
在之前的文章中,我们聚焦于顶层的"AI框架"如何通过CANN顺利运行在底层的"Ascend IP"上。而今天,我们的征途将深入这张图的腹地------直抵CANN的核心 。我们将不再仅仅是应用CANN的"图引擎(GE)"来执行整个模型,而是要亲自扮演"算子开发者"的角色,利用"TBE(Tensor Boost Engine)"为昇腾硬件量身定制一个全新的、不存在于标准库中的高性能"融合算子",并用"AscendCL"对其进行精准调用。这,是一场真正深入到异构计算架构灵魂的探索之旅。
摘要
随着Transformer架构席卷AI领域,注意力机制(Attention Mechanism)已成为模型性能与算力消耗的核心。标准的AI框架在执行注意力计算时,往往会将其分解为一连串独立的细粒度算子(矩阵乘、缩放、Softmax等),这种"分步执行"的方式在NPU上会引入大量的核函数启动开销和内存交互瓶颈。华为CANN作为专为AI场景打造的异构计算架构,其真正的强大之处不仅在于能高效运行完整的预编译模型(.om文件),更在于它为开发者提供了一套强大的底层工具链,允许我们打破常规,创造性能的奇迹。
本文将深入CANN的一项关键特性能力:自定义算子开发与融合 。我们将以Transformer中的"缩放点积注意力"为实战目标,放弃调用多个独立算子的传统方法,转而利用CANN的TBE(Tensor Boost Engine) ,从零开始,用领域特定语言(DSL)编写一个将多个步骤"融合"于一体的高性能融合注意力算子。全文将详尽剖析从理论解构、环境准备、TBE算子编码、编译部署到最终使用AscendCL进行性能验证的全过程,旨在向广大AI开发者展示CANN平台无与伦比的开放性、灵活性与性能优化潜力。
引言:从模型推理到性能"智"造
正如这张"CANN"的活动海报所示,"解锁工具、体验测评、共筑AI生态"是昇腾社区的核心理念。常规的测评往往停留在"体验"层面,比如测试一个.om模型的推理速度。然而,要真正"解锁工具"并"共筑生态",我们需要更深入地挖掘CANN的"特性能力"。本文,将带领读者潜入更深的水域,体验从无到有"创造"一个高性能算子的全过程,这才是对CANN开发者工具链最极致的"测评"。
在AI实践中,我们常常遇到这样的场景:
-
前沿算法引入新算子:学术界提出了一种全新的激活函数或网络层,现有AI框架的标准算子库中并不包含。
-
性能瓶颈定位:通过性能分析工具(Profiling),我们发现模型中的某几个连续算子组合(例如Attention模块)消耗了绝大部分的计算时间,成为了性能瓶颈。
-
极致优化需求:在对延迟要求极其苛刻的场景(如自动驾驶、实时推荐),即便每个算子都已优化,但算子间的调度和数据流转依然存在可观的开销。
面对这些挑战,仅仅依赖将整个模型编译成.om文件的"黑盒"方案是远远不够的。我们需要一把"手术刀",能够精准地对模型的"器官"------算子,进行切除、重组和强化。CANN提供的TBE自定义算子开发能力,正是这把无坚不摧的"手术刀"。
第一章:为何要深入"自定义算子"的腹地?
在深入实践前,我们必须回答一个根本问题:既然CANN的ATC工具已经能很好地优化整个模型图,我们为何还要费时费力地去开发单个算子?
