视觉Transformer实战 | Token-to-Token Vision Transformer(T2T-ViT)详解与实现
-
- [0. 前言](#0. 前言)
- [1. T2T-ViT 技术原理](#1. T2T-ViT 技术原理)
-
- [1.1 传统 ViT 的局限性](#1.1 传统 ViT 的局限性)
- [1.2 T2T-ViT 创新点](#1.2 T2T-ViT 创新点)
- [2. T2T-ViT 核心](#2. T2T-ViT 核心)
-
- [2.1 Tokens-to-Token (T2T) 模块](#2.1 Tokens-to-Token (T2T) 模块)
- [2.2 网络架构](#2.2 网络架构)
- [3. 实现 T2T-ViT 模型](#3. 实现 T2T-ViT 模型)
-
- [3.1 实现 T2T 模块](#3.1 实现 T2T 模块)
- [3.2 模型训练](#3.2 模型训练)
- 相关链接
0. 前言
Vision Transformer (ViT)在计算机视觉领域取得了巨大成功,但标准的 ViT 存在一些局限性,如需要大规模预训练数据、对局部结构建模不足等。Token-to-Token ViT (T2T-ViT) 通过引入渐进式分词过程改进了原始 ViT,使其能够在中小型数据集上取得更好的性能。本节将详细介绍 T2T-ViT 的技术原理,并使用 PyTorch 从零开始实现 T2T-ViT。
1. T2T-ViT 技术原理
1.1 传统 ViT 的局限性
在深入介绍 T2T-ViT 之前,我们首先回顾传统 Vision Transformer (ViT)的核心处理流程:
- 图像分块:将输入图像划分为固定大小的非重叠
patch(如16×16像素) - 线性投影:通过可学习的矩阵将每个
patch展平为1D词元 (token) - 位置编码:添加位置信息后输入
Transformer编码器
ViT 在中小型数据集(如 ImageNet )上从头训练时性能不如卷积神经网络 (Convolutional Neural Network, CNN),其主要原因在于局部结构建模不足和特征冗余,ViT 将图像硬分割为固定大小非重叠 patch (如 16×16),破坏了边缘、线条等局部结构,ViT 结构存在大量无效通道,特征丰富度有限。
1.2 T2T-ViT 创新点
针对上述两个问题,T2T-ViT 提出了两个解决方法,首先是分层的 Tokens-to-Token 转换,通过合并相邻的 token 来结构化图片信息,同时合并 token 也可以减少 token 的长度,减少计算复杂度,另一个创新点是一个深而窄的注意力机制,其设计灵感来源于卷积神经网络,通过实验该结构具有高效性。
2. T2T-ViT 核心
2.1 Tokens-to-Token (T2T) 模块
网络中的 T2T Process 模块如下图所示,通过渐进式 token 重组解决局部结构建模问题,上一个 T2T Transformer 模块处理过的 token 作为本 T2T 模块的输入,执行以下处理:
- 重组 (
Re-structurization),将Transformer层输出的token序列 T i T_i Ti 通过自注意力 (MSA+MLP) 变换为 T i ′ T_i' Ti′,再整形 (reshape) 为2D图像 I i I_i Ii:
T i ′ = M L P ( M S A ( T i ) ) I i = R e s h a p e ( T i ′ ) T_i^′=MLP(MSA(T_i))\\I_i=Reshape(T_i^′) Ti′=MLP(MSA(Ti))Ii=Reshape(Ti′) - 软拆分 (
Soft Split):使用重叠滑动窗口(如7×7大小,stride=4) 将 I i I_i Ii 拆分为新token序列 T i + 1 T_{i+1} Ti+1,通过拼接邻域token聚合局部信息:
T i + 1 = U n f o l d ( I i ) T_{i+1}=Unfold(I_i) Ti+1=Unfold(Ii)
在Soft Split之后,输出token可进行下一轮T2T操作。
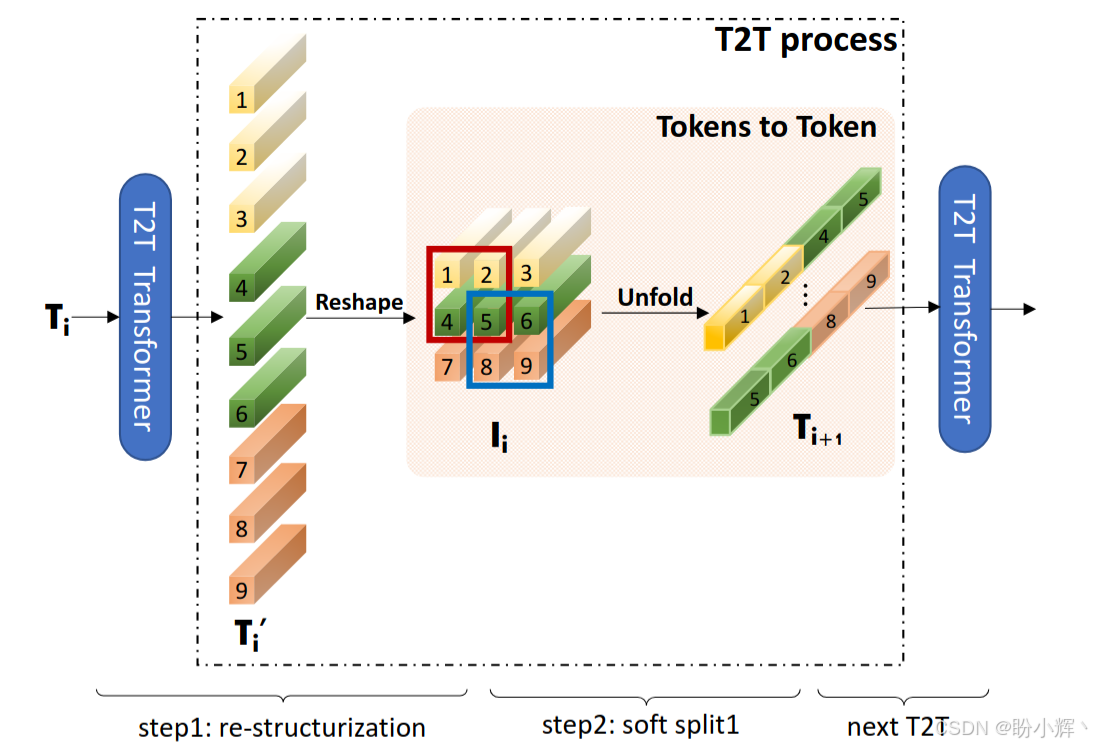
T2T 模块除了 T2T Process 模块外,还有包括 T2T Transformer 模块,T2T Process 模块和 T2T Transformer 模块交替组成了 T2T 模块。网络架构如下图所示,需要注意的是,第一个 T2T Process 没有整形操作,因为网络的输入即为一张图片,所以不需要整形。
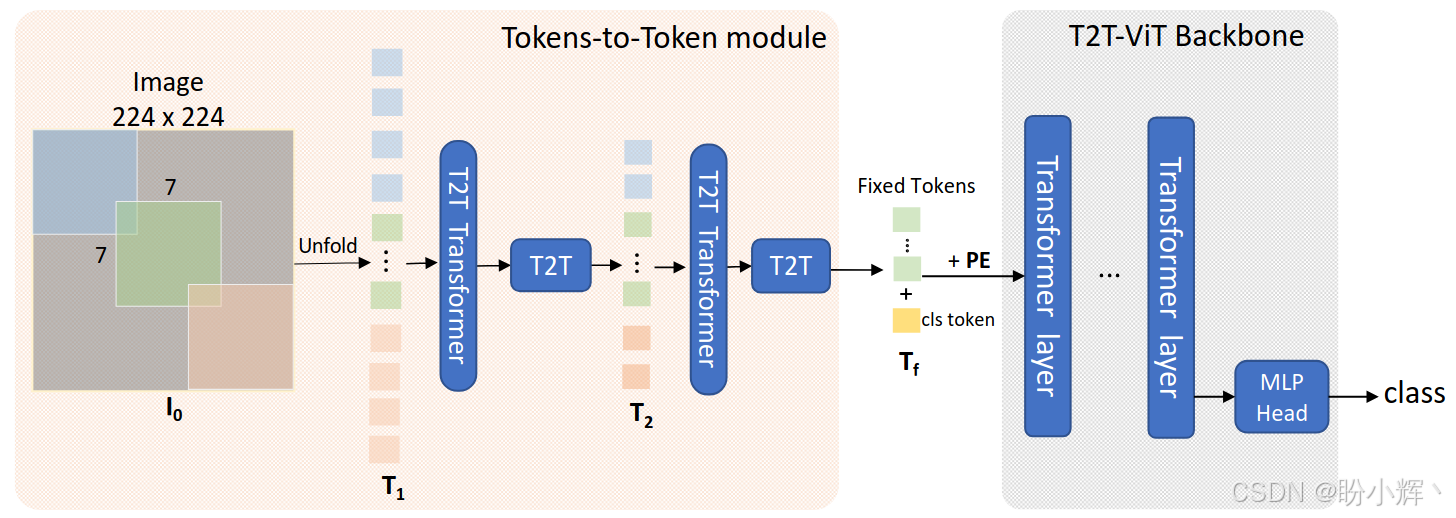
2.2 网络架构
