GPU-Initiated Networking for NCCL(面向NCCL的GPU主动网络技术)
摘要
现代AI工作负载,尤其是混合专家模型架构,日益需要低延迟、细粒度的GPU到GPU通信以及设备端控制能力。传统的GPU通信遵循主机发起模型,即CPU负责协调所有通信操作------这是CUDA运行时的典型特征。尽管该模型在集合操作方面表现稳健,但对于需要紧密集成计算与通信的应用程序而言,能够消除CPU协调开销的设备发起式通信将大有裨益。
NCCL 2.28引入了设备API,提供三种操作模式:适用于NVLink/PCIe的加载/存储可访问模式,适用于NVLink SHARP的多内存模式,以及适用于网络RDMA的GPU主动网络模式。本文介绍了GIN的架构、设计、语义,并重点阐述了其对MoE通信的影响。GIN构建于三层架构之上:i) 用于创建设备通信器和注册集体内存窗口的NCCL核心主机端API;ii) 可从CUDA内核调用的、用于远程内存操作的设备端API;iii) 具有双重语义(GPU直接异步内核发起和代理)的、用于广泛硬件支持的网络插件架构。GPU直接异步内核发起的后端利用DOCA GPUNetIO实现GPU到网卡的直接通信,而代理后端则通过基于标准RDMA网络的无锁GPU到CPU队列提供同等功能。我们通过将其与MoE通信库DeepEP集成,展示了GIN的实用性。全面的基准测试表明,GIN在NCCL的统一运行时内提供了设备发起的通信,将低延迟操作与NCCL的集体算法和生产基础设施相结合。
索引术语 ---NCCL Device API, GPU-Initiated Networking, Load/Store Accessible, Multimem, RDMA, One-Sided Communication, Device-Initiated Communication, DeepEP
NCCL设备API, GPU主动网络, 加载/存储可访问, 多内存, RDMA, 单边通信, 设备发起通信, DeepEP
一、引言
大语言模型的快速发展对GPU通信库提出了新的性能需求。现代AI工作负载不仅需要传统的集合通信:它们需要用于推理令牌生成的低延迟点对点操作 1, 2,用于混合专家模型架构的自定义通信模式 3,以及编译器生成的内核中计算与通信的紧密集成 4, 5。这些工作负载受益于GPU直接发起和控制网络通信而无需CPU参与。
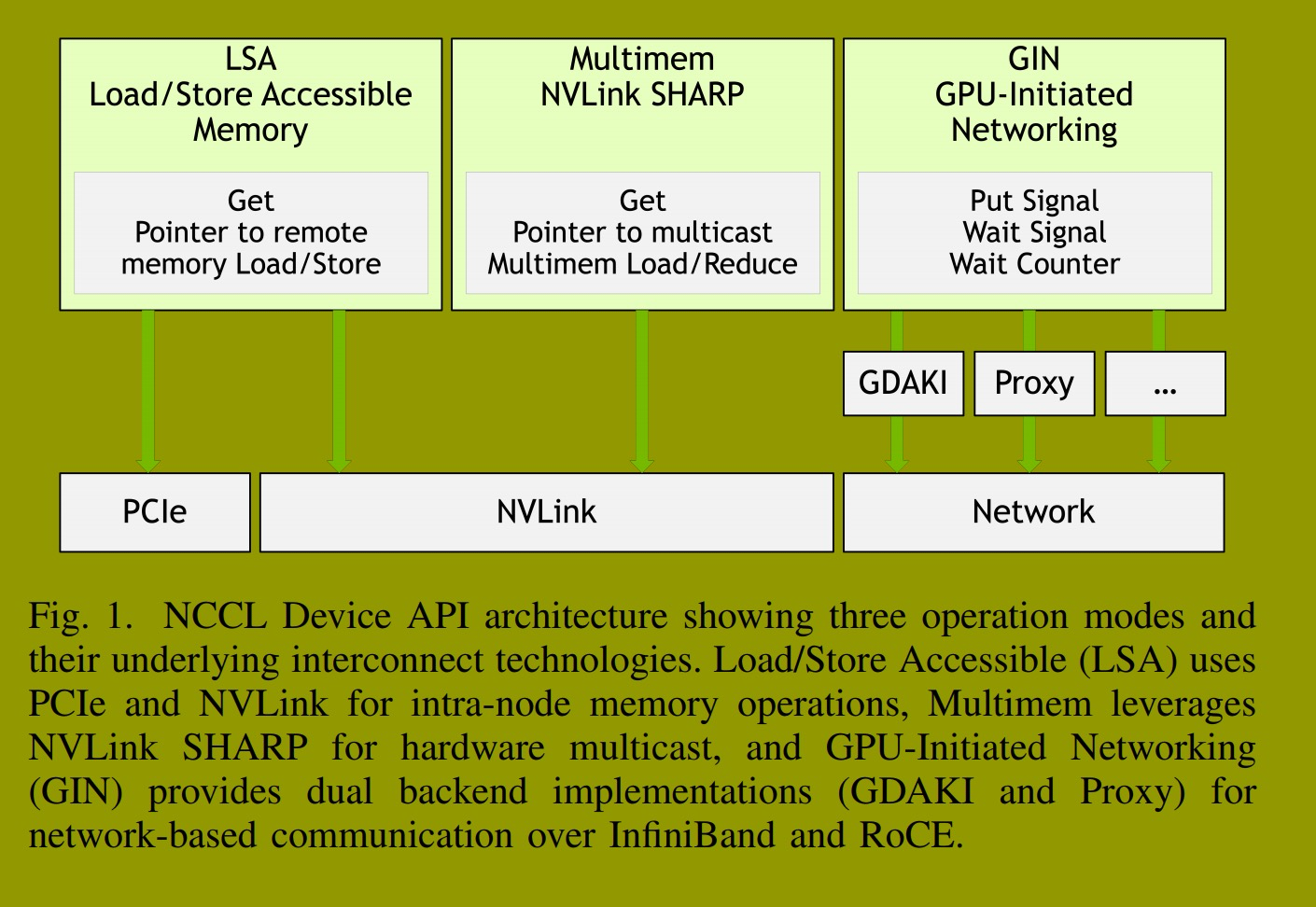
NCCL 6 已成为基于GPU的机器学习事实上的通信运行时,为分布式训练和推理提供了优化的集体算法和稳健的基础设施。传统的GPU通信遵循主机发起模型,CPU负责协调所有通信操作。这种方法需要显式的主机-设备同步------这是CUDA运行时模型的特性------并且每个通信调用都需要单独的内核启动。虽然该模型在大规模集合操作中已被证明是稳健的,但需要紧密集成计算与通信的应用程序------例如MoE推理中的动态令牌路由 3、JAX 5 和 Triton 4 内核中编译器生成的通信------需要设备发起的通信,以消除基于CUDA的主机端同步带来的CPU协调开销。另一方面,NVSHMEM库 7, 8 已成功证明了GPU直接异步内核发起能力的可行性和性能影响,它提供了为AI工作负载实现通信与计算融合的设备原语。
