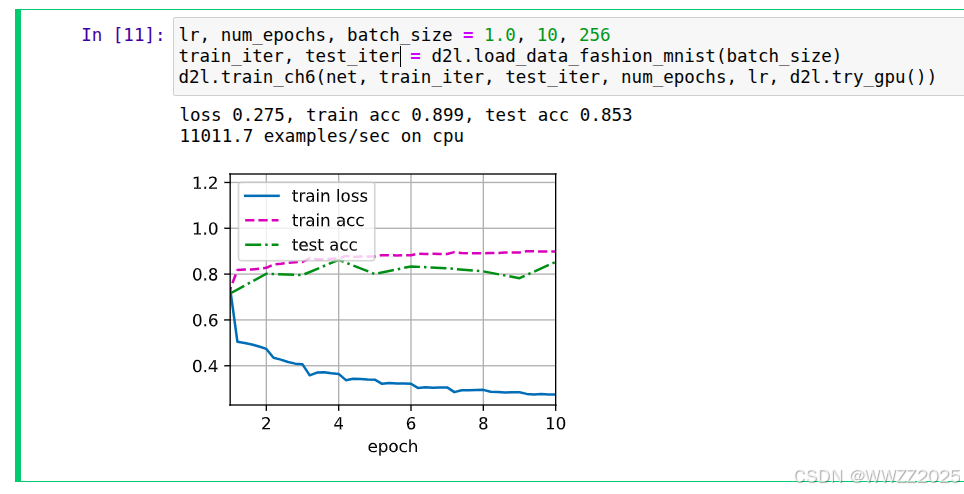
1 模型较大时训练技巧
(1)减小batch size(最有效);
(2)降低输入分辨率resize;
(3)减少模型复杂度 / 层数 / 通道数;
(4)使用更轻量的模型(MobileNet / ResNet18);
(5)使用混合精度AMP (自动半精度);
(6)梯度累积(模拟大batch);
(7)减少num_workers;
(8)清理显存 / 减少缓存;
(9)使用CPU辅助训练(最后手段)。
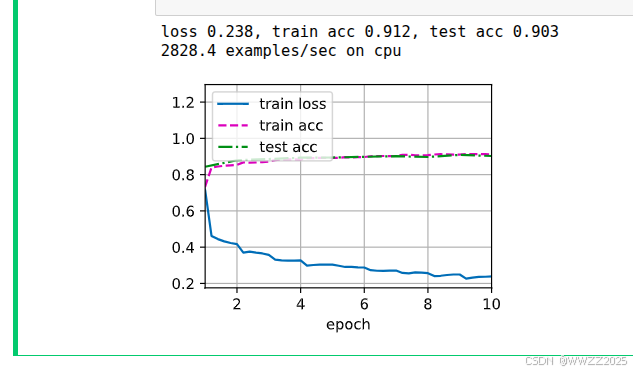
2 降低模型参数+CPU训练
PS.笔者GPU算力不足,即使降低模型大小仍旧报错
CUDA error: out of memory故使用CPU训练,模型同样改小,代码如下
import torch from torch import nn from d2l import torch as d2l import gc # ----------------------------- # 清理显存(如果之前使用过 GPU) gc.collect() torch.cuda.empty_cache() # ----------------------------- # 定义 VGG Block def vgg_block(num_convs, in_channels, out_channels): layers = [] for _ in range(num_convs): layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)) layers.append(nn.ReLU()) in_channels = out_channels layers.append(nn.MaxPool2d(kernel_size=2, stride=2)) return nn.Sequential(*layers) # ----------------------------- # 超小 VGG 架构 small_conv_arch = [(1, 16), (1, 32), (2, 64)] def vgg(conv_arch): conv_blks = [] in_channels = 1 # Fashion-MNIST 是灰度图 for (num_convs, out_channels) in conv_arch: conv_blks.append(vgg_block(num_convs, in_channels, out_channels)) in_channels = out_channels return