借鉴卷积神经网络架构优化 ViT 主干,相比 ViT 的宽浅设计(如 12层×768维),T2T-ViT 采用深窄 (Deep-Narrow) 结构(如 24层×384维),减少通道冗余并增强特征复用;采用通道注意力 (Channel Attention),在 Transformer Block 中引入 SE (Squeeze-Excitation) 模块,增强特征选择能力。T2T-ViT 包含两部分:
-
T2T模块:输入224×224图像,经过3次Soft Split(kernel=[7,3,3], stride=[4,2,2]) 和2次Re-structurization,输出14×14的token网格(长度196) -
Backbone:深窄Transformer堆叠+分类头
3. 实现 T2T-ViT 模型
接下来,我们将使用 PyTorch 从零开始实现 T2T-ViT 模型,并在 CIFAR-100 数据集上进行训练。
3.1 实现 T2T 模块
(1) 首先导入所需模块:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
import math(2) 实现标准的位置编码,添加位置信息到 token 嵌入:
python
class PositionalEncoding(nn.Module):
def __init__(self, dim, dropout=0.1, max_len=5000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, dim, 2) * (-math.log(10000.0) / dim))
pe = torch.zeros(max_len, dim)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(1)]
return self.dropout(x)(3) 实现标准的多头注意力机制:
python
class MultiHeadAttention(nn.Module):
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), qkv)
dots = torch.einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = dots.softmax(dim=-1)
out = torch.einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)(4) 实现 Transformer 中的前馈网络:
python
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)(5) 实现 T2T 模块,逐步重构 token,返回重构后的 token 序列和 token 数量:
python
class T2TModule(nn.Module):
def __init__(self, img_size=224, tokens_type='transformer', in_chans=3, embed_dim=768, token_dim=64):
super().__init__()
if tokens_type == 'transformer':
print('adopt transformer encoder for tokens-to-token')
self.soft_split0 = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
self.soft_split1 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.soft_split2 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.attention1 = TokenTransformer(dim=in_chans * 7 * 7, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.attention2 = TokenTransformer(dim=token_dim * 3 * 3, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.project = nn.Linear(token_dim * 3 * 3, embed_dim)
elif tokens_type == 'performer':
raise NotImplementedError("performer not implemented")
else:
raise NotImplementedError("T2T type not recognized")
self.num_patches = (img_size // (4 * 2 * 2)) * (img_size // (4 * 2 * 2))
