Aryan Vichare
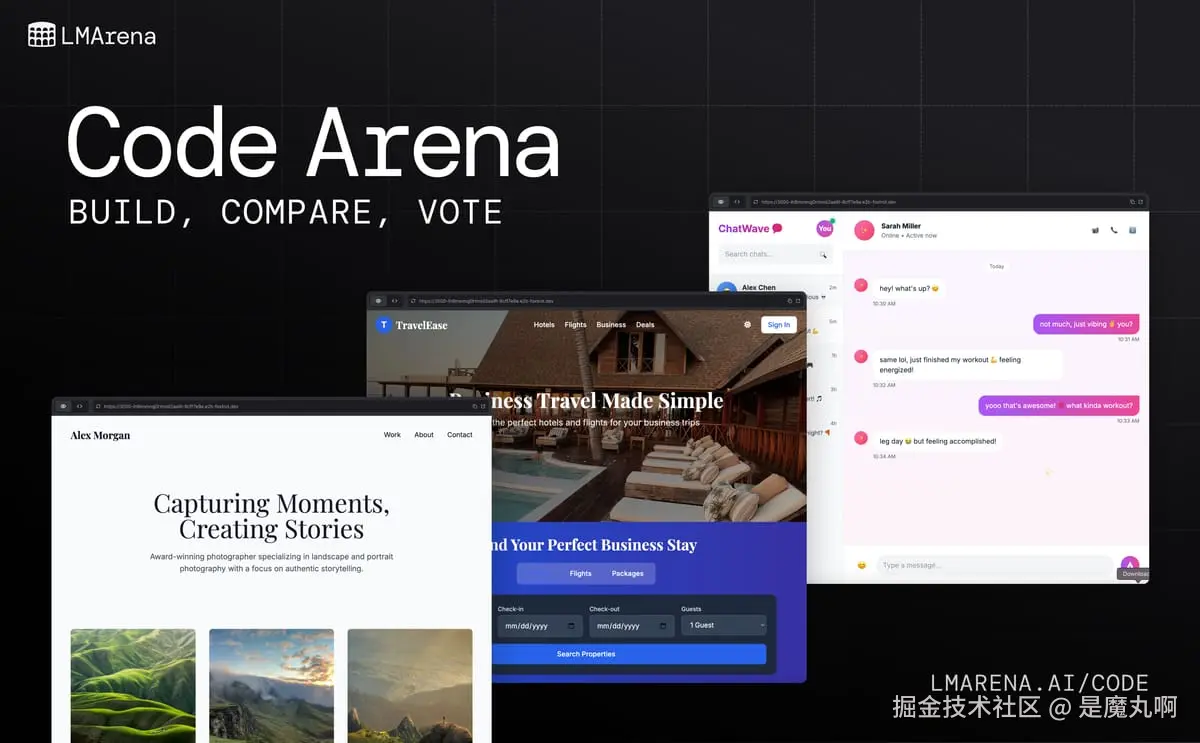
介绍 Code Arena:现实世界中 agentic coding 的实时评估
AI 代码模型发展迅速。如今的系统不再只是一次性输出静态代码。它们构建 。它们搭建完整的 Web 应用和站点,重构复杂系统,并实时自我调试。许多现在扮演着coding agents的角色,规划和执行结构化操作来设计和部署完整的应用程序。
但问题不再是"模型能写代码吗?"而是"它在多大程度上能端到端地构建真实的应用程序?"