为了满足现代AI工作负载对计算与通信紧密集成的需求,NCCL 2.28引入了设备API 9,使GPU能够直接从内核内部发起通信操作。设备API支持三种设备发起通信的操作模式(图1):用于通过NVLink和PCIe在节点内使用内存加载/存储操作进行通信的加载/存储可访问模式,用于通过NVLink SHARP进行硬件多播的多内存模式,以及用于通过InfiniBand和RoCE网络进行节点间通信的GPU主动网络模式。本文重点介绍GIN,它使GPU能够在GPU内核内直接发起网络操作。GIN提供了用于单边操作的设备端API,允许CUDA内核执行远程内存操作、点对点同步以及完全在设备代码中轮询完成。具备GIN功能的NCCL设备API为AI工作负载提供了低延迟原语、融合和定制机会,同时使这些应用程序能够利用NCCL现有的基础设施,例如用于大规模生产部署的分层通信器、弹性和容错机制。
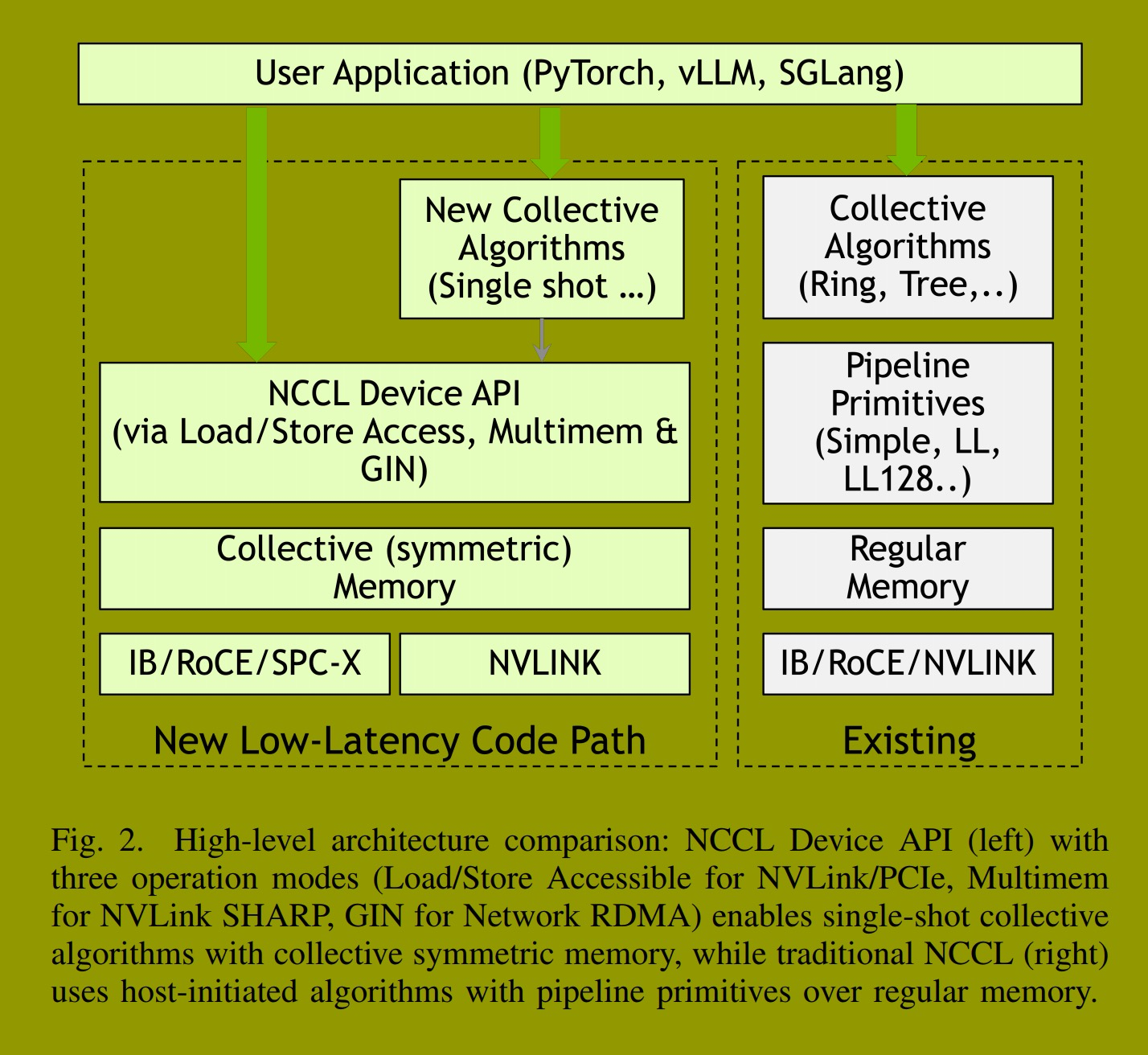
图2比较了NCCL设备API架构与传统的宿主发起的NCCL。应用程序(PyTorch 10, TRT-LLM 1, vLLM 2, SGLang 11)既可以使用NCCL提供的、使用设备API实现的单次集体算法,也可以直接调用设备API原语在GPU内核中实现自定义通信模式。设备API在集体对称内存上操作,这与传统NCCL使用基于常规内存的流水线原语(Simple, LL, LL128)的宿主发起集合操作形成对比。
GIN通过三层架构实现这一点:i) 扩展NCCL核心的主机端API,用于通信器初始化、GIN资源管理和集体内存窗口注册;ii) 设备端API,公开了可直接从CUDA内核调用的、用于远程内存操作的放置/信号原语,并具有灵活的完成语义;iii) 可插拔网络后端架构,支持通过DOCA GPUNetIO的直接GPU到网卡通信(GDAKI后端)和通过无锁队列的CPU辅助操作(代理后端)。通过提供硬件直接和CPU辅助两种插件接口,GIN在多样化的部署场景中提供功能,同时保持与NCCL现有生态系统的兼容性。与典型的分层架构不同,GIN通过编译时优化和直接硬件访问引入了最小的开销。
A. GIN关键设计要素
GIN的设计和实现包含几个关键的技术要素:
i) 设备API设计。GIN提供了一个设备端API,支持灵活的合作模型(线程级和线程束级集体操作),具有针对小型内联值的优化原语、基于字节偏移的窗口内存寻址,以及灵活的本地(刷新和计数器)和远程完成(信号)机制。这允许应用程序表达自定义通信模式,并在内核内将通信与计算融合。
ii) 双重插件架构。NCCL GIN实现了两种插件架构:GDAKI接口利用DOCA GPUNetIO后端使GPU线程能够通过设备动词直接编程InfiniBand/RoCE网卡,而代理接口使用带有64字节描述符的无锁GPU到CPU队列,在任何支持RDMA的网卡上启用GIN功能。
iii) 同步机制。GIN提供本地和远程完成通知原语:信号(用于远程通知)和计数器(本地完成跟踪)。这些原语通过基于线程作用域注解的自动栅栏插入与CUDA的内存模型集成。
iv) 内存管理 。GIN使用集体窗口注册(ncclCommWindowRegister),其中每个节点提供一个本地缓冲区,并接收包含所有对等节点远程密钥的句柄,从而实现零拷贝单边操作。
B. 贡献
总之,这项工作的主要贡献是:
i) 在NCCL中设计和实现了GIN,包括统一的主机和设备API、用于异步完成的模块化同步原语(信号和计数器),以及两种可互换的后端架构:使用DOCA GPUNetIO进行直接GPU到网卡通信的GDAKI后端,和基于标准RDMA的CPU辅助操作的代理后端。
ii) 与专门的MoE通信库DeepEP集成,展示了GIN的实际适用性以及与现有基于NVSHMEM的设备发起通信的兼容性。
iii) 使用微基准测试和DeepEP内核的应用级实验对GIN进行了全面的性能评估,并通过比较分析确立了其性能特征。
