论文题目:WFF-Net: Trainable weight feature fusion convolutional neural networks for surface defect detection(用于表面缺陷检测的可训练权重特征融合卷积神经网络)
期刊:Advanced Engineering Informatics(工程技术 Top)
摘要:基于深度学习的表面缺陷分割技术以其较高的准确率和较强的鲁棒性被广泛应用于表面缺陷检测领域。然而,基于深度学习的表面缺陷分割方法在多尺度特征融合过程中受到高维特征和低维特征之间语义差异的干扰,会给网络带来额外的噪声,从而影响检测精度。针对这一缺陷,本文研究了一种新的基于权重的特征融合方法,目的是在高维语义特征和低维语义特征的耦合过程中减少多尺度特征融合后的语义差异和信息冗余。首先,在多尺度特征融合阶段提出了WFF特征融合方法,该方法使用可学习门模块为相邻特征分配权重系数,并使用注意力机制对加权的相邻特征进行融合,从而在相邻特征耦合之前减少冗余信息。融合后还可以减少多高维特征与低维特征之间的语义差异。其次,构建了双译码模块以减少译码阶段的特征损失,并设计了结构损失函数以优化网络在双译码中的多尺度输出。在三个数据集上的实验结果表明,该方法在并集(NEU-SEG:85.70%,DAGM 2007:86.12%,MT缺陷:82.72%)和F1-MEASURE(NEU-SEG:94.11%,DAGM 2007:96.32%,MT缺陷:93.90%)的平均交集上优于已有的几种DL方法。
引言
在智能制造时代,产品质量检测是保证生产可靠性的关键环节。传统的人工检测不仅效率低下,还容易受到工人疲劳、光照变化等因素的影响。近年来,深度学习技术的发展为表面缺陷检测(Surface Defect Detection, SDD)提供了新的解决方案。
今天,我要为大家介绍一篇发表在Advanced Engineering Informatics 2025上的重要论文:WFF-Net: Trainable Weight Feature Fusion Convolutional Neural Networks for Surface Defect Detection。这篇来自中国地质大学的研究团队提出了一种创新的多尺度特征融合方法,在三个公开数据集上都取得了SOTA的性能。
问题的提出:现有方法的两大痛点
痛点1:语义差异的困扰
