文章目录
- 摘要
- [1. 引言](#1. 引言)
- [2. 相关工作](#2. 相关工作)
- [3. 方法](#3. 方法)
-
- [3.1 任务内推理(IntraTR)用于时间异常检测](#3.1 任务内推理(IntraTR)用于时间异常检测)
- [3.2 任务间链式连接(InterTC)用于整体异常分析](#3.2 任务间链式连接(InterTC)用于整体异常分析)
- [4. 实验](#4. 实验)
-
- [4.1 实验设置](#4.1 实验设置)
- [4.2 VAD 结果](#4.2 VAD 结果)
- [4.3 VAL 结果](#4.3 VAL 结果)
- [4.4 VAU 结果](#4.4 VAU 结果)
- [5. 结论](#5. 结论)
A Unified Reasoning Framework for Holistic Zero-Shot Video Anomaly Analysis
NIPS'25
北京交通大学 信息科学研究所;英国 伯明翰大学 MIx 课题组
这篇论文的创新是提出了一个统一的、零样本的推理框架,能够在无需额外训练的情况下,结合时间检测、空间定位和文本理解任务,实现全面的视频异常分析。
有一个自适应的阈值选择可以学习一下。
摘要
大多数视频异常研究停留在逐帧检测上,对事件为何异常几乎没有提供任何洞见,通常只输出缺乏空间或语义上下文的逐帧异常分数。近期的视频异常定位和视频异常理解方法提升了可解释性,但仍然依赖数据且任务特定。我们提出了一个统一的推理框架,用于弥合时间检测、空间定位和文本解释之间的差距。我们的方法构建在一个串联的测试时推理过程之上,该过程按顺序连接这些任务,使得在无需任何额外训练的情况下实现整体的零样本异常分析。具体来说,我们的方法利用任务内推理来细化时间检测,并通过任务间链式连接进行空间和语义理解,从而在完全零样本的方式下提高可解释性和泛化能力。在没有任何额外数据或梯度的情况下,我们的方法在多个视频异常检测、定位和解释基准上取得了最先进的零样本性能。结果表明,通过带有任务链式连接的精心提示设计,可以释放基础模型的推理能力,从而在完全零样本的方式下实现实用且可解释的视频异常分析。项目页面:https://rathgrith.github.io/Unified_Frame_VAA/
1. 引言
视频异常分析是计算机视觉在公共安全领域的重要应用。多数早期工作将该任务表述为时间视频异常检测(Video Anomaly Detection,VAD):标记行为偏离已学习正常模式的片段。传统检测器在基准数据集上已取得较高性能,但它们仅输出逐帧分数,且无法提供关于片段为何异常的任何洞见。这些可解释性的局限推动了研究从时间检测向具有更友好且可解释输出的下游异常分析任务转移,包括空间视频异常定位(Video Anomaly Localization,VAL)Liu and Ma, 2019, Weng et al., 2022 和文本视频异常理解(Video Anomaly Understanding,VAU)任务 Du et al., 2024, Tang et al., 2024, Zhang et al., 2024b,这些方法利用经过微调的 MLLMs。尽管这些工作分别提供了空间或文本线索以提升对视频异常的可解释性,但先前的方法大多聚焦于某一类型的下游任务,无法对视频异常提供整体分析,导致现有视频异常分析方法存在"不完整性"。
另一个挑战是对特定数据集监督的严重依赖。传统 VAD 和 VAL 模型需要时间掩码或空间边界框,但不同数据集中的异常定义差异巨大 Wu et al., 2020, Lu et al., 2013, Mahadevan et al., 2010,因此在某一领域上调优的模型往往在另一领域上失效 Wu et al., 2024a。此外,在真实应用中,由于隐私和安全问题,训练数据在某些敏感场景中可能无法获取。作为部分补救,近期的研究探索了使用冻结的视觉-语言骨干或 MLLMs 的零样本和小样本方法,我们在表 1 中对此进行了总结。我们注意到,大多数基于 VLM 的工作任务范围有限,且仍依赖标注数据集。唯一严格的零样本方法仅聚焦于时间 VAD,因此可用性较差 Zanella et al., 2024。对于基于提示的方法 Yang et al., 2024, Ye et al., 2025, Wu et al., 2024b,它们不可避免地需要在标注训练集上进行归纳,但这会以通用性为代价,因为提示通常被学习得具有任务/领域特定性。这种通用性问题在经过指令调优的 MLLMs 中甚至更加突出 Tang et al., 2024, Zhang et al., 2024b,这些模型被优化为基于已见 QA 对返回答案,主要聚焦于描述一个封闭的异常类型集合 Ding and Wang, 2024。

鉴于这些问题,并且考虑到多模态 LLM 已经编码了丰富的视觉---语义先验用于常识推理 Zhao et al., 2023, Zhang et al., 2025b, Ren et al., 2025,对于某些任务而言,只要能在测试时有效地基于任务上下文进行推理,则可能无需进行微调 Minaee et al., 2025, Ma et al., 2024。特别是在视频异常分析中,我们可以将先前的各个基准任务视为在回答关于视觉异常的具体问题(何时、何地、是什么以及为什么?),其中每个问题都可以看作是促成整体分析的子问题。因此,解决这些任务自然构成了面向整体异常分析的分层推理上下文 。受到此启发,我们提出了一个统一的、基于推理驱动的链式框架,在测试时有条件地连接不同的基于 MLLM 的任务求解器。
具体而言,我们的框架在三个明确定义的阶段中系统性地运行,而不是简单地将多个独立任务串联起来。首先,初始的视频异常检测(VAD)在视频级别计算一个代理异常概率,并提取与最可疑片段对应的上下文标签列表,从而为每个样本提供个性化的上下文线索。在此之后,一个基于分数门控的细化过程利用上下文标签列表和初步异常分数执行条件得分调整,并基于推断的上下文对 VAD 任务进行细化。最后,最终的异常分数和上下文标签列表共同引导下游的空间视频异常定位(VAL)和进一步的文本视频异常理解(VAU)任务,在这些任务中,文本和视觉提示根据 VAD 分数进行动态细化。总的来说,我们框架的每一个阶段都采用冻结的视觉---语言模型(VLMs),动态提示根据前一阶段的推断迭代生成。
251113:"而不是简单地将多个独立任务串联起来",这句话感觉很关键,虽然他就是很简单,但是让人读后感觉好像他多做了一步。