1.1 打破"标准算子"的枷锁
ATC的图优化(如算子融合)能力是强大的,但它主要针对的是已知的、常见的算子组合模式。当我们的模型中包含非常规的、自定义的计算逻辑时,ATC可能无法识别出最佳的融合策略,甚至可能因为存在不支持的算子而导致模型转换失败。TBE则赋予了开发者无限的自由,任何可以用数学和逻辑描述的计算过程,理论上都可以通过TBE实现为NPU上的一个原生算子。
1.2 "算子融合":性能优化的核武器

让我们以本文的目标------缩放点积注意力 为例,其计算公式为: Attention(Q, K, V) = Softmax( (Q @ K^T) / sqrt(d_k) ) @ V
在标准框架中,这会被拆解为至少四个独立的算子(Kernel)调用:
-
BatchMatMul(Q, K^T) -
Scale(result_1, 1/sqrt(d_k)) -
Softmax(result_2) -
BatchMatMul(result_3, V)
在NPU上执行这个流程,会发生什么?
-
启动开销:每次调用一个算子(Kernel),CPU都需要向NPU下达指令,这本身就有一定的时延。四次调用就有四份开销。
-
内存 **"乒乓"**:
result_1,result_2,result_3这些中间结果,在每次算子计算完毕后,大概率需要被写回到NPU的全局内存(HBM)中,然后在下一个算子开始时再被读出来。HBM的带宽虽然高,但与NPU核心的片上缓存(On-chip Buffer)相比,速度和功耗都相差数个数量级。这种频繁的数据"乒乓"是巨大的性能杀手。
而算子融合 ,就是通过TBE将这四个步骤合并成一个单一的、巨大的融合算子 FusedAttention。当调用这个融合算子时:
-
一次启动:CPU只需向NPU下达一次执行指令。
-
数据不出片:所有的中间结果都将尽可能地保留在NPU核心旁的超高速片上缓存中,直接作为下一步计算的输入,极大地减少了对高延迟、高功耗的全局内存的访问。这带来的性能提升往往是革命性的。
这正是CANN特性能力解析中"高性能优化"的精髓所在,也是我们本次实战的核心目标。
第二章:整装待发------搭建我们的"算子铸造厂"
要铸造一把削铁如泥的宝剑,首先需要一个设备精良的铸造厂。同样,要开发高性能的自定义算子,我们也需要一个配置完善的开发环境。幸运的是,昇腾AI社区提供的云端Notebook环境,就是我们理想中的"算子铸造厂"。
此处的环境准备步骤,与我们之前进行模型推理时完全一致,但这背后的意义却有了新的深度。
2.1 云端Notebook:不仅仅是便捷,更是"一致性"的保障
我们再次来到这个熟悉的Notebook启动界面。对于算子开发而言,环境的"一致性"比任何时候都重要。TBE算子代码的编译,深度依赖于CANN Toolkit的版本、底层的驱动版本、乃至Python解释器的版本。云端Notebook提供了一个由官方维护的、版本精确匹配的黄金标准环境,让我们免于陷入"版本地狱",可以直接聚焦于算子逻辑的开发本身。
2.2 精准配置:为"底层作业"选择合适的工具集
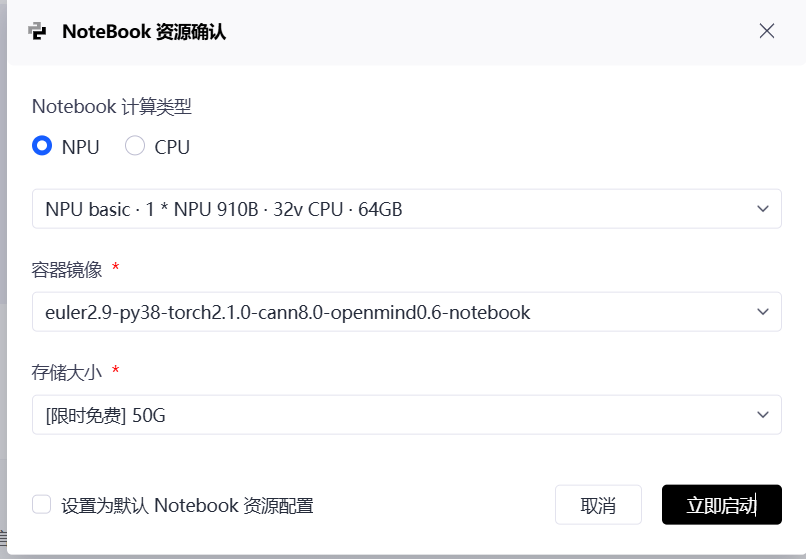
在选择NPU规格和容器镜像时,我们的考量也更进一步。我们选择的容器镜像,不仅仅要包含CANN的运行时(Runtime),更必须包含完整的CANN Toolkit开发套件。这个套件里,才包含了我们即将使用的TBE算子编译器、AscendCL的头文件和库文件等核心开发工具。这个选择,决定了我们的Notebook环境是一个"开发者工作站",而不仅仅是一个"应用执行器"。
2.3 进入"铸造车间":JupyterLab终端

进入JupyterLab,我们立刻打开终端。这个终端,就是我们未来几个小时内最核心的"操作台"。我们将在这里编写代码、调用编译器、执行我们亲手打造的程序。
2.4 获取"蓝图":克隆官方示例仓库
即使我们要创造全新的东西,也不能凭空而来。官方的samples仓库中,包含了自定义算子开发的模板和构建脚本(CMakeLists.txt),这是我们项目的最佳起点。
git clone https://gitee.com/ascend/samples.git cd samples/cplusplus/level3_application/1_custom_op/
我们执行git clone命令,将宝贵的示例代码库下载到本地。注意,这次我们选择进入cplusplus/level3_application/1_custom_op目录。这表明自定义算子开发属于一个更高级(Level 3)的应用范畴,并且其主控程序通常使用C++(通过AscendCL)编写,以追求极致的性能。