本文的其余部分组织如下。第二节提供了GPU通信的背景知识并阐述了GIN的需求动机。第三节介绍了GIN的架构、设计原则、设备端API语义和实现------包括三层设计以及GDAKI和代理后端,同时介绍了同步原语和内存管理。第四节描述了GIN与DeepEP的集成,展示了其在动态MoE工作负载中的实际应用。第五节通过在多节点GPU集群上的微基准测试和DeepEP中的应用级基准测试评估了GIN的性能。第六节回顾了GPU直接通信和单边编程模型的相关工作。第七节总结了GIN的经验教训和未来方向。
二、背景
像 OpenSHMEM 这样的传统通信库在对称内存区域上提供了单边原语(放置、获取、原子操作),实现了无需发送者-接收者协调的异步数据移动 12。然而,这些规范假设的是以 CPU 为中心的执行模式,所有通信原语均从主机代码调用。GPU 集成到 HPC 系统中暴露了该模型的低效性:细粒度的 GPU 到 GPU 通信会产生内核启动开销、需要通过主机内存中转数据的 PCIe 传输以及 CPU 调度延迟 13。这些瓶颈推动了支持直接从 CUDA 内核进行设备发起通信的 GPU 感知扩展 13, 14。
A. GPU直接技术
GPU直接 RDMA(2013)15, 16 使支持 RDMA 的网络接口能够通过 PCIe 基地址寄存器 映射直接访问 GPU 内存,从而在节点间传输的数据路径中消除了 CPU 和主机内存。网卡的 DMA 引擎执行到 GPU BAR 的 PCIe 点对点事务,访问通过 nvidia_p2p 内核模块注册的内存区域。然而,GPU直接 RDMA 仅在内核边界提供一致性保证。GPU 内存模型语义(宽松排序、写回缓存)阻止了从正在执行的内核安全地并发访问 RDMA 注册的内存,迫使应用程序分离计算和通信 17。
GPU直接异步(2016)18 引入了部分控制路径卸载:GPU 线程通过写入已内存映射到 GPU 地址空间的网卡门铃寄存器来触发预配置的网络操作。然而,CPU 必须预先构建通信描述符,将操作限制在主机预配置的范围内,从而阻碍了完全自主的设备驱动网络。
B. 设备发起通信原语
完全的设备发起网络需要在 GPU 代码中直接实现网络编程接口。早期的原型如 GPUrdma 19 和 GIO 17 将 InfiniBand 动词暴露为设备可调用函数,但面临着 GPU-网卡内存一致性的挑战。
NVSHMEM 8 将 OpenSHMEM 语义扩展到 GPU 集群,提供了可从 CUDA 内核调用的设备可调用单边操作(放置、获取、原子操作)。这使得设备代码能够交织进行计算和通信,而无需内核启动开销,它使用的传输后端包括用于节点间传输的 IBGDA(支持 GPU直接异步的 InfiniBand)和用于节点内通信的对称内存机制。
DOCA GPUNetIO 为 InfiniBand 和 RoCE 网络提供了 GPU 端 RDMA API(IBGDA),暴露了使 GPU 内核能够直接对网卡进行编程的设备函数 20。具体来说,它实现了 GPU直接 RDMA(直接的 GPU 数据移动)和 GPU直接异步内核发起(GPU 控制网络通信)技术。它构成了 GIN 的 GDAKI 后端的基础,通过硬件支持的设备动词实现直接的 GPU 到网卡通信。
C. 用于 GPU 发起通信的网络硬件
GPU 发起的网络需要支持通过以下几种 RDMA 技术之一进行直接设备访问的网络接口卡:InfiniBand、RoCE 或 iWARP 21。