我们在 UCF-Crime、XD-Violence、UBnormal 和 MSAD Sultani et al., 2018, Wu et al., 2020, Acsintoae et al., 2022, Zhu et al., 2024 上进行了广泛的实验。所提出的框架在零样本设定下的三个独立任务上都取得了最先进的性能,在 VAD 上整体 AUC 提升了 4--6%,并在 VAL 和 VAU 任务的多种度量上获得了持续改进。这些结果表明,我们的无训练、统一的视频异常分析框架具有可解释性、可扩展性,并且在不同领域与任务间表现出强鲁棒性。
2. 相关工作
传统视频异常分析。 早期的视频异常检测(VAD)工作通常落入三种主要监督范式:one-class 模型只在正常片段上训练,并使用紧凑的嵌入或记忆库来检测离群点 Sohrab et al., 2018, Wang and Cherian, 2019, Micorek et al., 2024;完全 unsupervised 的方法依赖重建或未来帧预测损失 Hasan et al., 2016, Thakare et al., 2022;以及 weakly-supervised 的 MIL 框架使用视频级标签对异常片段进行排序 Sultani et al., 2018, Feng et al., 2021, Joo et al., 2023。上述所有方法在处理未见领域或未见异常类型时都需要重新训练,并且无法为其决策提供语义上的解释 Ramachandra et al., 2020, Wu et al., 2024b。为了解决这一点,open-set 检测器出现:OVVAD 将 LLM 语义融合到系统中,使其能够检测并分类新颖异常 Wu et al., 2024a。然而,这类 open-set 检测器仍然需要任务特定训练,且仅在为何某些帧可能异常方面提供有限的文本洞见,因此推动了向更超越时间检测的任务表述、面向视觉---语言解决方案的转变。
基于 VLM 的视频异常分析。 LAVAD Zanella et al., 2024 引入了一个完全 无需训练 的时间检测管线:冻结的 VLM 为每帧生成描述;一个提示式 LLM 将描述流转换为逐帧异常分数,再由基础模型集成进一步优化。该方法在异常与正常明显可区分时效果显著,但在区分更复杂的异常类型时表现欠佳 Ding and Wang, 2024,并缺乏直接的语义解释,仅提供默认的 VLM 描述与计算出的异常分数。Prompt-tuning 变体 Du et al., 2024, Wu et al., 2024b, Yang et al., 2024, Ye et al., 2025 针对特定任务优化文本提示以指导冻结的 VLMs。尽管这些方法表现强劲,但仍依赖标注数据并受限于任务范围 Zhang et al., 2024b。
视频异常理解与多模态 LLMs。 随着对更深层语义推理的需求,像 Hawk Tang et al., 2024 和 Holmes-VAU Zhang et al., 2024b 等指令微调方法在带异常描述的视频片段上微调 VLMs,以生成叙事性解释。这些方法在描述准确性方面取得了显著进展,但需要大量标注与计算资源,并仍然局限于已见异常类型 Liu et al., 2025。
总而言之,我们观察到:严格零样本方法如 Zanella et al. 2024 支持时间检测,但缺乏空间 grounding 和文本洞见。Prompt-tuning 变体 Du et al., 2024, Wu et al., 2024b, Ye et al., 2025 主要聚焦于少量任务/领域,因为提示通常具有任务/领域特定性。指令微调模型 Tang et al., 2024, Zhang et al., 2024b 产生丰富的叙事解释,但缺乏时间或空间覆盖,且带来高标注成本。这些差距促使我们努力在零样本设定下统一这些任务。
3. 方法
我们在图 1 中展示了该框架的整体概述。视频异常分析任务被分解为三个主要子任务,如先前工作中所定义,而我们的框架利用了它们之间的内在关联。我们的统一框架可总结为两个主要组成部分:1)任务内推理(Intra-Task Reasoning,IntraTR),通过时间视频异常检测(VAD)任务提取异常先验,并通过一个带门控的额外推理步骤进一步细化时间检测;2)基于 IntraTR 中的推理过程,额外的任务间链式连接(Inter-Task Chaining,InterTC)将从初始 VAD 结果中提取的标签列表和时间分数结果连接起来,以级联方式支持后续的定位与理解任务。每个组成部分的详细解释分别在第 3.1 节和第 3.2 节中提供。
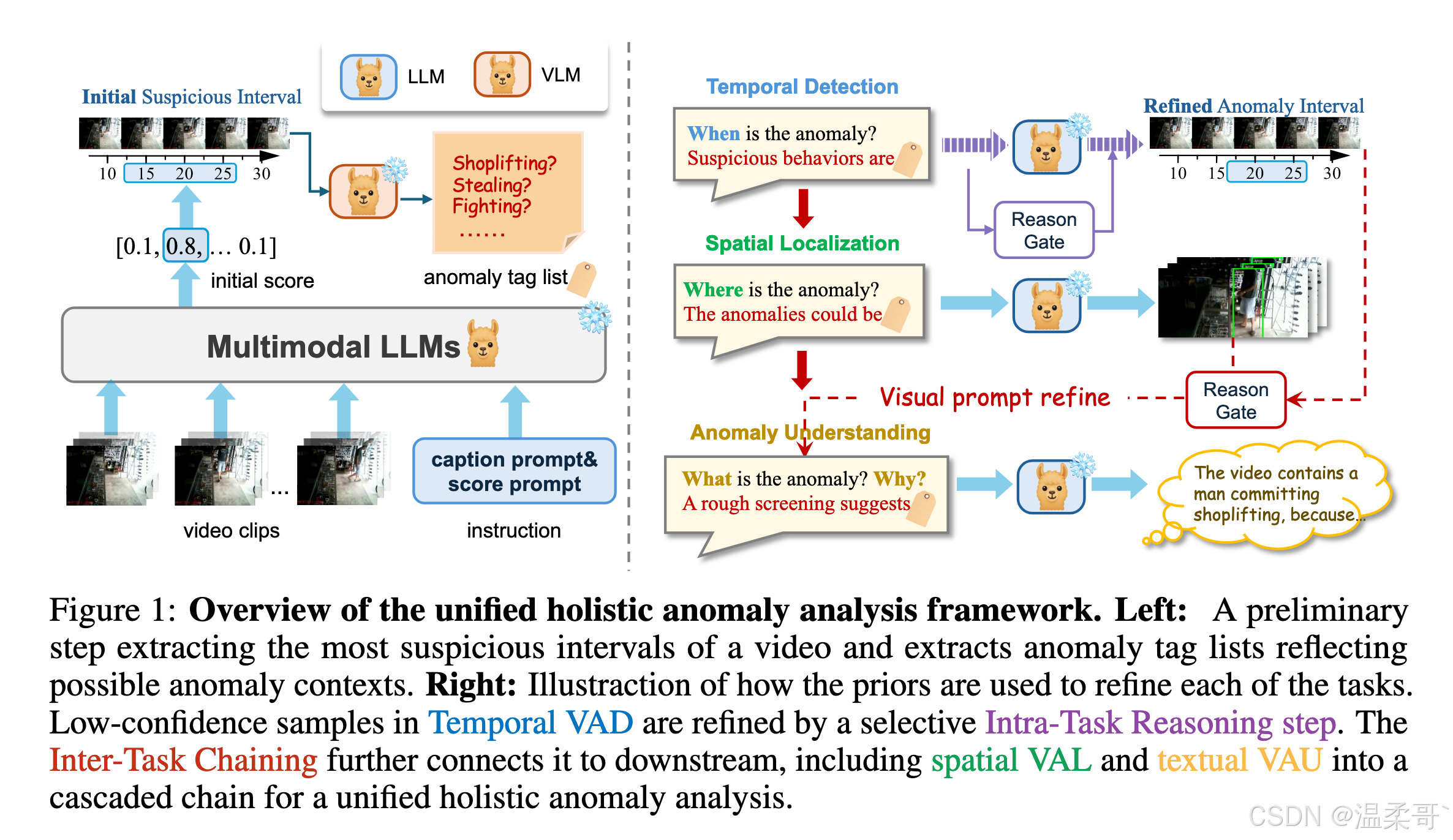
251113:这个图看起来只用了一次大模型,但其实左侧的初始步骤就用了两次大模型,然后右侧这里的推理门,感觉就是对第一阶段的一个分数的修正呗。
3.1 任务内推理(IntraTR)用于时间异常检测
问题表述。
VAD 可以被表述为逐帧的二分类(0-1)。理想情况下,对于每个输入帧 f i f_i fi,目标是预测一个异常概率 s i s_i si。对于使用 LLM 和 VLM 的基线方法 Zanella et al., 2024,其公式可表示为:
s i = θ LLM ( p VAD ⊕ θ VLM ( c i , p caption ) ) , S V = s 1 , ... , s T , (1) s_i = \theta_{\text{LLM}}(p_{\text{VAD}} \oplus \theta_{\text{VLM}}(c_i, p_{\text{caption}})), \quad S_V = s_1, \\ldots, s_T, \tag{1} si=θLLM(pVAD⊕θVLM(ci,pcaption)),SV=s1,...,sT,(1)
其中 T T T 是视频 V V V 的帧数, c i c_i ci 是表示帧 f i f_i fi 周围事件的短视频片段, p VAD p_{\text{VAD}} pVAD 与 p caption p_{\text{caption}} pcaption 分别表示用于视频异常检测和视频描述的提示词。向量 S V S_V SV 因此为每一帧提供一个第一次估计的异常结果,且无需微调。
然而,超越这一基线,我们能否进一步利用 S V S_V SV 来提升推理能力?