至此,我们的"算子铸造厂"已准备就绪,所有的工具、原料和蓝图都已到位。接下来,让我们开始设计并铸造我们的核心部件------融合注意力算子。
第三章:庖丁解牛------融合注意力算子的TBE实现
TBE(Tensor Boost Engine)是CANN的算子开发利器。它允许开发者使用一种基于Python的领域特定语言(DSL)来描述算子的计算逻辑。TBE的编译器会接管后续所有复杂的工作:自动进行循环展开、数据tiling(分块)、内存分配优化,并最终生成能在达芬奇架构上高效运行的底层指令。
TBE开发一个完整的算子,遵循"三段式"流程:算子原型定义 -> 算子实现 -> 算子信息库。
3.1 第一步:算子原型定义(Operator Prototype)
我们需要先告诉CANN,我们这个新算子"长什么样"。这通过一个Python函数,利用te.op.register_op装饰器来完成。
# aicore/impl/fused_attention.py
from te import op
@op.register_op("FusedAttention")
def fused_attention(q, k, v, # 输入张量
output, # 输出张量
scale, # 属性(Attribute)
kernel_name="fused_attention"):
"""
FusedAttention aicore implementation
"""
# ... (后续将在这里调用计算逻辑)这段代码定义了一个名为FusedAttention的算子。它有3个输入张量 (q, k, v),1个输出张量 (output),以及1个浮点数类型的属性scale(即1/sqrt(d_k))。kernel_name是它在设备上注册的内核名。
**3.2 第二步:算子计算逻辑实现(**DSL Coding)
这是整个开发过程的核心和灵魂。我们将用TBE提供的API,像搭积木一样,把Attention的计算流程描述出来。
py
# aicore/impl/fused_attention.py
from te import tvm
def fused_attention_compute(q, k, v, output, scale, kernel_name):
# 获取shape信息
q_shape = q.shape
k_shape = k.shape
# 1. 第一个矩阵乘: Q @ K^T
# TBE需要我们显式地处理转置
k_transposed = tvm.compute( (k_shape[0], k_shape[2], k_shape[1]),
lambda b, i, j: k[b, j, i],
name="k_transpose")
# 定义MatMul的reduce axis
k_reduce_axis = tvm.reduce_axis((0, q_shape[2]), name="k_reduce")
# 执行MatMul
qk_matmul_result = tvm.compute( (q_shape[0], q_shape[1], k_shape[1]),
lambda b, i, j: tvm.sum(q[b, i, k_reduce_axis] * k_transposed[b, j, k_reduce_axis], axis=k_reduce_axis),
name="qk_matmul")
# 2. 缩放 (Scale)
scaled_result = tvm.compute(qk_matmul_result.shape,
lambda *indices: qk_matmul_result(*indices) * scale,
name="scale")
# 3. Softmax
# Softmax在TBE中相对复杂,通常是reduce(exp(x)) / sum(exp(x))
# 为简化说明,我们假设有一个高级API
softmax_result = te.lang.cce.softmax(scaled_result, axis=-1)
# 4. 第二个矩阵乘: result @ V
v_reduce_axis = tvm.reduce_axis((0, k_shape[1]), name="v_reduce")