def forward(self, x):
# 第一次soft split
x = self.soft_split0(x).transpose(1, 2) # [B, C, H, W] -> [B, num_patches, C*kernel_size^2]
x = self.attention1(x)
B, new_HW, C = x.shape
x = x.transpose(1, 2).reshape(B, C, int(math.sqrt(new_HW)), int(math.sqrt(new_HW)))
# 第二次soft split
x = self.soft_split1(x).transpose(1, 2)
x = self.attention2(x)
B, new_HW, C = x.shape
x = x.transpose(1, 2).reshape(B, C, int(math.sqrt(new_HW)), int(math.sqrt(new_HW)))
# 第三次soft split
x = self.soft_split2(x).transpose(1, 2)
x = self.project(x)
return x, self.num_patches(6) 定义 Token Transformer 模块,用于 T2T 模块中的 token 重构:
python
class TokenTransformer(nn.Module):
def __init__(self, dim, in_dim, num_heads=1, mlp_ratio=1.):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = MultiHeadAttention(dim, heads=num_heads, dim_head=dim//num_heads)
self.norm2 = nn.LayerNorm(dim)
self.mlp = FeedForward(dim, int(dim * mlp_ratio))
self.proj = nn.Linear(dim, in_dim)
def forward(self, x):
x = self.norm1(x)
x = x + self.attn(x)
x = self.norm2(x)
x = x + self.mlp(x)
x = self.proj(x)
return x(7) 定义 Transformer 编码器模块,返回编码后的 token 序列:
python
class TransformerEncoder(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
nn.LayerNorm(dim),
MultiHeadAttention(dim, heads=heads, dim_head=dim_head, dropout=dropout),
nn.LayerNorm(dim),
FeedForward(dim, mlp_dim, dropout=dropout)
]))
def forward(self, x):
for norm1, attn, norm2, ff in self.layers:
x = norm1(x)
x = x + attn(x)
x = norm2(x)
x = x + ff(x)
return x(8) 定义完整的 T2T-ViT 模型,使用分类 token 进行分类,返回分类 logits:
python
class T2TViT(nn.Module):
def __init__(self, img_size=224, tokens_type='transformer', in_chans=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4., token_dim=64):
super().__init__()
self.t2t = T2TModule(
img_size=img_size,
tokens_type=tokens_type,
in_chans=in_chans,
embed_dim=embed_dim,
token_dim=token_dim
)
self.pos_embedding = PositionalEncoding(embed_dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim))
self.transformer = TransformerEncoder(
dim=embed_dim,
depth=depth,
heads=num_heads,
dim_head=embed_dim // num_heads,
mlp_dim=int(embed_dim * mlp_ratio),
dropout=0.