为回答这一问题,我们的 VAD 流水线将 S V S_V SV 不仅视为最终答案,还作为一个起点,用于在测试时执行结构化的任务内推理步骤。图 2 提供了所提 IntraTR 流水线的概览。
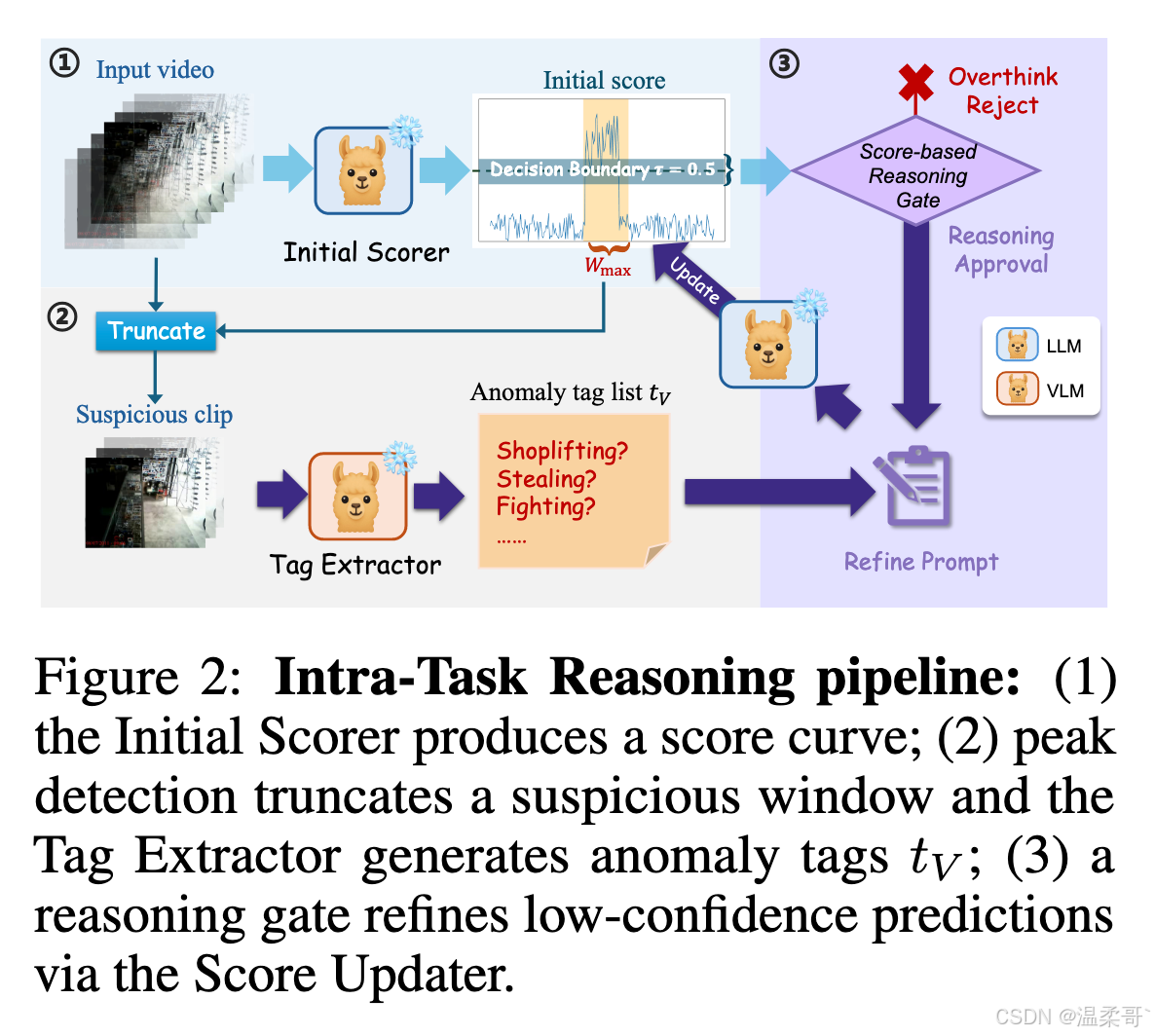
基于分数的异常提取。 为了识别视频中潜在存在的异常,我们首先进行一次前向传播,得到该视频的逐帧异常分数 S V = s 1 , ... , s T S_V = s_1, \\ldots, s_T SV=s1,...,sT,其中视频 V V V 共有 T T T 帧,每个 s i ∈ 0 , 1 s_i \in 0,1 si∈0,1。直观地说,一个异常事件 e e e 应当占据一个连续的窗口 W e = { t , ... , t + ℓ − 1 } W_e = \{t, \ldots, t + \ell - 1\} We={t,...,t+ℓ−1},其中 ℓ ≪ ∣ S V ∣ \ell \ll |S_V| ℓ≪∣SV∣ 表示一个局部片段。将任意窗口 W W W 内的平均分数记为
μ ( W ) = 1 ∣ W ∣ ∑ j ∈ W s j \mu(W) = \frac{1}{|W|} \sum_{j \in W} s_j μ(W)=∣W∣1∑j∈Wsj。根据异常事件应当持续保持较高分数的直觉,在一段异常视频中,我们期望能找到:
∃ W e : ∣ W e ∣ = ℓ , such that μ ( W e ) ≥ τ , (2) \exists W_e : |W_e| = \ell,\ \text{such that } \mu(W_e) \ge \tau, \tag{2} ∃We:∣We∣=ℓ, such that μ(We)≥τ,(2)
其中 τ \tau τ 是一个自然的决策边界(例如 τ = 0.5 \tau = 0.5 τ=0.5)。
为了判断视频中是否存在这样的窗口 W e W_e We,在推理阶段,我们滑动一个长度为 ℓ \ell ℓ 的可行窗口并选取:
W max = arg max W ⊆ { 1 , ... , T } , ∣ W ∣ = ℓ μ ( W ) , (3) W_{\max} = \arg\max_{W \subseteq \{1,\ldots,T\},\, |W| = \ell} \mu(W), \tag{3} Wmax=argW⊆{1,...,T},∣W∣=ℓmaxμ(W),(3)
s ~ V = μ ( W max ) , (4) \tilde{s}V = \mu(W{\max}), \tag{4} s~V=μ(Wmax),(4)
其中 W max W_{\max} Wmax 是最可疑的片段,而 s ~ V ∈ 0 , 1 \tilde{s}V \in 0,1 s~V∈0,1 是视频级的代理异常概率。在确定了由 W max W{\max} Wmax 指示的视频中最可疑的部分 V sus V_{\text{sus}} Vsus 之后,我们通过查询 VLM 提取与异常相关的文本上下文,生成一个简洁短语列表 t V t_V tV,用于概括视频片段 V sus V_{\text{sus}} Vsus 中可能相关的异常活动,如下所示:
V sus = f j , j ∈ W max , (5) V_{\text{sus}} = f_j, \quad j \in W_{\max}, \tag{5} Vsus=fj,j∈Wmax,(5)
t V = θ VLM ( V sus , p extract ) . (6) t_V = \theta_{\text{VLM}}(V_{\text{sus}}, p_{\text{extract}}). \tag{6} tV=θVLM(Vsus,pextract).(6)
随后,我们将 W max W_{\max} Wmax、 s ~ V \tilde{s}_V s~V 和 t V t_V tV 传递给后续阶段以进行进一步处理。
251113:这里 p e x t r a c t p_{extract} pextract 没说是什么,可能是提示词吧。
251113:这里就是把一个视频中最可能异常的部分给提取出来了,感觉有点像 MIL,他那个假设出现异常一定会是一个片段是合理的。