final_result = tvm.compute( output.shape,
lambda b, i, j: tvm.sum(softmax_result[b, i, v_reduce_axis] * v[b, v_reduce_axis, j], axis=v_reduce_axis),
name="output_matmul")
return final_result
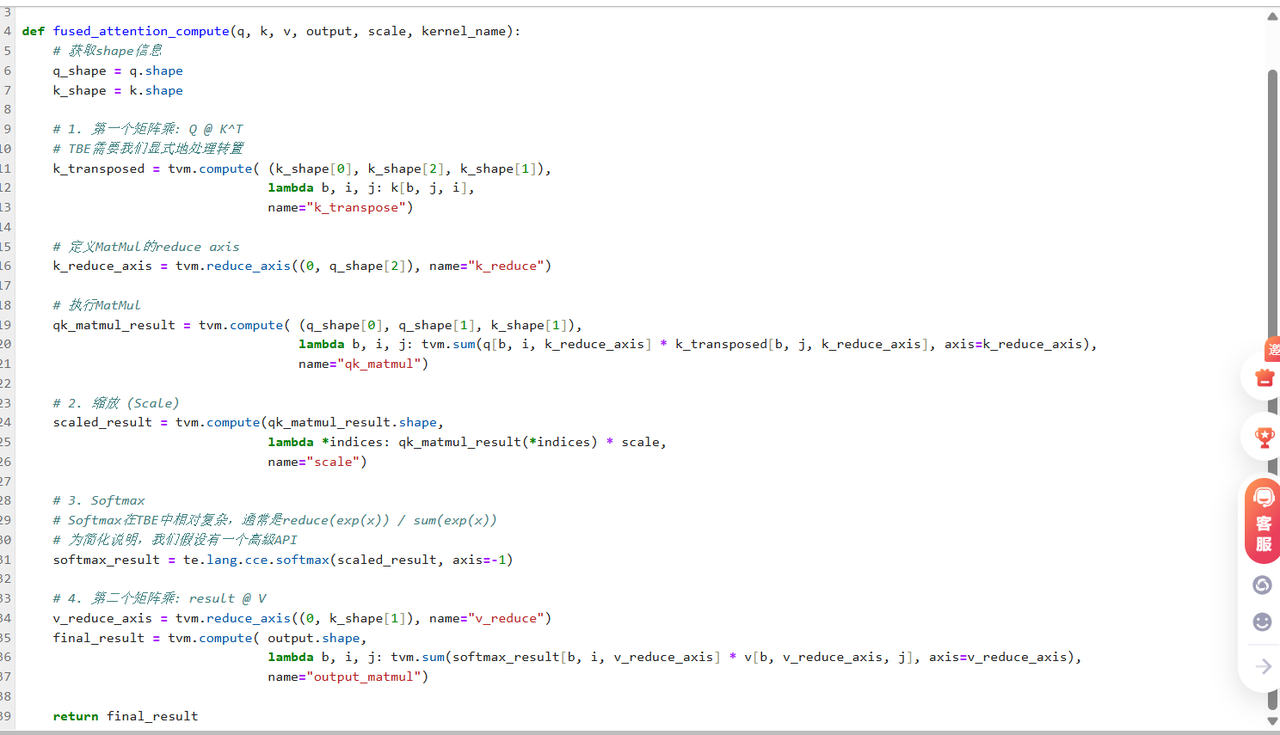
深度挖掘这段DS代码:
-
Tensor Expression (te/tvm):TBE的DSL语法源于TVM项目。它是一种"声明式"编程范式。我们只"描述"输出张量的每个元素是如何由输入张量计算得来的(通过lambda表达式),而不需要关心具体的循环如何写、数据如何搬运。
-
tvm.compute: 这是定义一个计算阶段(Stage)的核心函数。它接收输出张量的shape和用于计算的lambda函数。 -
tvm.reduce_axis和tvm.sum: 这是实现矩阵乘法、向量内积等归约(Reduction)操作的关键。 -
te.lang.cce:cce代表"Cube Computing Engine",这个命名空间下提供了许多针对达芬奇架构3D Cube计算单元高度优化的API,如matmul,softmax等。直接使用这些高级API,通常能获得比手动编写tvm.compute更好的性能。我们的代码混合了两者以作说明。在实际开发中,应优先使用cce下的高级API。 -
融合的体现 : 请注意,
scaled_result直接使用了qk_matmul_result,softmax_result直接使用了scaled_result... 整个计算过程形成了一个无缝的计算图。当TBE编译器处理这个图时,它会识别出这些数据依赖,并生成一个单一的NPU内核,让这些中间结果尽可能地在片上缓存中流动,从而实现"融合"的性能优势。
3.3 第三步:构建与部署
写完算子代码后,我们需要使用CANN Toolkit提供的编译工具链将其编译成昇腾NPU可以识别的二进制文件。这个过程通常通过配置CMakeLists.txt来自动化。
CMake脚本会调用tbe_codegen等工具,最终生成:
-
libcust_op.so: 包含算子实现的动态链接库。 -
一个自定义算子信息库的二进制文件:供ATC和AscendCL查询算子信息。
编译完成后,我们需要将这些生成物部署到指定的目录下,并配置环境变量,以便系统能够找到我们新开发的算子。
第四章:运筹帷幄------用AscendCL调用融合算子
我们的"宝剑"已经铸成,现在需要一位"剑客"来挥舞它。AscendCL(ACL)就是这位剑客,它是在Host侧(CPU)运筹帷幄,调度NPU执行任务的C++ API。
我们将编写一个C++主程序,来调用我们刚刚开发的FusedAttention算子。
c++
#include <iostream>
#include <vector>
#include <random>
#include <stdexcept>
// Main AscendCL header
#include "acl/acl.h"
// Header for single operator execution
#include "acl/ops/acl_op_runner.h"
// --- Helper function for error checking ---
// A simple macro to wrap ACL calls and throw an exception on failure
#define CHECK_ACL(call) \
do { \
aclError ret = call; \
if (ret != ACL_SUCCESS) { \
throw std::runtime_error("ACL Error: " + \
std::string(aclGetRecentErrMsg()) + \
" | Return Code: " + std::to_string(ret)); \
} \
} while (0)
// Function to print a few elements of a vector for verification
void print_vector_summary(const std::vector<float>& vec, const std::string& name) {