想象一下,你在拼一幅拼图,有些碎片展示的是整体轮廓(类似高层特征),有些碎片展示的是细节纹理(类似低层特征)。如果直接把这些不同"语言"的碎片简单拼在一起,很可能会造成信息的混乱。
在深度神经网络中也是如此:
- 高维特征:包含更多的语义信息("这是什么")
- 低维特征:包含更多的细节信息("长什么样")
传统的特征融合方法往往忽视了这种语义差异,导致:
- 特征表达混淆
- 检测精度下降
- 误检和漏检增加
痛点2:特征冗余的浪费
在特征金字塔网络中,相邻层级的特征往往存在大量相似信息。就像两张内容重复的照片,保存两份既浪费存储空间,又增加了处理负担。
特征冗余会导致:
- 计算资源浪费
- 关键判别信息被淡化
- 网络训练效率降低
WFF-Net的创新解决方案
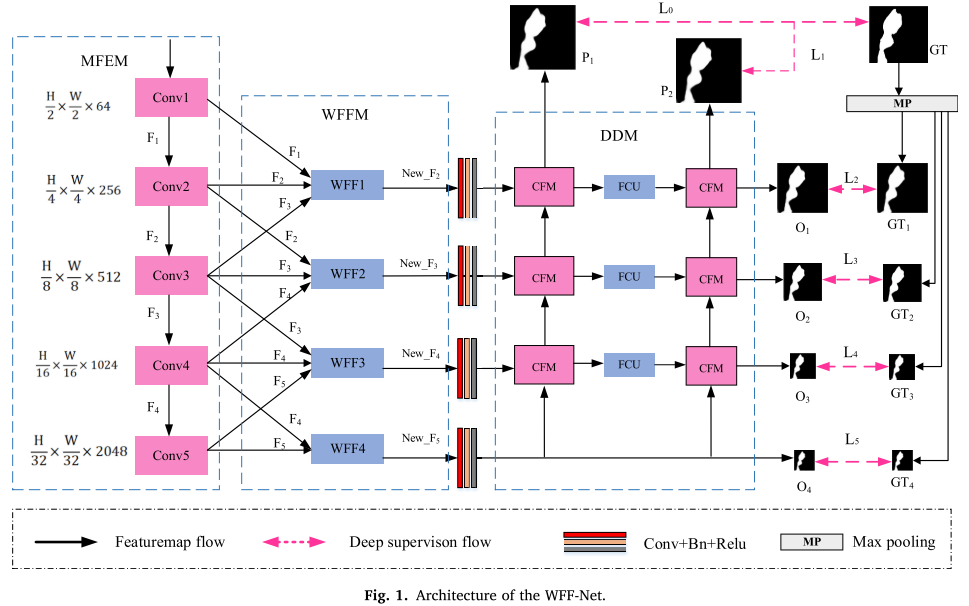

创新1:可学习的加权特征融合
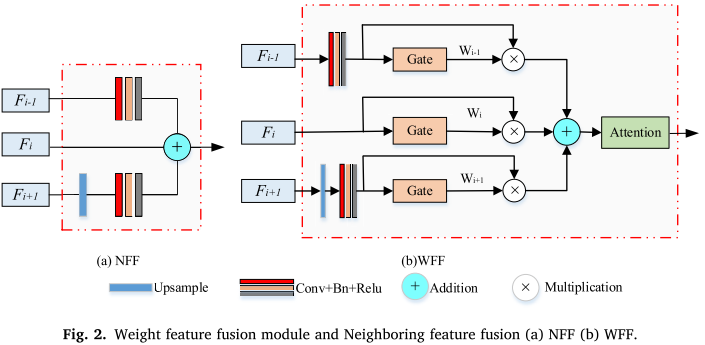
WFF-Net的第一个创新是引入了Gate模块,这就像给网络配备了一个"智能调节器",能够自动学习每个特征的重要性。
工作原理:
-
特征预处理:
- 对于相邻的三个尺度特征(Fi-1, Fi, Fi+1)
- 通过卷积和上/下采样调整到统一尺寸
-
Gate权重分配:
wi-1 = Conv3×3(Fi_i-1) // 为Fi-1分配权重 wi = Conv3×3(Fi) // 为Fi分配权重 wi+1 = Conv3×3(Fi_i+1) // 为Fi+1分配权重 -
加权融合:
Fused = (wi-1 + 1) × Fi-1 + (wi + 1) × Fi + (wi+1 + 1) × Fi+1 -
注意力增强:
Output = EMA(Fused) // 使用EMA注意力机制进一步增强
为什么这样设计有效?
- 自适应性:权重在训练过程中自动学习,不需要人工设定
- 双重减少:融合前减少冗余,融合后减少语义差异
- 可解释性:权重大小反映了特征的重要程度
创新2:双解码器架构
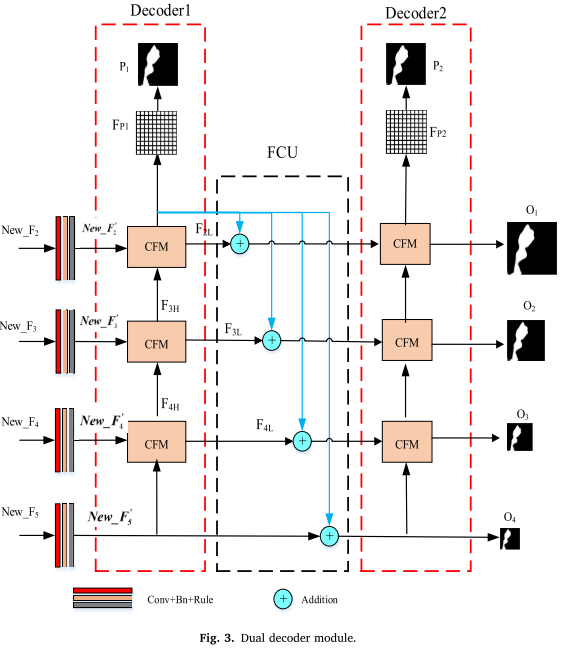
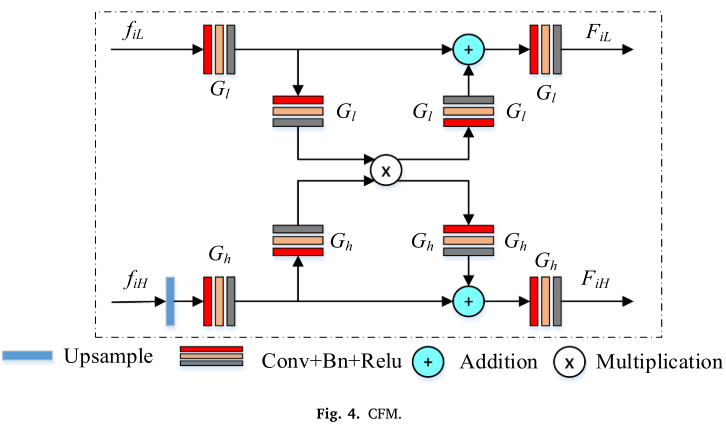
传统的单解码器在上采样过程中会不可避免地丢失一些特征信息。WFF-Net采用双解码器设计,就像给数据恢复过程上了"双保险"。
核心组件:
1. 交叉特征模块(CFM)
- 完全对称的双分支结构
