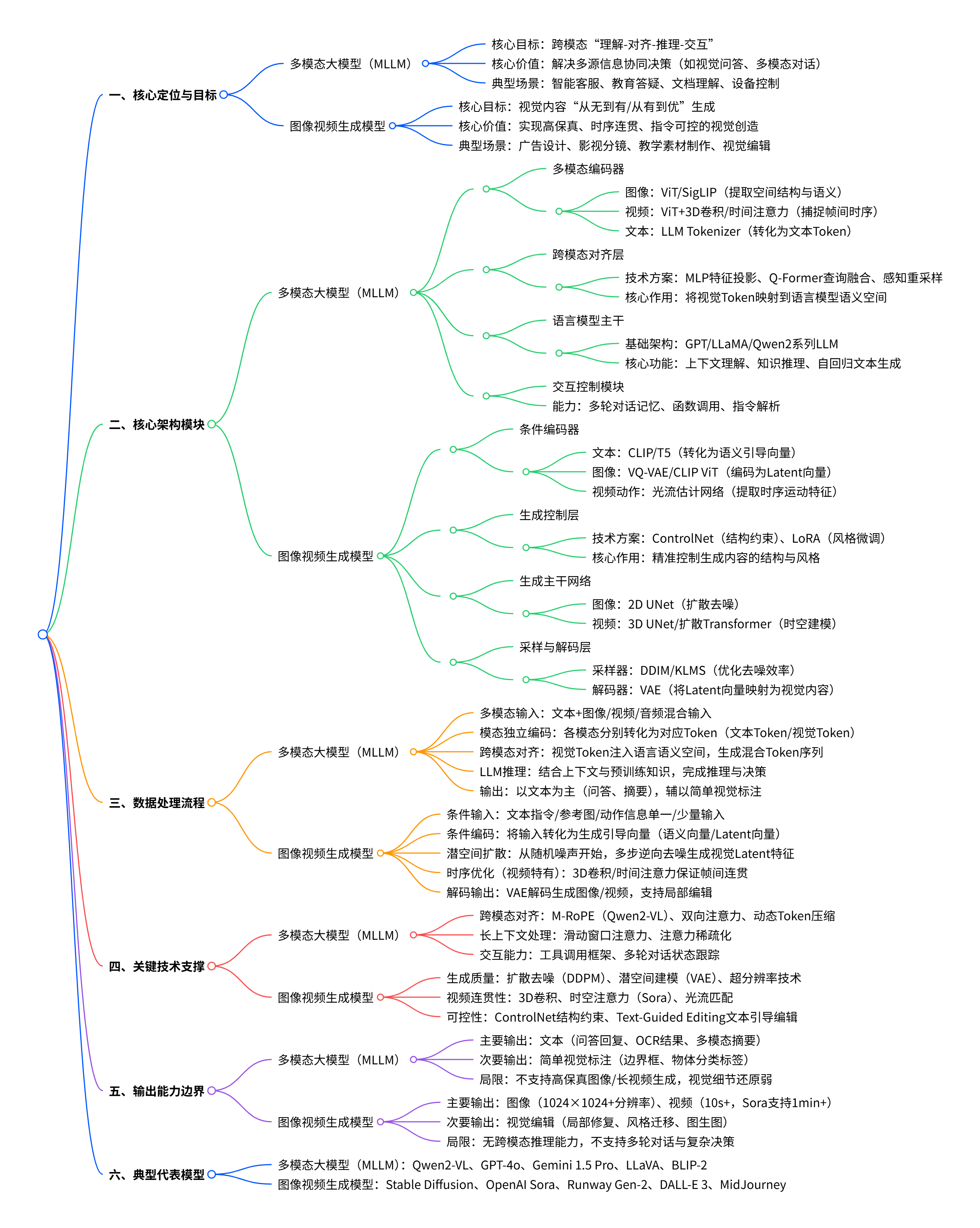
在 AI 技术从 "单一能力" 向 "通用智能" 演进的过程中,多模态大模型(MLLM)与图像视频生成模型成为两大核心技术分支。前者聚焦跨模态信息的 "理解与协同",后者专注视觉内容的 "创造与生成",二者既存在技术路径差异,又在实际应用中深度融合,共同推动 AI 在内容创作、人机交互等领域的落地。
一、定义与边界:核心目标与能力差异
多模态大模型与图像视频生成模型虽均涉及视觉模态,但核心定位与能力范围存在显著区别,可通过 "能力矩阵" 清晰划分:
| 维度 | 多模态大模型(MLLM) | 图像视频生成模型 |
|---|---|---|
| 核心目标 | 打破模态壁垒,实现 "理解 - 推理 - 交互" 全链路跨模态处理 | 从无到有 / 从有到优生成视觉内容,聚焦 "保真度 - 连贯性 - 可控性" |
| 输入模态 | 文本、图像、音频、视频等多模态混合输入(如 "图片 + 语音提问") | 文本、图像、动作骨架等单一 / 少量条件输入(如 "文本描述""参考图") |
| 输出模态 | 以文本为主(如问答回复、内容总结),部分支持简单视觉输出 | 以图像 / 视频为主(如文生图、图生视频),输出类型单一但精度高 |
| 关键能力 | 跨模态语义对齐(如图文消歧)、复杂推理(如视觉问答)、多轮交互 | 视觉细节还原(如纹理生成)、时序一致性(如视频帧间运动)、风格控制 |
| 典型任务 | 视觉问答(VQA)、文档理解(OCR + 语义分析)、多模态对话 | 文生图、图生图、文生视频、视频编辑(如局部修复) |
| 代表模型 | GPT-4o、Gemini 1.5 Pro、Qwen-VL、LLaVA | Stable Diffusion、Sora、Runway Gen-2、DALL-E 3 |
简言之,多模态大模型是 "全能理解者与交互者",擅长整合多源信息解决复杂问题;图像视频生成模型是 "专精创造者",专注于高质量视觉内容的生成与优化,二者在技术目标上形成互补。
二、技术架构:从模块设计看本质差异
两类模型的架构设计围绕核心目标展开,多模态大模型强调 "跨模态融合",图像视频生成模型聚焦 "视觉生成效率与质量",具体模块差异如下:
2.1 多模态大模型(MLLM):以 "理解" 为核心的架构
典型 MLLM 遵循 "模态编码→跨模态对齐→语言模型推理" 的三阶段架构,部分需生成视觉内容时会引入 "专用生成器",但非核心组件:
-
模态编码器:处理非文本输入的 "感知入口"
- 图像输入:采用 ViT、CLIP、SigLIP 等视觉编码器,提取图像的空间结构与高层语义(如将图像切分为 16×16 Patch Token);
- 视频输入:在图像编码器基础上增加 3D 卷积(如 Qwen2-VL)或时间注意力(如 Gemini 1.5 Pro),捕捉帧间时序关系;
- 核心目标:将视觉信号转化为 "机器可理解" 的语义特征,而非 "生成可用" 的细节特征。
-
