Map接口
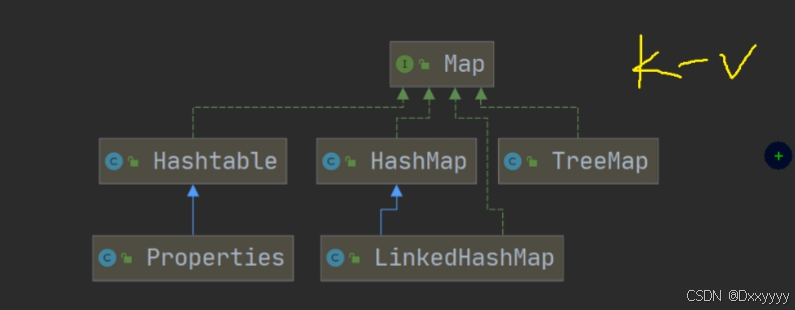
Map接口实现类的特点
注意:这里讲的是JDK8的Map接口特点Map_java
1)Map与Collection并列存在。用于保存具有映射关系的数据:Key-Value
2)Map中的key和value可以是任何引l用类型的数据,会封装到HashMap$Node对象中
3)Map中的key不允许重复,原因和HashSet一样,前面分析过源码。
-
Map中的 value 可以重复
-
Map的key可以为 null,value也可以为null,注意key为null只能有一个,value为null,可以多个.
6)常用String类作为Map的 key
7)key和value之间存在单向一对一关系,即通过指定的key总能找到对应的value
java
package com.Map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Set;
public class Map_ {
@SuppressWarnings("all")
public static void main(String[] args) {
//1、放的是KEY-VALUE
HashMap map = new HashMap();
map.put("no1", "aaa");
map.put("no2", "bbb");
map.put("no3", "ccc");
map.put("no4", "aaa");//VALUE是可以重复的
map.put("no3", "ddd");//会直接替换KEY=no3的VALUE
map.put(null, "ddd");//KEY只能有一个空
map.put("no5", null);//Value可以有很多空
System.out.println("MAP" +map);//输出结果的顺序并不是输入的顺序
System.out.println(map.get("no5"));//可以通过找KEY来找其对应的value
Set set = map.keySet();//返回所有的key
System.out.println(set);
Collection values = map.values();
System.out.println(values);//返回所有value
}
}8)Map存放数据的key-value示意图,一对k-v是放在一个Node中的,有因为Node实。
现了Entry接口,有些书上也说一对k-v就是一个Entry(如图)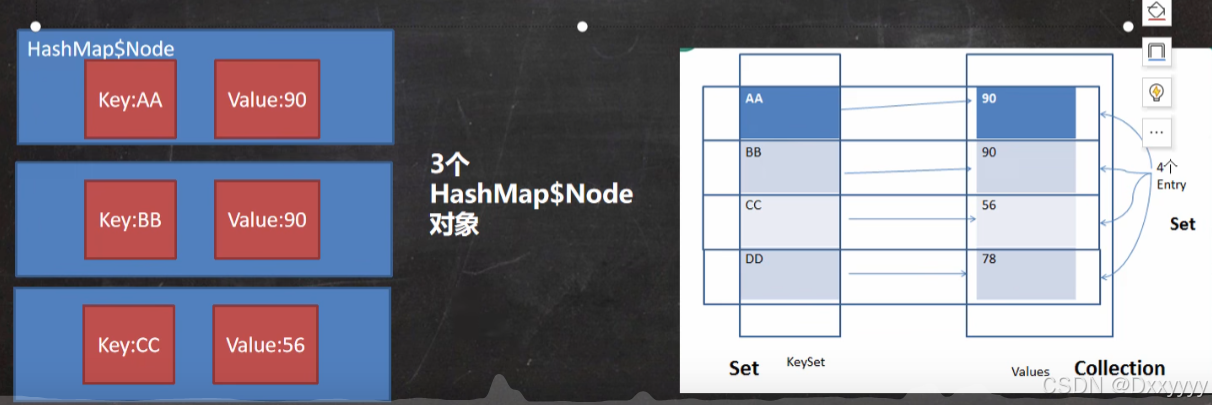
常用方法
- put:添加
2)remove:根据键删除映射关系
3)get:根据键获取值
4)size:获取元素个数
5)isEmpty:判断个数是否为0
- clear:清除
7)containskey:查找键是否存在
java
package com.Map;
import java.util.HashMap;
public class MapMethods {
@SuppressWarnings("all")
public static void main(String[] args) {
//常用方法
HashMap map = new HashMap();
map.put("no1", "aaa");
map.put("no2", "bbb");
map.put("no3", "ccc");
map.put("no4", "ddd");
map.put("no5", "eee");
map.put("no3", "fff");
//remove
map.remove("no2");
//get 根据key获取元素
map.get("no1");
//size 获取元素
map.size();
//isEmpty 判空
map.isEmpty();
//containsKey 查找key是否存在
map.containsValue("no4");
//clear 清空map
map.clear();
}
}几种遍历方式
java
package com.Map;
import java.util.*;
public class MapTraverse {
@SuppressWarnings("all")
public static void main(String[] args) {
//常用方法
HashMap map = new HashMap();
map.put("no1", "aaa");
map.put("no2", "bbb");
map.put("no3", "ccc");
map.put("no4", "ddd");
map.put("no5", "eee");
map.put("no3", "fff");
//1、遍历所有的KEY,再通过KEY遍历所有的VALUE
Set keyset = map.keySet();
//方法一:增强for循环(推荐)