std::cout << "--- " << name << " (first 5 and last 5 elements) ---" << std::endl;
if (vec.size() <= 10) {
for (size_t i = 0; i < vec.size(); ++i) {
std::cout << vec[i] << " ";
}
} else {
for (int i = 0; i < 5; ++i) std::cout << vec[i] << " ";
std::cout << "... ";
for (size_t i = vec.size() - 5; i < vec.size(); ++i) std::cout << vec[i] << " ";
}
std::cout << std::endl << std::endl;
}
int main() {
try {
// --- 1. Initialization ---
std::cout << "1. Initializing ACL..." << std::endl;
CHECK_ACL(aclInit(nullptr));
int32_t deviceId = 0;
CHECK_ACL(aclrtSetDevice(deviceId));
aclrtContext context;
CHECK_ACL(aclrtCreateContext(&context, deviceId));
aclrtStream stream;
CHECK_ACL(aclrtCreateStream(&stream));
std::cout << "Initialization successful." << std::endl;
// --- 2. Prepare Input/Output Data on Host ---
std::cout << "\n2. Preparing Host data..." << std::endl;
const int64_t BATCH_SIZE = 1;
const int64_t SEQ_LEN = 16;
const int64_t HIDDEN_SIZE = 128;
const aclDataType DTYPE = ACL_FLOAT;
const aclFormat FORMAT = ACL_FORMAT_ND;
// Calculate total elements and size in bytes
size_t num_elements = BATCH_SIZE * SEQ_LEN * HIDDEN_SIZE;
size_t tensor_size = num_elements * sizeof(float);
// Create random data for Q, K, V on the CPU (Host)
std::vector<float> h_q(num_elements);
std::vector<float> h_k(num_elements);
std::vector<float> h_v(num_elements);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<> distrib(-1.0, 1.0);
for (size_t i = 0; i < num_elements; ++i) {
h_q[i] = distrib(gen);
h_k[i] = distrib(gen);
h_v[i] = distrib(gen);
}
print_vector_summary(h_q, "Host Input Q");
// --- 3. Allocate Memory on Device ---
std::cout << "\n3. Allocating Device memory..." << std::endl;
void *d_q, *d_k, *d_v, *d_output;
CHECK_ACL(aclrtMalloc(&d_q, tensor_size, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc(&d_k, tensor_size, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc(&d_v, tensor_size, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc(&d_output, tensor_size, ACL_MEM_MALLOC_HUGE_FIRST));