跨模态对齐模块:连接 "感知" 与 "理解" 的核心桥梁这是 MLLM 的技术核心,需将视觉特征映射到语言模型的语义空间,常见方式包括:
- 特征投影(如 LLaVA):通过 MLP 将视觉特征直接映射为语言 Token,结构简洁但对齐精度有限;
- 查询式融合(如 BLIP-2 Q-Former):用可学习查询向量从视觉特征中提取关键语义,生成固定数量的视觉 Token,适合精细对齐;
- 感知重采样(如 Flamingo):将高维视觉 Token 压缩为语义密集的 Latent Token,动态注入语言模型各层,支持灵活融合。
-
语言模型主干:MLLM 的 "推理与交互引擎"基于 LLM(如 GPT-4、LLaMA 系列)构建,负责:
- 整合多模态上下文(如判断 "文本描述与图像内容是否一致");
- 调用预训练知识进行推理(如根据 "数学题图像" 生成解题步骤);
- 以自回归方式生成文本输出(如视觉问答回复、多模态对话)。
-
可选专用生成器:仅在需视觉生成时引入多数 MLLM 不内置视觉生成能力,若需支持文生图等任务,会外接扩散模型(如 Qwen2vl-Flux 复用 Qwen2-VL 的理解模块,外接 FLUX 扩散生成器),生成器仅作为 "工具",不参与核心理解与推理。
2.2 图像视频生成模型:以 "生成" 为核心的架构
视觉生成模型的架构围绕 "从噪声 / 条件生成高质量视觉内容" 设计,核心是 "生成器 + 时序建模(视频特有)",不依赖复杂的跨模态理解模块:
-
主流生成架构:扩散模型为主导目前 90% 以上的高质量视觉生成模型采用扩散模型(如 Sora、Stable Diffusion),核心流程为 "前向扩散(加噪)→逆向去噪":
- 前向扩散:将真实图像 / 视频逐步添加高斯噪声,直至变为随机噪声;
- 逆向去噪:训练 UNet/Transformer 主干网络,学习从噪声中逐步恢复真实内容,过程中通过 "条件引导"(如文本、参考图)控制生成方向;
- 优势:生成质量高、细节丰富,支持高分辨率输出(如 Stable Diffusion 可生成 1024×1024 图像)。
-
视频生成的额外挑战:时序一致性相比图像生成,视频生成需额外解决 "帧间运动连贯" 问题,常见技术包括:
- 时空卷积(3D-CNN):直接在 "帧序列 × 空间尺寸" 的时空体上提取特征,建模局部运动(如物体平移);
- 时间注意力(Temporal Attention):用 Transformer 机制跨帧建模长时依赖(如 Sora 的扩散 Transformer,捕捉人物行走的连贯轨迹);
- 光流建模(Optical Flow):显式计算帧间像素运动方向,用于优化帧间过渡自然度(如 Runway Gen-2)。
-
条件控制模块:确保生成内容符合指令为实现 "文本→视觉""图像→视觉" 的精准映射,需引入条件编码与引导机制:
- 文本条件:用 CLIP、T5 等强文本编码器将文本指令转化为语义向量,通过交叉注意力注入扩散模型(如 DALL-E 3);
- 图像条件:用 VQ-VAE 将参考图编码为潜在向量,引导生成内容的风格 / 结构一致性(如图生图任务);
