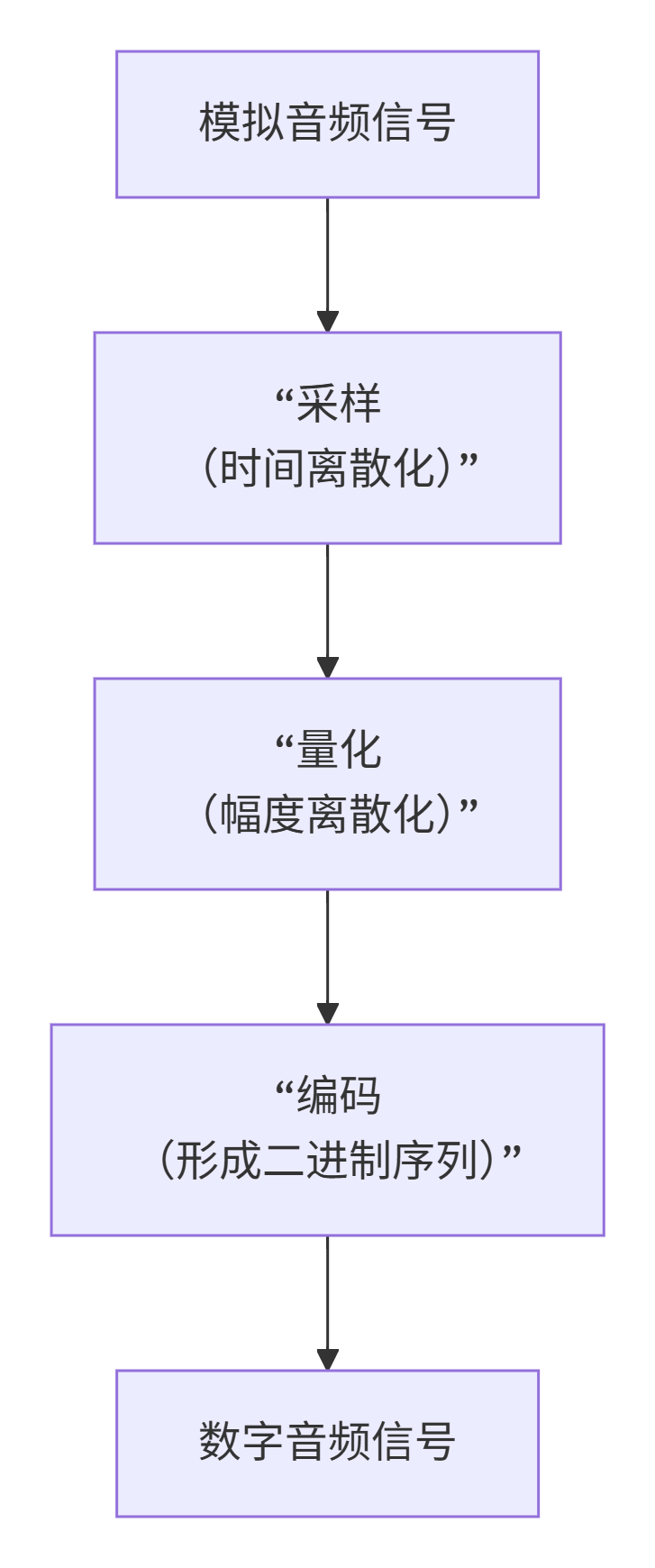
- 采样 :以固定的时间间隔,测量模拟信号的瞬时振幅值。
采样率 :每秒采样的次数(Hz)。奈奎斯特-香农定理 告诉我们:采样率必须至少是信号中最高频率的2倍 ,才能无失真地还原声音。- 人耳听觉范围:20Hz - 20kHz。
- 常见标准:CD音质(44.1kHz,满足还原人耳听觉),语音识别(16kHz或8kHz,因语音主要能量集中在中低频)。
- 量化 :将采样得到的连续振幅值,映射到一个有限离散集合(量化等级)中的某个值上的过程。
位深 :表示每个采样点振幅值的二进制位数,决定了有多少个"等级"(如16bit有2^16=65536个等级,范围是32768~32767)。位深越高,记录的声音细节越丰富,动态范围越广。 - 编码:将量化后的整数值,最终转换为二进制码流,并按照特定格式存储起来。
【4】音频的存储与压缩
数字音频信号主要有两种存储方式:
无损压缩 :如同用ZIP压缩文件,可完全还原,不损失任何信息。适用于音频资料的存档(如FLAC, APE)。
有损压缩 :通过去除人耳不敏感的音频信息,大幅减小文件体积。适用于网络传输和消费级应用(如MP3, AAC)。
AT:
FLAC: Free Lossless Audio Codec (免费无损音频编解码器)
APE: Monkey's Audio (猴子音频)
AAC: Advanced Audio Coding (高级音频编码)唇语识别关联 :在开始模型训练前,我们通常需要将所有音频文件统一解码为标准PCM格式的数字音频信号,即获取时间序列形式的振幅离散值。并进行后续的特征提取。