nn.Sequential( *conv_blks, nn.Flatten(), nn.Linear(in_channels * 4 * 4, 256), nn.ReLU(), nn.Dropout(0.5), nn.Linear(256, 128), nn.ReLU(), nn.Dropout(0.5), nn.Linear(128, 10) ) # ----------------------------- # 强制使用 CPU device = torch.device('cpu') # ----------------------------- # 数据加载(输入 32x32) batch_size = 16 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size, resize=32) # ----------------------------- # 网络实例化 net = vgg(small_conv_arch).to(device) # ----------------------------- # 超参数 lr, num_epochs = 0.05, 10 # ----------------------------- # 训练 d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, device)
3 云服务器
3.1 免费云GPU使用
Kaggle官网每周一个账号有30h免费训练额度。
使用方法:
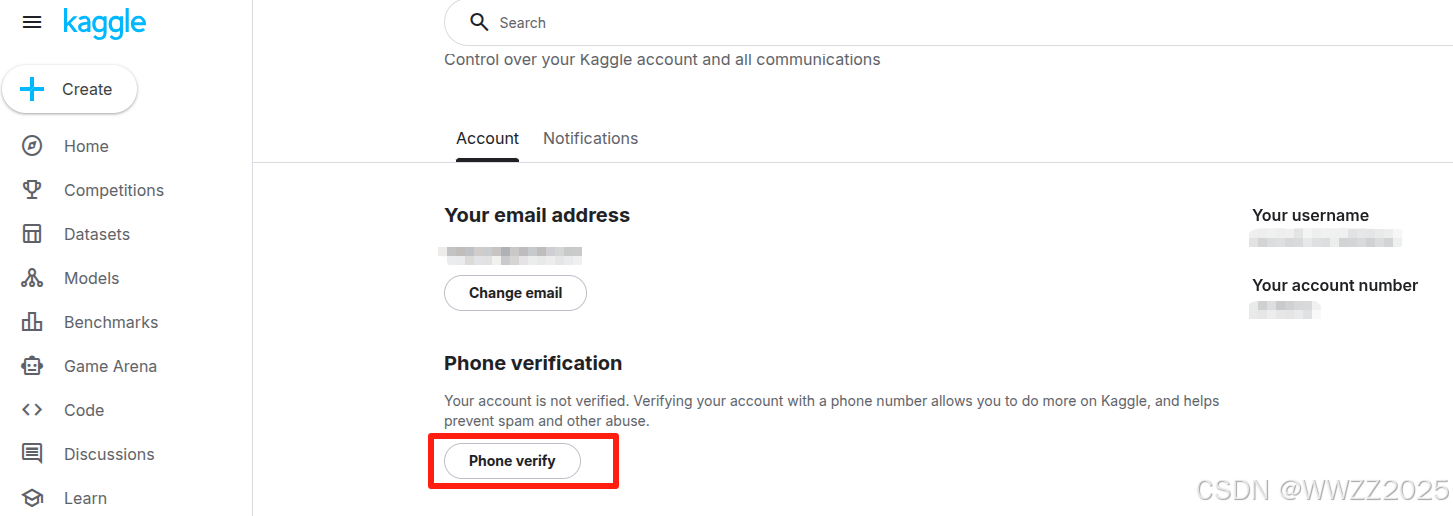
(1)登陆账号;
(2)主页home-点击头像-设置settings-手机验证phone verification
(3)验证后创建notebook-输入需要训练的代码-选择GPU/TPU即可
(4)GPU/TPU区别
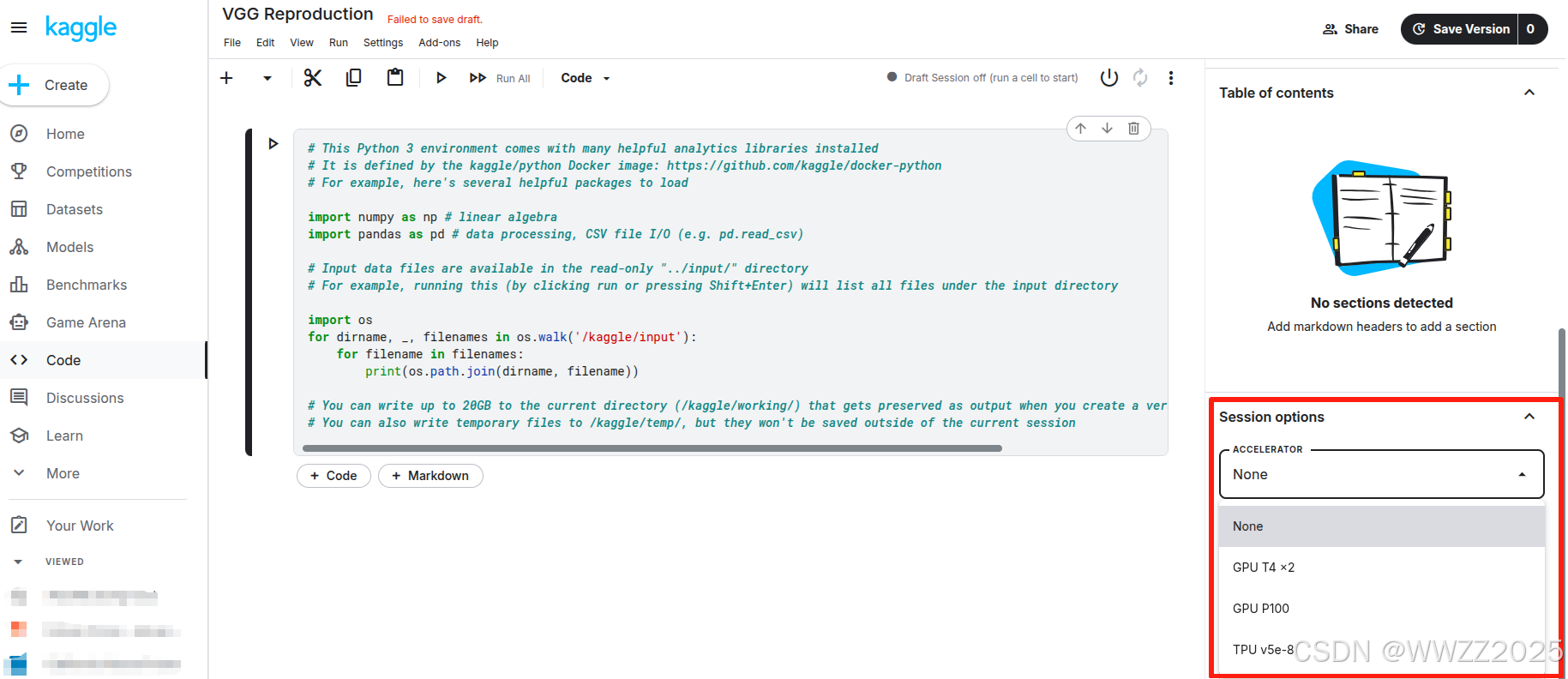
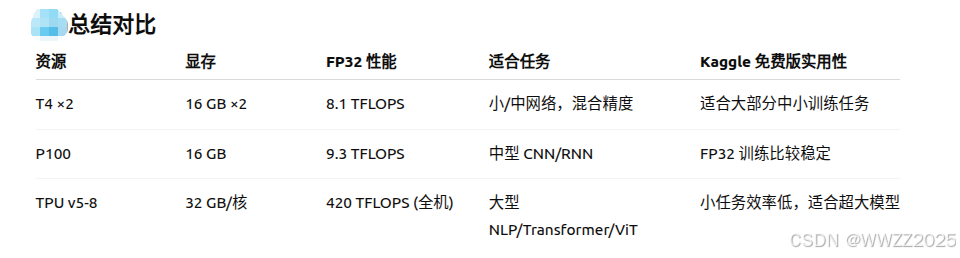
3.2 云服务器租用
云服务器有很多,可以自行选择一家性价比高的,但长期从事深度学习、大模型等相关工作还是建议组里有计算资源。
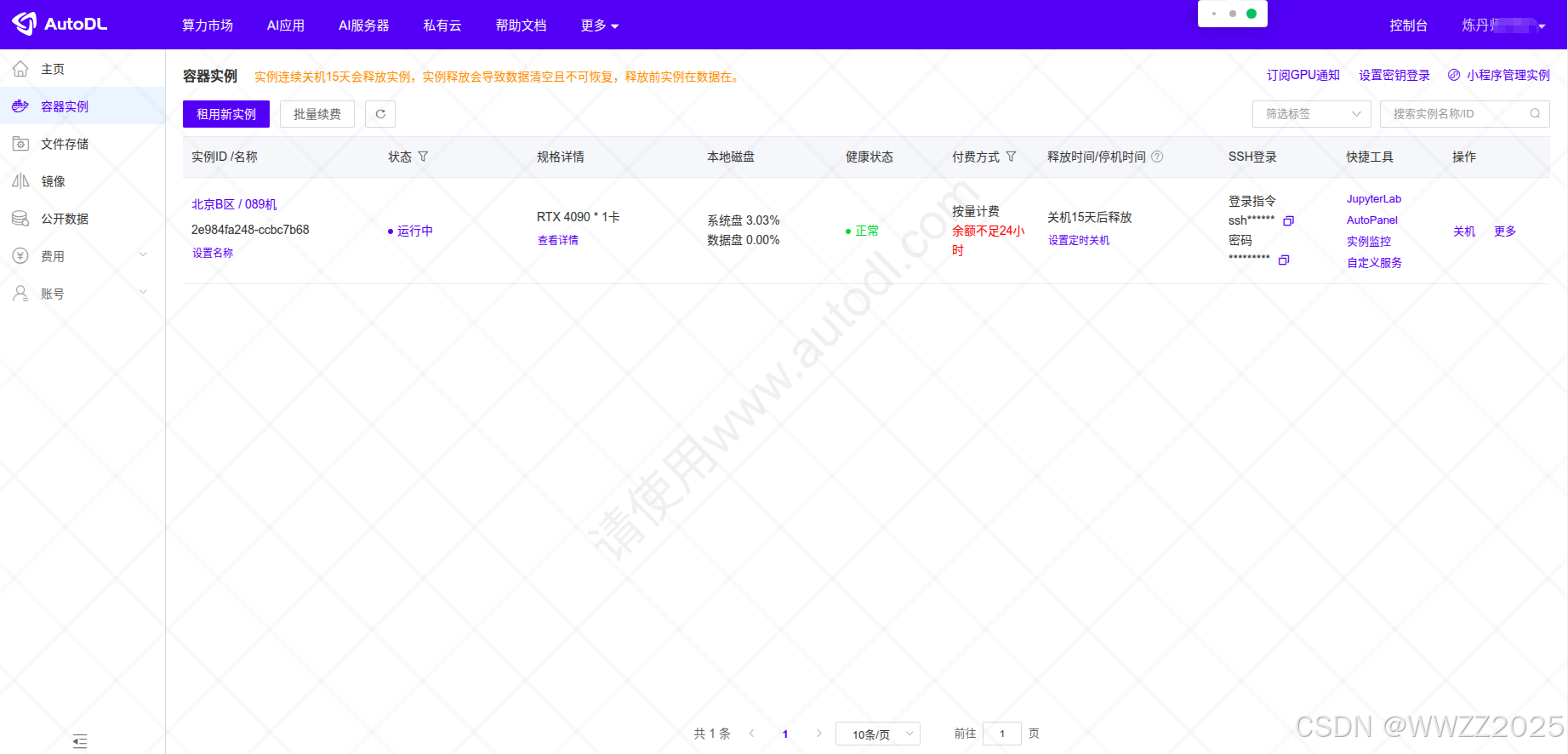
3.2.1 租用服务器
以AutoDL为例,网站:https://api.autodl.com/market/list
3.2.2 安装文件传输工具
(1)下载安装FileZilla,链接:https://filezilla-project.org/
(2)解压安装指令:
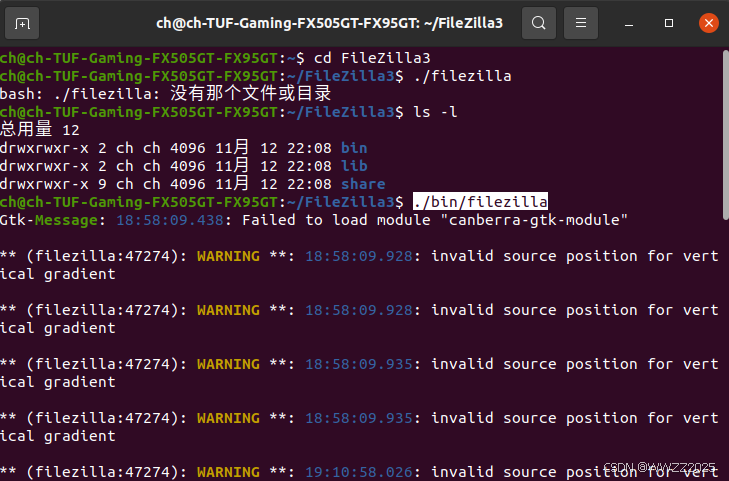
