
做Doris运维或开发的同学,多少都踩过内存的坑:BE突然OOM、导入时内存暴涨、查询报"内存不足"...明明配置看着没问题,问题却反复出现?
今天这份指南,从内存分类、监控方法,到核心原理、高频问题解决,全流程覆盖,建议收藏备用!
一、先搞懂:Doris的内存都用在哪?
要解决内存问题,先得明确Doris的内存分类和关键配置,避免盲目调参。
1. 内存分类:7类核心内存场景
Doris的内存消耗主要分散在7个场景,不同场景的异常对应不同问题:
| 标识 | 名称 | 核心说明 |
|---|---|---|
| process | BE总使用内存 | 整个BE进程的内存总占用 |
| query_pool | 查询内存 | 分执行层(如Join、聚合)和存储层(如读数据) |
| load | 导入内存 | 核心是MemTable(导入数据暂存区),满了会刷盘 |
| table_meta | 元数据内存 | 存储Schema、Tablet、RowSet、列等元信息,版本多会膨胀 |
| compaction | 多版本合并内存 | 数据导入后多版本合并用的内存 |
| snaphost | 快照内存 | 主要用于副本克隆(clone),通常占用很少 |
| column_pool | 列缓存 | 加速列对象的申请与释放,执行线程会保留部分缓存 |
| page_cache | BE自有PageCahe | 默认关闭,手动开启后缓存热点数据 |
2. 关键配置:BE与Session变量对照表
内存问题大多和配置不当有关,这两类配置是核心(建议保存备用):
2.1 BE配置(be.conf)
| 配置项 | 默认值 | 核心作用 |
|---|---|---|
| vector_chunk_size | 4096 | Chunk分配器的预留字节限制 |
| tc_use_memory_min | 10737418240(10G) | Tcmalloc最小保留内存,超此值,Doris才把空闲内存返还系统 |
| mem_limit | 80% | BE可使用的机器总内存比例,混合部署推荐修改,防止OOM |
| disable_storage_page_cache | true | 是否关闭自有PageCache(默认关闭) |
| write_buffer_size | 104857600(100M) | 单个MemTable内存上限,超了触发刷盘 |
| load_process_max_memory_limit_bytes | 107374182400(100G) | 导入总内存上限,与百分比取最小值生效 |
| load_process_max_memory_limit_percent | 60% | 导入内存占BE总内存的比例,min(mem_limit * load_process_max_memory_limit_percent, load_process_max_memory_limit_bytes) |
| load_mem_limit | 2147483648(2G) | 单个导入实例接收端内存上限,到达这个限制,会触发刷盘逻辑,需配合Session变量load_mem_limit修改才能生效 |
2.2 Session变量
| 变量名 | 默认值 | 核心作用 |
|---|---|---|
| exec_mem_limit | 2147483648(2G) | 单个查询实例instance的内存限制 |
| load_mem_limit | 0 | 单个导入任务内存限制,0时复用exec_mem_limit |
二、内存监控:5种方法精准定位问题