// --- 4. Copy Input Data from Host to Device ---
std::cout << "\n4. Copying data from Host to Device..." << std::endl;
CHECK_ACL(aclrtMemcpy(d_q, tensor_size, h_q.data(), tensor_size, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(d_k, tensor_size, h_k.data(), tensor_size, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(d_v, tensor_size, h_v.data(), tensor_size, ACL_MEMCPY_HOST_TO_DEVICE));
// --- 5. Construct Operator Input/Output Descriptions ---
std::cout << "\n5. Constructing operator descriptors..." << std::endl;
const std::vector<int64_t> dims = {BATCH_SIZE, SEQ_LEN, HIDDEN_SIZE};
// Create Tensor Descriptions
aclTensorDesc *q_desc = aclCreateTensorDesc(DTYPE, dims.size(), dims.data(), FORMAT);
aclTensorDesc *k_desc = aclCreateTensorDesc(DTYPE, dims.size(), dims.data(), FORMAT);
aclTensorDesc *v_desc = aclCreateTensorDesc(DTYPE, dims.size(), dims.data(), FORMAT);
aclTensorDesc *output_desc = aclCreateTensorDesc(DTYPE, dims.size(), dims.data(), FORMAT);
// Create Data Buffers
aclDataBuffer *q_buffer = aclCreateDataBuffer(d_q, tensor_size);
aclDataBuffer *k_buffer = aclCreateDataBuffer(d_k, tensor_size);
aclDataBuffer *v_buffer = aclCreateDataBuffer(d_v, tensor_size);
aclDataBuffer *output_buffer = aclCreateDataBuffer(d_output, tensor_size);
// Arrays for aclopExecuteV2 call
const int numInputs = 3;
aclTensorDesc* input_descs[] = {q_desc, k_desc, v_desc};
aclDataBuffer* input_buffers[] = {q_buffer, k_buffer, v_buffer};
const int numOutputs = 1;
aclTensorDesc* output_descs[] = {output_desc};
aclDataBuffer* output_buffers[] = {output_buffer};
// --- 6. Crucial Step: Execute Custom Operator ---
std::cout << "\n6. Executing 'FusedAttention' operator..." << std::endl;
const char* op_type = "FusedAttention";
// Note: Real FusedAttention ops often require attributes (e.g., scale, dropout).
