本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
本文全面解析微软开源的 GraphRAG 项目,从它是什么、怎么用、如何优化运行性能、生成哪些关键文件,到如何集成到你自己的业务中。内容深入但通俗,适合开发者、数据分析师、AI工程师学习参考。
一、什么是 GraphRAG?它解决了什么问题?
GraphRAG(Graph Retrieval-Augmented Generation)是微软研究团队发布的开源项目,它是一种"图增强的检索生成系统"。
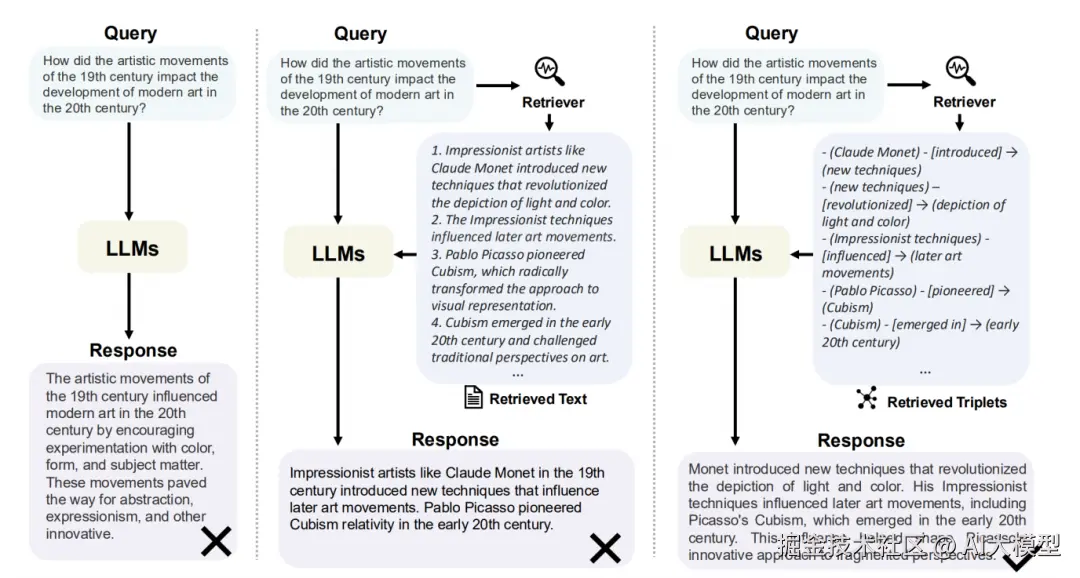
与传统的RAG不同,GraphRAG不仅仅是"检索+生成",它引入了图结构,使得RAG具备以下关键能力:
| 能力 | 描述 |
|---|---|
| 结构化理解 | 构建文档内的实体-关系图谱 |
| 全局洞察 | 对文档中的知识点进行社区聚类和语义总结 |
| 精确查询 | 提供局部语义搜索 与全局知识总结两种方式 |
| 可解释性强 | 每个结论都可以回溯原始实体、文本、社区 |
使用GraphRAG的典型场景:
- 长文档问答(文档QA) :如法律文书、政策文件、财报等
- 结构化摘要生成:需要从海量文本中提炼结构化知识
- 知识图谱构建:不手写规则、纯靠LLM自动提取关系
- 企业数据洞察:对公司资料、项目报告进行结构建模和分析
🆚 GraphRAG vs 传统 RAG vs Embedding Search
| 特性 | 传统Embedding Search | 普通RAG | GraphRAG |
|---|---|---|---|
| 基于向量检索 | ✅ | ✅ | ✅ |
| 上下文生成 | ❌ | ✅ | ✅ |
| 知识关系建模 | ❌ | ❌ | ✅ |
| 社区聚类分析 | ❌ | ❌ | ✅ |
| 全局结构回答 | ❌ | ❌ | ✅ |
| 可解释性 | 中 | 低 | 高 |
简言之,GraphRAG是对RAG的能力升级,不仅可问,还能解释"知识是如何构成的"。
二、如何跑通 GraphRAG?从0到1完整流程
1. 安装环境(推荐使用虚拟环境)
pip install graphrag
不再需要 Poetry、源码克隆等繁琐步骤。GraphRAG 已正式发布到 PyPI。
2. 初始化项目目录
使用官方命令快速初始化:
bash
graphrag init --root ./ragtest
这一步会生成标准的目录结构:
ragtest/
├── settings.yaml
# 主配置文件
├── prompts/
# 提示词模板
├── .