tar -xvf FileZilla_3.69.5_x86_64-linux-g(3)打开FileZilla
cd FileZilla3 ./bin/filezilla
3.2.3 SSH协议远程接入云服务器
(1)VSCode上配置远程文件
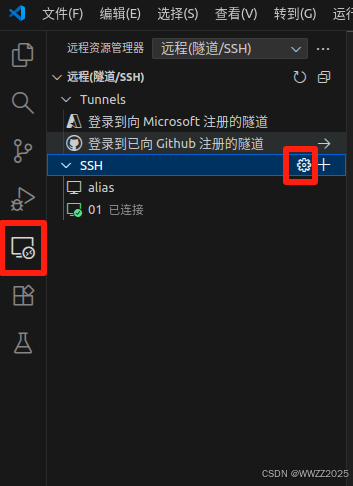
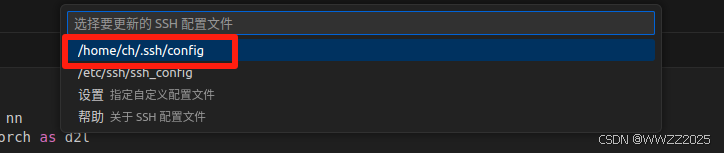
复制登陆指令,并在VSCode上配置:
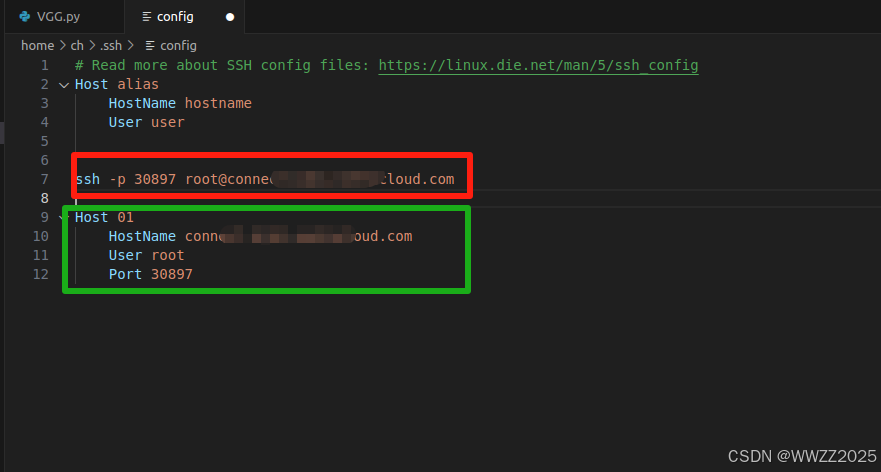
复制下来是红色框的信息,根据红色框编写绿色部分内容(其中01序号自定),删除红框内容并保存。
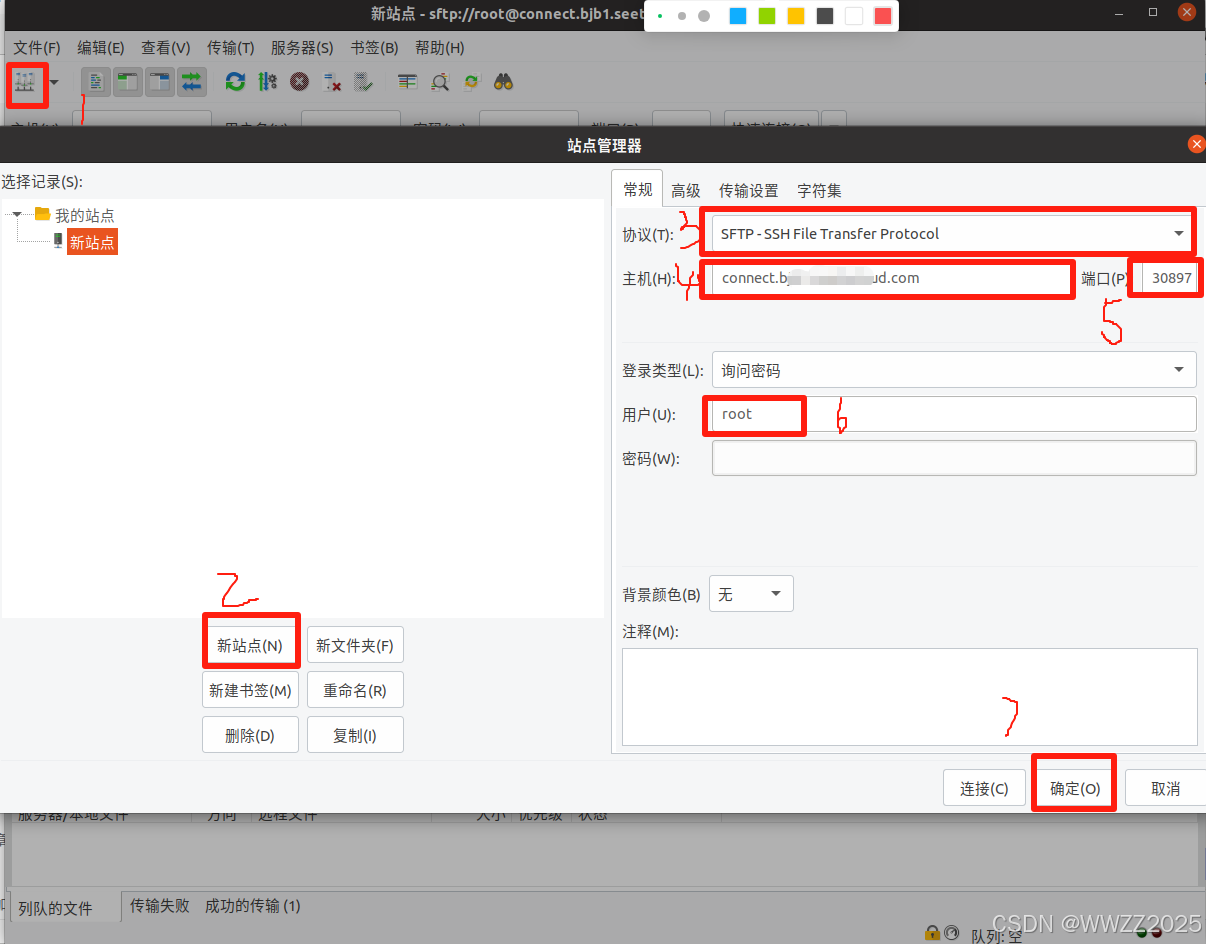
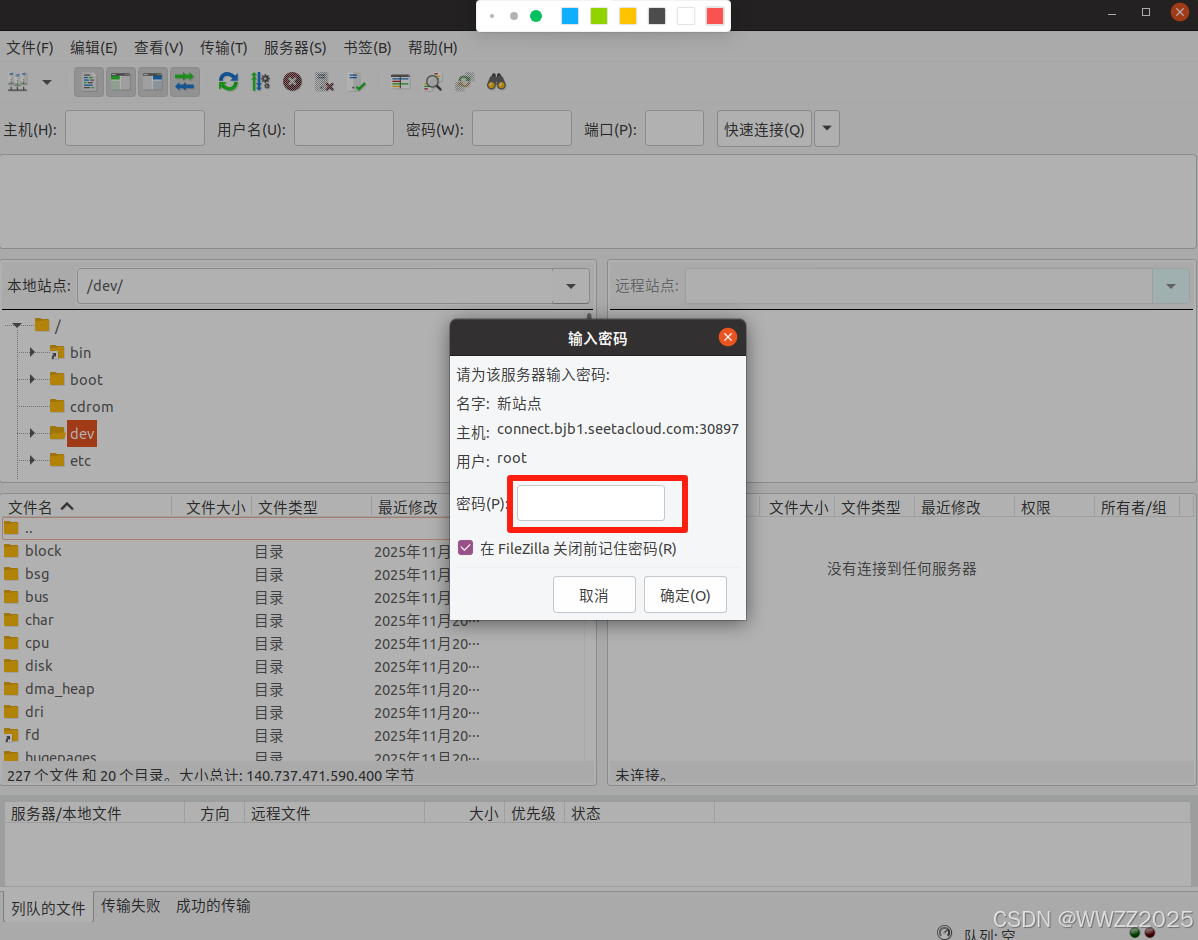
(2)FileZilla上配置
密码在AutoDL上复制:


3.2.4 连接测试
将自己需要训练的数据集、代码拖入root,在vs中调用训练代码。
4 卷积神经网络续章
前序见https://blog.csdn.net/weixin_45728280/article/details/154958277?spm=1011.2415.3001.5331
4.1 GoogLeNet
4.1.1 Incepion块
特点:和3*3或5*5卷积层相比,Inception块有更少的参数个数和计算复杂度。(通过有选择的降低通道数而减少运算量)
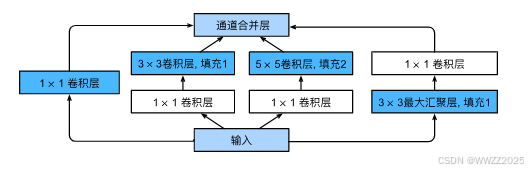
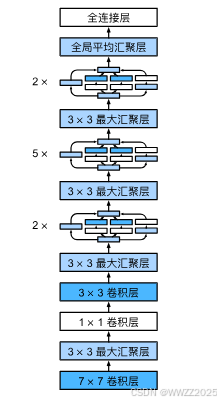
4.1.2 GoogLeNet架构
5段,9个Inception块:
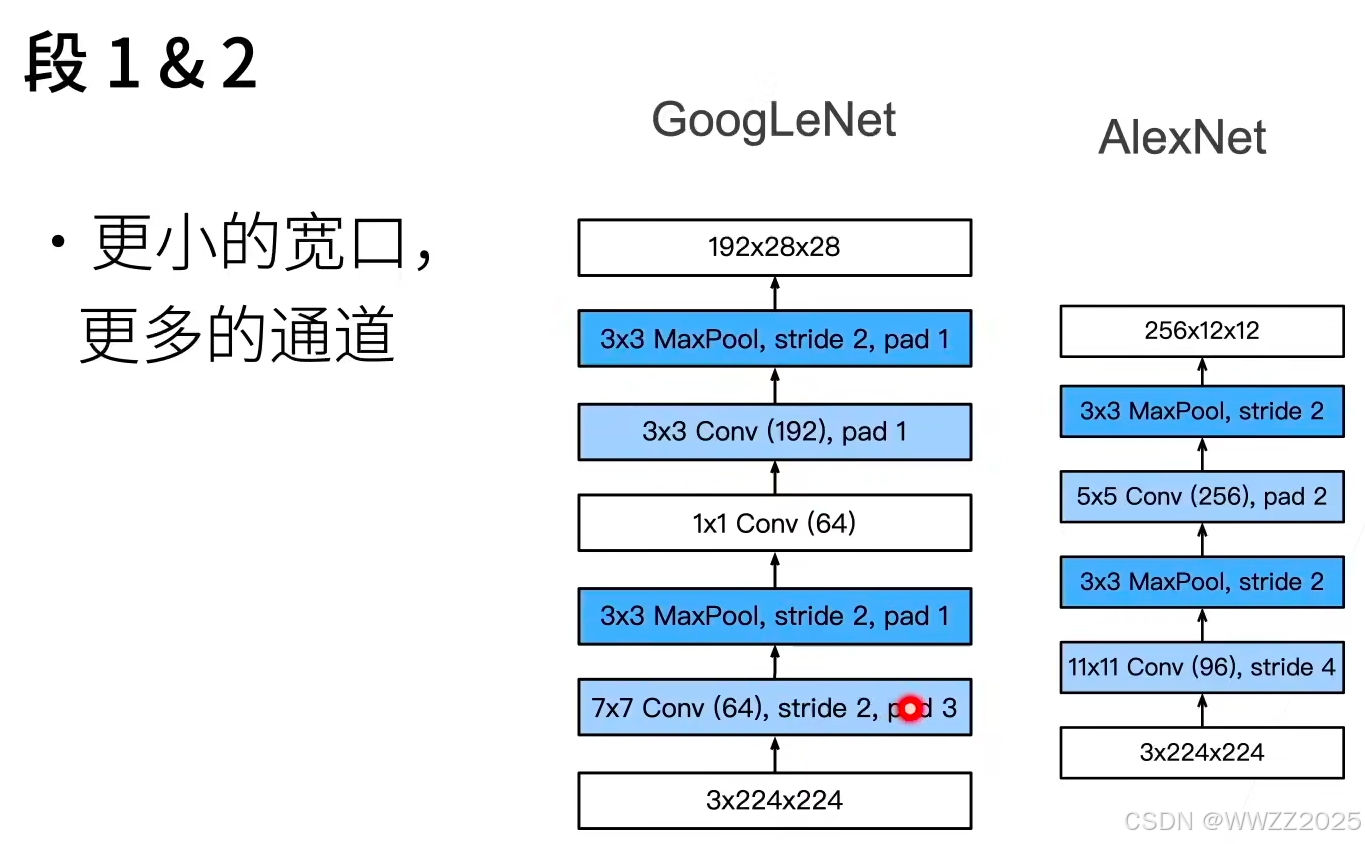
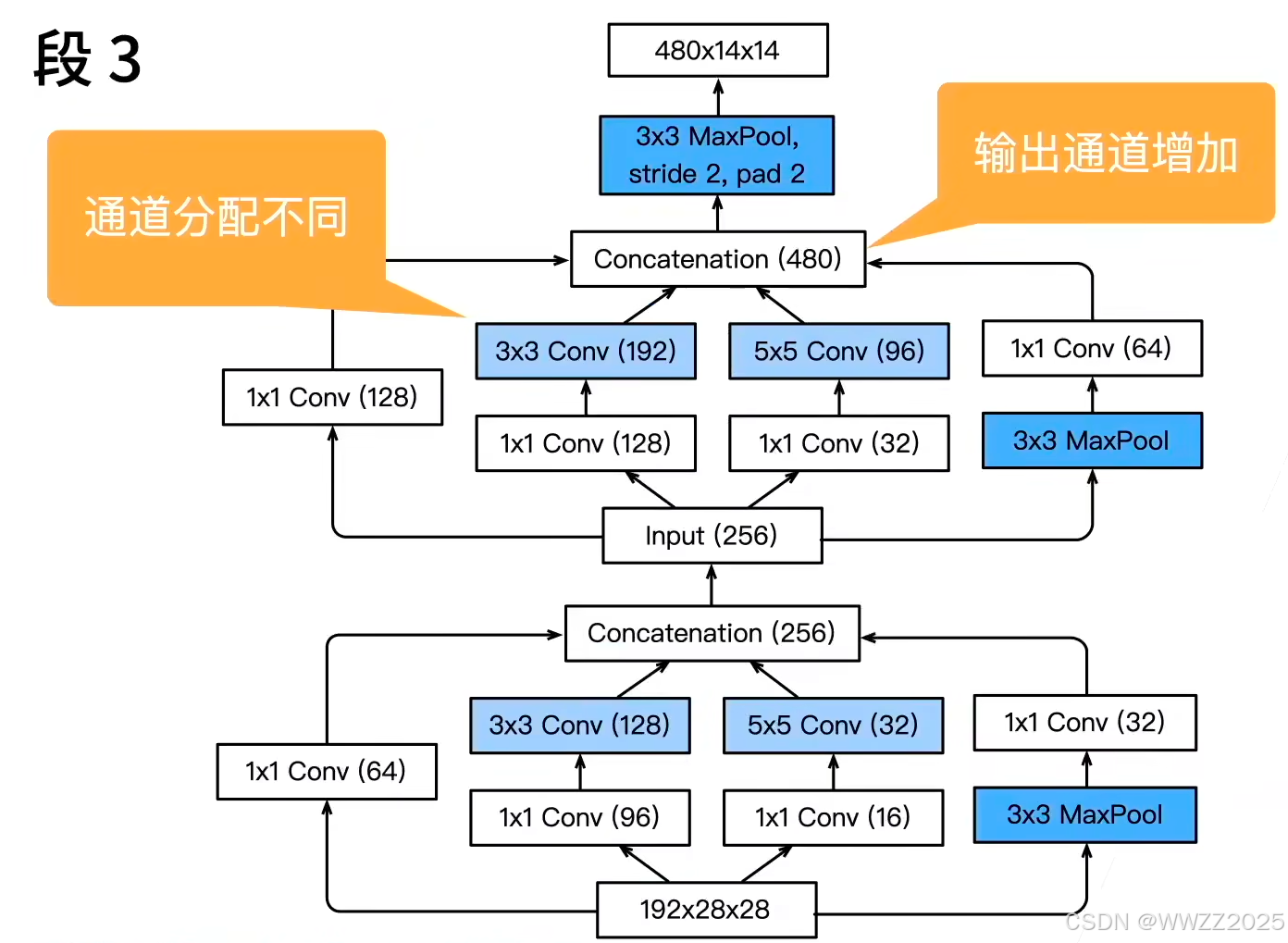
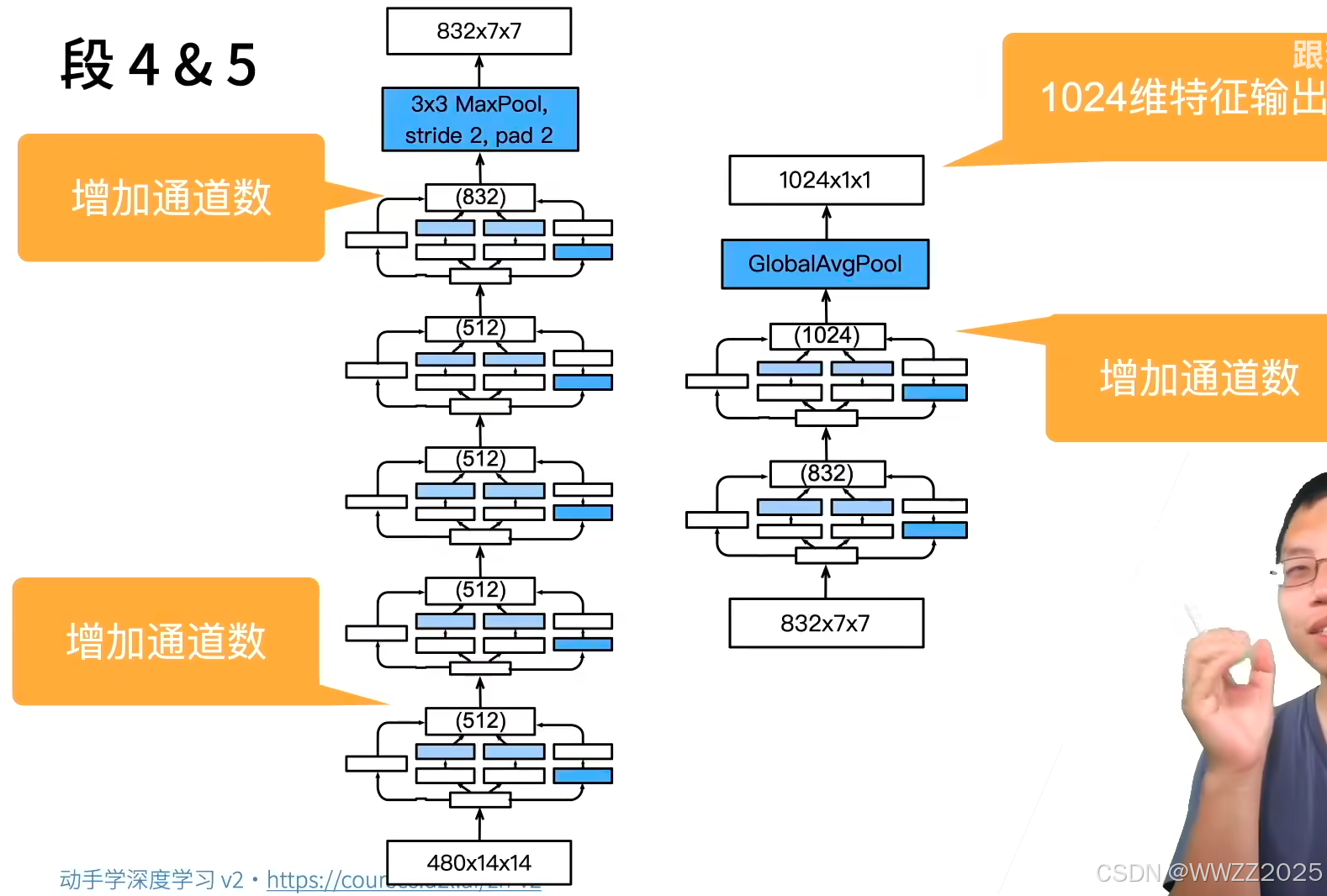
4.1.3 代码
(1)Inception块
import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l class Inception(nn.Module): # c1--c4是每条路径的输出通道数 def __init__(self, in_channels, c1, c2, c3, c4, **kwargs): super(Inception, self).