- 低层特征向高层注入细节
- 高层特征过滤低层的噪声
2. 反馈补偿单元(FCU)
FiL = FiL + Up(Fp1) // 将第一解码器的预测融入第二解码器这种设计的优势:
- 特征补偿:第一解码器的输出帮助纠正第二解码器的特征
- 信息保留:双路解码减少了特征损失
- 多尺度监督:两个解码器都参与损失计算
创新3:结构化损失函数
WFF-Net设计了一个精巧的多层次监督策略:
Ltotal = (1/2)Σ(P1和P2的损失) + Σ(各阶段输出的加权损失)损失函数组成:
-
加权二元交叉熵(WBCE):
- 强调困难像素
- 考虑像素的重要性
-
加权IoU损失(ωIoU):
- 关注全局结构
- 平衡正负样本
这种设计确保了:
- Gate模块能够得到恰当的梯度信号
- 网络在多个尺度上都得到优化
- 最终预测更加准确
实验结果:全面领先
数据集概况
研究团队在三个具有代表性的工业缺陷检测数据集上进行了验证:
| 数据集 | 应用场景 | 缺陷类型数 | 挑战 |
|---|---|---|---|
| NEU-SEG | 钢材表面 | 3类 | 类间相似、类内差异大 |
| DAGM | 纹理表面 | 6类 | 非像素级标注 |
| MT | 磁瓦表面 | 5类 | 小缺陷、低对比度 |
性能对比
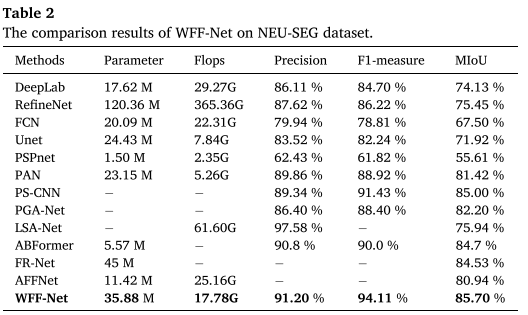
NEU-SEG数据集结果
┌─────────────┬───────────┬────────────┬────────┐
│ 方法 │ Precision │ F1-measure │ MIoU │
├─────────────┼───────────┼────────────┼────────┤
│ PS-CNN │ 89.34% │ 91.43% │ 85.00% │
│ ABFormer │ 90.80% │ 90.00% │ 84.70% │
│ WFF-Net │ 91.20% │ 94.11% │ 85.70% │
└─────────────┴───────────┴────────────┴────────┘亮点:
- F1-measure提升2.7%(相比PS-CNN)
- 在所有三个指标上都达到最优
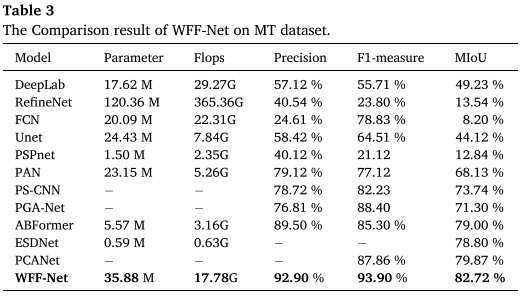
MT数据集结果
