Linux slab分配器深度剖析:从原理到实践
1 Linux slab分配器概述
1.1 什么是slab分配器
Slab分配器是Linux操作系统内核中一种高效的小内存分配机制 , 专门用于管理内核对象的分配和释放. 该机制最早由Sun Microsystems的Jeff Bonwick为Solaris操作系统开发, 后来被移植到Linux内核中, 成为Linux内核内存管理的核心组件之一 . slab分配器的设计基于对象管理思想, 通过为频繁分配和释放的内核对象(如进程描述符、文件对象、信号量等)建立对象缓存, 显著提高了内存分配性能和利用率
在实际操作中, slab分配器相当于一个对象仓库, 它预先分配并初始化一批常用内核对象, 当内核需要这些对象时, 可以直接从仓库中快速获取, 而不需要每次都经过复杂的内存分配流程. 就像一家大型餐厅会提前准备一些常用食材和半成品菜, 当顾客点餐时, 厨师可以直接使用这些预制材料, 而不必每次都从最原始的食材开始处理, 大大提高了出餐效率
1.2 设计目标与解决的问题
在slab分配器出现之前, Linux内核主要使用伙伴系统 进行内存分配. 伙伴系统虽然能有效地管理物理页框的分配和释放, 但它主要面向大块内存的管理(以页为单位), 对于内核中大量存在的小对象分配来说, 直接使用伙伴系统会带来显著的问题:
- 内存碎片化:频繁分配和释放小内存块会导致大量不连续的小空闲内存块, 无法满足较大的内存分配请求
- 性能开销:每次分配都需要调用复杂的伙伴系统算法, 对小对象来说开销过大
- 初始化开销:内核对象在分配后往往需要初始化, 重复的初始化操作浪费CPU时间
slab分配器通过以下方式解决上述问题:
- 对象缓存:为常用内核对象建立缓存, 避免频繁向伙伴系统申请内存
- 对象复用:释放的对象不立即返回给伙伴系统, 而是保留在缓存中, 供后续分配使用
- 预初始化:在创建对象时就进行初始化, 后续分配无需重复初始化
slab分配器特别适合频繁分配释放相同大小对象 的场景, 比如进程创建和销毁时对进程描述符task_struct的操作为例. 在没有slab分配器的情况下, 每次创建进程都需要向伙伴系统申请内存并对task_struct进行初始化;而使用slab分配器后, 只需要从task_struct缓存中直接获取一个已经初始化好的对象即可, 极大地提高了效率
2 slab分配器的架构设计
2.1 三级层次结构:cache、slab、object
slab分配器采用了一种清晰的三级层次结构来组织内存, 从顶到下分别是cache 、slab 和object. 这种设计类似于一个大型图书馆的管理体系, 让我们通过这个比喻来理解三者之间的关系
cache(缓存) 就像图书馆中的图书分类区 (如科技区、文学区、历史区), 每个cache专门用于存储一种特定类型的内核对象. 在内核中, 每个cache负责管理一种特定大小的对象, 例如task_struct cache专门管理进程描述符, inode_cache专门管理inode对象等. 每个cache维护着三个slab链表:满、部分满和空, 这与图书馆分类区中完全借出的书架、部分借出的书架和全部在架的书架类似
slab 是cache的基本管理单元 , 相当于分类区中的一个书架. 每个slab由一个或多个连续的物理页框组成(通常为一页), 这些页框被划分为多个大小相等的对象存储槽. 就像一个书架上可以放置多本同类型书籍一样, 一个slab包含多个同类型对象. slab有三种状态:满(所有对象都已分配)、空(所有对象都空闲)和部分(部分对象分配, 部分空闲), 这与书架的满载、空载和部分满载状态相似