【5】进阶知识:从数字信号到特征
PCM编码后的数字信号 (即离散时间序列)虽然包含所有信息,但直接扔给模型,就像让一个人通过看像素点来识别图片一样低效。因此,我们需要从中提取更有代表性的声学特征。
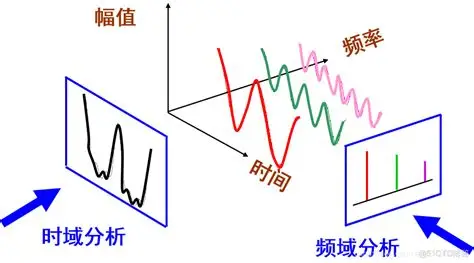
1.时域与频域(基础知识)
- 时域 :横轴是时间,纵轴是振幅。它告诉我们 "振幅如何随时间变化" ,即我们熟悉的波形图。
- 频域 :横轴是频率,纵轴是能量。它告诉我们 "声音里有哪些频率成分,各自有多强" 。通过傅里叶变换,可以实现从时域到频域的转换。
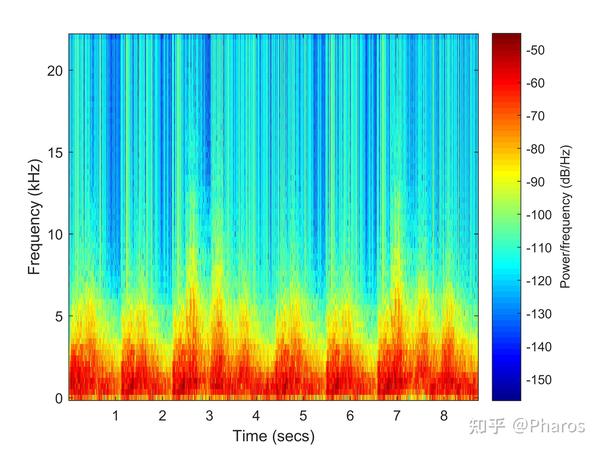
- 频谱图 :它是语音识别和唇语识别中最常用的特征表示之一。它将时域和频域结合,横轴是时间,纵轴是频率,颜色表示能量。它直观展示了频率成分如何随时间演变 。
2.关键声学特征(用于模型输入)
- 梅尔频谱图 :模仿人耳听觉特性(人耳对低频分辨力强于高频)的非线性频谱图。它是当前端到端模型最常用的音频前端输入。
- MFCC :在梅尔频谱基础上,通过一系列处理(取对数、DCT变换等),"提纯"出表征语音内容的核心信息。它能有效过滤掉说话人身份、情绪等冗余信息,专注于"发了什么音"。
- F0(基频) :代表了声音的音高 ,对应声带振动的频率 。它是区分清浊音(如/p/和/b/)的关键,而清浊音在唇形上无法区分,这就体现了音频的互补价值
- 共振峰 :元音音色的决定因素,是频谱中能量集中的频带区域。第一(F1)、第二(F2)共振峰 与嘴的张合度、舌位的前后 直接相关,是连接嘴部动作 与音频特征最直接的桥梁。