监控是解决内存问题的前提,5种方法覆盖"宏观统计"到"堆栈分析",按需选用:
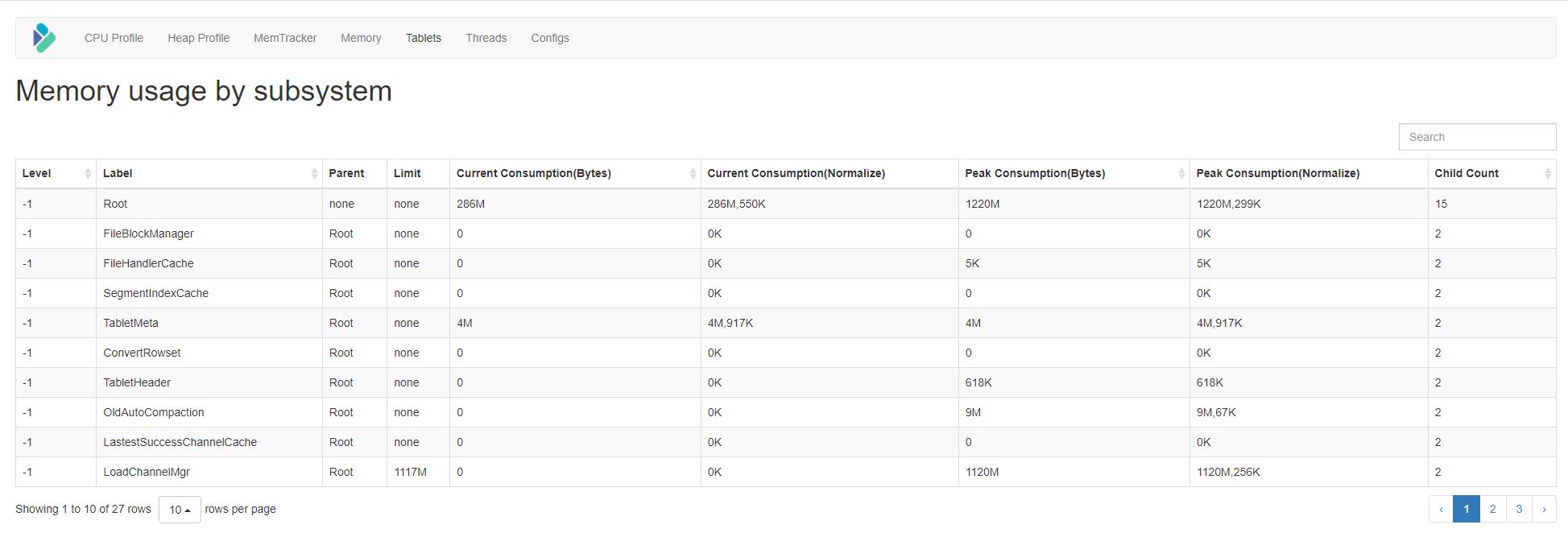
1. mem_tracker:整体内存统计(最常用)
-
操作方式 :浏览器访问
http://BE_IP:BE_WEB_PORT/mem_tracker -
优势:直观展示各分类内存(如query_pool、load)的占用情况
-
不足:部分内存未统计(非向量Compaction、存储层读内存)
2. Tcmalloc:最精准的内存统计
-
操作方式 :浏览器访问
http://BE_IP:BE_WEB_PORT/memz -
核心指标解读:
-
Bytes in use by application:实际被应用使用的内存(最关键) -
Actual memory used:物理+交换分区的实际占用
-
-
注意:统计的是"预留内存"而非"实时使用内存",需结合业务场景判断
3. metrics:批量监控(适合运维告警)
-
操作方式 :执行命令
curl -XGET http://127.0.0.1:BE_WEB_PORT/varz | grep 'mem' -
优势:可提取关键指标接入监控系统(如Prometheus)
-
不足:10秒更新一次,实时性一般,老版本仅支持部分统计
4. growth:内存增长堆栈(定位泄漏)
-
操作方式:生成火焰图分析
Bashpprof --svg http://be_host:be_webport/pprof/growth >mem.svg -
用途:查看内存增长最快的函数调用栈,定位内存泄漏点
5. HEAP_PROFILE:详细堆栈分析(深度排查)
-
操作步骤:
-
设置环境变量并重启BE:
Bashexport HEAPPROFILE=/tmp/doris_be.hprof ./bin/start_be.sh --daemon -
生成堆栈图:
Bashpprof --svg lib/doris_be /tmp/doris_be.hprof.0012.heap > heap.svg -
排查后清理:
unset HEAPPROFILE并重启BE
-
-
优势:最详细的内存使用堆栈,适合疑难内存问题
三、核心原理:3大高频内存消耗场景解析
内存问题不是偶然的,这3个场景是消耗内存的"重灾区",理解原理才能精准解决:
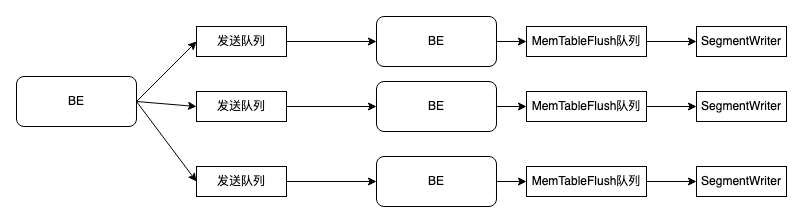
1. 导入:MemTable与刷盘逻辑
-
内存消耗点:发送队列、MemTableFlush队列、SegmentWriter的PageBuffer
-
关键逻辑 :导入数据先写入MemTable,达到
write_buffer_size或load_mem_limit触发刷盘,刷盘不及时会导致内存堆积
2. Compaction:多版本合并的内存消耗

-
核心消耗点:Overlapping合并时需打开所有Segment,字典和Chunk占用内存最高
-
关键限制:
-
Cumulative Compaction最多合并1000个版本
-
Base Compaction最多合并5个版本
-
3. 查询:4类高频高内存操作
-
Join:构建右表哈希表时占用内存,大表广播、表顺序搞反易OOM
-
聚合:高基数聚合需存储大量中间结果,内存占用陡增
-
TopN:N值过大时需缓存大量数据排序
-
全量Sort:无索引的全表排序,内存不足会触发磁盘排序
四、高频问题:8类内存异常解决方案
这部分是核心干货,覆盖运维中最常遇到的内存问题,按"问题场景→排查步骤→解决方法"整理:
1. Compaction OOM(最棘手)