object(对象) 是slab分配器的最小分配单位 , 相当于书架上的单个书籍. 每个object就是实际可分配给内核使用的内存块, 大小由所属的cache决定. 当内核需要分配对象时, 相当于读者借阅书籍;释放对象时, 相当于归还书籍到原书架
下面的Mermaid图清晰地展示了cache、slab和object之间的层次关系:
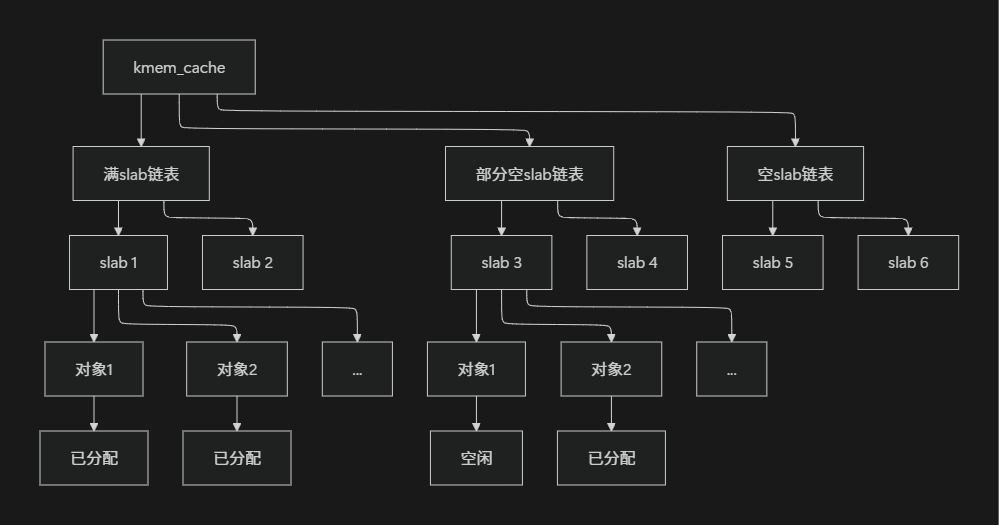
图:slab分配器三级结构示意图
2.2 核心数据结构kmem_cache
slab分配器的核心是kmem_cache数据结构, 它相当于整个分配器的"大脑", 负责管理一个特定类型的对象缓存. 该结构定义在Linux内核的include/linux/slub_def.h中, 以下是其关键字段及其含义:
c
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; /* 每CPU slab信息 */
slab_flags_t flags; /* 缓存标志位 */
unsigned long min_partial; /* 最小保留空slab数量 */
unsigned int size; /* 对象总大小(包括元数据) */
unsigned int object_size; /* 对象原始大小 */
unsigned int offset; /* 空闲指针偏移量 */
unsigned int cpu_partial; /* 每CPU部分空slab最大数量 */
struct kmem_cache_order_objects oo; /* 包含order和objects数量 */
/* 更多字段:slab大小设置、分配标志、构造函数等 */
const char *name; /* 缓存名称 */
struct list_head list; /* 缓存链表 */
int refcount; /* 引用计数 */
void (*ctor)(void *); /* 对象构造函数 */
unsigned int inuse; /* 对象实际使用大小 */
unsigned int align; /* 对齐大小 */
// ...
};kmem_cache结构中的几个关键字段说明:
-
cpu_slab:这是一个每CPU变量, 每个CPU都有自己独立的slab, 这样可以避免多处理器环境下的锁竞争, 提高性能. 这相当于银行为每个柜台设置一个独立的钱箱, 柜员可以直接从自己的钱箱取钱, 而不需要与其他柜员竞争同一个钱箱 -
size和object_size:object_size是对象的原始大小 , 而size是对齐后的大小 , 包括为了对齐而添加的填充字节和元数据空间. 比如一个实际大小为30字节的对象, 经过8字节对齐后,size可能是32字节 -
oo:这个字段编码了每个slab的页数 和每个slab包含的对象数量. 高16位存储页数(order), 低16位存储对象数量, 这种编码方式便于一次性原子操作 -
flags:控制slab行为的标志位, 例如是否开启调试、是否对齐硬件缓存等
2.3 SLAB、SLUB与SLOB分配器的对比
随着Linux内核的发展, slab分配器演化出了三种不同的实现:SLAB 、SLUB 和SLOB. 这三种分配器都提供了相同的接口, 但内部实现和性能特征有所不同
下表对比了三种slab分配器的特点:
| 特性 | SLAB(传统) | SLUB(默认) | SLOB(简易) |