传统基准测试衡量正确性:代码是否能编译并通过一组静态测试用例。正确性很重要,但这只是定义真实开发的部分。构建软件是迭代性和创造性的:你规划、测试、完善和重复。一个可信的评估必须反映这个过程。
Code Arena 正好做到了这一点。这是我们下一代评估系统,从零开始重建,专为透明度、精确性和现实世界性能而设计。模型在受控的隔离环境中作为交互式 agents 运行,每个提示、渲染和操作都被记录。会话在访问之间可恢复且持久,生成内容可以稍后共享或重新访问。
其结果是一个实时的、可检查的系统,不仅评估代码是否有效,还评估它运行得如何良好 、它交互得如何自然 ,以及它如何忠实地满足预期设计 。Code Arena 衡量动态编码,捕捉模型在模拟真实开发的条件下如何思考、规划和构建。
为开发者带来什么新内容
Code Arena 引入了面向开发者的体验,旨在营造实时编码环境的感觉:交互式、透明,并且从头到尾都是持久的。
- Agentic behaviors(代理行为): 模型使用结构化工具调用(create_file、edit_file、read_file)自主规划和执行,逐步展示推理过程。
- Multi-turn, multi-step execution(多轮、多步执行): 模型在多次交互中迭代、编辑和完善,在单次评估中完成复杂构建。
- Real-time generation(实时生成): 输出在模型构建时实时渲染,因此开发者可以在代码演进过程中探索运行中的应用。
- Persistent sessions(持久会话): 代码会话在访问之间可恢复且持久,保留状态并支持协作审查。
- Recursive edits and HTML file trees(递归编辑和HTML文件树): 每次生成包含完整的项目结构(HTML、CSS、JS),让评估者检查模型如何管理相互依赖的文件和递归编辑。
- Shareable generations(可共享生成): 每个构建都可通过唯一链接共享,用于同行测试或模型比较。
- Unified workflow(统一工作流): 提示、生成和评估现在完全在 Arena 的基础设施内完成,确保受控环境、一致参数和可重现结果。
总之,这些更新将基准测试变成一个你可以看到、运行和共享的实验。Code Arena 现在是一个面向开发者、模型构建者、原型制作者、知识工作者、创意专业人士等的透明编码环境。
Code Arena 如何工作
每次 Code Arena 评估都是一个可重现的实验,捕捉 AI 辅助开发的完整轨迹,从想法到生成到人类判断。
- Prompt(提示): 评估者或开发者提交一个任务,例如"构建一个带有暗色模式的 markdown 编辑器。"
- Plan(规划): 模型解释请求并使用结构化工具调用决定采取哪些操作。这种 agentic 规划反映了真实的开发者工作流程。
- Generate(生成): 模型生成实时的、可部署的 Web 应用和站点。
- Record(记录): 每个模型操作(文件创建、编辑或执行)都被记录和版本控制。快照存储在 Cloudflare R2 中并链接到 Arena 的数据库以实现透明可追溯性。
- Render(渲染): 生成的应用通过安全前端流式传输,使用 CodeMirror 6 进行源代码查看,使用实时预览进行交互和测试。
- Vote(投票): 评估者成对比较输出,评估功能、可用性和保真度以及设计、品味和美学。每个投票都存储有完整的上下文:模型版本、延迟和环境。
- Aggregate(聚合): 结构化的人类判断实时反馈到排行榜,显示置信区间和性能方差,而不是静态平均值。
这个从提示到实时应用再到可验证投票的闭环管道,确保了 Code Arena 中的每个结果都是透明的、可重现的和科学基础的。Code Arena 不仅仅是完善我们评估 AI 代码模型的方式,它重新定义了基础本身。
从 WebDev Arena 到 Code Arena
当我们启动 WebDev Arena 时,它引入了第一个大规模的人工参与式 AI 编码基准测试。开发者可以观看模型构建真实应用、与输出交互并对性能投票,使评估具有参与性和透明度。
随着使用规模的扩大,对精确性和可重现性的需求也日益增长。最初为实验设计的系统,无法满足现实世界使用和评估所需的严格性要求。
Code Arena 从零开始重建了这个基础。每个组件都为透明度、可追溯性和方法控制而重新设计。其结果是一个更强大、更具科学基础的系统,不仅衡量代码是否有效 ,还衡量它在实践中运行得如何良好。
重建内部
Code Arena 不仅仅是基础设施升级。它是一个新的评估框架,为可重现性、透明度和科学严谨性而构建。每次评估都在为精确性和规模而设计的严格控制环境中运行,其中每个操作、渲染和结果都被记录并可重现。
- Agentic tool use(代理工具使用): 模型通过结构化工具调用自主创建、修改和执行代码,实现递归编辑和依赖管理等现实世界行为。
- Persistent and shareable sessions(持久和可共享会话): 代码会话在访问之间是可恢复和持久的,允许用户重新访问、检查和分发实时生成内容。
- Reproducibility(可重现性): 每个提示、模型版本和人类投票都链接到可追踪的 ID。
- Scoring framework(评分框架): 结果结合结构化的人类评估与透明统计聚合,包括评估者间可靠性和置信区间。
这种组合将 Code Arena 从排行榜转变为科学测量系统,其中每个数字都是可重现的,每个输出都是可验证的,每个模型都可以在现实世界条件下测试。
统一评估系统和方法论
提示、生成、比较和投票现在在 Arena 平台内以一个无缝工作流程中进行。这种集成减少了延迟,提高了可靠性,并允许对数千个同时任务进行精确跟踪。
有了 Code Arena,我们不仅仅是更新了界面。我们重建了编码评估的基础。每个模型都在三个轴上评分,这反映了真实的开发者判断:
- Functionality(功能性): 应用程序是否做到了它应该做的?