env
# 存放API密钥(需手动填入)
└── input/
# ❗需要手动创建,用来放你要分析的文档
3. 配置 API 密钥
编辑 .env 文件,填入你的 API Key。例如使用硅基流动 API:
ini
GRAPHRAG_API_KEY = sk-your-siliconflow-api-key
同时,在settings.yaml中设置 API 提供方:
makefile
models:
default_chat_model:
type: openai_chat
api_base: https://api.siliconflow.cn/v1
api_key: ${GRAPHRAG_API_KEY}
model: deepseek-ai/DeepSeek-V3
encoding_model: cl100k_base
concurrent_requests: 3
requests_per_minute: 30
default_embedding_model:
type: openai_embedding
api_base: https://api.siliconflow.cn/v1
api_key: ${GRAPHRAG_API_KEY}
model: BAAI/bge-large-zh-v1.5
encoding_model: cl100k_base
concurrent_requests: 3
requests_per_minute: 304. 添加文档到 input 目录
将你需要处理的文档放入 ragtest/input/ 目录中:
bash
ragtest/
├── settings.yaml # 配置文件
├── prompts/ # 提示词模板
├── input/ # 数据输入目录(需手动创建)
├── .env # 存储API密钥
└── output/ # 自动生成的索引结果
支持.txt,.pdf,.docx等多种格式。5. 运行索引构建命令
bash
cd ragtest
graphrag index --root .