|---|---|---|---|
| 设计目标 | 稳定可靠 | 高性能、可调试性 | 极简、低内存占用 |
| 数据结构复杂度 | 高(多队列、多链表) | 低(简化链表结构) | 极低(简单链表) |
| 内存开销 | 较高 | 较低 | 极低 |
| 调试支持 | 基础 | 丰富 | 有限 |
| 适用场景 | 需要稳定性的企业级系统 | 大多数通用系统 | 嵌入式、内存紧张系统 |
| 内核默认 | 旧版本内核 | 新版本内核默认 | 嵌入式内核配置 |
SLAB 是最初的实现, 设计相对复杂, 使用多个链表管理slab状态. 它的优点是经过长期测试, 稳定可靠, 但缺点是内存开销较大和性能相对较低
SLUB (Unqueued Slab Allocator)是当前Linux内核的默认分配器 , 它简化了SLAB的设计, 减少了管理开销, 提高了性能. SLUB的核心思想是减少链表使用, 优先从每CPU的本地slab分配, 只有当每CPUslab耗尽时才从节点部分空链表中获取. 这与现代多核处理器架构更加匹配
SLOB (Simple List Of Blocks)是一种极简分配器 , 主要用于内存极度受限的嵌入式系统. 它使用简单的首次适应算法, 管理开销最小, 但容易产生碎片. 除非系统内存非常紧张, 一般不建议使用SLOB
三种分配器可以通过内核配置选项选择, 开发者可以根据实际需求权衡功能性和资源消耗
3 slab分配器核心算法与工作原理
3.1 初始化过程
slab分配器的初始化是一个渐进的过程, 发生在内核启动阶段. 这个过程通过kmem_cache_init()函数完成, 标志着内核内存管理系统的正式启用. 初始化过程面临一个"鸡生蛋蛋生鸡"的挑战:slab分配器本身需要内存来存储其管理数据结构, 但这些数据结构又需要通过slab分配器来分配
为了解决这个问题, 内核采用了一种自举的策略:
-
静态初始化 :首先使用静态分配的
kmem_cache和kmem_cache_node结构, 这些结构在内核编译时就已经预留了空间 -
简单分配阶段:在系统启动初期, 使用临时的基于位图的分配器为最初的几个slab缓存分配内存
-
完整功能启用:当基本的slab缓存就绪后, 切换到完整的slab分配器, 此时可以正常分配所有类型的内核对象
这个过程好比在建造一个工厂:首先手工制造几台简单的机器, 然后用这些机器制造更复杂的机器, 最后用复杂的机器大规模生产各种产品
初始化过程中, 内核会创建一系列通用缓存 , 这些缓存中的对象大小通常是2的幂次方或者几何分布的, 范围从几十字节到几MB不等. 当内核使用kmalloc()函数申请内存时, 会根据申请的大小选择最合适的通用缓存. 这就像有一套标准尺寸的集装箱, 无论货物是什么形状, 都选择最合适尺寸的集装箱来装载
3.2 对象分配算法
当内核请求分配一个对象时, slab分配器按照以下顺序寻找可用的对象, 这种分配策略类似于超市结账时顾客选择排队队伍的逻辑:
-
快速路径 :首先尝试从当前CPU的slab(
kmem_cache_cpu)中分配. 这就像顾客优先选择人最少且开放的结账通道. 由于这是无锁操作(只涉及当前CPU), 速度最快 -
慢速路径一:如果当前CPU的slab没有空闲对象, 则从CPU的部分空slab链表(如果存在)中获取一个slab作为新的CPUslab. 这类似于当当前结账通道临时关闭时, 顾客选择另一个有空闲容量的通道
-
慢速路径二:如果CPU部分空链表也为空, 则从节点的部分空slab链表中获取slab. 这相当于从其他结账区域调配收银员到当前区域