- 控制网络(ControlNet):输入边缘、深度等结构化信息,精确控制生成内容的轮廓(如 "根据线稿生成彩色插画")。
三、协同机制:从 "独立工作" 到 "互补融合"
随着 AI 应用场景的复杂化,多模态大模型与图像视频生成模型不再孤立,而是形成 "MLLM 负责理解交互 + 生成模型负责视觉创造" 的协同链路,典型融合方式有三类:
3.1 管线式协同:MLLM 为生成模型提供 "精准指令"
这是最成熟的融合方式,MLLM 作为 "任务规划者",将用户模糊需求转化为生成模型可执行的精细指令,生成模型作为 "执行者" 完成视觉创作:
-
案例 1:多模态对话中的内容生成用户输入 "生成一张'未来科技城市夜景'的图,要有飞屋和霓虹灯光",流程为:
- MLLM 理解需求:拆解 "场景(科技城市夜景)、核心元素(飞屋、霓虹灯)、风格(未来感)";
- 指令优化:将自然语言转化为生成模型适配的结构化提示(如 "a futuristic city at night with floating houses and neon lights, hyper-detailed, 8k resolution");
- 调用生成模型:将优化后的提示输入 Stable Diffusion,生成图像后返回用户。
-
案例 2:视觉问答与生成结合用户输入 "这张数学题图像的解题步骤是什么?再生成一张辅助理解的示意图",流程为:
- MLLM(如 Qwen2-VL)解析图像中的数学题,生成文字解题步骤;
- MLLM 根据解题步骤,生成示意图的文本描述(如 "生成一个直角三角形,标注直角边长度 3cm 和 4cm,斜边长度 5cm");
- 调用扩散模型生成示意图,与文字步骤共同返回。
这种协同的核心价值在于:MLLM 解决了 "生成模型难以理解复杂需求" 的痛点,生成模型弥补了 MLLM "视觉生成能力薄弱" 的短板。
3.2 架构级融合:生成模型嵌入 MLLM,实现 "端到端多模态生成"
部分先进模型将生成模型的核心模块(如扩散主干)嵌入 MLLM 架构,实现 "理解 - 生成" 的端到端链路,典型代表为 UniTok、Nexus-Gen 等模型:
-
技术关键点:
- 统一视觉 Tokenizer:用多码本量化(MCQ)技术设计兼顾 "理解" 与 "生成" 的视觉 Token(摘要 5)------ 既保留 CLIP 的语义对齐能力,又通过多子码本提升 Token 的细节表达力,解决 "理解型 Token 细节不足、生成型 Token 语义薄弱" 的矛盾;
- 共享语义空间:将视觉 Token 与文本 Token 映射到同一嵌入空间,MLLM 可直接用自回归方式生成视觉 Token 序列,再通过内置的扩散解码器转化为图像 / 视频;
- 优势:无需外接生成模型,支持 "文本问答→图像生成→多轮修改" 的无缝交互(如用户说 "把生成的图中飞屋颜色改为蓝色",模型可直接理解并优化)。
-
