| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文名称 | Helix-From Figure AI |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | OpenHelix-Team/OpenHelix: OpenHelix: An Open-source Dual-System VLA Model for Robotic Manipulation |
| 4 | 创新点 | Helix 是首个使用 单一模型权重(S2(7B)+ S1(80M)一套权重搞定所有任务),无需特定任务微调 ,直接从 自然语言控制(直接输出用于高维动作空间的连续控制,不需要离散化指令) humanoid 全上半身 的 VLA 系统,而且可以多个机器之间相互写作,采用用同一套参数,能够实现高频、高维、多任务泛化、零样本物体抓取以及多机器人协作,同时训练数据需求远低于传统方法。训练时加入 S1 与 S2 输入之间的时间偏移,使训练与部署匹配。 |
| 5 | 引用量 | 感觉很好,看视频感觉效果很好,很期待VLA得继续发展。 |

一:提出问题
关于Helix的一篇技术博客。Helix是一个双系统的通用的VLA模型,克服了机器人的很多长期面临的挑战,在多个方面,helix都带来了让我眼前一亮的效果。
-
**Full-upper-body control:**全上半身控制,是第一个能够完全控制且高速的VLA模型,包括手腕,躯干,头部,每根手指。
-
Multi-robot collaboration: Helix 是第一个能够同时控制两台机器人工作的 VLA ,让它们一起完成一个共享的、长时间序列的操作任务,并且这些任务中的物体还是它们从未见过的。
-
Pick up anything: 装备了Helix的人形机器人可以根据语言提示捡起来任何小的家庭物品。
-
One neural network: Helix 使用同一套神经网络权重来学习所有行为,也就是说所有的能力都来自于同一个模型和同一套权重下,无需针对特定任务微调。
-
**Commercial-ready:**第一个能够完全部署在低功耗的GPU上运行的VLA,为商业部署做好了准备。
New Scaling for Humanoid Robotics:人形机器人的新规模化
家庭环境对机器人来说是最大的一个挑战,和实验室或者工业环境不同,家庭环境物体多样,变化大,位置情况多,而且每个物体的形状、颜色、尺寸等都不可预测。为了让机器人在家庭背景下能够有用,它们必须能够实现按需生成智能的新动作的能力,尤其是面对从未见过的物体的时候。目前的机器人技术不做一个根本性的改进的话,是无法扩展到家庭环境的。当前,即便教机器人一个新行为,也需要大量人力,要么是几小时的博士级专家手工编程、要么是成千上万次示范。而针对家庭环境问题的广度,这两种解决方案的成本都显得过高了。但是在AI的其他领域,已经掌握了这种即时泛化的能力,例如在NLP、视觉领域的大模型可以实现zero-shot / few-shot 推理。
那么,如果把VLM捕获的丰富语义知识,直接转化为机器人动作,会怎么样?--VLA
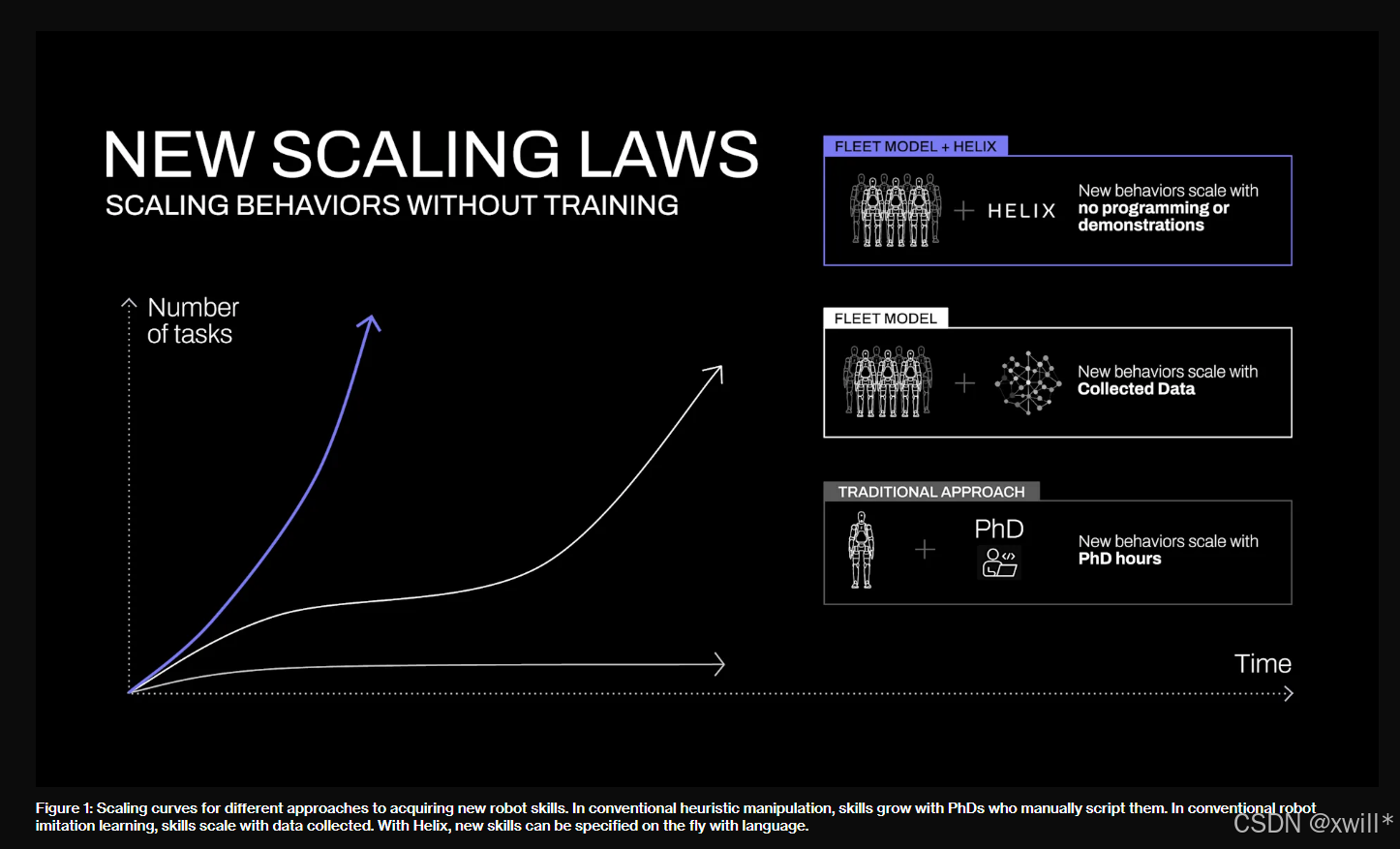
