引言:我们如何感知三维世界?
当你伸手去拿桌上的水杯时,你不会撞倒杯子,也不会够不着,你能精准地判断出它与你的距离。这背后,是我们人类与生俱来的超能力------深度感知。
那么,计算机能否像我们一样"看见"三维世界,理解物体的远近呢?答案是肯定的。在自动驾驶汽车规避障碍、无人机精准降落、工业机器人抓取零件、手机实现人像虚化乃至AR/VR构建虚拟世界的背后,都离不开一项核心技术------深度估计。
在众多深度估计技术中,有一种方法模仿了人类的双眼,它无需昂贵的专用传感器(如激光雷达),仅凭两个普通的摄像头,就能计算出场景的深度信息。这就是基于双目视觉的深度估计。
本文将从人类视觉的启发讲起,深入到严谨的数学原理,再通过一步步的代码实践,最终亲手实现一个属于自己的双目深度估计系统。
第一部分:理论基石------双目如何"看"出深度
1.1 灵感来源:人类的双眼视觉
我们先来做一个简单的实验:伸出食指,放在鼻尖正前方(至少30cm远)。先闭上左眼,用右眼看;再闭上右眼,用左眼看。我们会发现,手指相对于远处背景的位置发生了明显的移动。这种因两眼位置不同导致的物体在视网膜上成像位置的差异,被称为 "视差"。
我们的大脑正是通过解读这种视差信息,来精确地判断物体的远近。物体越近,视差越大;物体越远,视差越小。当物体无限远时,视差接近于零,两只眼睛看到的图像几乎完全相同。
双目深度估计,正是对上述生物过程的精确数学复现。
1.2 核心模型:极线几何与三角测量
为了用数学语言描述这个过程,我们需要引入一个核心概念------极线几何。
想象一下,我们有两个完全相同的相机,它们的中心点分别为 O l O_l Ol 和 O r O_r Or(代表左眼和右眼),两者之间的距离称为 基线 ,记作 B B B。空间中有一个点 P P P,它在左相机成像平面上的投影是 p l p_l pl,在右相机成像平面上的投影是 p r p_r pr。
1.2.1 极线约束
极线几何中的一个关键发现是:对于左图像上的任何一个点 p l p_l pl,其在右图像中对应的匹配点 p r p_r pr 必然位于一条特定的直线上 ,这条直线就是 极线。
这个约束极大地简化了我们的工作。如果没有这个约束,我们在右图中寻找 p l p_l pl 的匹配点时,需要遍历整个图像,这是一个 O ( n 2 ) O(n^2) O(n2) 的复杂问题。但有了极线约束,我们只需要在一条线上进行搜索,复杂度降为 O ( n ) O(n) O(n)。这就像在图书馆找书,从漫无目的地逛整个图书馆,变成了根据索书号直接去一个特定的书架寻找。
1.2.2 三角测量原理
找到了匹配点对 ( p l , p r ) (p_l, p_r) (pl,pr) 后,我们就可以通过三角测量法计算深度。
让我们来看一个简化后的模型(两个相机光轴平行,成像平面共面):
P(X,Y,Z)
/ | \
/ | \
/ | \
/ | \
Ol | Or
|------B------|
|<----->|- O l O_l Ol 和 O r O_r Or 是左右相机的光心,距离为基线 B B B。
- P P P 是空间中的一点,其深度(即Z坐标)是我们要求的。
- p l p_l pl 和 p r p_r pr 是 P P P 在左右相机成像平面上的投影点。
- f f f 是相机的焦距。
根据相似三角形原理,我们可以得到:
B − ( x l − x r ) Z − f = B Z \frac{B - (x_l - x_r)}{Z - f} = \frac{B}{Z} Z−fB−(xl−xr)=ZB
其中, ( x l − x r ) (x_l - x_r) (xl−xr) 就是 视差 ,我们用 d d d 表示。经过整理,可以得到一个极其重要的公式:
Z = B ⋅ f d Z = \frac{B \cdot f}{d} Z=dB⋅f
这个公式就是双目深度估计的灵魂:
- 深度 Z Z Z 与 视差 d d d 成反比。视差越大(两个像点离得越远),物体越近(Z越小);视差越小(两个像点离得越近),物体越远(Z越大)。
- 基线 B B B 和 焦距 f f f 是系统固有的参数。基线越长,理论上能测量的最远距离就越远,但对近处物体的测量盲区也会变大。
1.3 立体匹配:寻找"另一半"的挑战
三角测量的前提是,我们必须找到左图中的一个像素点在右图中对应的那个像素点。这个过程就是 立体匹配。它是整个双目深度估计中最核心、最困难的一步。
为什么困难?
- 无纹理区域:一面纯白的墙,左图和右图的区域看起来一模一样,无法确定哪个像素对应哪个像素。