__init__(**kwargs) # 线路1,单1x1卷积层 self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1) # 线路2,1x1卷积层后接3x3卷积层 self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1) self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1) # 线路3,1x1卷积层后接5x5卷积层 self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1) self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2) # 线路4,3x3最大汇聚层后接1x1卷积层 self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1) def forward(self, x): p1 = F.relu(self.p1_1(x)) p2 = F.relu(self.p2_2(F.relu(self.p2_1(x)))) p3 = F.relu(self.p3_2(F.relu(self.p3_1(x)))) p4 = F.relu(self.p4_2(self.p4_1(x))) # 在通道维度上连结输出 return torch.cat((p1, p2, p3, p4), dim=1)(2)GoogLeNet模型
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(), nn.Conv2d(64, 192, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32), Inception(256, 128, (128, 192), (32, 96), 64), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64), Inception(512, 160, (112, 224), (24, 64), 64), Inception(512, 128, (128, 256), (24, 64), 64), Inception(512, 112, (144, 288), (32, 64), 64), Inception(528, 256, (160, 320), (32, 128), 128), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128), Inception(832, 384, (192, 384), (48, 128), 128), nn.AdaptiveAvgPool2d((1,1)), nn.Flatten()) net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10)) X = torch.rand(size=(1, 1, 96, 96)) for layer in net: X = layer(X) print(layer.__class__.__name__,'output shape:\t', X.shape)(3)模型训练