基于分数的推理门。 近期研究表明,在大语言模型中,推理深度与准确性之间存在一种非单调折中关系:简短的思维链可以提升性能,而过多步骤则常常导致"过度思考"和幻觉 Huang and Chang, 2023, Chen et al., 2025。受此启发,我们仅在第一次推理结果存在歧义时触发一个额外的推理步骤,通过一个基于分数的门控组件实现,其动机如下所述。
从初始的逐帧分数 S V S_V SV 出发,我们得到视频级的代理概率 s ~ V \tilde{s}V s~V。若 s ~ V ∉ 0.5 − m , 0.5 + m \tilde{s}V \notin 0.5 - m, 0.5 + m s~V∈/0.5−m,0.5+m,则模型对其第一轮预测是有信心的,因为该预测远离决策边界 El-Yaniv and Wiener, 2010。因此,一个宽度为 2 m 2m 2m 的门控机制允许边界性/模糊的视频(即 s ~ V ∈ 0.5 ± m \tilde{s}V \in 0.5 \\pm m s~V∈0.5±m)进入第二阶段推理。结合从窗口 W max W{\max} Wmax 中提取的标签列表 t V t_V tV,任务提示被细化为 p VAD ∗ = t V ⊕ p VAD p{\text{VAD}}^{*} = t_V \oplus p{\text{VAD}} pVAD∗=tV⊕pVAD。
直观地, m m m 定量描述了"怀疑程度",它可以是一个固定值或一个与样本相关的自适应值。对于 m m m 的设置,我们提供两种选项:1)一个对所有样本固定的启发式常数,使用户可以控制怀疑程度;2)一个从当前视频估计的自适应变量 m ~ V = Var ( S V ) \tilde{m}_V = \text{Var}(S_V) m~V=Var(SV),用于反映当前视频中正常/异常帧分数的差异。我们在第 4.2 节和附录 B.1 中比较并讨论 m m m 的影响。
251113:这里的门控可以参考一下,尤其是还有自适应,他还找到了参考文献。
基于上述内容,当 s ~ V ∈ 0.5 ± m \tilde{s}_V \in 0.5 \\pm m s~V∈0.5±m 时,我们再次使用细化后的提示词查询评分 LLM:
S V ∗ = θ LLM ( p VAD ∗ ⊕ θ VLM ( c i , p caption ) ) , i = 1 , ... , T . (7) S_V^{*} = \theta_{\text{LLM}}(p_{\text{VAD}}^{*} \oplus \theta_{\text{VLM}}(c_i, p_{\text{caption}})), \quad i = 1, \ldots, T. \tag{7} SV∗=θLLM(pVAD∗⊕θVLM(ci,pcaption)),i=1,...,T.(7)
细化步骤会更新逐帧分数 S V ∗ S_V^{*} SV∗,并以其作为最终决策的依据。按照先前工作的做法 Ye et al., 2025, Tran et al., 2022,我们对细化后的分数 S V ∗ S_V^{*} SV∗ 进行标准高斯平滑 ,得到最终的预测分数 S V pred S_V^{\text{pred}} SVpred。通过将代价较高的推理步骤仅分配给边界性样本(即分数靠近不确定区域时),该方法继承了计算效率与选择性预测的鲁棒性,同时减轻了在不受限制的思维链生成中出现的"过度思考"和幻觉问题。
超越 IntraTR 辅助的 VAD 过程,我们进一步在第 3.2 节和第 3.3 节中通过 InterTC 组件将该推理步骤应用于下游任务。
3.2 任务间链式连接(InterTC)用于整体异常分析
在本节中,我们介绍 InterTC 在异常分析中的两个关键子任务中的设计:1)空间视频异常定位(VAL),以及 2)文本视频异常理解(VAU)。
从时间检测到空间定位的 InterTC。
视频异常定位(Video Anomaly Localization,VAL)的目标是在帧 f f f 中预测包含异常活动的区域对应的空间边界框。InterTC 通过一种直接的方法将 VAD 与 VAU 连接起来。具体而言,我们使用冻结的 VLM θ LOC ( p LOC ⊕ f ) \theta_{\text{LOC}}(p_{\text{LOC}} \oplus f) θLOC(pLOC⊕f),其中基础定位任务的提示词 p LOC p_{\text{LOC}} pLOC 用于指导帧 f f f 的定位。