- 重复纹理:一张布满同样格子的桌布,很容易在极线上找到多个相似的区域,导致匹配错误。
- 遮挡:有些物体只能被其中一个相机看到,在另一个相机中根本没有匹配点。
- 光照变化:两个相机的曝光、白平衡略有不同,会导致同一物体颜色和亮度不一致。
为了解决这些问题,研究人员提出了多种立体匹配算法,主要可分为:
- 局部方法 :如块匹配(Block Matching, BM)。它为左图的一个像素点,取其周围一个小窗口(比如9x9的像素块),然后在右图的极线上滑动这个窗口,计算每个位置与左图窗口的相似度(使用SAD, SSD, NCC等度量方法),选择相似度最高的位置作为匹配点。这种方法速度快,但在无纹理和重复纹理区域效果差。
- 全局方法 :如半全局匹配(Semi-Global Matching, SGM)。它不仅仅考虑局部窗口的相似性,还考虑整个视差图的光滑性约束(即相邻像素的视差应该变化平缓)。通过构建一个全局能量函数并最小化它来求解视差图。这种方法精度高,能更好地处理弱纹理区域,但计算量巨大。
- 深度学习方法:近年来,利用卷积神经网络(CNN)来学习匹配代价的计算或直接回归视差图,取得了巨大的成功,精度远超传统方法。但这通常需要大量的标注数据和高计算资源。
在本文中,我们将重点介绍OpenCV中实现的BM 和SGBM(StereoSGBM) 算法,它们是实践中最常用、最成熟的传统方法。
第二部分:实践准备------搭建你的双目视觉系统
在开始写代码之前,我们必须确保我们的双目相机系统是"健康"的。一个未经校准的双目系统,就像两个近视且散光程度不一样的人,无法协同工作。这一步至关重要,直接决定了后续深度估计的成败。
2.1 硬件搭建与图像采集
硬件选择:
- 相机:两个型号、参数相同的USB摄像头或网络摄像头。分辨率越高,理论上深度图越精细。全局快门的相机比滚动快门的相机在运动场景下表现更好。
- 固定方式:将两个相机尽可能地平行固定在同一水平线上。可以使用现成的双目摄像头模组,也可以自己用3D打印或支架组装。刚性要好,避免震动导致相对位置变化。
采集图像:
同时触发左右相机,采集同一场景的图片。为了后续标定,我们需要采集大约15-20张不同姿态的 棋盘格 图片。确保棋盘格在两张图片中都能被完整看到,并且姿态(平移、旋转)多样。
2.2 相机标定------洞察相机的"内心世界"
理想情况下,相机是小孔成像模型。但现实中,镜头会引入 畸变 ,导致图像边缘的直线变弯。标定的目的就是找出每个相机的 内参 和 畸变系数。
- 内参矩阵 K K K :描述了相机如何将三维世界点映射到二维图像像素。它包含了焦距 f x , f y f_x, f_y fx,fy 和主点坐标 c x , c y c_x, c_y cx,cy。
K = f x 0 c x 0 f y c y 0 0 1 K = \begin{bmatrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{bmatrix} K= fx000fy0cxcy1 - 畸变系数:一组数值(通常为5个:k1, k2, p1, p2, k3),描述了镜头的径向畸变和切向畸变。
OpenCV提供了 cv2.findChessboardCorners 和 cv2.calibrateCamera 函数来轻松完成单目标定。
2.3 立体标定与校正------让双眼"对齐"
即使我们努力将两个相机平行放置,它们在物理上也很难完全对齐。立体标定的目的就是找到两个相机之间的相对位置关系,即 外参 :旋转矩阵 R R R 和平移向量 T T T(其中 T T T 的模就是基线 B B B)。
找到外参后,我们就可以进行 立体校正 。这是关键的一步,它的目标是将两个相机的成像平面重投影到同一个平面上,使得极线变得水平对齐。
校正后,左图上的一个点,其在右图中的匹配点,必然位于同一扫描线(同一行)上 。这极大地简化了匹配搜索,从在一条可能倾斜的直线上搜索,变成了在同一行上搜索。
OpenCV中使用 cv2.stereoCalibrate 进行立体标定,并使用 cv2.stereoRectify 计算校正映射矩阵,最后通过 cv2.initUndistortRectifyMap 生成映射表,cv2.remap 函数应用校正。
第三部分:代码实战------用OpenCV实现深度估计
理论已经充足,工具已经备好,让我们开始动手编码吧!我们将使用Python和OpenCV库,一步步构建一个完整的双目深度估计流水线。
3.1 环境配置
首先,创建 Python 环境,安装必要的库。
bash
conda create -n opencv python=3.10
