1.TorchRL入门1
python
'''
没有数据就没有学习。在监督学习中,用户习惯于使用数据加载 DataLoader 等工具将数据集成到训练循环中。数据加载器是可迭代对象,它提供用于训练模型的数据。
TorchRL 处理数据加载的方式与此类似,尽管它在强化学习库生态系统中显得独树一帜。TorchRL 的数据加载器被称为 DataCollectors 。大多数情况下,数据收集并不止于原始数据的收集,因为数据在被损失模块使用之前,需要临时存储在缓冲区(或策略内算法的等效结构)中。本教程将探讨这两个类。
'''
#Data Collectors
'''
这里讨论的主要数据收集器是 本文档重点介绍 SyncDataCollector 。从根本上讲,收集器是一个简单的类,负责在环境中执行策略、在必要时重置环境,并提供预定义大小的批次数据。与 env 教程中演示的 rollout() 方法不同,收集器不会在连续的数据批次之间重置。因此,两个连续的数据批次可能包含来自同一轨迹的元素。
传递给收集器的基本参数包括:要收集的批次大小( frames_per_batch )、迭代器的长度(可能为无限长)、策略和环境。为简单起见,本例中我们将使用虚拟的随机策略。
'''
import torch
from torchrl.envs import GymEnv
from torchrl.envs.utils import RandomPolicy
from torchrl.collectors import SyncDataCollector
torch.manual_seed(0)
env = GymEnv("CartPole-v1")
env.set_seed(0)
policy = RandomPolicy(env.action_spec)
collector = SyncDataCollector(
env,
policy,
frames_per_batch=200,
total_frames=-1 # 无限迭代
)
# Note: 在实际使用中,您可能希望设置 total_frames 以限制收集的总帧数。并且两个连续的批次可能包含来自同一轨迹的元素,不会重置环境。
# 了解数据样子
for data in collector:
print(data)
break
print(data["collector", "traj_ids"])
'''
for data in collector: 会从 SyncDataCollector 迭代得到一个 batch(一个 TensorDict),每次 batch 大小约为 frames_per_batch(此处 200);break 会只取第一个 batch 并退出循环。
print(data) 会显示该 batch 中包含的键(如 observation、action、reward、done 等)及每个张量的 shape。
data["collector", "traj_ids"] 是每个帧对应的轨迹 ID(trajectory id),用来标识哪些帧属于同一条 episode。因为 collector 不在 batch 间强制重置,batch 内可能包含来自多条或同一条轨迹的连续片段,所以 traj_ids 可以用来按轨迹分割或统计完整 episode。
TensorDict(
fields={
action: Tensor(shape=torch.Size([200, 2]), device=cpu, dtype=torch.int64, is_shared=False),
collector: TensorDict(
fields={
traj_ids: Tensor(shape=torch.Size([200]), device=cpu, dtype=torch.int64, is_shared=
batch_size=torch.Size([200]),
device=None,
is_shared=False),
done: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=Fa,
observation: Tensor(shape=torch.Size([200, 4]), device=cpu, dtype=torch.float32, isred=False),
reward: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.float32, is_sharalse),
done: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=Fa,
observation: Tensor(shape=torch.Size([200, 4]), device=cpu, dtype=torch.float32, isred=False),
reward: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.float32, is_sharalse),
done: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=Fa,
observation: Tensor(shape=torch.Size([200, 4]), device=cpu, dtype=torch.float32, isred=False),
reward: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.float32, is_sharalse), vice=None,
reward: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.float32, is_sharalse), ation: Tensor(shape=torch.Size([200, 4]), device=cpu, dtype=torch.float32, is_shared= terminated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shaFalse), ated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=Fals