案例:UniTok 统一 Tokenizer 的应用(摘要 5)字节跳动的 UniTok 通过多码本量化,将视觉特征切分为 8 个 8 维子向量,每个子向量用独立码本量化,既扩大了 Token 的表达空间(潜在编码组合数指数级提升),又保留了语义对齐能力。基于 UniTok 的 MLLM 可同时完成:
- 理解任务:DocVQA 文档问答(准确率接近 CLIP);
- 生成任务:文生图(FID 指标接近 Stable Diffusion),实现 "一套架构,两类能力"。
3.3 反馈式协同:MLLM 对生成结果进行 "质量优化"
生成模型常因 "语义理解偏差" 生成不符合需求的内容(如用户要 "可爱的猫咪",却生成 "写实风格的老虎"),此时 MLLM 可作为 "评估者与修正者",形成反馈闭环:
-
流程:
- 生成模型初步生成视觉内容;
- MLLM 评估生成结果与用户需求的一致性(如 "生成的是老虎,不符合'猫咪'需求,且风格偏写实,需调整为卡通风格");
- MLLM 生成修正指令(如 "生成一只卡通风格的橘色猫咪,坐姿,背景为草地");
- 生成模型根据修正指令重新生成,直至符合需求。
-
技术支撑:MLLM 的跨模态一致性判断能力(如 GPT-4o 的 DocVQA 准确率达 92.8%(摘要 3)),可精准识别生成内容与指令的偏差,为修正提供依据。
四、典型案例:融合应用的落地场景
两类模型的协同已在多个领域落地,覆盖内容创作、教育、医疗等,以下为三类典型场景:
4.1 智能内容创作:从 "需求拆解" 到 "多轮优化"
- 场景:广告公司为某饮料品牌设计春节海报,用户需求为 "体现'团圆'主题,有饮料瓶、灯笼元素,中国风风格";
- 协同链路 :
- MLLM(如 GPT-4o)拆解需求:提取 "核心元素(饮料瓶、灯笼)、主题(团圆)、风格(中国风)、应用场景(春节海报)";
- MLLM 生成结构化提示:"a Chinese-style Spring Festival poster with a family reunion scene, featuring the brand's beverage bottles and red lanterns, warm color palette, traditional paper-cutting elements";
- 生成模型(如 DALL-E 3)根据提示生成 3 版海报;
- MLLM 评估海报:指出 "第 1 版缺少'团圆'元素(无人物),第 2 版饮料瓶不明显",生成修正提示;
- 生成模型重新生成,最终输出符合需求的海报。
- 价值:将传统 "设计师 1 天出 3 版" 的流程缩短至 10 分钟,且支持快速迭代优化。
4.2 教育领域:"理解知识点 + 生成辅助素材"
- 场景:教师需要 "讲解'三角形面积公式',并生成动态演示视频";
- 协同链路 :
- MLLM(如 Qwen2-VL)理解教学需求:拆解 "知识点(三角形面积 = 底 × 高 / 2)、教学步骤(公式推导→例题→动态演示)";
- MLLM 生成文字教案与视频描述(如 "生成一个动态视频:先显示直角三角形,再将两个全等三角形拼成矩形,演示面积公式推导过程");
- 生成模型(如 Sora)根据描述生成 30 秒演示视频;