- Usability(可用性): 它是否清晰、响应迅速和直观?
- Fidelity(保真度): 它是否匹配请求的设计或行为?
新系统引入了agentic、多轮执行,模型自主规划和执行操作。每个模型可以调用像 create_file、edit_file 和 run_command 这样的工具,在结构化步骤中递归完善自己的工作。这实现了反映真实工程行为的复杂、迭代开发周期。
模型生成和部署完全交互的 Web 应用和站点,每次评估在一致条件下记录从提示到最终渲染的完整链,确保结果是可追溯的、可审计的和可重复的。
评估仍然是人工驱动的,但现在应用结构化评分和透明聚合,产生统计验证和可重现的结果。这次重建为 Code Arena 的演进评估框架奠定了基础,基于三个原则:
- Humans at the core(人类为核心): 每个分数都代表人类判断。投票随上下文记录并透明聚合。
- Show our work(展示工作): 每个指标都链接到其数据:成本、延迟和方法论。透明度内置于基础设施中。
- Embrace uncertainty(拥抱不确定性): Arena 发布置信区间和方差,而不仅仅是平均值。评估应该反映细微差别,而不是掩盖它。
干净数据基础和新排行榜
因为 Code Arena 的架构和方法论已经完全重建,它在为从头开始反映这个新系统而设计的新排行榜上启动。没有数据从 WebDev Arena 合并或改造,确保方法论一致性并保护未来比较的完整性。
将 WebDev Arena 的结果合并会损害数据完整性,因为它结合了在不同评分系统、环境和假设下产生的评估。从头开始允许 Code Arena 在清晰、可重现的评估规则下成熟,免受遗留偏见影响,并符合我们对透明度和可审计性的严格标准。
原始的 WebDev Arena 排行榜(WebDev Legacy )将在不久的将来退休,但目前,它仍然保持在线状态,作为 AI 编码评估第一个时代的历史记录。支撑 Code Arena 的新 WebDev V2 排行榜定义了现实世界性能的前瞻标准。
偏见跟踪和数据完整性
每次 UI 或工作流更改都可以改变人类投票模式。Arena 将其视为评估科学的一部分。在任何更改集成之前,团队运行偏见审计,测量对投票行为的影响并在排行榜更新前进行补偿。这确保人工参与式评估在平台演进时保持一致、公平和统计合理。
社区为核心
Arena 的优势一直是其社区:相信进步应该是开放、可测量和可共享的开发者、研究者和构建者。Code Arena 将这种信念付诸实践。
在平台内部,真实参与者推动每次评估。开发者探索实时应用、比较输出,并决定哪些模型在真实场景中表现最佳。他们的集体反馈构成了推动排行榜的数据。人类判断转化为结构化洞察。
Arena Discord 社区保持这个循环活跃。开发者在这里提出新挑战、参加实时测试,并发现帮助完善框架本身的异常情况。这种协作确保 Code Arena 与它所衡量的生态系统共同演进。
Arena Creator Community 延续了这种精神,展示人们如何使用、测试和构建 Arena。他们的项目使评估不仅是开放和透明的,而且是有吸引力和创造力的。
当人们参与 Code Arena 时,他们不仅仅是生成数据。他们在定义什么是好的 AI 编码。
下一步
Code Arena 的启动标志着一个新阶段的开始,专注于深度、可靠性和覆盖范围。在未来几个月,团队将继续完善数据质量、延迟和评估速度,同时扩展模型可以构建的内容以及开发者与它们的交互方式。
下一波更新将引入多文件 React 应用程序,允许模型生成结构化仓库而不是单文件原型,使 Code Arena 更接近现实世界软件开发:迭代、分层和可视化。
在未来几个月内,Arena 将开始推出 agent 支持和多模态输入,以及多文件项目的隔离沙盒。这些扩展将 Code Arena 推向连接的、协作的环境,反映现代 coding agents 实际如何跨系统、界面和媒体工作。
Code Arena 不是静态基准测试。它是一个活系统,随着每个新模型、实验和人类投票而演进。每次更新都加强其基础:为规模而构建的透明、可重现评估。
Arena 的使命一直是衡量重要的东西:AI 在现实世界中的表现。有了 Code Arena,这个使命现在触及软件创造的核心。这是开发者、研究者和模型构建者汇聚一堂、共同测试性能的地方。
AI 代码评估的下一阶段已经到来。