bash
pip install opencv-python opencv-contrib-python numpy matplotlib
3.2 第一步:双目标定与校正

- 9*6 棋盘格
- 单格子实际尺寸 27*27 mm
我们将采集好了左右相机的棋盘格图像(10*7 棋盘格,4*4 cm),分别存放在 left/ 和 right/ 文件夹中。


python
import numpy as np
import cv2
import glob
# --- 配置参数 ---
chessboard_size = (9, 6) # 棋盘格内角点数量 (宽度,高度)
square_size = 40.0 # 棋盘格方格的实际大小,单位毫米(用于获取真实尺度,如果只关心相对深度可设为1)
# 终止标准
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 准备对象点,例如 (0,0,0), (1,0,0), (2,0,0) ...., (8,5,0)
objp = np.zeros((chessboard_size[0] * chessboard_size[1], 3), np.float32)
objp[:, :2] = np.mgrid[0:chessboard_size[0], 0:chessboard_size[1]].T.reshape(-1, 2)
objp *= square_size
# 用于存储所有图像的对象点和图像点
objpoints = [] # 真实世界中的3D点
imgpoints_l = [] # 左图像中的2D点
imgpoints_r = [] # 右图像中的2D点
# 获取左右图像路径
images_left = sorted(glob.glob('left/*.jpg'))
images_right = sorted(glob.glob('right/*.jpg'))
# --- 单目标定:分别查找左右相机的角点 ---
for img_path_l, img_path_r in zip(images_left, images_right):
img_l = cv2.imread(img_path_l)
img_r = cv2.imread(img_path_r)
gray_l = cv2.cvtColor(img_l, cv2.COLOR_BGR2GRAY)
gray_r = cv2.cvtColor(img_r, cv2.COLOR_BGR2GRAY)
# 查找棋盘格角点
ret_l, corners_l = cv2.findChessboardCorners(gray_l, chessboard_size, None)
ret_r, corners_r = cv2.findChessboardCorners(gray_r, chessboard_size, None)
# 如果都找到了,添加对象点和精确的角点
if ret_l and ret_r:
objpoints.append(objp)
# 角点亚像素精细化
corners_l_refined = cv2.cornerSubPix(gray_l, corners_l, (11,11), (-1,-1), criteria)
imgpoints_l.append(corners_l_refined)
corners_r_refined = cv2.cornerSubPix(gray_r, corners_r, (11,11), (-1,-1), criteria)
imgpoints_r.append(corners_r_refined)
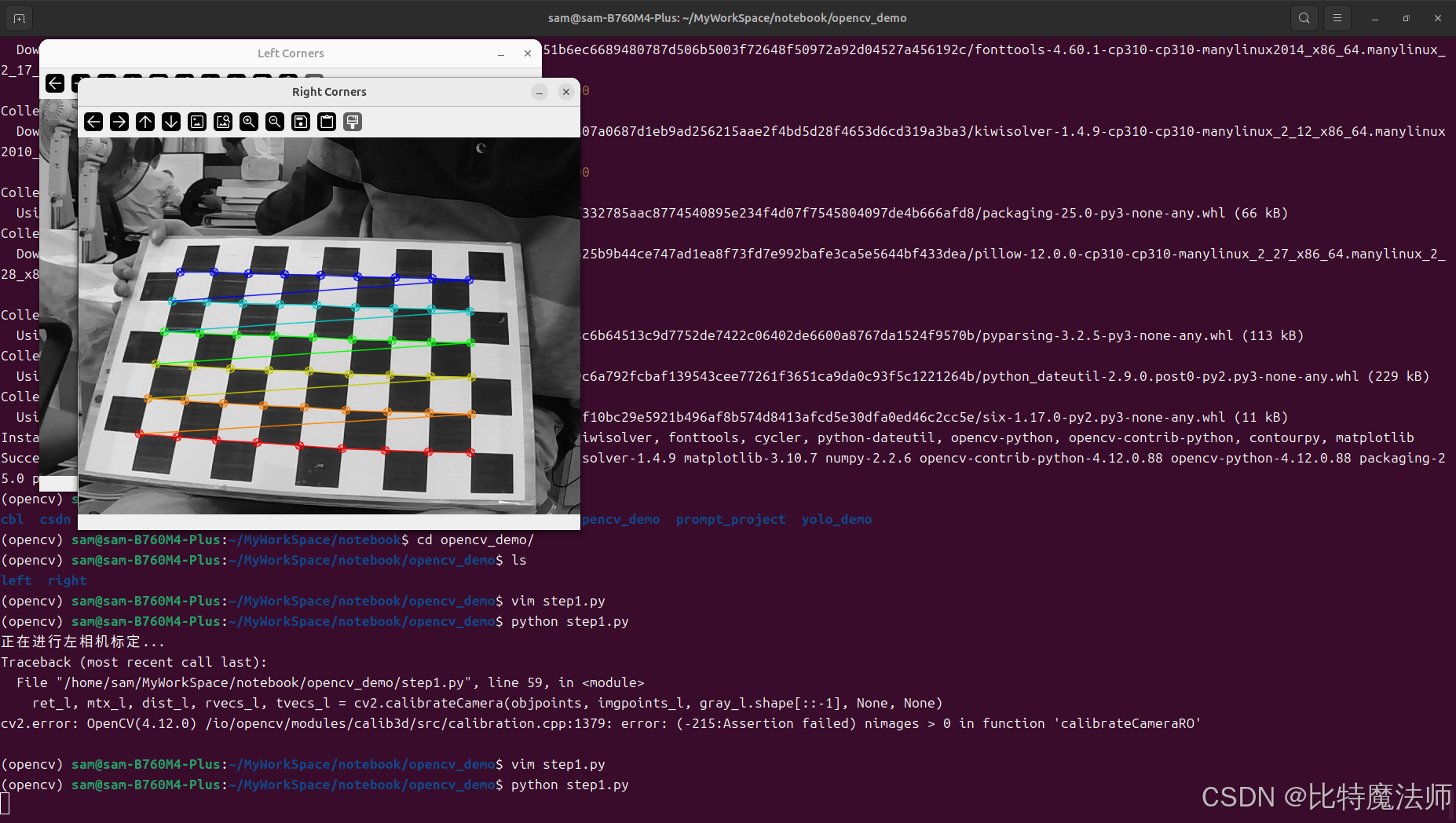
# 可视化(可选)
cv2.drawChessboardCorners(img_l, chessboard_size, corners_l_refined, ret_l)
cv2.drawChessboardCorners(img_r, chessboard_size, corners_r_refined, ret_r)
cv2.imshow('Left Corners', img_l)
cv2.imshow('Right Corners', img_r)
cv2.waitKey(500) # 显示0.5秒
cv2.destroyAllWindows()
# --- 单目标定 ---
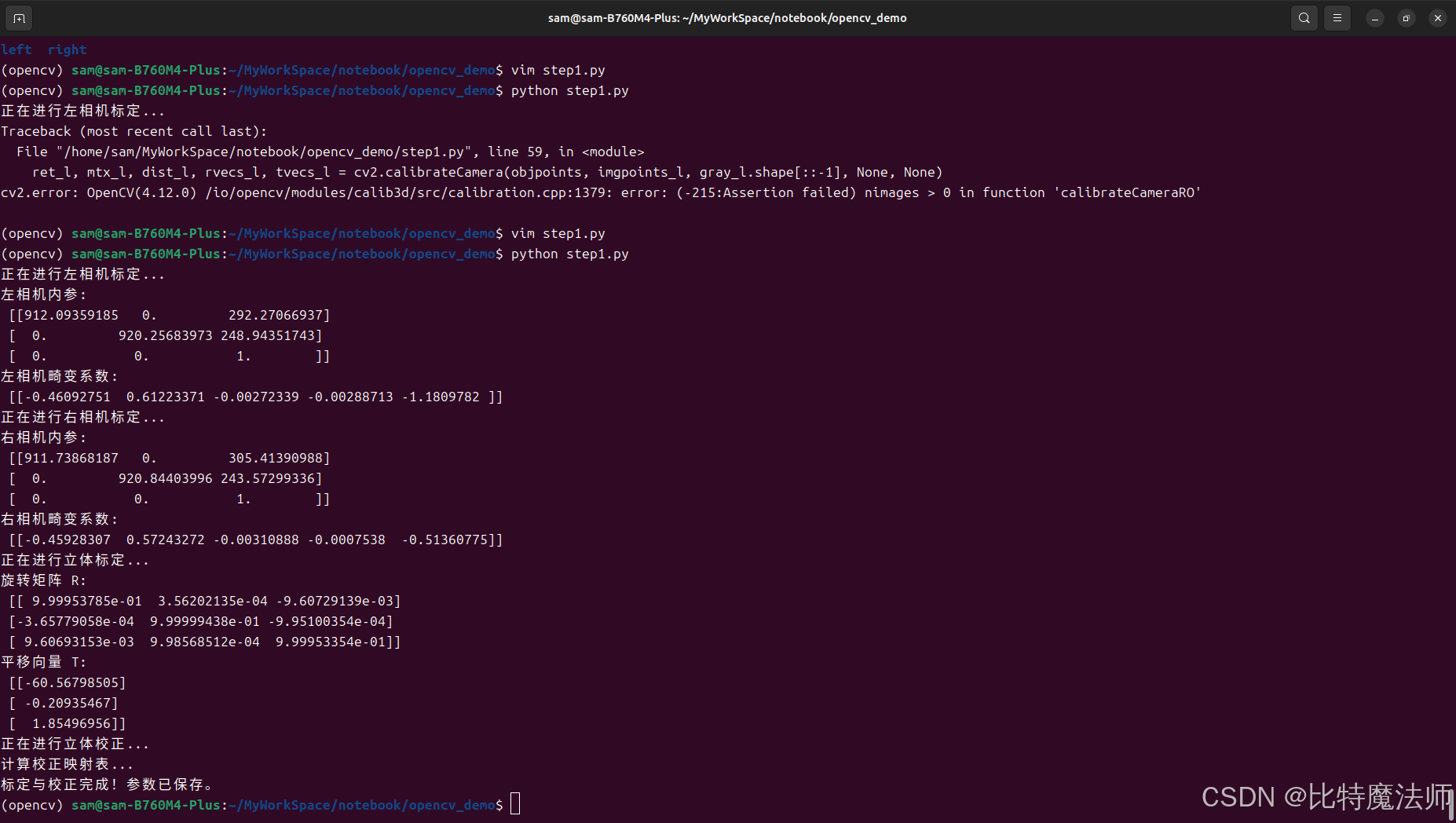
print("正在进行左相机标定...")