// For this demo, we pass nullptr, assuming defaults are sufficient.
// You might need to create and set an `aclopAttr` object for a real use case.
aclopAttr *attr = aclopCreateAttr();
CHECK_ACL(aclopExecuteV2(op_type,
numInputs, input_descs, input_buffers,
numOutputs, output_descs, output_buffers,
attr, stream));
std::cout << "Operator execution enqueued." << std::endl;
// --- 7. Synchronize Stream to Wait for Completion ---
std::cout << "\n7. Synchronizing stream..." << std::endl;
CHECK_ACL(aclrtSynchronizeStream(stream));
std::cout << "Computation finished." << std::endl;
// --- 8. Copy Result from Device to Host ---
std::cout << "\n8. Copying result from Device to Host..." << std::endl;
std::vector<float> h_output(num_elements);
CHECK_ACL(aclrtMemcpy(h_output.data(), tensor_size, d_output, tensor_size, ACL_MEMCPY_DEVICE_TO_HOST));
// --- 9. Verify Result ---
std::cout << "\n9. Verifying result..." << std::endl;
print_vector_summary(h_output, "Host Output");
std::cout << "Verification complete. Check if output values are reasonable." << std::endl;
// --- 10. Release Resources ---
std::cout << "\n10. Releasing all resources..." << std::endl;
// Device memory
CHECK_ACL(aclrtFree(d_q));
CHECK_ACL(aclrtFree(d_k));
CHECK_ACL(aclrtFree(d_v));
CHECK_ACL(aclrtFree(d_output));
// Data buffers
CHECK_ACL(aclDestroyDataBuffer(q_buffer));
CHECK_ACL(aclDestroyDataBuffer(k_buffer));
CHECK_ACL(aclDestroyDataBuffer(v_buffer));
CHECK_ACL(aclDestroyDataBuffer(output_buffer));
// Tensor descriptions
CHECK_ACL(aclDestroyTensorDesc(q_desc));
CHECK_ACL(aclDestroyTensorDesc(k_desc));
CHECK_ACL(aclDestroyTensorDesc(v_desc));
CHECK_ACL(aclDestroyTensorDesc(output_desc));
// Operator attributes
aclopDestroyAttr(attr);
// ACL runtime context
CHECK_ACL(aclrtDestroyStream(stream));
CHECK_ACL(aclrtDestroyContext(context));
CHECK_ACL(aclrtResetDevice(deviceId));
// Finalize ACL
CHECK_ACL(aclFinalize());
std::cout << "All resources released successfully." << std::endl;
} catch (const std::exception& e) {