lr, num_epochs, batch_size = 0.1, 10, 128 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96) d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
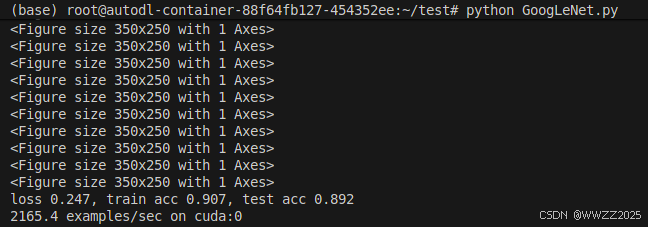
4.1.4 Inception变种
(1)Inception-BN(V2)
使用batch normalization
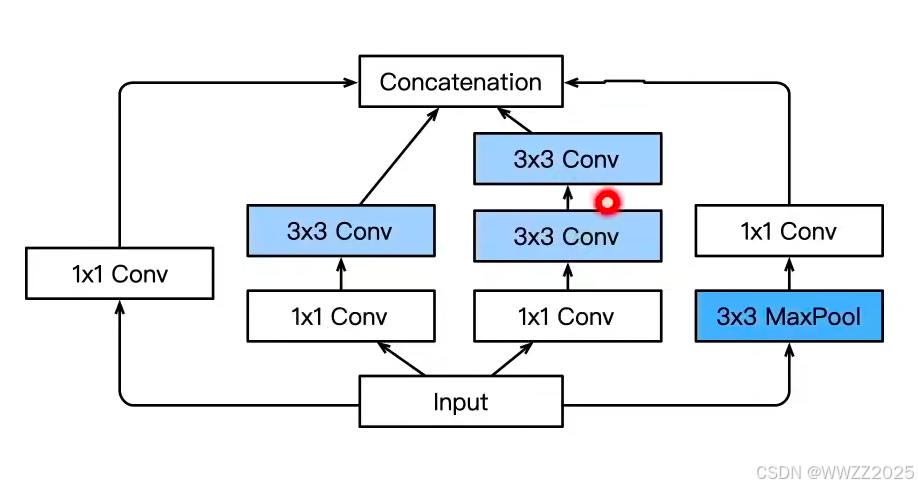
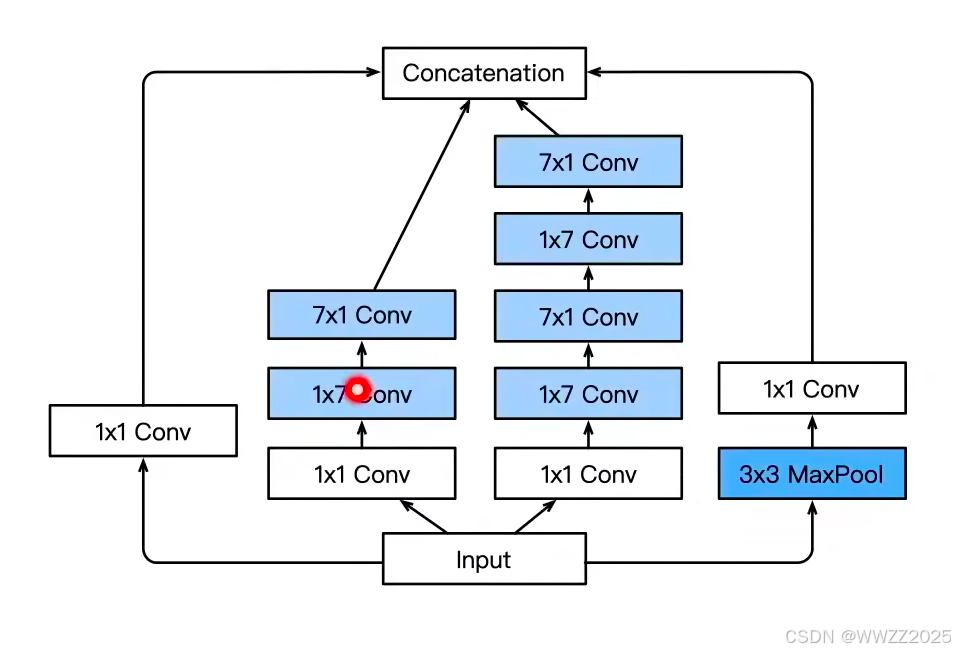
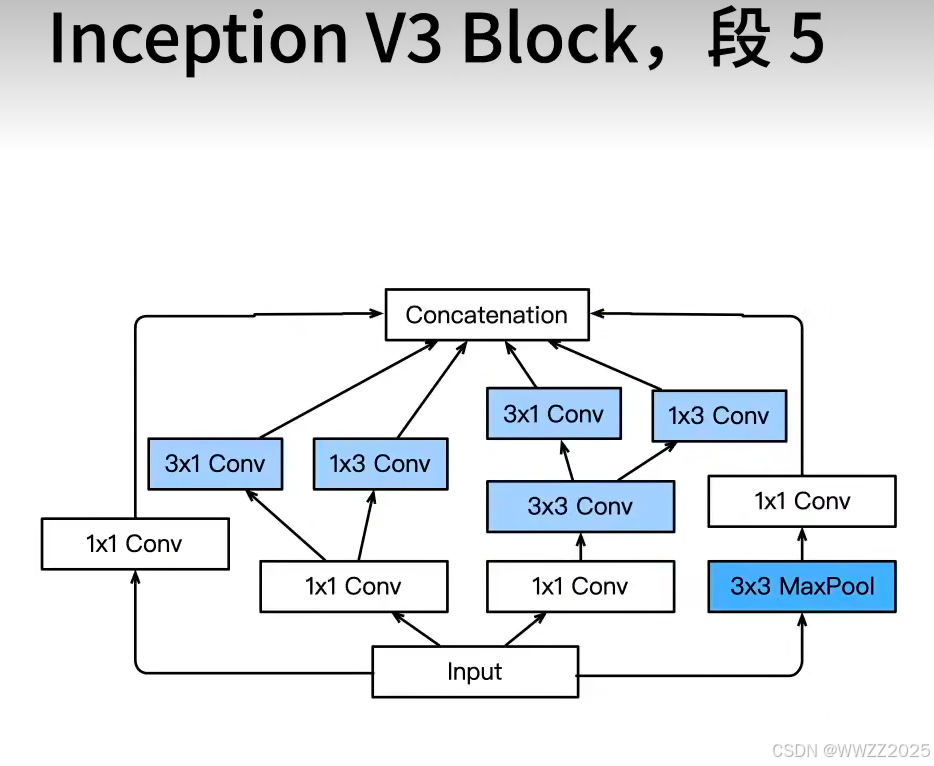
(2)Inception-V3
修改了Inception块,替换5x5为多个3x3卷积层、5x5为1x7和7x1卷积层、3x3为1x3和3x1卷
积层,模型更深
(3)nception-V4
使用残差连接
4.2 ResNet残差网络
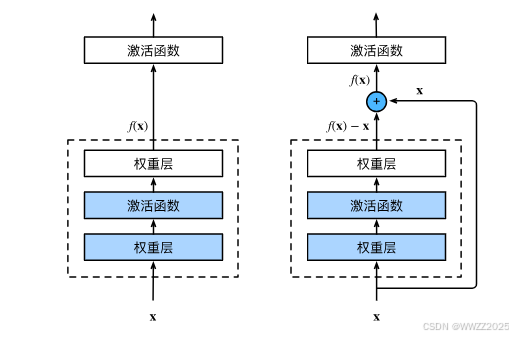
4.2.1 ResNet块
ResNet残差块是将上一层的输出和经过这层学习后的输出求和作为这一层的输出。
4.2.2 架构
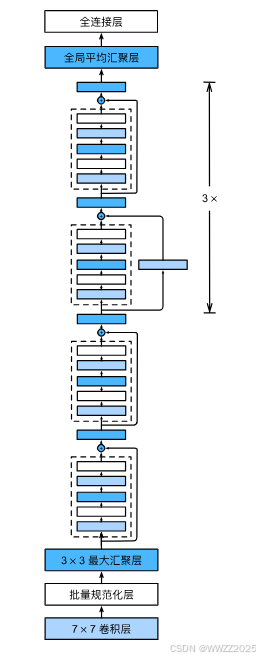
4.2.3 代码
(1)残差块
pythonimport torch from torch import nn from torch.nn import functional as F from d2l import torch as d2l class Residual(nn.Module): #@save def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1): super().