ret_l, mtx_l, dist_l, rvecs_l, tvecs_l = cv2.calibrateCamera(objpoints, imgpoints_l, gray_l.shape[::-1], None, None)
print("左相机内参:\n", mtx_l)
print("左相机畸变系数:\n", dist_l)
print("正在进行右相机标定...")
ret_r, mtx_r, dist_r, rvecs_r, tvecs_r = cv2.calibrateCamera(objpoints, imgpoints_r, gray_r.shape[::-1], None, None)
print("右相机内参:\n", mtx_r)
print("右相机畸变系数:\n", dist_r)
# --- 立体标定 ---
print("正在进行立体标定...")
flags = cv2.CALIB_FIX_INTRINSIC # 固定单目标定得到的内参和畸变
criteria_stereo = (cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 100, 1e-5)
retval, _, _, _, _, R, T, E, F = cv2.stereoCalibrate(
objpoints, imgpoints_l, imgpoints_r,
mtx_l, dist_l, mtx_r, dist_r,
gray_l.shape[::-1], criteria=criteria_stereo, flags=flags
)
print("旋转矩阵 R:\n", R)
print("平移向量 T:\n", T) # 这个T的模就是基线长度
# --- 立体校正 ---
print("正在进行立体校正...")
rectify_scale = 0 # 0表示校正后图像会进行裁剪,1表示保留所有原图像素(会有黑边)
R1, R2, P1, P2, Q, roi1, roi2 = cv2.stereoRectify(
mtx_l, dist_l, mtx_r, dist_r,
gray_l.shape[::-1], R, T,
alpha=rectify_scale
)
# --- 计算校正映射表 ---
print("计算校正映射表...")
map_l1, map_l2 = cv2.initUndistortRectifyMap(mtx_l, dist_l, R1, P1, gray_l.shape[::-1], cv2.CV_16SC2)
map_r1, map_r2 = cv2.initUndistortRectifyMap(mtx_r, dist_r, R2, P2, gray_r.shape[::-1], cv2.CV_16SC2)
# 保存校准参数(非常重要,以后可以直接加载使用)
np.savez('stereo_calibration_params.npz',
map_l1=map_l1, map_l2=map_l2,
map_r1=map_r1, map_r2=map_r2,
Q=Q)
print("标定与校正完成!参数已保存。")运行效果:
3.3 第二步:立体匹配与深度图生成
现在,我们可以使用校正后的图像来计算视差图,进而得到深度图。我们将演示OpenCV中两种主要的立体匹配器:BM和SGBM。
python
# 加载之前保存的校正参数
calibration_data = np.load('stereo_calibration_params.npz')
map_l1 = calibration_data['map_l1']
map_l2 = calibration_data['map_l2']
map_r1 = calibration_data['map_r1']
map_r2 = calibration_data['map_r2']
Q = calibration_data['Q'] # 重投影矩阵Q,用于将视差图转换为深度图
# 读取一对新的左右测试图像
img_l = cv2.imread('test_left.jpg')
img_r = cv2.imread('test_right.jpg')
# 应用校正映射,得到校正后的图像
img_l_rectified = cv2.remap(img_l, map_l1, map_l2, cv2.INTER_LINEAR)
img_r_rectified = cv2.remap(img_r, map_r1, map_r2, cv2.INTER_LINEAR)
# 转换为灰度图用于匹配
gray_l_rectified = cv2.cvtColor(img_l_rectified, cv2.COLOR_BGR2GRAY)
gray_r_rectified = cv2.cvtColor(img_r_rectified, cv2.COLOR_BGR2GRAY)
# --- 方法一:使用BM立体匹配器 ---
print("使用BM算法计算视差图...")
stereoBM = cv2.StereoBM_create(numDisparities=80, blockSize=15) # 参数需要调整
# numDisparities: 最大视差 - 最小视差,必须是16的整数倍。这个值决定了能探测的最近距离。
# blockSize: 匹配的块大小,必须是奇数。越大越平滑,但边缘细节越模糊。
disparity_BM = stereoBM.compute(gray_l_rectified, gray_r_rectified)
# 归一化显示
disparity_BM_vis = cv2.normalize(disparity_BM, None, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U)
# 注意:BM计算出的原始视差是16位有符号整数,需要除以16.0得到真正的视差值。
# --- 方法二:使用SGBM立体匹配器(推荐) ---
print("使用SGBM算法计算视差图...")
stereoSGBM = cv2.StereoSGBM_create(
minDisparity=0,
numDisparities=80, # 同BM
blockSize=5, # 通常比BM小
P1=8 * 3 * 5 ** 2, # 控制视差平滑度的参数,通常P1=8*通道数*SADWindowSize**2
P2=32 * 3 * 5 ** 2, # P2通常为P1的3-4倍
disp12MaxDiff=1,
uniquenessRatio=15, # 唯一性比率,值越大匹配越稳定
speckleWindowSize=100, # 过滤小连通区的窗口大小