)
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
# 初始化权重
self.apply(self._init_weights)
def _init_weights(self, m):
"""初始化模型权重"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Parameter):
nn.init.normal_(m, std=0.02)
def forward(self, x):
# 通过T2T模块获取token
x, num_patches = self.t2t(x) # [B, num_patches, embed_dim]
b, n, _ = x.shape
# 添加分类token
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
x = torch.cat((cls_tokens, x), dim=1)
# 添加位置编码
x = self.pos_embedding(x)
# 通过Transformer编码器
x = self.transformer(x)
# 使用分类token进行分类
x = self.norm(x)
cls_token = x[:, 0]
return self.head(cls_token)3.2 模型训练
接下来,使用 CIFAR-100 数据集训练 T2T-ViT 模型。
(1) 加载 CIFAR-100 数据集:
python
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
def get_cifar100_dataloaders(batch_size=128):
# 数据增强和归一化
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomApply([
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.RandomApply([
transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 0.2))
], p=0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5071, 0.4867, 0.4408], std=[0.2675, 0.2565, 0.2761])
])
val_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5071, 0.4867, 0.4408], std=[0.2675, 0.2565, 0.2761])
])
# 加载CIFAR-100数据集
train_dataset = torchvision.datasets.CIFAR100(
root='./data',
train=True,
download=True,
transform=train_transform
)
val_dataset = torchvision.datasets.CIFAR100(
root='./data',
train=False,
download=True,
transform=val_transform
)
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4,
pin_memory=True
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=4,
pin_memory=True
)
return train_loader, val_loader(2) 调整 T2T 模块参数以适应小图像:
python
class T2TViTForCIFAR100(nn.Module):
def __init__(self, img_size=32, tokens_type='transformer', in_chans=3, num_classes=100,
embed_dim=384, depth=7, num_heads=6, mlp_ratio=3., token_dim=64):
super().__init__()
self.t2t = T2TModule(
img_size=img_size,
tokens_type=tokens_type,
in_chans=in_chans,
embed_dim=embed_dim,
token_dim=token_dim
)
self.pos_embedding = PositionalEncoding(embed_dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim))
self.transformer = TransformerEncoder(
dim=embed_dim,
depth=depth,
heads=num_heads,
dim_head=embed_dim // num_heads,
mlp_dim=int(embed_dim * mlp_ratio),
dropout=0.1 # 增加dropout防止过拟合
)
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, num_classes)
# 初始化权重
self.apply(self._init_weights)
def _init_weights(self, m):
"""初始化模型权重"""
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Parameter):
nn.init.normal_(m, std=0.02)
def forward(self, x):
# 通过T2T模块获取token
x, _ = self.t2t(x) # [B, num_patches, embed_dim]
b, n, _ = x.shape
# 添加分类token
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
x = torch.cat((cls_tokens, x), dim=1)
# 添加位置编码
x = self.pos_embedding(x)
# 通过Transformer编码器
x = self.transformer(x)
# 使用分类token进行分类
x = self.norm(x)
cls_token = x[:, 0]
return self.head(cls_token)(3) 训练模型:
python
from matplotlib import pyplot as plt
def train_cifar100():
# 初始化模型 - 使用更小的架构以适应CIFAR-100
model = T2TViTForCIFAR100(
img_size=32,
tokens_type='transformer',
in_chans=3,
num_classes=100,
embed_dim=384,
depth=7,
num_heads=6,
mlp_ratio=3.,
token_dim=64
)
# 获取数据加载器
train_loader, val_loader = get_cifar100_dataloaders(batch_size=128)
# 训练参数
device = 'cuda' if torch.cuda.is_available() else 'cpu'