如图一所示,这种能力将从根本上改变机器人技术的扩展路径,原本需要数百次示范才能学会的新技能,现在只需用自然语言告诉机器人,就能立即掌握,充分展现了零样本和语言驱动动作生成的能力。所以,如何从 VLM 中提取常识知识 并将其转化为可泛化的机器人控制?成为目前的关键问题。因此,helix的出现也是针对这个问题做了一个解决。
-
Helix = VLM 与机器人控制的桥梁
-
可以把语言、视觉、常识 → 转化为实际操作动作
二:解决方案
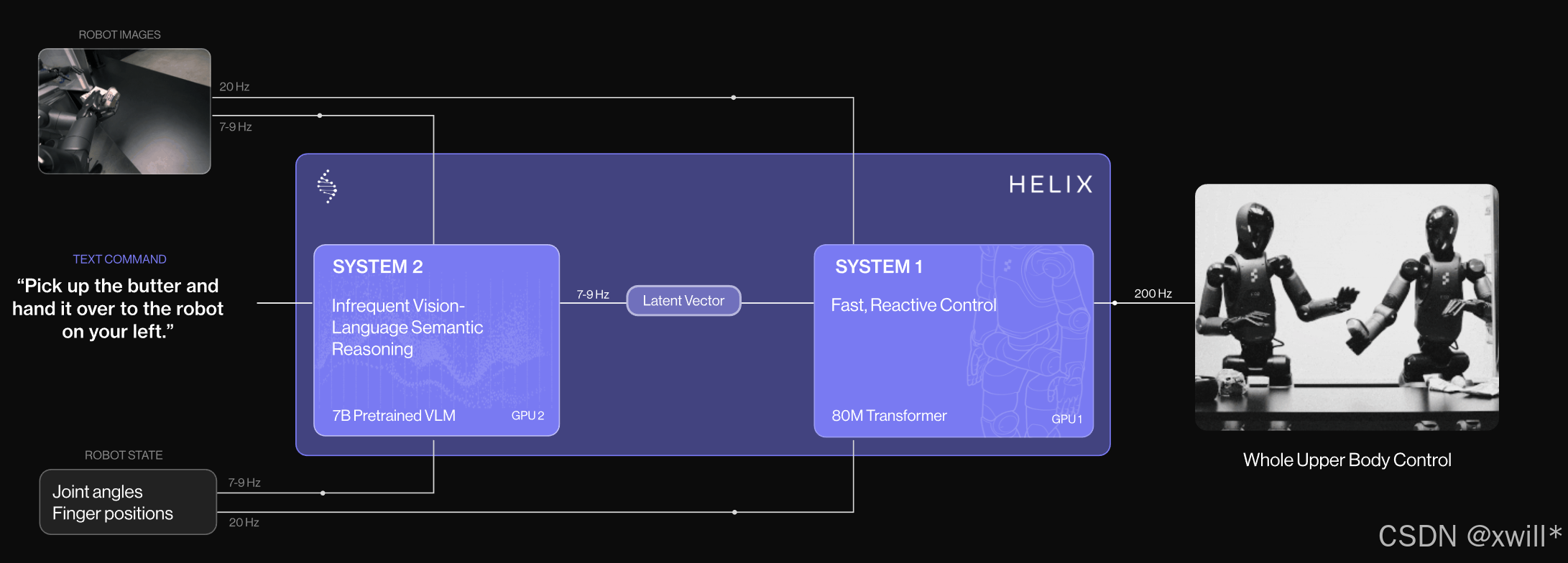
Helix就是一种用于完整上半身控制的 "系统1--系统2" VLA(视觉--语言--动作)模型,首个结合 "系统1--系统2" 架构的 VLA 模型,能够以高频率实现对整个人形机器人上半身的灵巧操作控制。
在过去,双系统的方案 一直有个根本的问题,就是VLM 模型泛化能力强,但速度慢;机器人视觉--运动策略速度快,但泛化性差。而Helix通过两个互补的系统来解决这一矛盾,这两个系统都是端到端训练,并且能够实现彼此之间的通讯。
其中,System 2(S2),是一个基于互联网预训练的 VLM,每秒 7--9 次运行,用于场景理解和语言理解,为各种对象和上下文提供广泛泛化能力。
System 1 (S1),是一个高速的反应式视觉---运动策略,将 S2 产生的语义潜表示转换为精确的连续机器人动作,以 200Hz 的速度运行。
这种解耦架构让每个系统都能在最适合自己的时间尺度工作 。S2 可对高层目标进行 "慢思考",而 S1 则能对动作实时地 "快反应" 和调整。例如,在多机器人协作任务中(视频 2),S1 会快速适应另一台机器人的运动变化,同时保持 S2 设定的语义目标不变。

Helix 的亮点是把一个慢但聪明的大模型(S2)和一个快但精确的小控制器(S1)结合,通过端到端训练实现"会思考也会实时执行"的机器人控制系统,率先解决了泛化能力与控制速度的矛盾。
与其他方法相比,Helix的设计有几个关键的优势:
-
速度与泛化能力
Helix 的执行速度可以匹配专门为单一任务训练的行为克隆策略,同时还能对数千个全新的测试对象实现零样本泛化。也就是说Helix 的S1非常快,和传统的转为一个任务训练的BC策略一样的快,同时因为S2能够进行目标推理,系统整体又可以对新物体不经训练直接做动作。
-
可扩展性
Helix 可以直接输出用于高维动作空间的连续控制 ,避免了先前许多 VLA 方法所依赖的复杂动作 tokenization(动作离散化)方案。这些 token 化方法在低维控制场景(例如二值化的平行夹爪 gripper)中还算有效,但在高维的人形机器人控制上会出现严重的扩展性问题。
现代 VLA(如 RT-2、OpenVLA)通常用 token 来表示动作 例如:"MOVE_LEFT_1""MOVE_LEFT_2""OPEN_GRIPPER"等,其本质是把动作离散化,像语言一样处理。但对于"高维连续机器人"(尤其 humanoid)来说,关节太多,而且每个关节都是浮点角度,如果还是离散化表示,会导致token 爆炸,不可扩展。所以Helix 避免这个问题,S1 直接输出连续控制向量。
输出类似于这样:
md-end-block[0.34, -1.22, 0.05, 1.18, ...] # 每个值控制一个关节,机器人关节控制指令 -