speckleRange=32 # 视差变化阈值
)
disparity_SGBM = stereoSGBM.compute(gray_l_rectified, gray_r_rectified).astype(np.float32) / 16.0 # SGBM结果直接除以16
# 归一化显示
disparity_SGBM_vis = cv2.normalize(disparity_SGBM, None, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U)
# --- 将视差图转换为深度图 ---
# 使用重投影矩阵Q
# depth = (f * B) / (disparity) 这个计算被封装在reprojectImageTo3D中
points_3D = cv2.reprojectImageTo3D(disparity_SGBM, Q) # 这会得到一个HxWx3的数组,其中每个像素是(X, Y, Z)
depth_map = points_3D[:, :, 2] # 我们只取Z坐标,即深度
# 过滤掉无效值(视差为0或负值通常表示无效点)
depth_map[disparity_SGBM <= 0.0] = 0
# 也可以设置一个最大深度阈值,避免无穷大的值
depth_map[depth_map > 10000.0] = 0
# 可视化结果
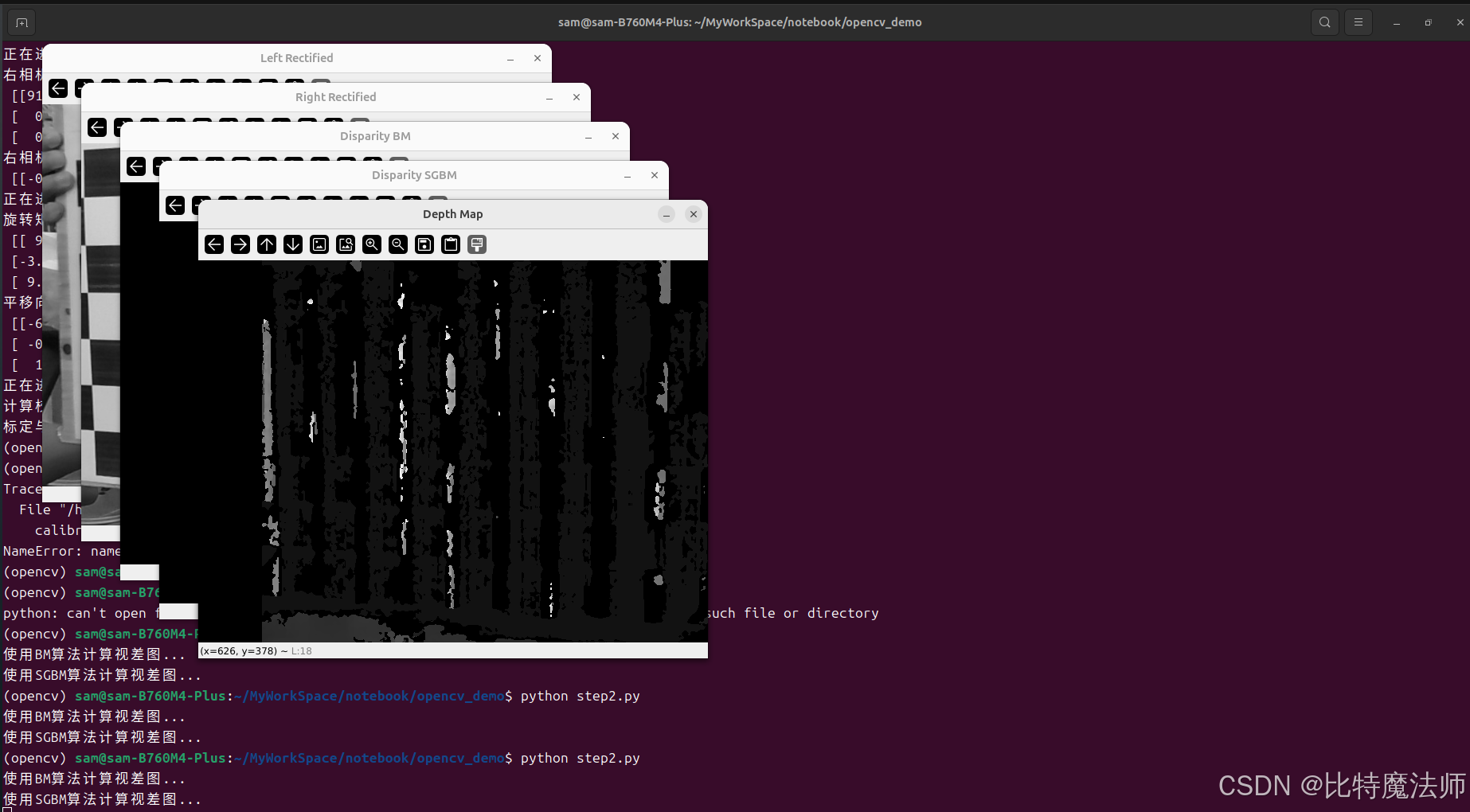
cv2.imshow('Left Rectified', img_l_rectified)
cv2.imshow('Right Rectified', img_r_rectified)
cv2.imshow('Disparity BM', disparity_BM_vis)
cv2.imshow('Disparity SGBM', disparity_SGBM_vis)
# 深度图也需要归一化显示
depth_map_vis = cv2.normalize(depth_map, None, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U)
cv2.imshow('Depth Map', depth_map_vis)
cv2.waitKey(0)
cv2.destroyAllWindows()运行效果:
3.4 案例:测量图像中物体的距离
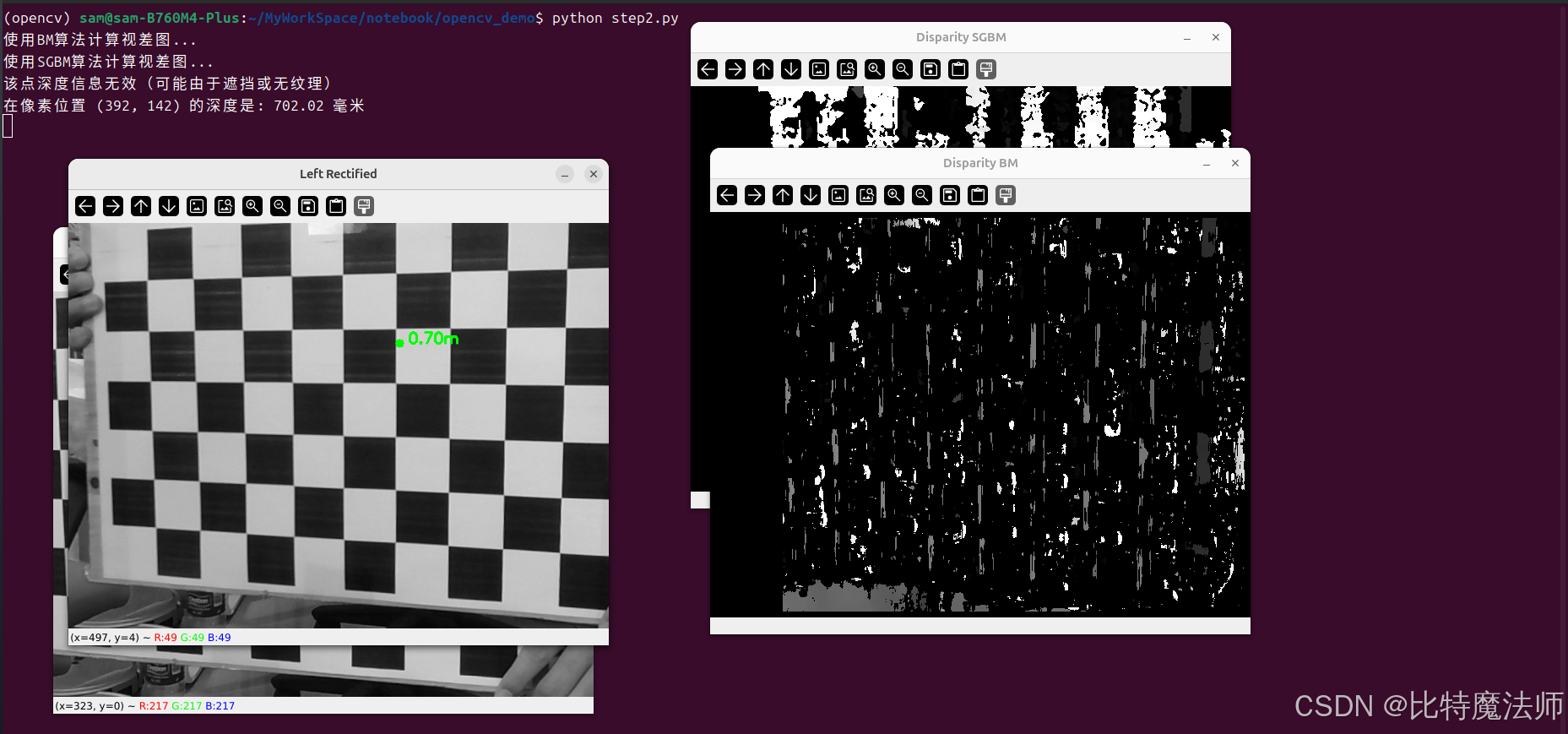
假设我们想测量图像中某个物体到相机的距离。我们可以通过鼠标点击来获取该点的深度值。
python
# 接上一段代码,我们已经得到了depth_map
# 定义一个鼠标回调函数
def get_depth_value(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
depth_value = depth_map[y, x]
if depth_value > 0:
print(f"在像素位置 ({x}, {y}) 的深度是: {depth_value:.2f} 毫米")
# 在图像上标记
img_with_marker = img_l_rectified.copy()
cv2.circle(img_with_marker, (x, y), 5, (0, 255, 0), -1)
cv2.putText(img_with_marker, f'{depth_value/1000:.2f}m', (x+10, y), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0,255,0), 2)
cv2.imshow('Left Rectified', img_with_marker)
else:
print("该点深度信息无效(可能由于遮挡或无纹理)")
# 显示左图并设置鼠标回调
cv2.imshow('Left Rectified', img_l_rectified)
cv2.setMouseCallback('Left Rectified', get_depth_value)
cv2.waitKey(0)
cv2.destroyAllWindows()运行效果:
3.5 噪声处理与点云图
使用后处理技术提升深度图质量,减少噪声和空洞,并生成清晰的3D点云。
bash
pip install opencv-python opencv-contrib-python open3d matplotlib numpy
完整代码:
python
import numpy as np
import cv2
from cv2 import ximgproc
import open3d as o3d
from matplotlib import pyplot as plt
# 兼容中文字体
plt.rcParams['font.sans-serif'] = ['Noto Serif CJK JP']
#用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
def post_process_depth_map(disparity_map, left_image, right_image=None, use_wls=True):
"""
深度图后处理完整流程
"""
# 确保视差图是浮点类型
if disparity_map.dtype != np.float32:
disparity_map = disparity_map.astype(np.float32)
# 步骤1: 基础无效值过滤
disparity_processed = disparity_map.copy()
disparity_processed[disparity_map <= 0.0] = 0
print("原始视差图统计:")
print(f" 有效像素比例: {np.sum(disparity_processed > 0) / disparity_processed.size * 100:.2f}%")
print(f" 视差范围: [{np.min(disparity_processed[disparity_processed>0]):.2f}, {np.max(disparity_processed):.2f}]")
if use_wls and right_image is not None:
try:
print("应用WLS滤波...")
# 创建右视差计算器 - 使用相同的参数
right_matcher = cv2.ximgproc.createRightMatcher(stereoSGBM)