随后,我们将从前一阶段得到的标签列表 t V t_V tV 注入到 p LOC p_{\text{LOC}} pLOC 中,通过预定义模板生成细化后的提示词 p LOC ∗ p_{\text{LOC}}^{*} pLOC∗。因此, p LOC ∗ p_{\text{LOC}}^{*} pLOC∗ 更具样本特异性,并提供更清晰的指导信息,用于空间定位,从而提升任务性能。
详细的提示词模板在附录 C.1 中给出。
级联式 InterTC 用于视频异常理解。
给定一段未裁剪的监控视频 V = ( f 1 , ... , f T ) V = (f_1, \ldots, f_T) V=(f1,...,fT),视频级异常理解(VAU)的目标是:1)判断 V V V 是否包含异常事件,以及 2)输出一个可读的描述 d ∗ d^{*} d∗ 来解释视觉输入中的异常。形式化地,有:
Θ VAU : V ⟶ ( y ^ V , d ∗ ) , y ^ V ∈ { 0 , 1 } . (8) \Theta_{\text{VAU}} : V \longrightarrow (\hat{y}_V, d^{*}), \qquad \hat{y}_V \in \{0, 1\}. \tag{8} ΘVAU:V⟶(y^V,d∗),y^V∈{0,1}.(8)
不同于早期通过指令微调训练特定任务模型的方法 Tang et al., 2024, Zhang et al., 2024b,我们的方法 Θ VAU \Theta_{\text{VAU}} ΘVAU 完全在零样本模式下运行。它复用了从前序步骤中获得的逐帧分数 S V S_V SV、标签列表 t V t_V tV 以及在时间检测和空间定位步骤中得到的可疑窗口 W max W_{\max} Wmax,并在推理阶段利用这些信息细化异常理解的提示词。
算法 1 展示了下游 VAU 任务的完整提示词细化步骤的概述,其利用来自 VAD 和 VAL 任务的推理结果。具体来说,我们首先进行 VAD-prior Prompt Refinement ,通过将标签列表 t V t_V tV 注入到 VAU 描述提示 p VAU p_{\text{VAU}} pVAU 中,形成一个更加具备上下文感知能力的最终查询提示 p VAU ∗ = t V ⊕ p VAU p_{\text{VAU}}^{*} = t_V \oplus p_{\text{VAU}} pVAU∗=tV⊕pVAU。

接下来,我们应用一个称为 Score-gated Localization Overlay 的视觉提示增强步骤。具体而言,该步骤只有在代理概率 s ~ V > 0.5 \tilde{s}V > 0.5 s~V>0.5 时才会触发------即当 VAD 检测器已经高度确信视频中存在异常时,引导我们相信基于物体层面的线索是有意义且有必要的。对于这样的 视频,我们会:1)从窗口 W max W{\max} Wmax 中采样若干帧;2)通过具备检测能力的 VLM 使用 t V ⊕ p LOC t_V \oplus p_{\text{LOC}} tV⊕pLOC 获得边界框;3)将这些边界框叠加到原视频帧上,生成带有标注的视频 V query V_{\text{query}} Vquery。如果 s ~ V ≤ 0.5 \tilde{s}_V \le 0.5 s~V≤0.5,我们跳过此步骤,直接保留视频原始、未修改的版本。
最后,VLM 接收 V query V_{\text{query}} Vquery(带标注或不带标注)以及细化后的提示 p VAU ∗ p_{\text{VAU}}^{*} pVAU∗,并输出最终描述 d ∗ d^{*} d∗。由于定位步骤仅在异常检测器高度确信存在异常时进行,这些插入的边界框作为可靠的视觉提示,而不会引入噪声杂质。
4. 实验
4.1 实验设置
数据集与评估指标。
我们在三个基准数据集的官方测试集上进行评估:
1)UCF-Crime Sultani et al., 2018(真实世界 CCTV 和众包视频,13 类异常);