该命令会自动完成以下过程:- 文本分块
- 实体识别与关系提取(调用大模型)
- 构建实体-关系图谱
- 社区检测(Leiden算法)
- 生成社区摘要(调用大模型)
- 嵌入计算 + 向量索引构建
这个过程会花费很长时间
6. 运行查询命令
bash
# 全局查询(问结构化主题)
graphrag query --root . --method global "公司的核心项目是什么?"
# 局部查询(问细节语义)
graphrag query --root . --method local "张三的职责是什么?"
需要在包含 settings.yaml 配置文件的目录中运行,也就是 ragtest 目录。
cd ragtest # 切换到包含settings.yaml的目录
示例:
graphrag query --root . --method global --query "张飞是谁的兄弟"
Missing reports for communities: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330, 331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 364, 365, 366, 367, 368, 369, 370, 371, 372, 373, 374, 375, 376, 377, 378, 379, 380, 381, 382, 383, 384, 385, 386, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 416, 417, 418, 419, 420, 421, 422, 423, 424, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446, 447, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467, 468, 469, 470, 471, 472, 473, 474, 475, 476, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 489, 490, 491, 492, 493, 494, 495, 496, 497, 498]
SUCCESS: Global Search Response:
张飞是刘备的兄弟。在三国时期,张飞与刘备、关羽并称为'桃园三结义',三人结为异姓兄弟,共同参与了三国的诸多历史事件。[Data: Reports (1, 3)] 三、ragtest目录结构详解
一旦运行完索引命令,目录结构如下:
csharp
ragtest/
├── input/ # 输入数据
│ └── three_kingdomspart.txt # 我们给定的文档,比如三国演义
├── output/ # 主要输出文件
│ ├── documents.parquet # 文档表
│ ├── text_units.parquet # 文本单元表
│ ├── entities.parquet # 实体表
│ ├── relationships.parquet # 关系表
│ ├── communities.parquet # 社区表
│ ├── community_reports.parquet # 社区报告表
│ ├── covariates.parquet # 协变量表(可选)
│ └── lancedb/ # 向量数据库
│ └── default/ # 存储文本嵌入向量
├── cache/ # 缓存文件
│ ├── base_text_units.parquet # 基础文本单元缓存
│ ├── extracted_entities.parquet # 提取的实体缓存
│ ├── extracted_relationships.parquet # 提取的关系缓存
│ └── ... (其他中间缓存文件)
└── logs/ # 运行日志
└── indexing-engine.log # 索引过程日志四、GraphRAG输出文件详解