# 计算右视差图
right_disp = right_matcher.compute(cv2.cvtColor(right_image, cv2.COLOR_BGR2GRAY),
cv2.cvtColor(left_image, cv2.COLOR_BGR2GRAY))
right_disp = right_disp.astype(np.float32) / 16.0
# 创建WLS滤波器
wls_filter = ximgproc.createDisparityWLSFilter(stereoSGBM)
wls_filter.setLambda(8000.0)
wls_filter.setSigmaColor(1.5)
# 应用滤波
disparity_processed = wls_filter.filter(disparity_map, left_image, disparity_map_right=right_disp)
# 尝试获取置信度图,如果可用的话
try:
confidence_map = wls_filter.getConfidenceMap()
if confidence_map is not None:
confidence_threshold = 0.3 * np.max(confidence_map)
disparity_processed[confidence_map < confidence_threshold] = 0
print("已应用置信度过滤")
else:
print("置信度图不可用,跳过置信度过滤")
except:
print("无法获取置信度图,跳过置信度过滤")
except Exception as e:
print(f"WLS滤波失败: {e},将使用基础后处理")
# WLS失败时回退到基础处理
# 步骤2: 中值滤波去除椒盐噪声
print("应用中值滤波...")
# 只对有效区域进行滤波
valid_mask = disparity_processed > 0
if np.any(valid_mask):
disparity_temp = disparity_processed.copy()
disparity_temp[~valid_mask] = np.nan
# 使用中值滤波
disparity_median = cv2.medianBlur(disparity_processed, 5)
# 只更新有效区域的滤波结果
disparity_processed[valid_mask] = disparity_median[valid_mask]
# 步骤3: 双边滤波保持边缘
print("应用双边滤波...")
valid_mask = disparity_processed > 0
if np.sum(valid_mask) > 1000: # 只有足够多有效点时才进行双边滤波
disparity_bilateral = cv2.bilateralFilter(disparity_processed, d=9, sigmaColor=50, sigmaSpace=50)
disparity_processed[valid_mask] = disparity_bilateral[valid_mask]
# 步骤4: 空洞填充(可选)
print("应用空洞填充...")
disparity_filled = fill_small_holes(disparity_processed, max_hole_size=50)
# 最终无效值过滤
disparity_filled[disparity_filled <= 0.0] = 0
print("处理后视差图统计:")
print(f" 有效像素比例: {np.sum(disparity_filled > 0) / disparity_filled.size * 100:.2f}%")
print(f" 视差范围: [{np.min(disparity_filled[disparity_filled>0]):.2f}, {np.max(disparity_filled):.2f}]")
return disparity_filled
def fill_small_holes(disparity, max_hole_size=50):
"""
填充小空洞
"""
disparity_filled = disparity.copy()
# 找到所有空洞(值为0的区域)
holes_mask = disparity == 0
# 使用形态学操作识别小空洞
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
small_holes = cv2.morphologyEx(holes_mask.astype(np.uint8), cv2.MORPH_OPEN, kernel)
# 对每个小空洞区域,用周围有效像素的中值填充
contours, _ = cv2.findContours(small_holes, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
if cv2.contourArea(contour) < max_hole_size:
# 获取空洞的边界框
x, y, w, h = cv2.boundingRect(contour)
# 扩展边界框以获取周围区域
pad = 5
x1 = max(0, x - pad)
y1 = max(0, y - pad)
x2 = min(disparity.shape[1], x + w + pad)
y2 = min(disparity.shape[0], y + h + pad)
# 获取周围区域的有效值
surrounding_region = disparity[y1:y2, x1:x2]
valid_values = surrounding_region[surrounding_region > 0]
if len(valid_values) > 0:
# 用中值填充空洞
fill_value = np.median(valid_values)
# 创建当前空洞的掩码
hole_mask = np.zeros_like(disparity, dtype=np.uint8)
cv2.drawContours(hole_mask, [contour], -1, 1, -1)
# 填充空洞
disparity_filled[hole_mask == 1] = fill_value
return disparity_filled
def create_colored_point_cloud(disparity_map, color_image, Q, max_depth=5000):
"""
创建彩色点云
"""
print("生成点云...")