__init__() self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides) self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1) if use_1x1conv: self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides) else: self.conv3 = None self.bn1 = nn.BatchNorm2d(num_channels) self.bn2 = nn.BatchNorm2d(num_channels) def forward(self, X): Y = F.relu(self.bn1(self.conv1(X))) Y = self.bn2(self.conv2(Y)) if self.conv3: X = self.conv3(X) Y += X return F.relu(Y)
pythonblk = Residual(3,3) X = torch.rand(4, 3, 6, 6) Y = blk(X) Y.shape blk = Residual(3,6, use_1x1conv=True, strides=2) blk(X).shape(2)ResNet模型
pythonb1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) def resnet_block(input_channels, num_channels, num_residuals, first_block=False): blk = [] for i in range(num_residuals): if i == 0 and not first_block: blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2)) else: blk.append(Residual(num_channels, num_channels)) return blk b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True)) b3 = nn.Sequential(*resnet_block(64, 128, 2)) b4 = nn.Sequential(*resnet_block(128, 256, 2)) b5 = nn.Sequential(*resnet_block(256, 512, 2)) net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1,1)), nn.Flatten(), nn.Linear(512, 10)) X = torch.rand(size=(1, 1, 224, 224)) for layer in net: X = layer(X) print(layer.__class__.__name__,'output shape:\t', X.shape)(3)模型训练