2)XD-Violence Wu et al., 2020(来自电影、体育剪辑、CCTV、行车记录仪、卡通等的 800 个测试视频);
3)UBnormal Acsintoae et al., 2022(211 个完全合成的监控视频,跨 29 种虚拟环境);
4)一个较新的 MSAD Zhu et al., 2024(14 种从多视角摄取的场景,包含 360 个测试视频),其与预训练数据重叠的可能性更小。
按照先前工作,我们主要在所有数据集上评估 AUC(ROC 曲线下的面积)。由于一些研究报告了 XD-Violence 上的 AP,我们也包含 AP 作为参考。
最后,对于 视频异常理解(VAU)任务 ,为了公平评估生成描述 d ∗ d^{*} d∗ 的质量,我们采用 HVAU-70k Zhang et al., 2024b 提供的所有视频级标注。该数据集包含 1051 个视频描述,其中 251 个来自 UCF-Crime 测试集,800 个来自 XD-Violence,这一规模大于 Zhang et al. 2024b 的原始视频级测试集(398 个样本)。
除了传统 NLP 指标 Papineni et al., 2002, Vedantam et al., 2015, Banerjee and Lavie, 2005, Lin, 2004,我们还评估 GPT-guided 分数,遵循近期工作 Tang et al., 2024, Li et al., 2024a。更多细节见附录 C。
超参数与实验细节。
对于 VAD 任务,片段级评分使用完整视频并采用 stride=16 的采样方式(详见附录 C.2)。可疑窗口长度设置为 ℓ = max ( 300 , T / 10 ) \ell = \max(300, T/10) ℓ=max(300,T/10),并固定 m = 0.05 m = 0.05 m=0.05。基于 VLM 模型的文本提取,我们从窗口 W max W_{\max} Wmax 中均匀采样最多 180 帧。
在所测试的默认 VLM 和 LLM 中,我们选择 VideoLLaMA3-7B Zhang et al., 2025a 和 Llama-3.1-8B-Instruct Grattafiori et al., 2024。为减少计算量,我们将所有视频下采样到 16 的时间步。所有实验均在两块 NVIDIA GeForce RTX 3090 GPU 上进行。更多实现细节、提示词和超参数稳定性测试可见附录 C 与附录 B.1。
此外,我们采用 Qwen2.5-VL-7B Bai et al., 2025 作为 VAL 任务的默认定位 VLM,并测试了 Zhang et al. 2025a、Li et al. 2024b 与 Bai et al. 2025 的不同 VLM 变体用于 VAU 任务。此外,对于 VAL 与 VAU 任务,我们均使用来自 IntraTR 的异常先验(即 t V , s ~ V , W max t_V, \tilde{s}V, W{\max} tV,s~V,Wmax)。
对于 视频异常定位(VAL)任务 ,遵循先前工作,我们评估 temporal IoU(TIoU)Liu and Ma, 2019, Wu et al., 2024b。对于每个异常帧 f j ( j = 1 , ... , N ) f_j\ (j = 1,\ldots,N) fj (j=1,...,N),定位头 θ LOC ( f j , p LOC ∗ ) \theta_{\text{LOC}}(f_j, p_{\text{LOC}}^{*}) θLOC(fj,pLOC∗) 输出置信度 C j C_j Cj 与边界框 B j B_j Bj。TIoU 定义为:
1 N ∑ j = 1 N Area ( B j ∩ G j ) Area ( B j ∪ G j ) I C j ≥ τ , \frac{1}{N} \sum_{j=1}^{N} \frac{\text{Area}(B_j \cap G_j)}{\text{Area}(B_j \cup G_j)} \mathbb{I}C_j \\ge \\tau, N1j=1∑NArea(Bj∪Gj)Area(Bj∩Gj)ICj≥τ,