# 使用reprojectImageTo3D生成3D点
points_3D = cv2.reprojectImageTo3D(disparity_map, Q)
# 创建掩码,只保留有效深度点
mask = (disparity_map > 0) & (points_3D[:, :, 2] > 0) & (points_3D[:, :, 2] < max_depth)
# 提取有效点
valid_points = points_3D[mask]
valid_colors = color_image[mask]
# 转换颜色从BGR到RGB
valid_colors = valid_colors[:, [2, 1, 0]] / 255.0
print(f"点云包含 {len(valid_points)} 个点")
# 创建Open3D点云对象
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(valid_points)
pcd.colors = o3d.utility.Vector3dVector(valid_colors)
return pcd
def post_process_point_cloud(pcd):
"""
点云后处理
"""
print("进行点云后处理...")
original_point_count = len(pcd.points)
# 1. 统计离群点移除
try:
cl, ind = pcd.remove_statistical_outlier(nb_neighbors=20, std_ratio=2.0)
pcd_filtered = pcd.select_by_index(ind)
print(f" 统计离群点移除: {original_point_count} -> {len(pcd_filtered.points)}")
except:
print(" 统计离群点移除失败,跳过")
pcd_filtered = pcd
# 2. 半径离群点移除
try:
cl, ind = pcd_filtered.remove_radius_outlier(nb_points=16, radius=50)
pcd_final = pcd_filtered.select_by_index(ind)
print(f" 半径离群点移除: {len(pcd_filtered.points)} -> {len(pcd_final.points)}")
except:
print(" 半径离群点移除失败,跳过")
pcd_final = pcd_filtered
print(f"点云后处理完成: {original_point_count} -> {len(pcd_final.points)} 个点")
return pcd_final
def visualize_results(original_disp, processed_disp, color_image, point_cloud):
"""
可视化结果
"""
# 创建可视化窗口
plt.figure(figsize=(20, 12))
# 原始视差图
plt.subplot(2, 3, 1)
plt.imshow(original_disp, cmap='jet', vmin=0, vmax=np.max(original_disp))
plt.colorbar()
plt.title('原始视差图')
plt.axis('off')
# 处理后视差图
plt.subplot(2, 3, 2)
plt.imshow(processed_disp, cmap='jet', vmin=0, vmax=np.max(processed_disp))
plt.colorbar()
plt.title('处理后视差图')
plt.axis('off')
# 彩色图像
plt.subplot(2, 3, 3)
plt.imshow(cv2.cvtColor(color_image, cv2.COLOR_BGR2RGB))
plt.title('彩色图像')
plt.axis('off')
# 深度图(从视差图转换)
depth_map = np.zeros_like(processed_disp)
valid_mask = processed_disp > 0
depth_map[valid_mask] = 1.0 / processed_disp[valid_mask] # 简化的深度计算
plt.subplot(2, 3, 4)
plt.imshow(depth_map, cmap='plasma')
plt.colorbar()
plt.title('深度图')
plt.axis('off')
# 有效点掩码
plt.subplot(2, 3, 5)
plt.imshow(valid_mask, cmap='gray')
plt.title('有效点掩码')
plt.axis('off')
# 视差图差异
plt.subplot(2, 3, 6)
diff = processed_disp - original_disp
diff[~valid_mask] = 0
plt.imshow(diff, cmap='coolwarm', vmin=-10, vmax=10)
plt.colorbar()
plt.title('处理前后差异')
plt.axis('off')
plt.tight_layout()
plt.show()
# 可视化点云
print("可视化点云...")
try:
o3d.visualization.draw_geometries([point_cloud],
window_name="3D点云",
width=1024,
height=768,
left=50,
top=50)
except Exception as e:
print(f"点云可视化失败: {e}")
def save_point_cloud(pcd, filename):
"""
保存点云到文件
"""
# 确保文件扩展名正确
if not filename.endswith('.ply'):
filename += '.ply'
try:
o3d.io.write_point_cloud(filename, pcd)
print(f"点云已保存到: {filename}")
except Exception as e:
print(f"保存点云失败: {e}")
# 主处理流程
if __name__ == "__main__":
# 加载之前保存的校正参数
try:
calibration_data = np.load('stereo_calibration_params.npz')
map_l1 = calibration_data['map_l1']
map_l2 = calibration_data['map_l2']
map_r1 = calibration_data['map_r1']
map_r2 = calibration_data['map_r2']
Q = calibration_data['Q']
print("校正参数加载成功")
except:
print("错误:无法加载校正参数,请先运行标定程序")
exit()
# 读取测试图像
img_l = cv2.imread('test_left.jpg')
img_r = cv2.imread('test_right.jpg')
if img_l is None or img_r is None:
print("错误:无法读取测试图像")
exit()
print(f"图像尺寸: {img_l.shape}")
# 应用校正
img_l_rectified = cv2.remap(img_l, map_l1, map_l2, cv2.INTER_LINEAR)
img_r_rectified = cv2.remap(img_r, map_r1, map_r2, cv2.INTER_LINEAR)
# 转换为灰度图用于匹配
gray_l = cv2.cvtColor(img_l_rectified, cv2.COLOR_BGR2GRAY)
gray_r = cv2.cvtColor(img_r_rectified, cv2.COLOR_BGR2GRAY)
# 创建SGBM立体匹配器
print("计算视差图...")
window_size = 5
# 全局定义 stereoSGBM,以便在函数中使用
global stereoSGBM
stereoSGBM = cv2.StereoSGBM_create(
minDisparity=0,
numDisparities=96,
blockSize=window_size,
P1=8 * 3 * window_size ** 2,
P2=32 * 3 * window_size ** 2,
disp12MaxDiff=5,
uniquenessRatio=10,
speckleWindowSize=200,
speckleRange=2,
preFilterCap=63,
mode=cv2.STEREO_SGBM_MODE_SGBM_3WAY
)
# 计算原始视差图
disparity_raw = stereoSGBM.compute(gray_l, gray_r).astype(np.float32) / 16.0
# 应用后处理
print("开始后处理...")