-
慢速路径三:如果节点的部分空链表也没有可用slab, 则向伙伴系统申请新的内存页, 创建全新的slab. 这就像超市发现所有结账通道都满负荷, 决定开设新的结账通道
下面的Mermaid流程图展示了对象分配的完整过程:
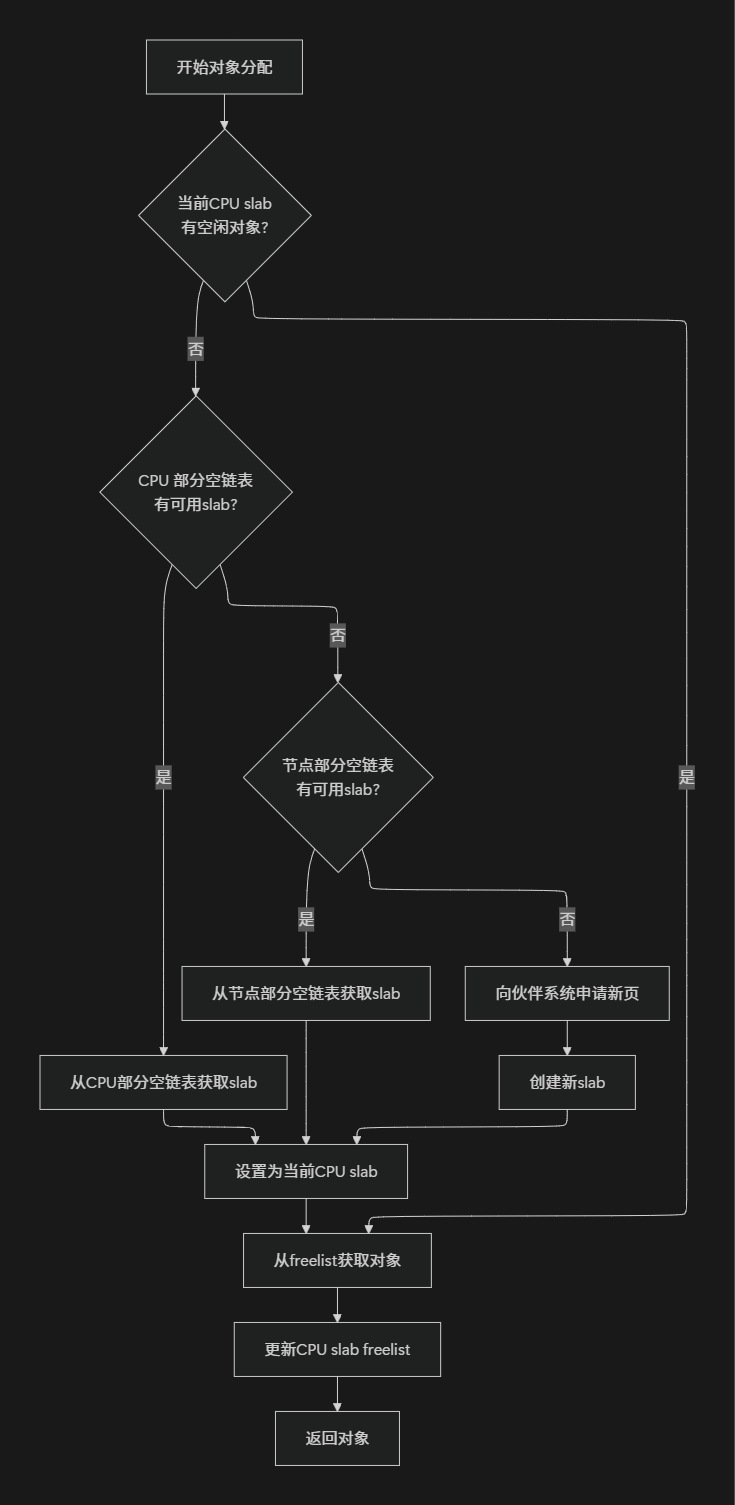
图:对象分配算法流程图
分配过程中, SLUB分配器使用freelist指针来跟踪空闲对象. 每个空闲对象内部存储着下一个空闲对象的地址, 形成一个隐式链表. 这种设计避免了额外的内存开销来存储空闲链表, 提高了内存利用率
3.3 对象释放与缓存管理
对象的释放过程与分配过程相对应, 但也有其特殊的优化策略:
-
快速释放:如果释放的对象属于当前CPU的slab, 并且该slab还不是满的, 则直接将对象放回CPU的freelist. 这就像收银员把零钱放回自己熟悉的钱盒位置
-
部分满处理:如果释放的对象使一个slab从满状态变为部分满状态, 需要将该slab加入到相应链表中
-
完全释放 :如果释放对象后, 整个slab变为空, 则考虑是否将空slab释放回伙伴系统. 但为了提升性能, slab分配器会保留一定数量的空slab (由
min_partial参数控制), 避免频繁向伙伴系统申请和释放内存
slab分配器通过延迟释放策略来优化性能:释放的对象不会立即返回给伙伴系统, 而是保留在缓存中, 供后续分配使用. 这类似于快递公司的包装箱回收策略, 使用过的纸箱不会立即丢弃, 而是整理保存供下次发货使用, 既节约了资源又提高了效率
slab的三种状态------满、部分满、空------会随着对象的分配和释放而动态转换. 下图展示了slab状态的转换关系:
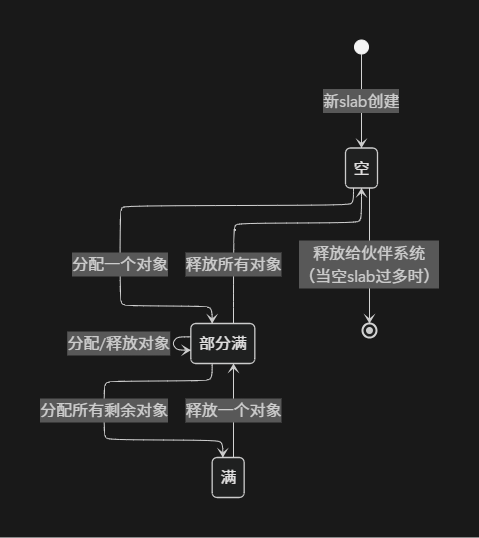
图:slab状态转换图
4 slab分配器代码实例与实践
4.1 创建与管理slab缓存
在实际内核开发中, 我们经常需要为特定的内核对象创建slab缓存. 下面通过一个完整的示例展示如何创建、使用和销毁一个slab缓存
假设我们需要为一个简单的"消息对象"创建slab缓存, 每个消息对象结构如下:
c
struct my_message {
int id;
char content[128];
long timestamp;
struct list_head list;
};创建和使用该slab缓存的完整代码如下:
c
#include <linux/slab.h>
#include <linux/init.h>
#include <linux/module.h>
static struct kmem_cache *my_cachep;
// 模块初始化函数
static int __init my_init(void)
{
void *msg;
struct my_message *message;
/* 创建slab缓存 */
my_cachep = kmem_cache_create("my_message_cache",
sizeof(struct my_message),
0, // 对齐要求
SLAB_HWCACHE_ALIGN | SLAB_PANIC,
NULL); // 构造函数
if (!my_cachep) {
printk(KERN_ERR "Failed to create slab cache\n");
return -ENOMEM;
}
printk(KERN_INFO "Successfully created slab cache: my_message_cache\n");
