Stream流

1.获取流对象

第一种:集合
List<String> list = new ArrayList<String>();
list.add("张三丰");
list.add("张无忌");
list.add("张翠山");
list.add("王二麻子");
list.add("张良");
list.add("谢广坤");
list.stream().forEach(s -> System.out.println(s));
Set<String> set = new HashSet<String>();
set.add("张三丰");
set.add("张无忌");
set.add("张翠山");
set.add("王二麻子");
set.add("张良");
set.add("谢广坤");
set.stream().forEach(s -> System.out.println(s));
//特殊:双列集合
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("张三丰", 100);
map.put("张无忌", 35);
map.put("张翠山", 55);
map.put("王二麻子", 22);
map.put("张良", 30);
map.put("谢广坤", 55);
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
entrySet.stream().forEach(s -> System.out.println(s));
第二种:数组
int\[\] arr1 = {11, 22, 33};
double\[\] arr2 = {11.1, 22.2, 33.3};
Arrays.stream(arr1).forEach(s -> System.out.println(s));
Arrays.stream(arr2).forEach(s -> System.out.println(s));
第三种:零散数据
Stream.of(1, 2, 3, 4, 5, 6).forEach(s -> System.out.println(s));
Stream.of("张三", "李四", "王五", "赵六").forEach(s -> System.out.println(s));
2.中间方法

用案例挨个展示:
// 需求: 将集合中以 【张】 开头的数据,过滤出来并打印在控制台
ArrayList<String> list = new ArrayList<String>();
list.add("林青霞");
list.add("张曼玉");
list.add("王祖贤");
list.add("柳岩");
list.add("张敏");
list.add("张无忌");
list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).forEach(s -> System.out.println(s));
System.out.println("-------------------------------------");
// 需求1: 取前3个数据在控制台输出
list.stream().limit(3).forEach(s -> System.out.println(s));
System.out.println("-------------------------------------");
// 需求2: 跳过3个元素, 把剩下的元素在控制台输出
list.stream().skip(3).forEach(s -> System.out.println(s));
System.out.println("-------------------------------------");
// 需求3: 跳过2个元素, 把剩下的元素中前2个在控制台输出
list.stream().skip(2).limit(2).forEach(s -> System.out.println(s));
System.out.println("-------------------------------------");
// 需求4: 取前4个数据组成一个流
Stream<String> s1 = list.stream().limit(4);
// 需求5: 跳过2个数据组成一个流
Stream<String> s2 = list.stream().skip(2);
// 需求6: 合并需求4和需求5得到的流, 并把结果在控制台输出
Stream<String> s3 = Stream.concat(s1, s2);
// s3.forEach(s -> System.out.println(s));
System.out.println("-------------------------------------");
// 需求7: 合并需求4和需求5得到的流, 并把结果在控制台输出,要求字符串元素不能重复
s3.distinct().forEach(s -> System.out.println(s));
3.终结方法

演示代码:
long count = Stream.of(1, 2, 3, 4, 5, 6).filter(s -> s % 2 == 0).count();
System.out.println(count);


代码演示:
List<Integer> list1 = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).filter(s -> s % 2 == 0).collect(Collectors.toList());
System.out.println(list1);
Set<Integer> list2 = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10).filter(s -> s % 2 == 0).collect(Collectors.toSet());
System.out.println(list2);
/*
创建一个 ArrayList 集合,并添加以下字符串
"张三,23"
"李四,24"
"王五,25"
保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值
*/
public static void main(String\[\] args) {
ArrayList<String> list = new ArrayList<>();
list.add("张三,23");
list.add("李四,24");
list.add("王五,25");
Map<String, Integer> map = list.stream().filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return Integer.parseInt(s.split(",")1) >= 24;
}
}).collect(Collectors.toMap(new Function<String, String>() {
@Override
public String apply(String s) {
return s.split(",")0;
}
}, new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split(",")1);
}
}));
System.out.println(map);
}
File类

File类构造方法:

代码演示:
public static void main(String\[\] args) throws IOException {
File f1 = new File("D:\\A.txt");
f1.createNewFile();
File f2 = new File("D:\\test");
System.out.println(f2.exists());
File f3 = new File("D:\\", "test");
System.out.println(f3.exists());
File f4 = new File(new File("D:\\"), "test");
System.out.println(f4.exists());
}