架构简单性
Helix 采用标准架构,System 2 使用一个开源、开权重的 VLM;System 1 则是一个基于 transformer 的简洁视觉-运动策略。
Helix 不是一个巨大的 end-to-end 大模型 。System 2 是一个常规 VLM(类似 LLaVA、Phi-3-Vision、Qwen-VL) 用来做推理、理解任务目标、物体关系等。System 1 是一个单纯的 transformer 控制器。输入视觉特征、状态,输出,连续动作。整个体系比 VLA-Transformer 小得多,大模型计算不介入实时控制,因此速度很快。
transformer 控制器: 一个小型 Transformer(几百万参数级别),输入视觉和状态,输出动作
不是一个巨大的 end-to-end 大模型(但是训练的时候是端到端的):也就是不像是RT-2、OpenVLA :图像 → 文本/token → 大模型(几十B) → 动作 token
-
模块分离
将 S1 和 S2 分离,使我们能独立地迭代和改进每个系统,而不必受限于寻找统一的观测空间或动作表示方式的需求。
S2(大模型)负责推理 , S1(小模型)负责控制,二者独立训练、独立优化、互不影响。这样可以不需要把图像、文本、动作揉成同一个 token 空间,S1 可以小而快,S2 可以升级不同的 VLM,不影响控制器,训练数据完全不同。
2:Model and Training Details
数据方面: 收集了一个高质量的、多机器人、多操作者数据集,包含大约 500 小时的操作演示。为了生成"自然语言指令---动作"的训练数据,他们用一个自动标注 VLM 来产生"回溯指令。VLM 会读取机器人相机的这一段视频,并回答:"为了让机器人做出视频中那段动作,你会给它什么指令?"同时,为避免测试污染,训练中用过的物体全部从测试集中排除。
模型结构 Architecture :S2 是一个 7B 参数的开源 VLM,在互联网规模数据上预训练。它处理单目相机图像和机器人状态(手腕姿态、手指位置),并把它们映射到视觉--语言嵌入空间。再加上自然语言指令,S2 将所有与任务相关的语义信息压缩成一个 连续 latent 向量,送入 S1。
S2 的功能类似于:
理解这是什么物体?
任务目标是什么?
当前状态与目标有什么关系?
最终把这些高层语义封装成一个向量:
md-end-blocklatent_S2 = f(image, robot_state, text)latent 向量 可以理解成,S2(大模型)想要告诉 S1(控制器)的所有高层语义信息,被压缩成的一段连续数字向量。本质就是一个浮点数列表。其中的数字不是token,不是离散指令,而是"当前场景理解"、"任务目标"等等得浓缩表达。由于是连续值,而且位于一个连续空间,并且能够表示语义,能够明显区别于离散得动作token.
S1 是一个 80M 参数的 cross-attention encoder-decoder Transformer,用于低层控制。它的视觉 backbone 是全卷积、多尺度结构,并来自纯模拟预训练。S1 也接收图像和状态,但处理得更快(用于反应式控制)。S2 的 latent 向量会被投影到 S1 的 token 空间,并和视觉 token 拼在一起作为"任务条件"。S1 输出上半身控制信号(200 Hz),包括手腕姿态、手指弯曲/张开、头部/躯干方向。此外还输出一个"任务完成百分比",帮助学习行为的终止判断。