1️⃣ documents.parquet(文档表)
- 存储原始文档的元信息与全文内容
- 每个文档一个条目,记录其
title、text、doc_id 就是原始文档的条目
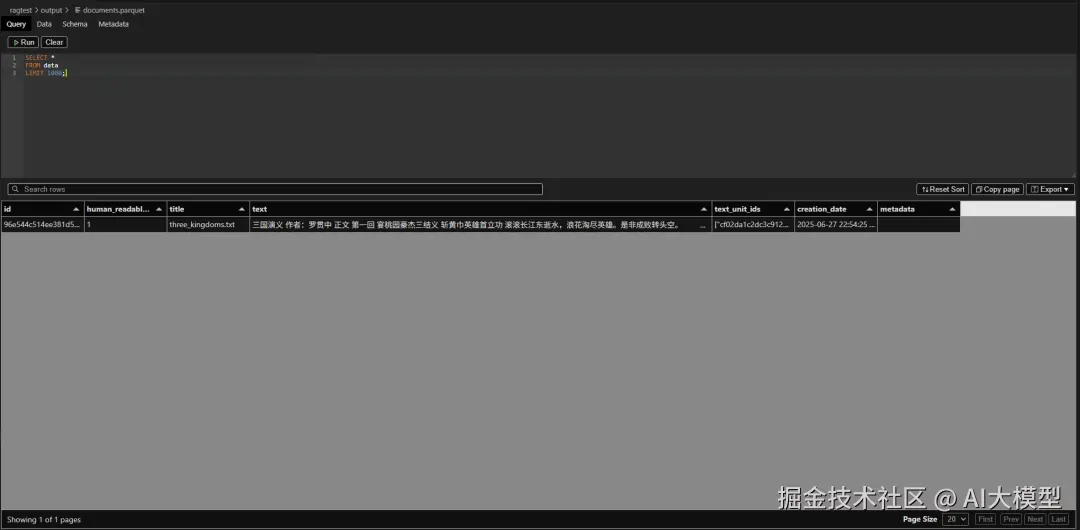
2️⃣ text_units.parquet(文本单元表)
- 将每个文档分块(chunk)后的切片内容
- 每一块对应一次LLM调用(如实体提取)
- 就是切分后的每一个chunk的内容
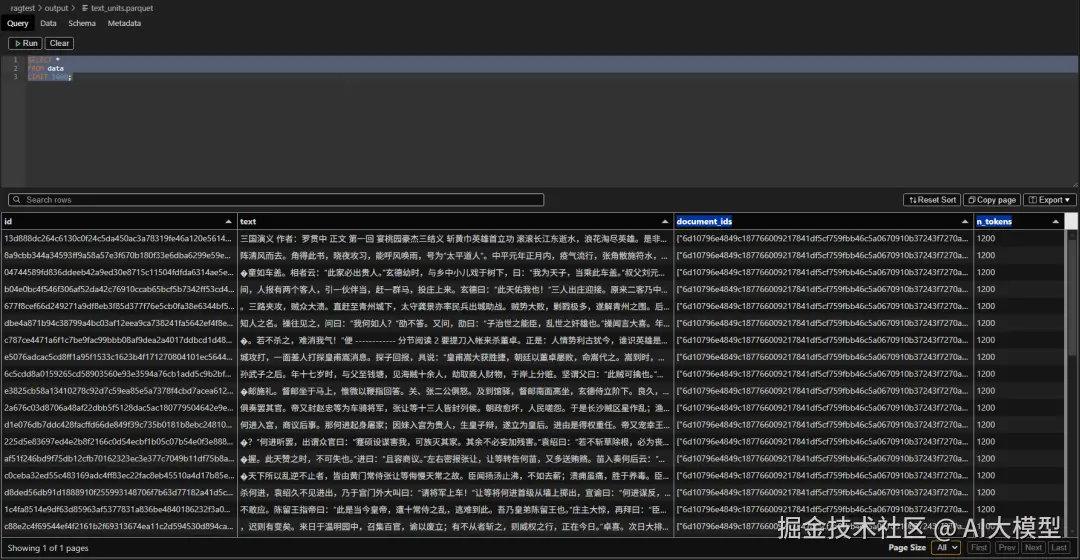
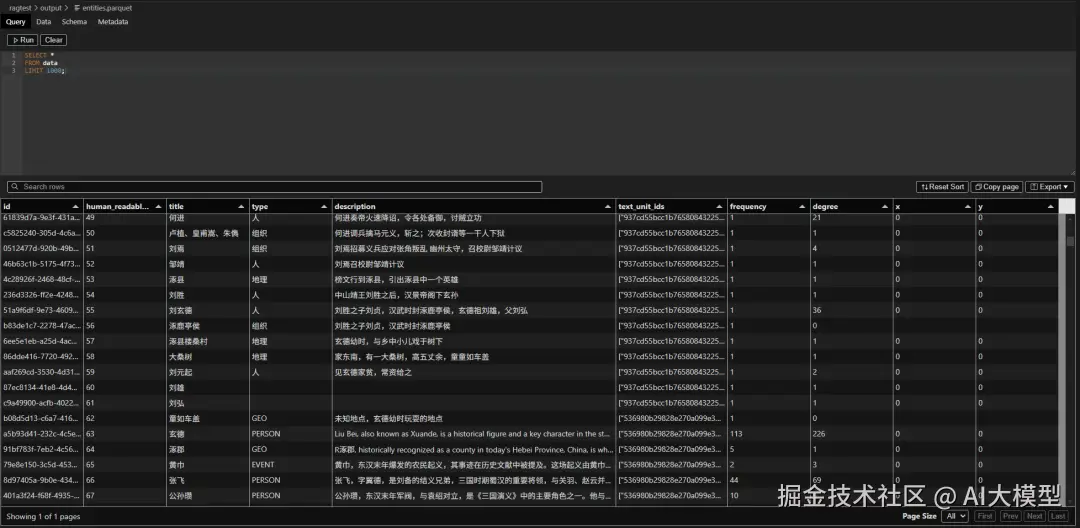
3️⃣ entities.parquet(实体表)
- 所有文档中提取出的人物、组织、地点、事件
- 包含:实体名称、类型、频率、描述、出现在哪些块中
- 是知识图谱的"节点"
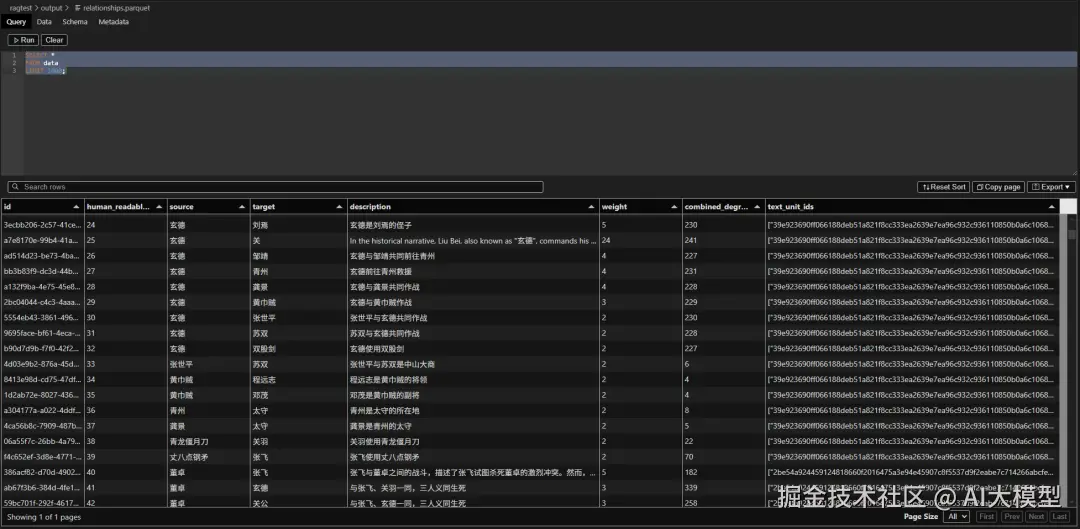
4️⃣ relationships.parquet(关系表)
- 每对实体之间的语义关系(如"张三-管理-产品部")
- 包含描述、关系类型、权重等
- 是知识图谱的"边"
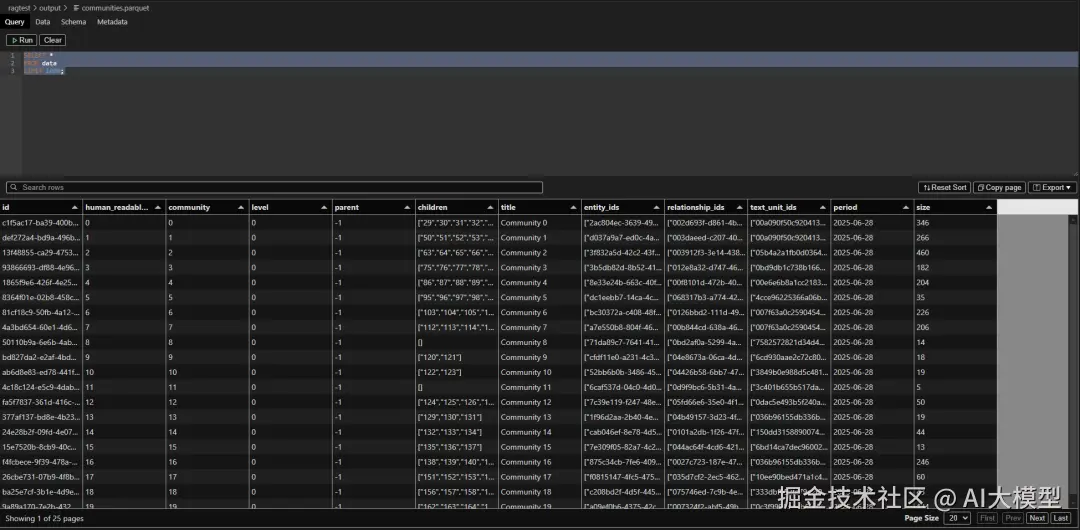
5️⃣ communities.parquet(社区表)
- 基于图谱运行社区检测算法,聚出"主题组"
- 每个社区包含一组相关的实体(如某产品线团队)
- 作用是发现"主题集群"
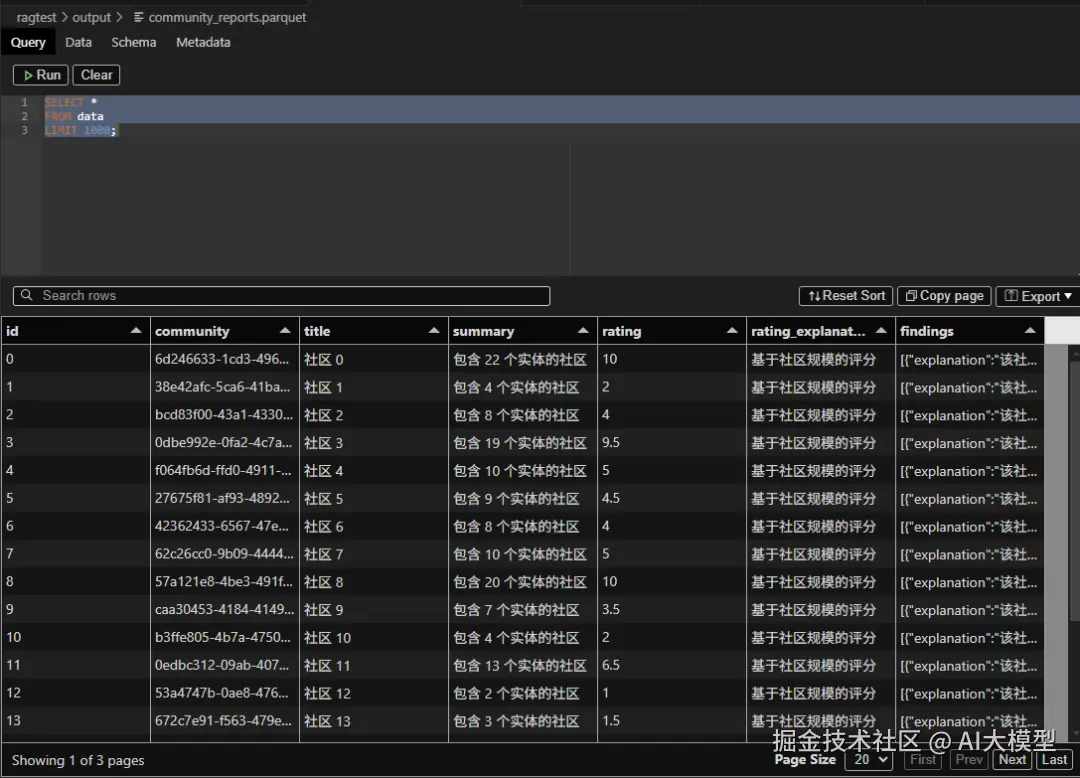
6️⃣ community_reports.parquet(社区报告表)
- 对每个社区,调用LLM生成的结构化摘要
- 包括报告标题、摘要、主要发现
- 面向的是用户,用的是自然语言
- Qwen模型容易失败,得换个合适的模型
7️⃣ lancedb/(向量数据库)
- 每个文本单元的向量表示,用于局部语义搜索
五、GraphRAG是否用到GPU?用的是API还是本地推理?