epochs = 200
lr = 5e-4
weight_decay = 0.05
# 损失函数和优化器
criterion = LabelSmoothingCrossEntropy(smoothing=0.1)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=weight_decay)
# 学习率调度器 - 带预热的余弦退火
warmup_epochs = 10
warmup_steps = warmup_epochs * len(train_loader)
total_steps = epochs * len(train_loader)
scheduler = WarmupCosineSchedule(optimizer, warmup_steps=warmup_steps, total_steps=total_steps)
# 混合精度训练
scaler = torch.amp.GradScaler('cuda')
# 训练循环
best_acc = 0.0
history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
model = model.to(device)
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
with torch.amp.autocast('cuda'):
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
scheduler.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
train_loss /= len(train_loader)
train_acc = 100. * correct / total
# 验证阶段
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
val_loss /= len(val_loader)
val_acc = 100. * correct / total
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
# 打印日志
print(f'Epoch {epoch+1}/{epochs}:')
print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')
print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'best_t2t_vit_cifar100.pth')
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Train Loss')
plt.plot(history['val_loss'], label='Val Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Train Acc')
plt.plot(history['val_acc'], label='Val Acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.show()
print(f'Training complete. Best Val Acc: {best_acc:.2f}%')
train_cifar100()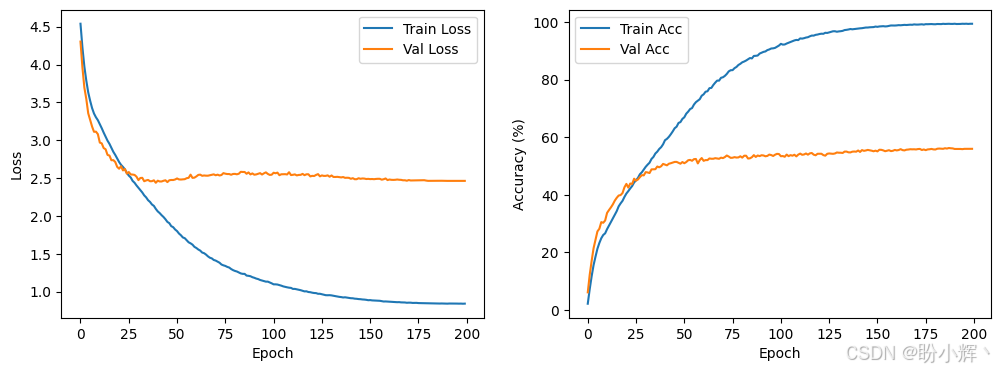
(4) 如果使用大尺寸图像进行训练,可以按照以下代码进行调整:
python
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
def get_dataloaders(data_dir='./data', batch_size=32):
# 数据增强和归一化
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
train_dataset = torchvision.datasets.ImageFolder(
root=data_dir + '/train',
transform=train_transform
)
val_dataset = torchvision.datasets.ImageFolder(
root=data_dir + '/val',
transform=val_transform
)
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4,
pin_memory=True
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=4,
pin_memory=True
)
return train_loader, val_loader
def train_model(model, train_loader, val_loader, epochs=50, lr=1e-4, device='cuda'):
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs)
best_acc = 0.0
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
train_loss /= len(train_loader)
train_acc = 100. * correct / total
# 验证阶段
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
val_loss /= len(val_loader)
val_acc = 100. * correct / total
# 更新学习率
scheduler.step()
# 打印日志
print(f'Epoch {epoch+1}/{epochs}:')
print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')
print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'best_t2t_vit.pth')
print(f'Training complete. Best Val Acc: {best_acc:.2f}%')
def main():
# 初始化模型
model = T2TViT(
img_size=224,
tokens_type='transformer',
in_chans=3,
num_classes=1000, # 根据实际数据集调整
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4.,
token_dim=64
)
# 获取数据加载器
train_loader, val_loader = get_dataloaders(batch_size=32)
# 训练模型
train_model(model, train_loader, val_loader, epochs=50, lr=1e-4)相关链接
视觉Transformer实战------Transformer详解与实现
视觉Transformer实战------Vision Transformer(ViT)详解与实现