InfiniBand 提供本机 RDMA 支持,并具有基于信用的流量控制,可实现约 130 纳秒的端口到端口延迟,并支持每个子网数万个节点 22。InfiniBand 适配器通过 PCIe BAR 暴露内存映射的队列对、完成队列和门铃寄存器,当与 GPU直接 RDMA 结合使用时,可实现直接的 GPU 访问 13, 15。
RoCE 在标准以太网上实现 RDMA,提供了更低的成本以及与现有数据中心基础设施更广泛的兼容性 21, 22。RoCEv2 是流行的变体,它在 UDP/IP 上封装了 InfiniBand 传输层,实现约 400 纳秒的端口到端口延迟------高于本机 InfiniBand,但对许多工作负载来说已足够 22。RoCE 需要使用优先级流量控制 和显式拥塞通知 的无损以太网配置来防止数据包丢失,这可能会在多租户环境中使部署复杂化 22。InfiniBand 和 RoCE 共享相同的用户空间动词 API,实现了互连的可移植性 21。
对于 GPU 发起的通信,硬件要求是网卡支持设备可访问的控制结构。NVIDIA ConnectX 系列适配器(ConnectX-6 Dx 及更高版本)和 BlueField DPU 通过 DOCA GPUNetIO 提供了此能力 20。缺乏此类硬件支持的系统无法启用直接的 GPU-网卡通信,必须回退到 CPU 中介的机制。在 GIN 的架构中,这一限制催生了双后端设计:GDAKI 后端在受支持的硬件上利用 DOCA GPUNetIO 进行直接设备通信,而代理后端通过无锁 GPU 到 CPU 队列和 CPU 驱动的网络操作,在任何支持 RDMA 的网卡上提供功能等效的语义。
最佳性能要求将 GPU 和网卡放置在同一个 PCIe 根复合体上,以最小化点对点延迟并最大化带宽 15, 23。具有分布式 PCIe 拓扑的多插槽系统可能会产生跨插槽遍历的开销,降低 GPU直接 RDMA 的效率。此外,GPU 发起的网络需要 nv_peer_mem 内核模块(用于 GPU直接 RDMA)和适当的驱动程序栈(用于 InfiniBand 的 OFED,用于 Mellanox 适配器的 MOFED)来建立 GPU 和网卡地址空间之间的内存映射 23。
D. NCCL 架构与网络插件
NCCL 是多 GPU 机器学习标准的集体通信运行时,提供了支持拓扑感知的全规约、全收集、规约散播和广播操作的实现 24。NCCL 的架构使用 CPU 代理线程来协调网络操作,其中 GPU 内核将通信描述符入队到主机可见的队列中,CPU 线程通过网络插件执行它们。虽然该设计已被证明在大规模集体操作中非常稳健,但 NCCL 2.28 的设备 API 9 使用设备端原语扩展了此架构,使应用程序能够直接从 GPU 代码实现自定义通信模式、将通信集成到计算内核中,并为新兴工作负载实现细粒度的计算-通信重叠。
NCCL 在生产框架中的广泛采用推动了这种设备发起通信能力的集成,在支持新用例的同时保留了生态系统兼容性。
NCCL 网络插件架构提供了一个抽象层,将核心库与特定的网络实现解耦。NCCL 同时支持直接内置在库中的内部插件(例如,Socket 和 InfiniBand),以及将 NCCL 网络 API 实现为共享库(libnccl-net.so)的外部插件。这种设计允许网络供应商和硬件提供商使用专门的传输实现来扩展 NCCL,而无需修改 NCCL 核心。外部插件在运行时动态加载,通过 NCCL_NET_PLUGIN 环境变量选择,从而能够无缝集成各种网络技术,同时通过版本化的 API 接口保持版本兼容性。
E. 专用 MoE 通信库