/* 从缓存分配对象 */
msg = kmem_cache_alloc(my_cachep, GFP_KERNEL);
if (!msg) {
printk(KERN_ERR "Failed to allocate object\n");
kmem_cache_destroy(my_cachep);
return -ENOMEM;
}
/* 使用对象 */
message = (struct my_message *)msg;
message->id = 1;
strcpy(message->content, "Hello from slab allocator!");
message->timestamp = jiffies;
printk(KERN_INFO "Allocated message: id=%d, content=%s, time=%ld\n",
message->id, message->content, message->timestamp);
/* 释放对象 */
kmem_cache_free(my_cachep, msg);
return 0;
}
// 模块退出函数
static void __exit my_exit(void)
{
/* 销毁slab缓存 */
kmem_cache_destroy(my_cachep);
printk(KERN_INFO "Slab cache destroyed\n");
}
module_init(my_init);
module_exit(my_exit);
MODULE_LICENSE("GPL");关键函数说明:
kmem_cache_create():创建新的slab缓存, 参数包括缓存名称、对象大小、对齐要求、标志位和构造函数kmem_cache_alloc():从指定缓存分配一个对象kmem_cache_free():将对象释放回缓存kmem_cache_destroy():销毁不再需要的slab缓存
标志位选择:
SLAB_HWCACHE_ALIGN:确保对象与硬件缓存行对齐, 提高缓存性能SLAB_PANIC:如果分配失败则导致内核panic, 适用于关键缓存SLAB_RECLAIM_ACCOUNT:表示该缓存可被内存回收机制回收
4.2 批量操作与性能优化
对于需要大量分配相同对象的场景, slab分配器提供了批量操作接口, 可以显著提高性能. 这些接口减少了锁的获取次数和函数调用开销, 类似于批发采购比零售更具效率
以下示例展示批量分配和释放对象:
c
// 批量分配示例
#define BATCH_SIZE 16
void batch_alloc_example(void)
{
void *objects[BATCH_SIZE];
int i, count;
/* 批量分配对象 */
count = kmem_cache_alloc_bulk(my_cachep, GFP_KERNEL, BATCH_SIZE, objects);
if (count < BATCH_SIZE) {
printk(KERN_WARNING "Requested %d, but only allocated %d objects\n",
BATCH_SIZE, count);
}
/* 使用对象 */
for (i = 0; i < count; i++) {
struct my_message *msg = objects[i];
msg->id = i;