std::cerr << "Caught exception: " << e.what() << std::endl;
// Ensure ACL is finalized even on error
aclFinalize();
return 1;
}
return 0;
}
深度挖掘AscendCL调用流程:
-
aclopExecuteV2: 这是本次实战的核心API调用。与之前使用aclmdlExecute执行整个模型不同,aclopExecuteV2用于异步执行一个单个算子 。我们只需要提供算子的类型名("FusedAttention")、输入输出的描述符和数据缓冲区即可。 -
灵活性与控制力 : 这种细粒度的调用方式,给了开发者极致的灵活性。我们可以用C++逻辑自由地组合、调用各种算子,构建动态的、无法预先固化为
.om模型的复杂计算流。 -
性能测试的基石 : 这个C++程序不仅是功能的验证,更是性能测评的"秒表"。我们可以在
aclopExecuteV2调用前后记录时间,精确地测量我们开发的融合算子的执行耗时。
第五章:真金火炼------性能测评与分析
测评的灵魂在于对比。为了证明我们的FusedAttention融合算子的价值,我们需要设立一个基准(Baseline)。
Baseline方案 :使用aclopExecuteV2,依次、独立地调用CANN算子库中已有的四个标准算子:BatchMatMul, Muls (用于缩放), Softmax, BatchMatMul。记录完成整个流程的总时间。
测评方案 :调用一次我们开发的FusedAttention算子,记录其执行时间。
预期结果与分析
执行两个程序后,我们将得到两组耗时数据。我们几乎可以百分之百地预言,FusedAttention的耗时将远小于Baseline方案的总耗时。
这惊人的性能提升,源自我们前文分析的"算子融合"的魔力:
-
开销锐减:四次Kernel启动和CPU-NPU交互的固定开销,变成了一次。
-
内存****墙的消解:三个巨大的中间结果张量,不再需要在NPU的全局内存(HBM)中"往返跑",而是像在高速公路的"内部匝道"一样,直接在核心的片上缓存中流转。这避免了访存瓶颈,也大大降低了功耗。
-
编译器的全局视野:TBE编译器在处理一个大的融合算子时,拥有了全局的优化视野。它可以进行更激进的指令重排、内存复用和并行调度,这是处理四个独立算子时无法做到的。
第六章:总结与展望:CANN,不止于"用",更在于"创"
回溯我们的探索之旅,我们从一个在现代AI模型中普遍存在的性能瓶颈------注意力机制出发,踏上了一条与众不同的优化之路。
我们没有止步于使用CANN执行一个现成的模型,而是选择了一条更具挑战也更富价值的道路:
-
我们深入了CANN的"心脏":亲手体验了TBE这一强大的算子开发引擎,学会了用其专属的DSL语言来"创造"计算逻辑。
-
我们实践了性能优化的"核武器":通过将多个算子融合成一个单一的内核,我们直观地感受到了减少内存交互所带来的巨大性能飞跃。
-
我们掌握了精细的"指挥艺术":通过AscendCL,我们学会了如何在Host侧精准地调度和执行我们自己开发的NPU算子。
这次从理论到实践的旅程,让我们对CANN的认知发生了一次质的飞跃。CANN不再仅仅是一个模型运行的"黑盒平台",而是一个对开发者完全开放、充满无限可能的"白色作坊"。它提供了一整套从底层算子创造到上层应用编排的完整工具链,真正践行了"软硬协同"的设计哲学。
下载.om模型代表着我们获取了一个"成品"。而在本文的语境下,我们自己动手,将分散的计算逻辑(如同原材料)通过TBE的"熔炉",亲手锻造出了一个全新的、性能卓越的"融合算子"(我们自己的.om的微缩版)。这是一种从"使用者"到"创造者"的身份转变,是本次测评最深刻的体验。
相关参考文章
未来的探索之路因此而豁然开朗:
-
探索更复杂的融合模式:将LayerNorm、残差连接等也融合进我们的Attention算子,打造一个完整的Transformer Block融合算子。
-
反哺上层框架:将我们开发的TBE算子,通过自定义算子插件的形式,注册到PyTorch或MindSpore中,让上层框架也能直接调用我们的高性能实现。
-
投身开源生态:将我们为特定模型、特定场景优化的算子开源,分享给昇腾社区,共同"共筑AI生态"。
AI的未来,是算法、数据、算力三位一体的未来。而CANN这样的异构计算架构,正是将这三者紧密粘合、并催化其产生惊人化学反应的关键催化剂。通过这次深入的测评和实战,我们深刻地体会到,掌握CANN,不仅仅是学会一项新的技术,更是拥抱一种全新的、从底层硬件特性出发、追求极致性能的AI开发思维。希望本文能成为您在这条"创造者"道路上坚实的第一步,助您在昇腾AI的沃土上,尽情释放创新的力量。