LLM 中的 MoE 架构需要具有不可预测消息大小的动态、负载均衡的全到全令牌路由,这产生了传统集体操作 25 不太适合处理的不规则通信模式。像 DeepEP 26 和 Perplexity 的 pplx-kernels 27 这样的专用库针对这些工作负载,提供了经过 CUDA 优化的、GPU 发起的原语,用于低延迟的全到全传输。这些努力证明了以 GPU 为中心的通信对于 MoE 工作负载的价值,但仍然独立于 NCCL 的生态系统。
GIN 将 GPU 发起的 RDMA 操作引入 NCCL,使应用程序能够在统一的运行时内同时利用主机优化的集体操作和设备驱动的点对点通信。
基于这些设备发起的网络技术和 NCCL 的插件架构,下一节将介绍 GIN 的设计与实现。
三、NCCL GIN:GPU主动网络
本节介绍NCCL中GIN的设计与实现。如第二节所述,使用设备端原语扩展NCCL使得现代AI工作负载能够实现计算与通信的紧密耦合。GIN通过将设备发起的单边原语集成到NCCL中来提供此能力,允许GPU线程直接从CUDA内核发起网络操作,无需CPU参与。
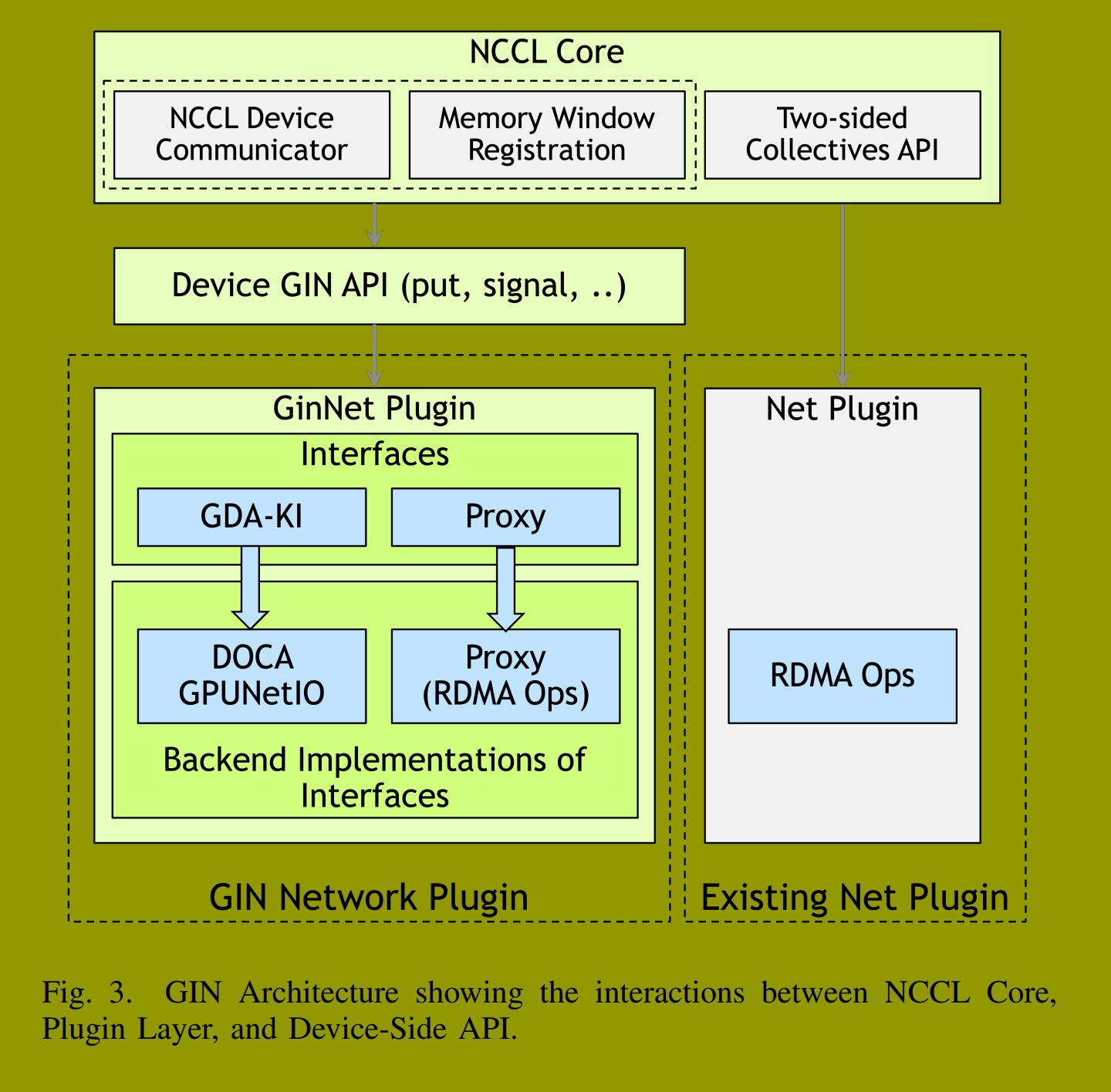
该设计在保留NCCL既定编程模型和生态系统集成的同时,为设备驱动的通信增加了一条并行的低延迟路径。这使得像TensorRT-LLM、vLLM和SGLang这样的生产系统,以及像DeepEP这样的通信库,能够实现传统NCCL无法实现的定制集体算法和内核融合模式。
我们分三部分组织本节:第III-A部分介绍三层架构和核心设计原则;第III-B部分介绍设备端API并通过一个实际示例演示其用法;第III-C部分分析两个插件接口及其后端实现(GDAKI和Proxy),解释它们的设计原理和性能特征。
A. 核心原则与架构
NCCL GIN的架构构建于单边通信语义之上,旨在实现两个关键性能目标:最大的通信-计算重叠和最小的端到端操作延迟。通过使GPU线程能够直接发起RDMA操作------无需接收者协调即可读写远程内存------GIN消除了主机-设备同步开销和双向握手延迟,允许异步数据传输与计算并发进行。
该架构包含三个为GIN协同工作的层------如图3的绿色路径(左侧)所示------旨在平衡高性能与广泛的供应商支持:NCCL核心(主机端API)、设备GIN API(GPU可调用原语)和GIN网络插件(可插拔网络后端)。图3的灰色路径(右侧)显示了基于内置网络插件的现有双向集合API。我们进一步讨论这三个GIN层:
i) NCCL核心 :主机端的NCCL功能管理内存窗口注册、资源分配和通信器初始化,为GIN资源管理提供基础,并通过设备发起通信能力扩展NCCL现有基础设施;
ii) 设备GIN API :设备端API向GPU内核暴露统一接口,使应用程序能够直接从CUDA内核调用单边通信操作。它根据底层网络后端,分派到NCCL提供的(Proxy)或插件提供的(GDAKI)实现;
iii) GIN网络插件 :插件层提供了一种可扩展机制,定义了远程数据移动操作并支持双重语义------GDAKI和Proxy------以最大化网络覆盖范围。NCCL的InfiniBand传输同时实现了这两者,而外部供应商可以提供自己的实现。在Proxy接口下,NCCL核心拥有控制结构、设备端排队逻辑和设备API实现,而插件仅提供基于CPU的放置、信号、测试和注册内存区域操作,从而支持不具备GPU直接能力的网络,并降低了GIN的采用门槛。在GDAKI语义下,插件拥有控制路径和设备API:它们通过createContext创建GPU上下文,并提供使用内核发起API(如DOCA GPUNetIO)直接对网卡进行编程的设备代码,NCCL核心则协调主机和设备组件之间的结构交换。
这些组件通过几个关键设计元素实现了设备发起的单边通信:用于单边数据移动的单边语义、用于零拷贝远程访问的对称内存窗口,以及具有灵活排序语义的异步完成跟踪。