snprintf(msg->content, sizeof(msg->content), "Message #%d", i);
msg->timestamp = jiffies;
}
/* 批量释放对象 */
kmem_cache_free_bulk(my_cachep, count, objects);
}批量操作特别适合网络和文件系统等需要处理大量相同数据结构的场景. 根据实际测试, 批量操作比单独分配每个对象可以提高30%-50% 的性能
4.3 调试与诊断技巧
slab分配器提供了丰富的调试功能, 帮助开发者诊断内存相关的问题. 以下是一些常用的调试技巧:
1. 通过/proc/slabinfo查看状态
bash
cat /proc/slabinfo该命令输出所有slab缓存的详细信息, 包括:
- 缓存名称和对象大小
- 活动对象数量
- 总对象数量
- 每slab对象数量
- 页面数量等
2. 使用slabtop实时监控
bash
slabtop类似于top命令, slabtop提供实时更新的slab缓存使用情况, 按内存使用量或对象数量排序
3. 内核参数调优
可以通过/proc/sys/vm目录下的文件调整slab分配器参数:
bash
# 调整最小保留空slab数量
echo 10 > /proc/sys/vm/min_slab_ratio
# 查看slab可回收统计
cat /proc/sys/vm/slab_reclaimable4. 调试内存泄漏
开启内核配置选项CONFIG_SLUB_DEBUG后, 可以使用以下命令检测内存泄漏:
bash
# 启用所有slab缓存的调试
echo 1 > /proc/sys/kernel/slab_debug
# 检查特定缓存的红色分区和对象跟踪
echo "cache_name" > /sys/kernel/slab/cache_name/validate5. 常见问题与解决方案
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 内核panic:slab错误 | 内存越界、重复释放 | 开启SLAB_DEBUG检测 |
| 内存使用过高 | 内存泄漏、缓存过多 | 检查对象分配释放平衡 |
| 性能下降 | 碎片化、缓存效率低 | 调整缓存参数, 批量操作 |
5 slab分配器性能优化与高级特性
5.1 硬件缓存对齐与着色
在现代处理器架构中, 硬件缓存 对性能有着至关重要的影响. slab分配器通过多种技术优化缓存利用率, 其中最重要的是缓存对齐 和缓存着色
缓存对齐 通过SLAB_HWCACHE_ALIGN标志启用, 它确保每个对象起始地址与处理器缓存行边界对齐. 这避免了错误共享(False Sharing)问题------当多个CPU访问同一缓存行中的不同变量时, 会导致缓存行无效化, 强制内存重新加载
考虑一个比喻:假设缓存行是一个货架隔板, 每个隔板有固定数量的位置. 如果物品(对象)横跨两个隔板, 取放时需要操作两个隔板, 效率低下. 对齐确保每个物品完全位于一个隔板内
缓存着色是一种更高级的优化技术. 由于硬件缓存大小有限, 不同内存地址可能映射到同一缓存位置. 如果多个常用对象恰好映射到同一缓存位置, 会导致缓存冲突, 降低命中率
slab着色通过在对象之间添加不同大小的偏移(颜色), 使对象在缓存中分布更均匀. 这就像图书馆中将同类书籍分散放在不同书架上, 避免读者聚集在同一区域造成拥堵
下面的表格对比了不同缓存优化技术的效果:
| 优化技术 | 原理 | 适用场景 | 性能影响 |
|---|---|---|---|