预警指标:FE监控doris_fe_tablet_max_compaction_score > 100
1.1 应急处理(先止损)
-
关闭自动Compaction:设置
disable_auto_compaction=true并重启BE -
重建表:
INSERT INTO 新表 SELECT FROM 老表(规避历史版本问题) -
恢复Compaction:改回配置并重启BE
1.2 根因解决
-
场景A:单个分桶文件过多 排查:
SHOW TABLET FROM 表名→ 查看Overlapping Segment数(建议≤100) 解决:① 增加分桶数 ② 缩小分区粒度(如月→天) ③ 调大write_buffer_size(并行导入少时用) -
场景B:版本过多 排查:①
SHOW TABLET FROM 表名 LIMIT 1看VersionCount ② 访问http://BE_IP:8040/api/compaction/show?tablet_id=XXX&schema_hash=XXX看未合并版本 解决:降低导入频率(如高频StreamLoad尽可能增大攒批) -
场景C:数据倾斜 排查:
SHOW TABLETS FROM 表名看各Tablet大小差异,数据多的Tablet中Segment数比较多,导致第一次Compaction消耗大量内存。 解决:重新建表,选择更均匀的分桶列
2. 导入OOM
2.1 高频场景:Insert Into Select From高并行
-
现象:导入时load和column_pool内存暴涨
-
解决:设置Session变量降低并行度
SQLset parallel_fragment_exec_instance_num=xxx;
2.2 其他场景解决
| 问题原因 | 解决方法 |
|---|---|
| 导入频率过高(版本堆积) | 减少RoutineLoad/Flink Load频率,攒批导入 |
| 聚合表导入产生大量小文件 | 调大write_buffer_size,减少小文件数量 |
| 无序导入写多Tablet | 优化导入数据顺序,避免同时写多个Tablet |
3. Join OOM
| 问题原因 | 解决方法 |
|---|---|
| 大表广播Join | 禁用广播:set enable_broadcast_join=false,改用Shuffle Join |
| 左右表顺序搞反 | 调整SQL,将小表作为右表(构建哈希表) |
| 右表列过多 | 只查询必要列,避免全列构建哈希表 |
4. Sort/聚合 OOM
-
Sort OOM:避免无索引全量Sort
-
聚合OOM:针对大数据聚合时,合理拆分
5. PageCache内存过高
-
现象:开启PageCache后内存占用高
-
解决:修改BE配置
disable_storage_page_cache=true并重启BE
6. 元数据OOM
-
原因:版本过多、列过多、Compaction不及时
-
解决:① 降低导入频率减少版本 ② 拆分宽表(列过多时) ③ 调优Compaction参数加速合并
7. 混合部署内存失控
-
问题:BE与其他服务混部时内存被抢占
-
解决:① 手动设置
mem_limit=分配给BE的内存比例(如50%) ② 不要用cgroup限制(无效)
8. 夜间11点内存暴涨
-
原因:默认触发Tablet一致性检查(
check_consistency_worker_count=1) -
解决:修改BE配置
check_consistency_worker_count=0并重启BE,关闭检查
你在Doris运维中遇到过哪些奇葩的内存问题?评论区分享你的踩坑经历,一起避坑~