truncated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shar terminated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shaFal
se),
truncated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_sharals is_shared=False),
terminated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shaF batch_size=torch.Size([200]),
alse),
truncated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shara observation: Tensor(shape=torch.Size([200, 4]), device=cpu, dtype=torch.float32, is_shared= truncated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=se),
False)},
batch_size=torch.Size([200]),
truncated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared is_shared=False),
=False)}, =
batch_size=torch.Size([200]), =
truncated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shar is_shared=False), s
ed=False)}, e
batch_size=torch.Size([200]),
truncated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([200]),
device=None,
is_shared=False),
observation: Tensor(shape=torch.Size([200, 4]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([200, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([200]),
device=None,
is_shared=False)
tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 9, 9,
9, 9, 9, 9, 9, 9, 9, 9])
'''
# Replay Buffers 回放缓冲区
'''
DataCollector 提供的数据批次可以直接传递给损失模块进行训练。通常,用户会将收集器与缓冲区结合使用,以便在使用离线数据进行训练之前存储数据。
下面的示例展示了如何将 SyncDataCollector 与 ReplayBuffer 结合使用,以实现基本的离线数据存储和采样。
for data in collector:
storage.store(data)
for i in range(n_optim):
sample = storage.sample()
loss_val = loss_fn(sample)
loss_val.backward()
optim.step()
'''
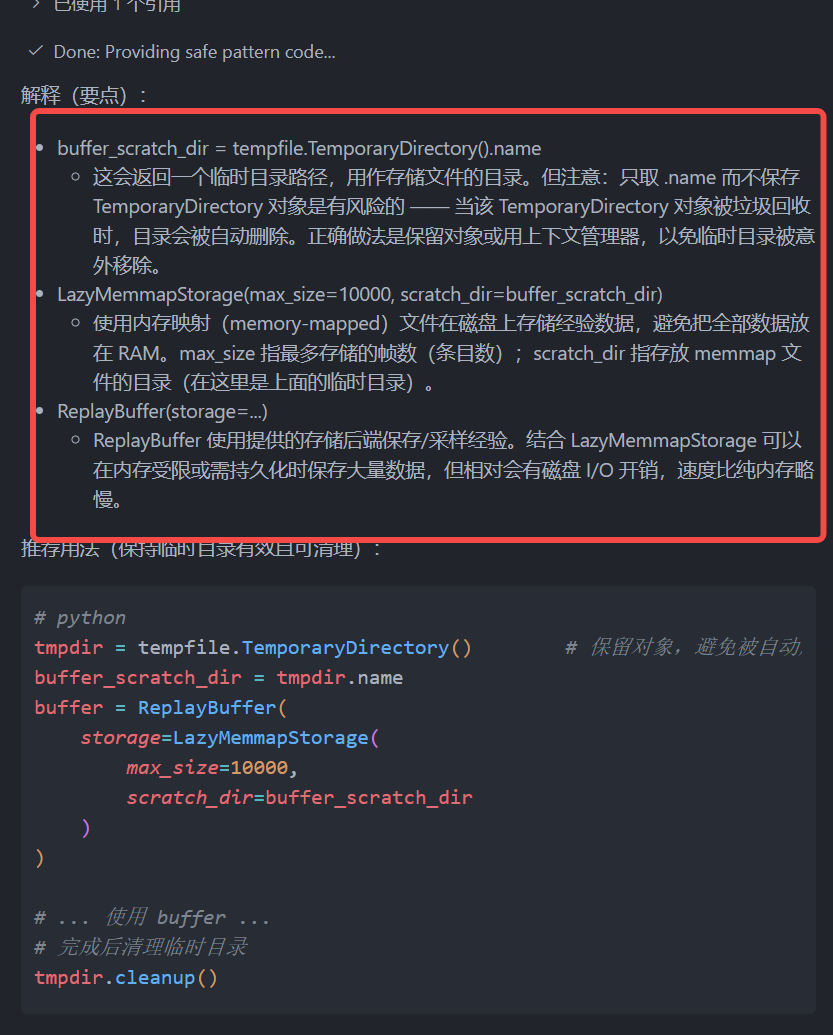
from torchrl.data.replay_buffers import LazyMemmapStorage, ReplayBuffer
import tempfile
buffer_scratch_dir = tempfile.TemporaryDirectory().name
buffer = ReplayBuffer(
storage=LazyMemmapStorage(
max_size=10000,
scratch_dir=buffer_scratch_dir
)
)
indices = buffer.extend(data)
assert len(buffer) == collector.frames_per_batch
print(indices)
# 剩下的唯一问题是如何从缓冲区中收集数据。当然,这要用到 sample() 方法。因为我们没有明确规定采样必须在不使用......的情况下进行。 重复实验并不能保证从我们的缓冲液中采集的样本的准确性,将是独一无二的(会被重复采样)
sample = buffer.sample(batch_size=30)
print(sample)Get started with data collection and storage
开始进行数据收集和存储

TorchRL中构造了和Dataloader类似的加载器;
Data collectors 数据收集器
需要注意:
每个batch并不会重新reset环境开始收集,也就是和之前的rollout不一样;

Replay Buffers 回放缓冲区
这对于off-policy很重要,就是利用buffer去采样训练的数据;
然后,buffer的更新规则,先入先出等;

buffer类有参数可以选;
然后就是往buffer添加data,检查buffer长度,
从buffer中采样;

总结
这一节的教程还是比较简单的,主要介绍了数据收集器和buffer;
两者关系是collertor收集的数据存在buffer中,用来训练。
如果是on-policy也就没有buffer了,是否还需要collector
不是必要的,但是可以利用collector去收集,然后反复更新网络


为什么可以反复用:

如果collector收集数据,即使是跨episode的可以用来更新?
因为策略并没有改变?