for (Object key :keyset) {
System.out.println(key +"-"+map.get(key));
}
//方式二:迭代器
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();//这个next就是key
System.out.println(next +"-"+map.get(next));
}
//2、把所有的values取出
Collection values = map.values();
//方式一:增强for
for (Object value :values) {
System.out.println(value);
}
//方式二:迭代器
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()) {
Object next = iterator1.next();//这个next就是value
System.out.println(next);
}
//3、通过EntrySet取出 key-value
Set entryset = map.entrySet();
//方式一:增强for
for (Object entry :entryset) {
//把entry 转为map.entry
Map.Entry a = (Map.Entry) entry;
System.out.println(a.getKey()+"-"+a.getValue());
}
//方式二:迭代器
Iterator iterator2 = entryset.iterator();
while (iterator2.hasNext()) {
Object next = iterator2.next();//HashMap$Node-实现->Map.Entry
Map.Entry next1 = (Map.Entry) next;//向下转型
System.out.println(next1.getKey()+"-"+next1.getValue());
}
}
}HashMap扩容机制
>扩容机制和HashSet相同
1)HashMap底层维护了Node类型的数组table,默认为null
2)当创建对象时,将加载因子(loadfactor)初始化为0.75.
3)当添加key-val时,通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,继续判断该元素的key和准备加入的key相是否等,如果相等,则直接替换val;如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
4)第1次添加,则需要扩容table容量为16,临界值(threshold)为12(16*0.75)
5)以后再扩容,则需要扩容table容量为原来的2倍(32),临界值为原来的2倍,即24,依次类推
6)在JaVa8中,如果一条链表的元素个数超过TREEIFYTHRESHOLD(默认是8),并且table的大小>=MINTREEIFYCAPACITY(默认64),就会进行树化(红黑树)
HashTable
1)存放的元素是键值对:即K-V
2)hashtable的键和值都不能为null
3)hashTable使用方法基本上和HashMap一样
4)hashTable是线程安全的,hashMap是线程不安全
5)底层有数组Hashtable$Entry ,初始化大小为11
扩容机制
1。底层有数组Hashtable$Entry\[\]初始化大小为11
2。临界值 threshold 8=11 *0.75
3。扩容:按照自己的扩容机制来进行即可。
4。执行方法addEntry(hashkey,value,index);添加K-V封装到Entry
5。当if(count>=threshold)满足时,就进行扩容
5。按照int newCapacity=(oldCapacity<<1)+1 的大小扩容。(乘2+1)
Hashtable 和 HashMap对比

Properties类
1.Properties类继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形式来保存数据。
2.他的使用特点和Hashtable类似
3.Properties主要用于从xxx.properties文件中,加载数据到Properties类对象,并进行读取和修改
4.说明:工作后xxx.properties文件通常作为配置文件,这个知识点在lo流举例
properties常用方法
java
package com.Map;
import java.util.Properties;
public class Properties_ {
@SuppressWarnings("all")
public static void main(String[] args) {
//1、继承自HashMap
//2、key和value不能为null
//增加