✅ GraphRAG 默认是 纯CPU + API架构
- 大模型(LLM)的生成任务 → 调用远程API(如OpenAI、DeepSeek、硅基流动)
- 向量嵌入 → 调用API返回向量
- 图谱构建与聚类 → 本地CPU完成
无需安装本地大模型,也不需要GPU。只需配置好API Key,即可全流程运行。
六、如何让GraphRAG跑得更快?性能优化建议
虽然GraphRAG不依赖GPU,但它对网络和API速率非常敏感。
常见导致运行慢的原因:
- 文本分块太多(默认1200字符一块)
- 并发请求太高,API服务限速
- 提取的实体种类太多(默认4类)
- 启用了多轮提取或大社区处理
✅ 优化建议清单:
1. 减小文本块大小,降低请求量
yaml
chunks:
size: 600 # 默认1200,减小可以减少每次Token量
overlap: 502. 限制实体类型
yaml
extract_graph:
entity_types: [person, organization]3. 降低并发并限速(尤其用硅基流动时)
yaml
models:
default_chat_model:
concurrent_requests: 3
requests_per_minute: 304. 启用缓存
yaml
cache:
type: file
base_dir: "cache"5. 先用小文档测试,逐步扩大规模
进一步的性能优化清单
| 优化点 | 说明 | 适用场景 |
|---|---|---|
| Chunk Size & Overlap 调参 | • 若供应商按 token/min 计费/限速,减小 chunk 可让单次 token-load↓,降低被限速概率;但请求数会增多。• 若按 req/min 限速,增大 chunk (1500-2000 tokens)+ overlap 50→20 可以显著减少调用次数。 | 大文件 / 限速严格 |
| 停用 Claim 与 Gleanings | 在 settings.yaml:claim_extraction.enabled: false``extract_graph.max_gleanings: 0 |
只想要实体-关系-社区时 |
| 分阶段执行 | 先跑 graphrag index --root . --method embeddings 只计算嵌入,确认速度 OK 后再跑完整流水线。 |
超长语料试跑 |
| 本地嵌入模型 | 用 api_base: http://localhost:11434 + Ollama embedding(nomic-embed)可把 60-70 %的 API 调用转本地,速度和成本双降。 |
有 GPU / CPU 充裕 |
| 递增批处理 | 利用 parallelization.stagger(0.3-0.5)让请求批次交错,更平滑地利用限额。 |
供应商支持并发高但限速 |
| 文本预清洗 | 去除页眉页脚、模板重复段,可减少 10-30 % 无效 token。 | PDF 批量导入 |
| 重用 Prompt 模板 | 把长系统 prompt 写进 prompt_template: 文件并引用,可显著减小每次 token。 |
自定义 prompt 很长时 |
七、我想接入自己项目,应该怎么做?
GraphRAG是标准输出结构+自定义配置驱动的系统,你只需要:
✅ 调整配置文件 settings.yaml
- 实体类型适配你业务领域
- 分块策略按文档特点调整
yaml
extract_graph:
entity_types: [person, department, project]
prompt: prompts/extract_business.txt
chunks:
size: 1000
overlap: 100✅ 修改提示词模板
在 prompts/ 中编写自定义模板,如:
diff
请从以下文本中提取:
- PERSON: 员工、客户、合作伙伴
- DEPARTMENT: 公司内部部门
- PROJECT: 项目/产品✅ 使用GraphRAG生成结构化结果并接入你系统
你可以将生成的 entities.parquet,``relationships.parquet,``community_reports.parquet作为你系统的知识结构、标签源、甚至问答基础。
✅ 总结
| 功能 | GraphRAG |
|---|---|
| 文档结构建模 | ✅ |
| 实体/关系抽取 | ✅ |
| 社区聚类分析 | ✅ |
| 多层次问答支持 | ✅ |
| 无需本地部署大模型 | ✅ |
| 支持企业定制 | ✅ |
GraphRAG 就像是一个自动化知识工厂,帮你从无结构文本中提炼出有结构的图谱和洞察。只要你配置得当,它可以无缝集成到你任何AI相关的业务系统中。
📎 项目地址:github.com/microsoft/g...
📖 官方文档:github.com/microsoft/g...
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。