| 缓存对齐 | 对象起始地址对齐缓存行 | 多核环境、频繁访问对象 | 减少错误共享, 提高10-15% |
| 缓存着色 | 调整对象在slab内偏移 | 大对象、大容量缓存系统 | 改善缓存分布, 提高5-10% |
| 每CPU缓存 | 每个CPU独立缓存对象 | 高并发场景 | 减少锁竞争, 提高20-30% |
5.2 内存回收与碎片整理
slab分配器作为Linux内存管理的重要组成部分, 需要与系统的内存回收和碎片整理机制紧密配合
当系统内存压力较大时, 内核的内存回收机制会尝试回收可释放的slab缓存. slab缓存分为两类:
- 可回收缓存:包含临时对象, 如目录项缓存(dentry)和inode缓存, 这些可以在内存不足时安全释放
- 不可回收缓存:包含关键内核对象, 如进程描述符, 这些通常不会被内存回收
通过/proc/slabinfo可以查看这两类缓存的状态:
bash
grep -E "(dentry|inode_cache)" /proc/slabinfo碎片管理是slab分配器的另一个重要特性. 虽然slab设计减少了内部碎片, 但长期运行后仍可能产生外部碎片. SLUB分配器通过以下方式减少碎片:
- CPU本地缓存:保持活跃对象集中, 提高局部性
- slab合并:当相邻slab都空闲时合并它们
- 移动式分配:在特定条件下重新排列slab位置
5.3 不同架构下的优化策略
slab分配器在不同处理器架构上需要采用不同的优化策略:
x86架构:
- 缓存行大小通常为64字节
- 支持多种页面大小(4KB, 2MB, 1GB)
- 关注多核扩展性和NUMA优化
ARM架构:
- 缓存行大小可能不同(32字节, 64字节等)
- 内存访问延迟较高, 需要更积极的缓存策略
- 嵌入式场景关注内存使用效率
大型NUMA系统:
- 考虑节点局部性, 优先从本地节点分配内存
- 使用
__GFP_THISNODE标志限制分配在特定节点 - 实现跨节点缓存平衡
下面的Mermaid图展示了NUMA系统中slab分配器的层次化结构:
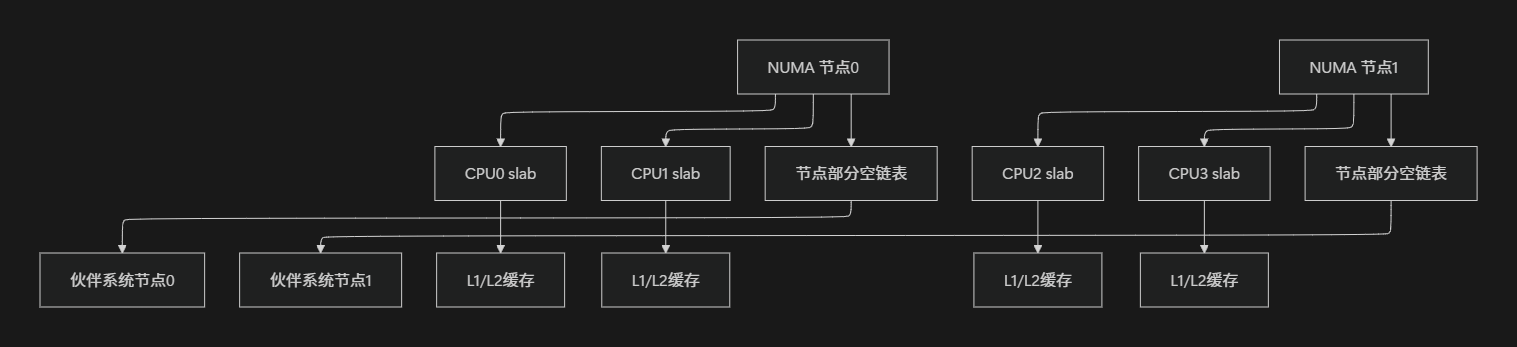
图:NUMA系统中slab分配器的层次化结构
6 总结
Linux slab分配器经过多年的发展和优化, 已成为内核内存管理的核心组件, 其技术优势主要体现在以下几个方面:
-
性能卓越:通过对象复用、每CPU缓存和硬件缓存优化, slab分配器显著减少了内存分配开销, 尤其适合小对象频繁分配的场景
-
碎片控制:基于对象的管理和slab状态跟踪有效减少了内存碎片, 提高了内存利用率
-
可扩展性:SLUB分配器的设计支持大规模多处理器系统, 通过减少锁竞争和优化本地缓存, 实现了良好的扩展性
-
调试支持:丰富的调试功能和状态监控接口, 帮助开发者诊断和解决内存相关问题
-
灵活性:支持多种分配器实现(SLAB、SLUB、SLOB), 适应从嵌入式设备到大型服务器的各种场景
下面的表格对比了slab分配器与传统内存分配方法的优势:
| 特性 | slab分配器 | 伙伴系统 | 简单分配器 |
|---|---|---|---|
| 小对象分配效率 | 高 | 低 | 中 |
| 内存碎片 | 少 | 多 | 很多 |
| 初始化开销 | 一次初始化多次使用 | 每次都需要初始化 | 每次都需要初始化 |
| 并发性能 | 高(每CPU缓存) | 中(需要锁) | 低(全局锁) |
| 内存开销 | 中 | 低 | 很低 |
| 适用场景 | 内核对象管理 | 大块内存分配 | 内存极度紧张 |