单边通信语义 。GIN暴露了单边RDMA原语------用于远程写入的put和用于附带远程通知的写入的put with signal------使GPU线程能够访问远程内存而无需任何接收者协调。这种单边模型消除了握手协议的开销以及接收者参与的需要,允许发起者单方面发起传输并独立控制何时验证完成。单边模型被证明对于MoE工作负载中的不规则通信模式(动态令牌路由会产生不可预测的流量模式)以及受益于并行、非阻塞对等通信的单次集体实现特别有效。
基于窗口的(非)对称内存。通信缓冲区必须在所有节点间集体注册,建立地址可访问性对称的内存窗口,遵循MPI RMA窗口模型28。所有进程都可以访问已注册的内存,类似于NVSHMEM的对称堆。GIN窗口设计支持容量上的不对称:每个节点可以注册不同大小的缓冲区。这种灵活性对于分解式服务架构至关重要,其中预填充节点比解码节点需要更大的缓冲区。请注意,NCCL 2.28中的当前实现强制要求对称大小,但此限制将在未来版本中解除。此外,内存分配与注册不耦合:NCCL-GIN内存窗口允许用户从现有分配创建窗口。每次注册都会产生封装了远程访问元数据的窗口句柄。窗口句柄提供了后端特定的优化机会。后端可以直接使用窗口元数据和基于节点相对偏移的目标地址来构建RDMA描述符。
用于网络并行性的GIN上下文。GIN上下文是表达网络并行性的主要抽象。每个上下文抽象了GPU和网卡之间的一个通道,并封装了网络资源和连接(队列对)。每个通信器拥有多个上下文使应用程序能够利用跨多个网卡、端口和QP的网络级并行性,允许独立的并发通信流。单个上下文可以寻址与该通信器关联的每个节点。因此,一个上下文可以向不同的对等节点发起多个并发操作。
异步完成跟踪 。所有设备发起的操作都异步执行并立即返回,以便其他工作(例如计算或通过NVLink的节点内通信)可以并行进行。应用程序使用每个上下文的资源通过两种不同的机制来跟踪操作完成。计数器 是本地对象,用于跟踪发送端的完成情况,指示源缓冲区何时可以安全地重用。与跟踪发布到上下文的所有操作完成的flush操作不同,计数器是一个强大的概念,用于跟踪每个操作的本地完成情况,允许用户有效地描述流水线算法。每个数据移动操作可以选择性地向用户提供的计数器(通过counterID)报告本地完成情况。
另一方面,信号(对称对象)提供远程完成跟踪,确认数据在目的地的到达和可见性。与OpenSHMEM基于地址的同步不同,GIN使用基于ID的寻址:每个信号(和计数器)由一个整数ID而非内存地址标识。这种基于ID的设计简化了资源管理,并实现了完成通知的高效硬件实现。
排序语义 。为了最大化网络效率和吞吐量,GIN操作默认是无序的。但是,GIN仅保证在同一上下文中发往同一对等节点的put和signal操作之间的顺序。当一个信号操作(独立的信号操作或带有ncclGin_SignalInc/ncclGin_SignalAdd信号动作的放置操作)在目的地完成时,它保证先前在同一上下文中发往该对等节点的所有放置操作都已完成并且对远程GPU线程可见。这提供了轻量级的排序,而无需显式的栅栏操作:应用程序可以批处理多个放置操作并在最终操作上附加一个信号,从而确保整个序列的有序远程可见性。相比之下,flush操作仅确保本地完成------所有挂起的操作已被消耗,源缓冲区可以安全地重用------但不保证远程可见性。GIN基于信号的排序旨在通过信号选择性地提供排序保证,而非全局性地提供,从而实现最佳性能。值得注意的是,GIN不假定或保证GPU线程之间的任何顺序。用户有责任使用CUDA同步原语来同步线程。