S1 的 transformer 不是语言模型,它是一种 时序控制 transformer。latent 向量的作用类似,
md-end-block"我要做什么任务"的目标 token而视觉 token 是:
md-end-block"当前环境长什么样"Transformer cross-attention 结合两者 => 输出动作。
Helix 是真正的 端到端训练 ,虽然结构是 S1 + S2,但训练时输入图像 + 状态 + 文本,输出连续动作,损失采用回归损失(模仿控制),梯度从 S1 反传到 S2。不需要任何任务微调,不需要 task-specific head。训练时加入 S1 与 S2 输入之间的时间偏移,使训练与部署匹配。
时间偏移:由于s2和s1得频率不同,导致推理时,S1 使用的图像是"最新的",而 S2 的 latent 可能是 几十毫秒前生成的。这也会导致如果训练时 S1 和 S2 输入严格对齐(t 时刻相同),但推理时 S2 的信息落后几十毫秒,致使训练---推理分布差异,控制稳定性下将。时间偏移也就是在训练得时候故意给 S2 的输入延迟几十毫秒(和实际推理一致)。
也就是说人为地把 S1 的监督信号向后偏移 Δ 时间,使得:
S1 在时间 t 学的是:S2 在未来 t+Δ 时刻 所希望机器人做的动作。S1 每一帧都在学 "未来一段时间的动作轨迹"。
S2 的 latent 代表的是"未来几秒的动作意图",它本身就是平滑、连续、宏观的。如果你不加偏移,S1 只能学"这一秒 S2 想干嘛",动作不连续,不成轨迹。而加了偏移,S1 学的是未来段的动作,必然是平滑的、连续的、轨迹型的。就像:
S2:我接下来 1 秒后,要把手伸过去抓这个东西 S1:好,我从现在起就按照"手伸过去"的轨迹执行,每 5ms 计算一次更细动作
在推理的时候,S2 不是实时运行的,所以"频率对不上"的问题根本不存在。推理时候只需要S2给出一个高层编码,然后S1完全独立执行,预测下一步动作。
3:推理 Optimized Streaming Inference
推理时,模型被拆成两个进程,S2采用慢速,异步后台进程,输入最新观测 + 指令,并且以7--9 Hz 更新 latent(语义目标)。而S1执行高速实时进程,以200Hz 接收最新图像 + 最新 latent,并且进行闭环控制。异步结构让两者在各自速度下运行,减少了训练和推理之间得分布差异,并且和训练时的 temporal offset 完全匹配,实现速度甚至可以达到纯 imitation policy 的水平。
三:实验
Helix 以 200Hz 的频率控制一个 35 自由度(DoF)的上半身动作空间,包括从单个手指动作、末端执行器轨迹、头部注视方向到躯干姿态等所有内容。头和躯干的控制尤其困难------因为它们移动时会改变机器人能触达的位置以及它能看到的内容,形成反馈回路,这些反馈回路在历史上常导致不稳定。