┌─────────────┬───────────┬────────────┬────────┐
│ 方法 │ Precision │ F1-measure │ MIoU │
├─────────────┼───────────┼────────────┼────────┤
│ ABFormer │ 89.50% │ 85.30% │ 79.00% │
│ ESDNet │ - │ - │ 78.80% │
│ WFF-Net │ 92.90% │ 93.90% │ 82.72% │
└─────────────┴───────────┴────────────┴────────┘亮点:
- MIoU提升3.72%(相比ABFormer)
- 在小缺陷检测上表现优异
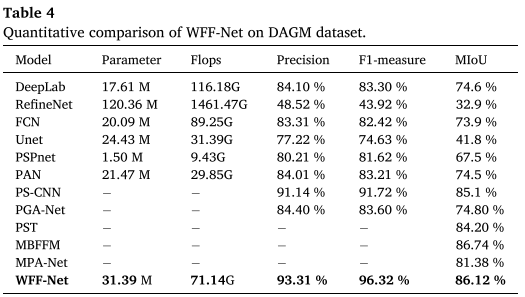
DAGM数据集结果
┌─────────────┬───────────┬────────────┬────────┐
│ 方法 │ Precision │ F1-measure │ MIoU │
├─────────────┼───────────┼────────────┼────────┤
│ PS-CNN │ 91.14% │ 91.72% │ 85.10% │
│ MBFFM │ - │ - │ 86.74% │
│ WFF-Net │ 93.31% │ 96.32% │ 86.12% │
└─────────────┴───────────┴────────────┴────────┘亮点:
- F1-measure提升4.6%(相比PS-CNN)
- 在纹理缺陷检测上表现突出
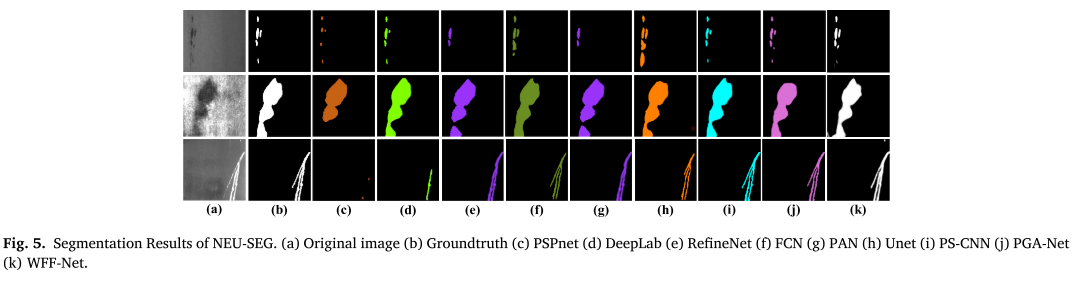
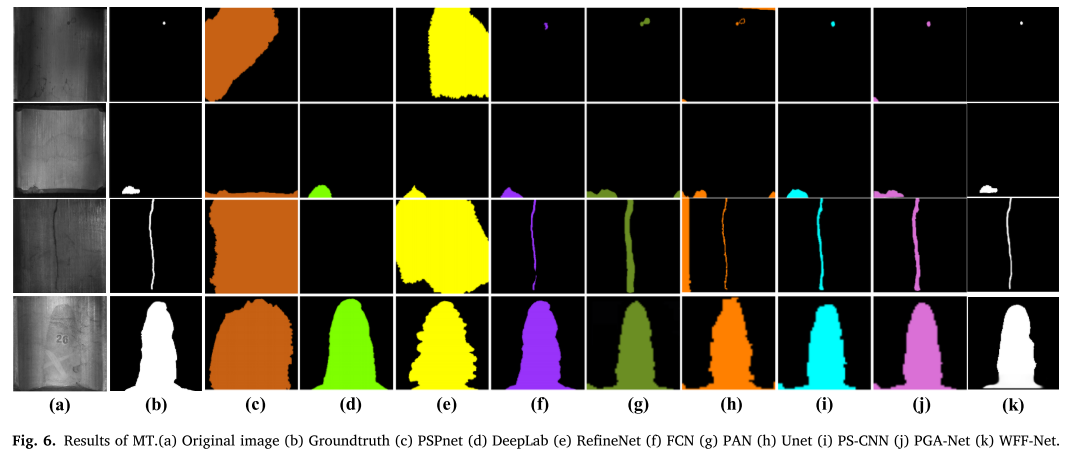
可视化对比
从论文的可视化结果可以看出:
- 边界更清晰:WFF-Net的分割边界明显更接近真实标注
- 小缺陷不遗漏:对于点状、线状小缺陷检测更准确
- 噪声抑制好:背景区域的误检明显减少
消融实验:每个创新都至关重要
1. 特征融合方法的影响
Baseline (无融合) → 84.10% MIoU
NFF (简单融合) → 84.41% (+0.31%)
WFF* (加Gate) → 85.12% (+0.71%)
WFF (加Gate+注意力) → 85.70% (+0.58%)结论:每一步改进都带来了性能提升!