pythonlr, num_epochs, batch_size = 0.05, 10, 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96) d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

5 批量归一化BN
5.1 定义
批量归一化就是对每一层的输入做标准化(减均值、除方差),再通过可学习的缩放和平移让网络自适应调整。目的是让每一层输入的分布("零均值、单位方差")更稳定,训练更快、更稳定。


5.2 代码
import torch from torch import nn from d2l import torch as d2l def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum): # 通过is_grad_enabled来判断当前模式是训练模式还是预测模式 if not torch.is_grad_enabled(): # 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差 X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps) else: assert len(X.shape) in (2, 4) if len(X.shape) == 2: # 使用全连接层的情况,计算特征维上的均值和方差 mean = X.mean(dim=0) var = ((X - mean) ** 2).mean(dim=0) else: # 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。 # 这里我们需要保持X的形状以便后面可以做广播运算 mean = X.mean(dim=(0, 2, 3), keepdim=True) var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True) # 训练模式下,用当前的均值和方差做标准化 X_hat = (X - mean) / torch.sqrt(var + eps) # 更新移动平均的均值和方差 moving_mean = momentum * moving_mean + (1.0 - momentum) * mean moving_var = momentum * moving_var + (1.0 - momentum) * var Y = gamma * X_hat + beta # 缩放和移位 return Y, moving_mean.data, moving_var.data class BatchNorm(nn.Module): # num_features:完全连接层的输出数量或卷积层的输出通道数。 # num_dims:2表示完全连接层,4表示卷积层 def __init__(self, num_features, num_dims): super().__init__() if num_dims == 2: shape = (1, num_features) else: shape = (1, num_features, 1, 1) # 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0 self.gamma = nn.Parameter(torch.ones(shape)) self.beta = nn.Parameter(torch.zeros(shape)) # 非模型参数的变量初始化为0和1 self.moving_mean = torch.zeros(shape) self.moving_var = torch.ones(shape) def forward(self, X): # 如果X不在内存上,将moving_mean和moving_var # 复制到X所在显存上 if self.moving_mean.device != X.device: self.moving_mean = self.moving_mean.to(X.device) self.moving_var = self.moving_var.to(X.device) # 保存更新过的moving_mean和moving_var Y, self.moving_mean, self.moving_var = batch_norm( X, self.gamma, self.beta, self.moving_mean, self.moving_var, eps=1e-5, momentum=0.9) return Y net = nn.Sequential( nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(), nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(), nn.Linear(84, 10)) lr, num_epochs, batch_size = 1.0, 10, 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu()) net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))