B. 设备端API与编程模型
设备端API为GPU内核提供了对网络操作的直接控制,暴露了可从CUDA设备代码调用而无需CPU干预的方法。该编程模型以ncclGin对象为核心,该对象封装了网络资源(上下文、操作队列和对等连接状态),并提供了数据移动、完成跟踪和同步的方法。后端选择(DOCA GPUNetIO或Proxy)在通信器初始化时根据硬件能力和用户配置透明地进行,无论底层实现如何,都呈现相同的面向设备的接口。
API组织 。该接口将操作分为四个反映通信工作流程的逻辑类别。数据移动操作 (put, putValue, signal)向远程对等节点发起单边传输或通知,提交异步执行的RDMA操作。完成跟踪操作 区分本地完成 (flush, readCounter, waitCounter)------表示源缓冲区可以安全重用------和远程完成 (readSignal, waitSignal)------确认数据已到达目的地并对远程GPU线程可见。屏障同步 (ncclGinBarrierSession)在通信阶段之前协调团队内的所有节点,通过网络范围的同步确保全局一致性。状态管理操作 (resetCounter, resetSignal)重置完成状态以便在多个通信轮次中重用。这种关注点分离使得能够对通信-计算重叠进行细粒度控制,并支持多种同步模式。
此外,GIN设备API与GPU内存模型紧密交互,并接受用户的提示以优化性能关键的内存排序和一致性任务。例如,put操作从用户那里获取两个提示:关于所提供数据的可见性范围,以及操作完成后预期的用户可见性。
使用工作流 。应用程序通过一个三阶段工作流(列表1)与GIN交互。在初始化 期间,应用程序在创建NCCL设备通信器时启用GIN支持(使用适当配置标志的ncclDevCommCreate),这将创建GIN上下文。然后,应用程序使用ncclCommWindowRegister集体注册内存缓冲区作为窗口,该函数返回用于设备代码的窗口句柄。在内核执行 期间,设备线程实例化一个指定了所需上下文索引(通常根据目标对等节点或负载均衡需求选择)的ncclGin对象,并发出数据移动操作,可选择性地附加完成动作,例如远程信号递增或本地计数器更新。最后,内核在重用缓冲区或进入后续计算阶段之前,通过等待信号或计数器来同步,确保通信和计算阶段的正确排序。列表1展示了NCCL GIN接口的简化视图,突出了基本操作。实际API包含用于高级用例(例如,协作线程组、内联数据传输)的额外模板参数和选项,但核心抽象保持一致。
cpp
class ncclGin {
// Constructor: initialize with device
// communicator and context ID
ncclGin(ncclDevComm comm, int contextIndex);
// Data Movement Operations
void put(team, peer, dstWindow, dstOffset,
srcWindow, srcOffset, bytes, ...);
void putValue(team, peer, dstWindow, dstOffset,
value, ...);
void signal(team, peer, signalId);
// Local Completion Tracking
void flush(coop); // Block until ops complete
uint64_t readCounter(counterId); // Poll counter