上边视频 演示了这种协调能力:机器人平滑地用头部追踪自己的手,同时调整躯干以获得最佳的操作范围,同时保持精确的手指控制来抓取物体。在以前得工作中,这种精度 + 高维动作空间的实时协调被认为极具挑战,即便是在单一已知任务里都很难做到。据我们所知,之前没有任何 VLA 系统能在保持任务泛化能力的情况下,实现如此程度的实时协调。
3.1 Zero-shot 多机器人协作
我们在困难的多智能体操作场景中测试 Helix:两个 Figure 机器人进行零样本协作式收纳杂货。
第一个视频(文章开头)展示了两大突破,机器人能够操控完全新物品(训练中未见过的),覆盖形状、大小、材质的多样性 → 泛化性很强。两个机器人使用 同一套 Helix 参数(也就是说部署的模型是相同的)
-
不需要特定机器人训练
-
不需要任务角色分配
-
不需要专门的协作规划
它们仅靠自然语言提示协调:"把饼干袋递给你的右侧机器人","从左侧机器人接过饼干袋并放到抽屉里"这是首次展示使用 VLA 模型,实现灵活、持续的多机器人协作,并且还能在完全新物体上保持性能。

3.2 Emergent "Pick up anything"
我们发现安装 Helix 的 Figure 机器人,在听到"Pick up the X"时,几乎能拾取任何小型家居物品。系统测试中,它能成功处理数千种新物体,从玻璃杯、玩具到工具和衣物,且不需要额外演示或定制编程。更令人注意的是 Helix 如何把互联网级语言理解与精确机器人控制结合。例如听到 "Pick up the desert item":
-
它能理解"沙漠 item"是"仙人掌玩具"
-
判断哪个手更近
-
执行精确的抓取动作
这种通用的"从语言到动作"的抓取能力,为在非结构化环境中的人形机器人部署打开新可能。

四:总结
Discussion :
Helix 的训练效率
Helix 的训练非常高效,能在极少的资源下实现强大的物体泛化能力。总共使用约 500 小时高质量监督数据 来训练 Helix,这只占以往 VLA 数据集规模的不到 5%,并且 无需依赖多机器人数据采集或多阶段训练 。注意到,这个数据量更接近现代单任务模仿学习的数据规模。尽管数据量相对较小,Helix 仍然能够扩展到 更具挑战性的全上半身 humanoid 控制动作空间,输出高频、高维动作信号。
A single set of weights:
以往的 VLA 系统通常需要,针对不同高层行为进行专门微调或者设计专门的动作头(action heads)来优化性能
而 Helix 的表现非常惊人,采用单一统一模型就可以处理多任务,权重只有S2 = 7B,S1 = 80M,而且功能功能包括:
拾取和放置物品
操作抽屉和冰箱
多机器人精巧手部交接
操作数千种新物体
结论:提出了 Helix,这是 首个能够通过自然语言直接控制整个 humanoid 上半身的 Vision-Language-Action 模型 。与早期机器人系统不同,Helix 能够即时生成 长时程、协作、灵巧操作,无需任务特定演示或大量人工编程。
Helix 显示出强大的 物体泛化能力:
-
能够通过自然语言指令抓取数千种训练中从未见过的家居物品
-
适应不同形状、尺寸、颜色和材质
这标志着 Figure 在 humanoid 机器人行为扩展方面的 重大突破 ,在家庭环境中辅助日常生活潜力巨大。虽然这些早期结果令人兴奋,但这只是可能性的冰山一角 。我们期待看到 Helix 扩展 1000 倍甚至更多 后的表现。