- MLLM 结合视频与教案,生成 "视频 + 文字" 的完整教学素材,支持学生边看视频边听讲解。
- 价值:将教师 "制作动态教学素材" 的时间从数小时缩短至分钟级,且素材更贴合知识点逻辑。
4.3 医疗领域:"影像理解 + 辅助生成"
- 场景:医生需要 "分析患者肺部 CT 影像,生成病情报告,并制作病灶标注示意图";
- 协同链路 :
- MLLM(如 GPT-4V 医疗版)解析 CT 影像:识别 "右肺下叶结节(直径 5mm)、无胸腔积液",生成文字报告;
- MLLM 生成示意图描述(如 "生成肺部 CT 示意图,用红色方框标注右肺下叶 5mm 结节,标注结节位置与大小");
- 生成模型(如医疗专用 Stable Diffusion)根据描述生成标注图,与文字报告整合;
- 医生基于整合结果与患者沟通,或用于病历存档。
- 价值:减少医生 "影像分析 + 报告撰写 + 标注图制作" 的重复工作,提升诊疗效率。
五、发展趋势:从 "协同" 到 "统一"
未来,两类模型将逐步从 "管线式协同" 走向 "架构级统一",核心趋势有三:
5.1 统一模态表示:解决 "理解 - 生成" 的 Token 冲突
当前融合的核心瓶颈是 "视觉 Token 的表达差异"------ 理解任务需要语义密集的 Token,生成任务需要细节密集的 Token。未来将通过 "多码本量化""动态 Token 生成" 等技术,设计兼顾两类需求的统一 Token(如 UniTok 的多码本方案(摘要 5)),实现 "一套 Token,两类能力"。
5.2 端到端多模态生成:MLLM 内置高效生成能力
现有融合需 "MLLM→生成模型" 的跨模型调用,未来将通过 "扩散 Transformer 统一架构",让 MLLM 直接学习视觉生成的反向去噪过程,无需外接生成器。例如,将扩散模型的 UNet 主干与 Transformer 语言模型结合,实现 "文本理解→视觉生成" 的端到端训练,降低部署复杂度。
5.3 可控性与安全性提升:MLLM 主导生成内容的合规性
随着生成模型能力增强,"深度伪造""版权侵权" 等风险凸显。未来 MLLM 将承担 "内容审核与控制" 角色:
- 生成前:过滤违规需求(如 "生成虚假明星视频");
- 生成中:通过条件引导确保内容合规(如 "生成的人物面部不与真实个体重合");
- 生成后:验证内容的版权归属(如 "检测生成图像是否包含受版权保护的元素"),实现 "生成 - 审核 - 溯源" 的全链路可控。
六、总结:两类模型的 "共生关系"
多模态大模型与图像视频生成模型并非 "替代关系",而是 "共生互补":
- 多模态大模型拓展了生成模型的 "应用边界",让视觉生成从 "单一指令" 走向 "复杂场景交互";
- 图像视频生成模型提升了多模态大模型的 "落地价值",让跨模态理解从 "文本输出" 走向 "视觉创造"。
未来,随着技术的统一与融合,或将诞生 "既能深度理解多模态信息,又能高效生成高质量视觉内容" 的通用多模态智能体,进一步推动 AI 在内容创作、智能交互、工业设计等领域的智能化升级。