其中 G j G_j Gj 为真实边界框,指示函数 I ∈ { 0 , 1 } \mathbb{I} \in \{0,1\} I∈{0,1} 用于判断置信度 C j C_j Cj 是否超过默认阈值 τ = 0.5 \tau = 0.5 τ=0.5。
251113:这个指标会考虑3个纬度:1️⃣ 是否检测到异常帧(就是异常分数,他说的是置信度);2️⃣ 给出的框是否准确(就是算一下IoU);3️⃣ 时序维度这里就考虑所有的异常帧,就是取个平均,你这里还得把所有的异常帧都尽可能检测对,你的最终的结果才会高。 其实好像就两个纬度,1和3好像差不多一个意思。
4.2 VAD 结果
表 2 总结了三个基准上的结果。整体而言,我们的 零样本、无需训练(zero-shot, training-free) 框架在 UCF-Crime 和 XD-Violence 上超越此前最优零样本检测器 4--6%,在 UBnormal 上超越 3%,并且在 MSAD 上也具有良好的泛化能力。与那些需要额外监督、额外数据或 CoT 推理步骤的基线相比,我们的方法也展现了具有竞争力的性能,进一步证明了我们所提出的 IntraTR 组件的有效性。图 3 对我们的方法与基线 Zanella et al., 2024 做了定性对比,显示出显著减少的假阳性预测。更多示例见附录 D.1。
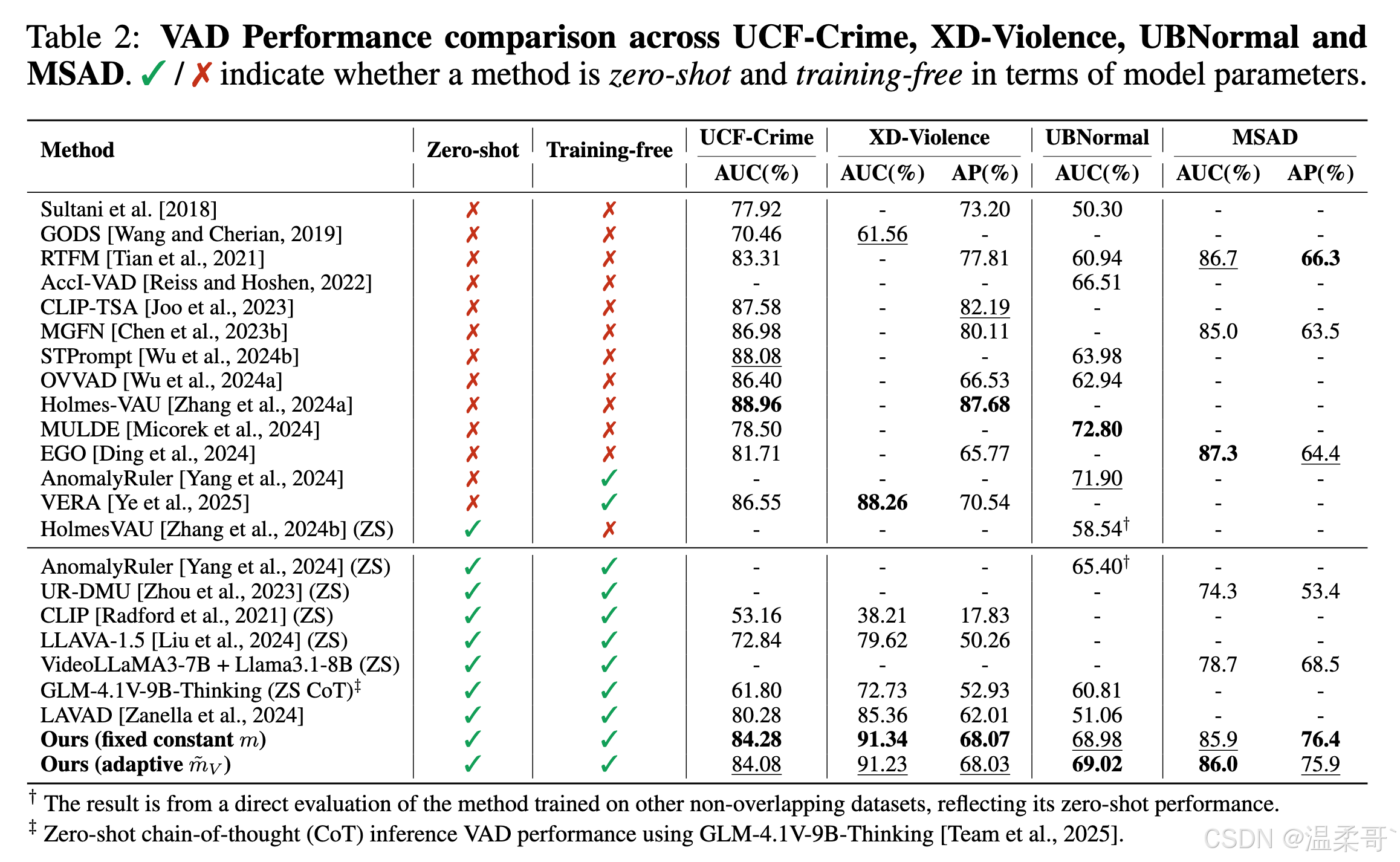
我们还发现,固定的 margin 值 m m m 表现已经很好,尽管它对测试域引入了一个不可避免的假设;而基于方差估计的自适应 m ~ V \tilde{m}_V m~V 也提供了类似的性能,并且不对测试域做任何假设。该样本特异性的"怀疑度"有助于解释其在 UBnormal(一个合成数据集,样本与自然视频存在差异)上的优势。我们在附录 B.1 中进一步讨论 m m m 的影响。
关于测试时推理步骤的消融实验。
表 3a 评估了推理循环中三个组件的独立贡献。最简单的基线是对冻结的 VLM 进行单轮直接查询,获得 77.67%(row 1)。引入 ① 基于 LLM 的 Scoring 组件和 ② Prior-Reasoning 组件,但不使用后续的 score-gated 推理时,结果仅达到 77.40%(row 2)。
相比之下,保留 LLM scorer 但去除 prior reasoning 模块,使性能提升到 80.38%(row 3),表明在所有样本上进行不受控制的"过度思考"可能引入噪声,引发幻觉并降低性能。而激活所有三个阶段(包括 ③ score-gated reasoning)将结果提升到 84.28%(row 4),较原始 VLM 基线提升 6.61%。这些结果验证了我们的假设:对异常存在性的置信度可以作为评估第一轮预测质量的度量,从而有效控制测试样本的推理深度。

关于 t V t_V tV 的消融实验。
表 3b 分离评估了在第二轮推理阶段引入视频级异常文本先验的效果。固定 m = 0.05 m = 0.05 m=0.05 时,仅使用空的 t V t_V tV 的 score-gated 推理模块性能为 81.86%。将 t V t_V tV 替换为来自标注的真实类名(如 "Arson, RoadAccident") ( t oracle ) (t_{\text{oracle}}) (toracle) 可提升至 83.91%,验证了准确的异常先验能够提升检测性能。
有趣的是,我们自动提取的先验 t V t_V tV 甚至超过了 oracle 类名,达到 84.28%,表明本地异常提取步骤能够有效将异常先验从粗粒度的类别(例如 "Arrest",其在真实标注中具有歧义)细化为更清晰的上下文(如 "physical altercation",更具信息性)。使用更清晰的上下文明显提升了逐帧异常检测性能。
4.3 VAL 结果
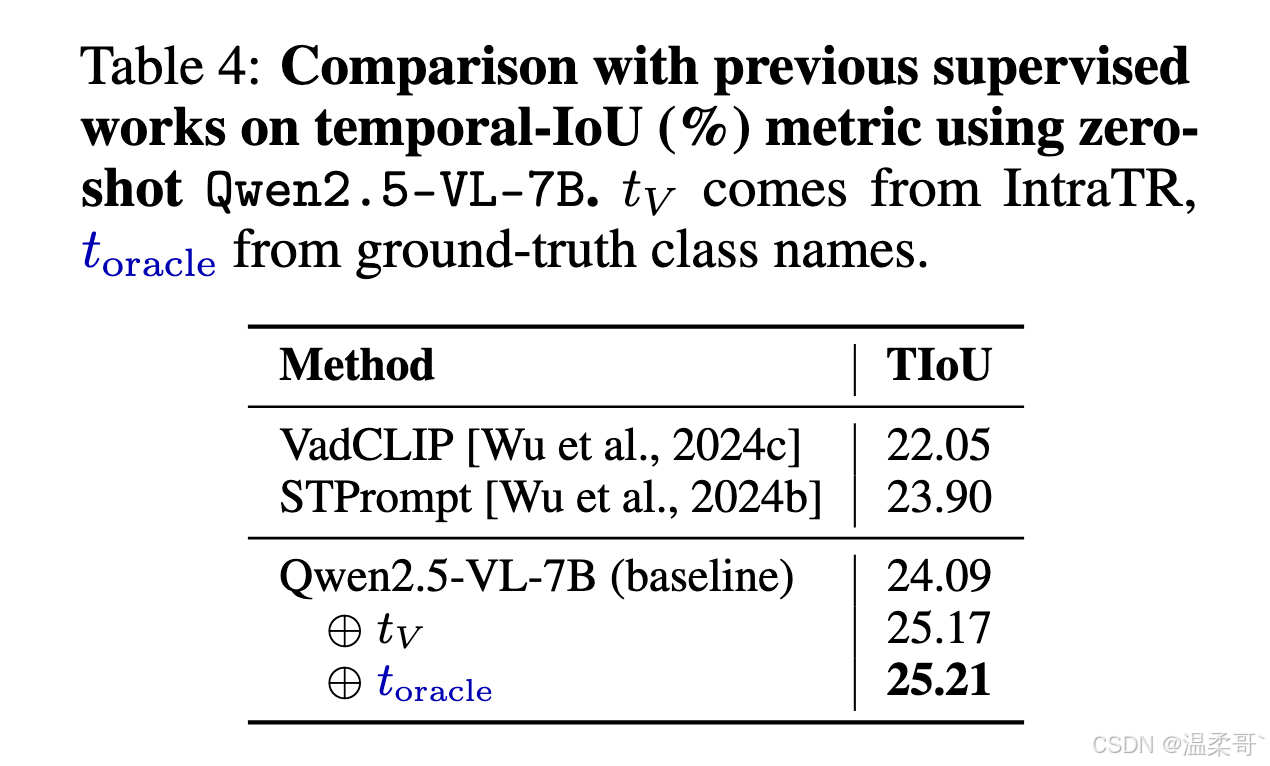
表 4 显示,零样本的 MLLM 基线已经超过了先前的监督式检测器;并且,无论是注入 IntraTR 自动生成的异常标签列表 t V t_V tV,还是注入真实类别名称,都能在定量的 TIoU 指标上带来约 1% 的绝对提升。此外,使用 t V t_V tV 与使用真实标签 t oracle t_{\text{oracle}} toracle 的结果之间仅存在极小差距,说明我们得到的 t V t_V tV 能够捕获几乎与 oracle 相当的语义线索,而无需任何人工标注。