disparity_processed = post_process_depth_map(disparity_raw, img_l_rectified, img_r_rectified, use_wls=True)
# 生成点云
point_cloud = create_colored_point_cloud(disparity_processed, img_l_rectified, Q, max_depth=3000)
# 点云后处理
point_cloud_processed = post_process_point_cloud(point_cloud)
# 可视化结果
visualize_results(disparity_raw, disparity_processed, img_l_rectified, point_cloud_processed)
# 保存点云
save_point_cloud(point_cloud_processed, 'output_point_cloud.ply')
print("处理完成!")运行效果:


第四部分:深入与优化------从"能用"到"好用"
运行完上面的代码,你可能已经得到了第一张深度图,但它可能充满了噪声、空洞和错误。别担心,这才是常态。现在,让我们深入探讨如何优化它。
4.1 参数调优的艺术
立体匹配器的性能极大地依赖于参数设置。没有一套"万能参数",需要根据你的场景和相机进行调整。
numDisparities(视差范围) :- 作用:决定了系统能探测的最近距离。值越大,能看到的物体越近,但计算量也越大。
- 调优:估算你场景中最近物体的视差。可以通过在校正后的图像上手动测量一个近处物体在左右图中的水平像素差来大致确定。设置一个比这个值稍大的、且是16整数倍的值。
blockSize(块大小) :- 作用:参与匹配的窗口大小。窗口越大,抗噪声能力越强,但边缘细节越模糊;窗口越小,边缘保持越好,但噪声更敏感。
- 调优:通常在3~15之间的奇数中尝试。对于纹理丰富的场景,可以用小窗口;对于弱纹理场景,需要大窗口。
uniquenessRatio(唯一性比率) :- 作用:一个百分比值。只有当最佳匹配的代价比次佳匹配的代价足够"独特"(好出这个百分比)时,才接受该匹配。用于过滤模糊不清的匹配。
- 调优:通常设置在5-15之间。值太小会产生噪声,值太大会导致视差图出现大量空洞。
speckleWindowSize和speckleRange:- 作用 :用于后处理,过滤小的孤立噪声点(斑点)。
speckleWindowSize定义了判断为斑点的最大连通区域大小(像素点数),speckleRange定义了判断为同一平面的视差最大变化值。 - 调优 :如果视差图中有很多小噪点,就增大
speckleWindowSize(如100)。如果同一平面被分割成多个区域,就适当增大speckleRange。
- 作用 :用于后处理,过滤小的孤立噪声点(斑点)。
调优策略:固定其他参数,一次只调整一个参数,观察视差图的变化,理解每个参数的影响。
4.2 后处理:提升深度图质量
原始计算出的视差图往往很粗糙,我们可以使用一些后处理技术来优化它。
- 滤波 :
- 中值滤波 :非常有效,可以去除椒盐噪声,同时较好地保持边缘。
cv2.medianBlur(disparity, ksize=5)。 - 双边滤波 :能在平滑区域的同时保护边缘,但速度较慢。
cv2.bilateralFilter(disparity, d=9, sigmaColor=75, sigmaSpace=75)。
- 中值滤波 :非常有效,可以去除椒盐噪声,同时较好地保持边缘。
- 左右一致性检查 :
- 原理 :用右图作为参考,重新计算一次视差图(右视差图)。对于左视差图中的一点 p p p,其视差为 d d d,那么它在右图中的匹配点应该是 p − d p-d p−d。检查右视差图中 p − d p-d p−d 点的视差是否与 d d d 一致。如果不一致,说明该点可能是遮挡区域或错误匹配点,可以将其剔除。
- 实现 :OpenCV的SGBM支持
mode=cv2.STEREO_SGBM_MODE_HH,可以同时计算左右视差图,然后我们手动进行一致性检查。
- WLS滤波(加权最小二乘滤波) :
- 这是目前最先进的传统视差图后处理技术。它能够根据左图的边缘信息,对视差图进行边缘保持的平滑。OpenCV在
ximgproc模块中提供了实现。它能显著提升视差图的视觉效果。
- 这是目前最先进的传统视差图后处理技术。它能够根据左图的边缘信息,对视差图进行边缘保持的平滑。OpenCV在
python
# WLS滤波示例 (需要安装opencv-contrib-python)
import cv2
from cv2 import ximgproc
# ... 计算左视差图 left_disp 和右视差图 right_disp ...
# 创建WLS滤波器
wls_filter = ximgproc.createDisparityWLSFilterGeneric(False)
wls_filter.setLambda(8000) # 平滑项权重
wls_filter.setSigmaColor(1.5) # 颜色相似性权重
filtered_disp = wls_filter.filter(left_disp, img_l_rectified, None, right_disp)
# 后续处理与可视化...4.3 挑战与局限性
尽管传统双目视觉取得了很大成功,但它依然面临固有的挑战:
- 计算复杂度:高质量的全局匹配算法(如SGM)计算量巨大,难以在高分辨率下实现实时。
- 弱纹理/重复纹理:这是传统方法的天敌,在这些区域匹配几乎必然会失败。
- 遮挡:始终存在一些区域只被一个相机看到,这些区域的深度信息永远无法通过匹配恢复。
- 光照与反射:镜面反射会严重破坏亮度一致性假设。
- 基线选择:基线短,对远处物体敏感;基线长,对近处物体盲区大,且标定难度增加。
第五部分:未来展望------深度学习的革命
近年来,深度学习已经彻底改变了立体视觉领域。基于CNN的方法在精度和鲁棒性上远超传统方法。
端到端立体匹配网络(如GC-Net, PSMNet, RAFT-Stereo)直接学习从左右图像对到视差图的映射。它们能够:
- 学习强大的特征表示:CNN学到的特征比手工设计的(如Census, SAD)对光照变化和噪声更鲁棒。
- 构建4D代价体:通过内积或连接左右特征,构建一个H, W, NumDisparities, FeatureSize的4D代价体,然后使用3D卷积进行代价聚合,这比局部窗口更全局、更智能。
- 隐式学习正则化:通过网络结构隐式地学习复杂的平滑先验,而不是依赖手工制定的平滑约束。
虽然深度学习模型需要大量数据和GPU资源进行训练,但它们在推理时可以通过优化达到实时,并且在各种困难场景下表现出惊人的鲁棒性。对于追求极致性能的应用,基于深度学习的方法已是必然选择。