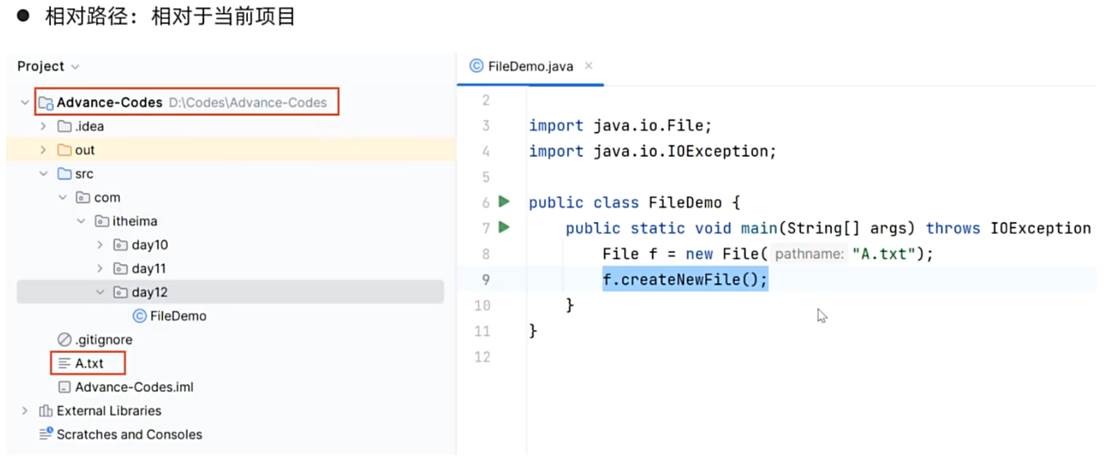
相对路径就是在写路径的时候没有写全,那就会相对于当前项目的路径去使用

//演示一下返回文件最后修改时间的方法常规使用
long time = f1.lastModified();
System.out.println(new Date(time));



代码举例:
public static void main(String\[\] args) {
File f = new File("D:\\test");
File\[\] files = f.listFiles();
//遍历数组
for (File file : files) {
System.out.println(file);
}
}
经典案例代码:
/*
需求: 键盘录入一个文件夹路径,找出这个文件夹下所有的 .java 文件
*/
public static void main(String\[\] args) {
File dir = FileTest1.getDir();
printJavaFile(dir);
}
/**
* 对接收到的文件夹路径进行遍历, 找出所有的.java文件
*/
public static void printJavaFile(File dir) {
// 1. 获取当前路径下所有的文件和文件夹对象
File\[\] files = dir.listFiles();
// 2. 对数组遍历, 获取每一个文件或文件夹对象
for (File file : files) {
// 3. 判断是否是.java文件
if (file.isFile()) {
if (file.getName().endsWith(".java")) {
System.out.println(file);
}
} else {
// 4. 代码执行到这里, 说明是文件夹
// 思路: 调用方法, 进入这个文件夹继续找.java文件
if (file.listFiles() != null) {
printJavaFile(file);
}
}
}
}
/*
需求: 设计一个方法, 删除文件夹 (文件夹的话delete() 只能删除空文件夹)
*/
public static void main(String\[\] args) {
deleteDir(new File("D:\\XXX"));
}
public static void deleteDir(File dir) {
File\[\] files = dir.listFiles();
for (File file : files) {
if (file.isFile()) {
// 文件直接删
file.delete();
} else {
// 文件夹的话, 需要进入文件夹继续删除.
if (file.listFiles() != null) {
deleteDir(file);
}
}
}
// 循环结束后, 删除空文件夹
dir.delete();
}
/*
需求: 键盘录入一个文件夹路径,统计文件夹的大小
*/
public static void main(String\[\] args) {
File dir = FileTest1.getDir();
System.out.println(getLength(dir));
}
public static long getLength(File dir) {
long sum = 0;
File\[\] files = dir.listFiles();
for (File file : files) {
if (file.isFile()) {
sum += file.length();
} else {
if (file.listFiles() != null) {
sum += getLength(file);
}
}
}
return sum;
}
public class FileTest5 {
/*
需求:键盘录入一个文件夹路径,统计文件夹中每种文件的个数并打印(考虑子文件夹)
打印格式如下:
txt:3个
doc:4个
jpg:6个
*/
static HashMap<String, Integer> hm = new HashMap<>();
static int count = 0; // 统计没有后缀名的文件
public static void main(String\[\] args) {
File dir = FileTest1.getDir();
getCount(dir);
hm.forEach(new BiConsumer<String, Integer>() {
@Override
public void accept(String key, Integer value) {
System.out.println(key + ":" + value + "个");
}
});
System.out.println("没有后缀名文件的个数为:" + count);
}
public static void getCount(File dir) {
File\[\] files = dir.listFiles();
for (File file : files) {
if (file.isFile()) {
// 文件的话, 统计个数
// 1. 获取文件名
String fileName = file.getName();
if (fileName.contains(".")) {
// 2. 获取后缀名
String\[\] sArr = fileName.split("\\.");
String type = sArrsArr.length - 1;
// 3. 统计
if (!hm.containsKey(type)) {
hm.put(type, 1);
} else {
hm.put(type, hm.get(type) + 1);
}
} else {
// 没有后缀名, 单独统计
count++;
}
} else {
// 文件夹的话, 递归调用
if (file.listFiles() != null) {
getCount(file);
}
}
}
}
}