这些观察结果表明,即使是轻量级的语义先验,也能够在无需重新训练的情况下有效提升空间定位性能。更多定位的定性示例见附录 D。
251113:人家VadCLIP没有定位功能,是怎么搞出来定位评估结果的???我感觉可能是这样,因为TIoU这个指标要考虑两个,一个是异常分数,一个是定位框,然后他就只用了VadCLIP的异常分数和细粒度类别,然后作为提示给一个QwenVL之类的定位模型去定位,应该就是这样。
4.4 VAU 结果
实验结果
表 5 将我们基于 InterTC 的提示词细化方法,与直接 VLM 推理基线及近期的指令微调 VAU MLLMs Tang et al., 2024; Zhang et al., 2024b 在两个不同测试域上进行了对比,使用 HIVAU-70k Zhang et al., 2024b 提供的真实描述作为参照。
在这两个测试域上,InterTC 细化后的查询提示词在传统 NLP 指标和所有 GPT 评分(可推理性、细节性、一致性)上均提升了基础 VLM 的表现,同时缩小了与指令微调方法之间的差距,甚至在部分指标上超越了这些方法。
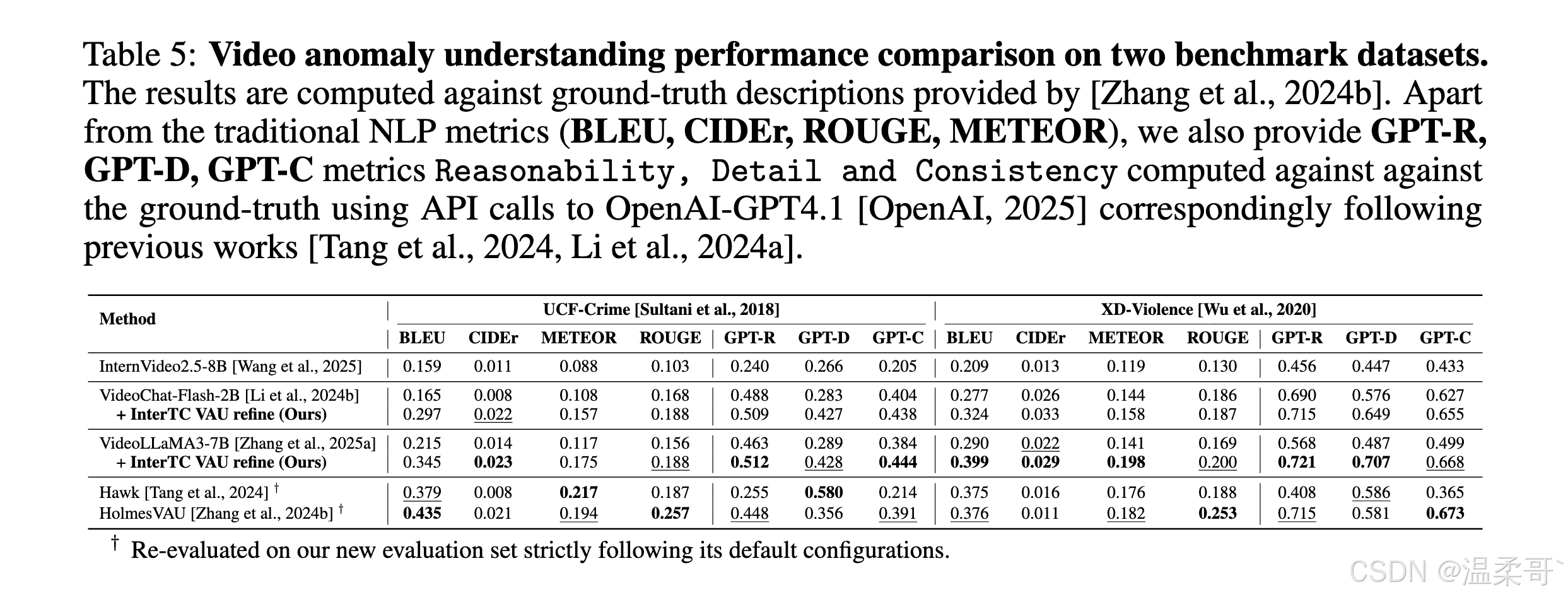
从定性角度,我们还在图 4 中展示了该框架的描述能力。例如在 shoplifting (商店行窃)片段上,基线 VLM Zhang et al., 2025a 与 HolmesVAU 均未能识别出异常行为,而我们的方法指出了关键动作("puts the phone in his pocket"),并将事件正确标注为 shoplifting 。更多示例见附录 D.3。
这些结果验证:
1)基于标签的提示词增强注入了关键上下文;
2)来自空间定位的线索进一步增强了叙述细节,而无需任何额外训练。

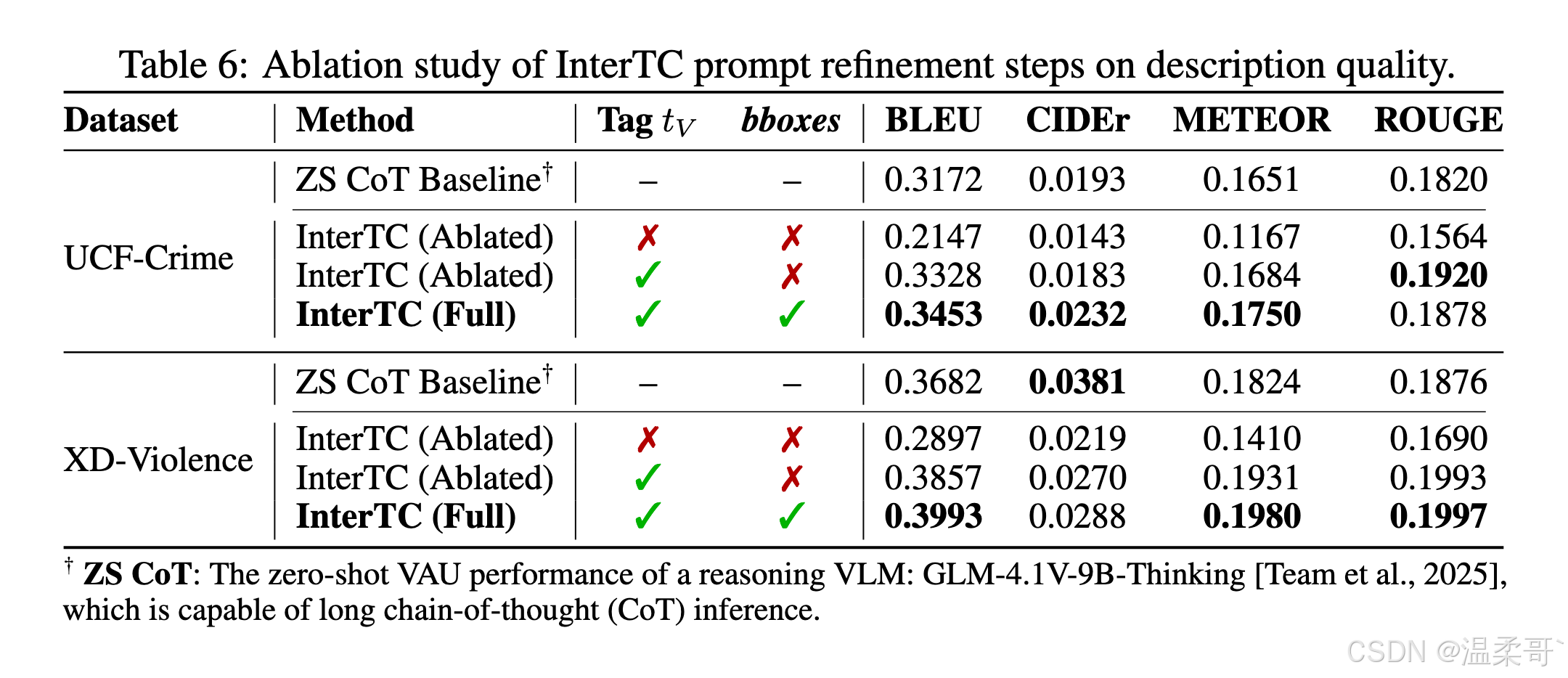
提示词细化步骤的消融实验
为了分析 InterTC 促进 VAU 性能的不同组件,我们进行了相应的消融实验。如表 6 所示,在 UCF-Crime 和 XD-Violence 上,仅将来自 VAD 的标签列表 t V t_V tV 注入提示词,即可解释观察到的大部分性能提升。相比之下,将空间定位阶段的 bounding box 叠加结果作为额外视觉提示传递给 VAU,只带来了较小的增益。
我们推测这是因为冻结的 VLM 并未针对带有叠加框的大规模视频进行训练,因此只能带来较为有限的改进。
相比之下,通用"思考型"VLM Team et al., 2025 虽然在更专门化的 VAD 任务上表现较弱(见表 2),但在 VAU 上优于零样本基线。这说明 Team et al. 2025 与我们提出的 InterTC 所采用的链式推理理念,都能够通过更细致的分步描述提升文本异常理解能力。然而,通用推理模型并不一定适用于更细粒度且复杂的异常视频理解 Shojaee\* et al., 2025,因为其可能引入与真实异常无关的内容。相反,我们的 InterTC 通过异常相关证据引导提示词,使其在所有视频异常分析任务的多数指标上取得更优表现。
总体而言,VAD 阶段的文本提示词细化在提示优化中起主要作用,而空间定位的视觉提示可在额外算力允许时作为可选增强项。
5. 结论
在本文中,我们提出了一个统一的、无需训练的整体视频异常分析框架,通过在单次推理中串联时间检测、空间定位和文本理解。我们的零样本系统在所有三个子任务上持续超越此前的无需训练基线,并接近监督式方法的表现。
通过将推理流程结构化为一系列 gated reasoning 步骤,每个子任务都能利用上一阶段的语义或视觉先验,实现自我修正与更深层次的可解释性,而无需额外训练。特别是在视频异常分析中,事件往往在时间和空间维度上展开,这种多阶段推理能够捕捉单阶段模型难以处理的结构,从而在获得准确检测的同时产生更具可读性的解释。
尽管该框架存在一些潜在的局限性及可能的社会影响(特别是在敏感视频分析中的 VLM 使用,详见附录 F 与附录 G),但我们相信,这种将推理视为主动的、上下文驱动过程的框架能够提高视频分析的稳健性,并有潜力推广至其他更复杂的视觉语言任务。