2. 注意力机制的选择
研究团队测试了多种注意力机制:
| 注意力类型 | NEU-SEG MIoU | 说明 |
|---|---|---|
| SE | 84.22% | 传统通道注意力 |
| CoordAttention | 84.56% | 坐标注意力 |
| ELA | 85.34% | 局部高效注意力 |
| EMA | 85.70% | 多尺度高效注意力(最优) |
结论:EMA注意力机制最适合这个任务!
3. FCU的作用
双解码器(无FCU) → 83.72% MIoU
双解码器(有FCU) → 84.11% MIoU (+0.39%)结论:特征补偿机制确实有效减少了特征损失!
技术细节:如何复现
网络架构
输入图像 (H×W×3)
↓
ResNet-50 编码器
├─ F1: H/2 × W/2 × 64
├─ F2: H/4 × W/4 × 256
├─ F3: H/8 × W/8 × 512
├─ F4: H/16 × W/16 × 1024
└─ F5: H/32 × W/32 × 2048
↓
WFF模块 (4层)
├─ WFF1: 融合F1, F2, F3
├─ WFF2: 融合F2, F3, F4
├─ WFF3: 融合F3, F4, F5
└─ WFF4: 融合F4, F5
↓
双解码器模块
├─ Decoder1 + FCU + Decoder2
└─ 输出: P1, P2, O1-O4
↓
分割结果 (H×W×1)训练策略
- 优化器:Adam
- 学习率:0.0001(每50个epoch减半)
- 训练轮数:200 epochs
- 数据增强:水平翻转、垂直翻转、颜色抖动
- 损失函数:WBCE + ωIoU
计算资源
- 参数量:35.88M
- FLOPs:17.78G (NEU-SEG)
- GPU:RTX 2080Ti
- 推理速度:适用于实时工业检测
局限性与未来方向
论文作者诚实地指出了WFF-Net的三个局限性:
1. 骨干网络不够轻量
现状 :使用ResNet-50作为特征提取器 问题 :在移动设备或边缘计算场景下可能较慢 未来方向:研究轻量级特征提取网络
2. 推理速度有待提升
现状 :特征融合和双解码器消耗较多计算资源 问题 :可能影响实时性要求高的应用 未来方向:设计更高效的融合和解码方法
3. 边界特征提取能力
现状 :在复杂边界的分割上还有提升空间 问题 :对于边缘模糊的缺陷检测精度有限 未来方向:研究专门的边界特征提取模块
实际应用建议
根据论文的实验结果,我给出以下应用建议:
适用场景
✅ 强烈推荐:
- 钢材表面缺陷检测
- 纺织品缺陷检测
- 磁瓦等陶瓷材料检测
- 需要精确分割边界的场景
- 小缺陷检测
⚠️ 需要评估:
- 实时性要求极高的场景(需要优化)
- 边缘计算设备(可能需要模型压缩)
- 超高分辨率图像(可能需要分块处理)
部署建议
-
数据准备:
- 确保有pixel-level标注
- 数据增强策略必不可少
- 训练:验证:测试 = 7:1:2
-
超参数设置:
- 初始学习率:0.0001
- Batch size:根据GPU内存调整(建议8-16)
- 图像尺寸:256×256或512×512
-
性能优化:
- 使用混合精度训练加速
- 考虑知识蒸馏压缩模型
- TensorRT等推理加速工具
总结与展望
WFF-Net通过三个核心创新------可学习的加权特征融合 、双解码器架构 和结构化损失函数------成功解决了多尺度特征融合中的语义差异和特征冗余问题。在三个公开数据集上的实验结果充分验证了方法的有效性。
核心贡献
- ✨ 提出Gate模块实现自适应特征加权
- ✨ 设计双解码器减少特征损失
- ✨ 构建多层次监督的损失函数
- ✨ 在多个数据集上达到SOTA性能
研究价值
- 理论价值:为多尺度特征融合提供了新思路
- 实用价值:可直接应用于工业质检场景
- 启发意义:Gate机制可迁移到其他视觉任务
未来展望
随着智能制造的发展,表面缺陷检测技术将朝着以下方向演进:
- 轻量化:适配边缘设备的轻量级模型
- 实时化:满足生产线实时检测需求
- 泛化性:少样本学习和跨域迁移能力
- 可解释性:提供缺陷形成原因的分析
WFF-Net为这些方向提供了坚实的技术基础,期待看到更多基于这项工作的后续研究和工业应用!