Properties properties= new Properties(;
properties.put("john",100);//k-v
properties.put("lucy",100);
properties.put("lic",100);
properties.put("lic",88);//替换,修改
//获取value
properties.get("lic");
//删除
properties.remove("lic");
}
}TreeSet
排序输出
java
package com.Map;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSet_ {
@SuppressWarnings("all")
public static void main(String[] args) {
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//调用String的compareTo方法,按照字符串首个字母的大小进行比较
return ((String)o1).compareTo((String)o2);
//按照长度大小排序
//return ((String)o1).length - ((String)o2).length;
}
});
//添加数据。
treeSet.add("jack");
treeSet.add("tom");
treeSet.add("sp");
treeSet.add("a");
//按照无参构造器,实际是无序的,还是需要处理
System.out.println(treeSet);
//使用TreeSet提供的一个构造器,可以传入一个比较器(匿名内部类)
//并指定排序规则
//上面写了匿名内部类
//按照匿名内部类的规则,比如上面的是按照字符串首个字母的大小进行比较,则如果同时add(a)和add(abc),则后面的abc加不进去,因为底层源码中得到了key=0,就不能再加了
//同理,如果是按照长度大小排序,则add(abc)和add(aaa)只会保留前面的
}
}TreeMap
java
package com.Map;
import java.util.Comparator;
import java.util.TreeMap;
public class TreeMap_ {
@SuppressWarnings({"all"})
public static void main(String[] args) {
// TreeMap treeMap = new TreeMap();//使用默认的构造器,创建TreeMap,是无序的
// TreeMap treeMap = new TreeMap(new Comparator() {
// @Override
// public int compare(Object o1, Object o2) {
// return ((String)o1).compareTo((String)o2);
// }
// });//编写排序方法:按照key的字符大小进行排序
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length()-((String)o2).length();
}
});//编写排序方法:按照key的长度大小进行排序
treeMap.put("jack","杰克");
treeMap.put("tom","汤姆");
treeMap.put("kristina","克瑞斯提诺");
treeMap.put("smith","斯密斯");
treeMap.put("abc","斯密斯");//加不进去,因为按照现在的比较方法此时abc和上面的tom的长度一样,底层认为这两个key一样,所以加不进去
System.out.println(treeMap);
}
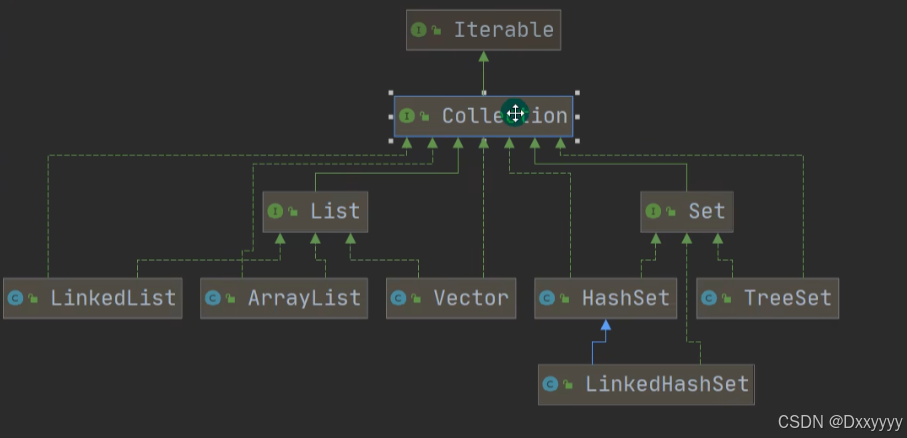
}开发中如何选择集合实现类?(重要)
在开发中,选择什么集合实现类,主要取决于业务操作特点 ,然后根据集合实现类特性进行
选择,分析如下:
1)先判断存储的类型(组对象或一组键值对)
2)一组对象:Collection接口
允许重复:List
增删多 :LinkedList底层维护了一个双向链表
改查多 :ArrayList底层维护Object类型的可变数组
不允许重复:Set
无序:HashSet[底层是HashMap ,维护了一个哈希表即(数组+链表+红黑树)
排序:TreeSet
插入和取出顺序一致:LinkedHashSet,维护数组+双向链表
3)一组键值对:Map
键无序:HashMap 底层是:哈希表jdk7:数组+链表,jdk8:数组+链表+红黑树
键排序:TreeMap
键插入和取出顺序一致:LinkedHashMap
读取文件 Properties
Day34 End
今天晚上有课,这周周末两个考试,好累啊
离回家还有54天,看12月初能不能去一趟南京