void waitCounter(coop, counterId, expectedValue);
void resetCounter(counterId); // Reset for reuse
// Remote Completion Tracking
uint64_t readSignal(signalId); // Poll signal
void waitSignal(coop, signalId, expectedValue);
void resetSignal(signalId); // Reset for reuse
};
// Network Barrier for cross-rank synchronization
class ncclGinBarrierSession {
ncclGinBarrierSession(coop, gin, team,
barrierHandle, index);
void sync(coop); // Global barrier sync
};
// Optional: Attach completion actions to data
// Remote signal
put(..., ncclGin_SignalInc{signalId});
// Local counter
put(..., ncclGin_CounterInc{counterId});列表1. 简化的NCCL GIN设备API。
使用示例 。列表2演示了使用GIN原语实现单向环状交换模式。在此内核中,每个节点在环状拓扑中向其后续节点发送数据,数据沿环单向流动,实现了流水线通信算法中的常见模式。put操作(第13-16行)将数据从本地sendWin传输到对等节点的recvWin的计算偏移处,并在完成时原子递增远程信号0,提供数据到达的远程通知。然后,发送节点等待其自身的信号0被其前驱节点递增(第19行),确保接收到的数据已到达并对本地GPU线程可见,然后才继续进行计算。最后,重置信号以供后续通信轮次使用(第21行)。此模式说明了GIN的异步操作、灵活的完成语义和显式同步原语如何能够从设备代码实现高效的重叠点对点通信。
cpp
1 __global__ void ringExchange(
2 ncclDevComm devComm,
3 ncclWindow_t sendWin,
4 ncclWindow_t recvWin,
5 size_t dataSize, int myRank)
6 {
7 // Initialize ctx 0
8 ncclGin gin(devComm, 0);
9 int peer = (myRank + 1) % devComm.nRanks;
10
11 // Send data to peer and signal completion
12 // by incrementing peer's signal
13 gin.put(ncclTeamWorld(devComm), peer,
14 recvWin, myRank * dataSize,
15 sendWin, peer * dataSize, dataSize,
16 ncclGin_SignalInc{0} );
17
18 // Wait for predecessor
19 gin.waitSignal(ncclCoopCta(), 0, 1);
20 // Reset for next round
21 gin.resetSignal(0);
22 }列表2. 使用NCCL GIN进行单向环状交换。
C. 后端(GDAKI与Proxy)实现
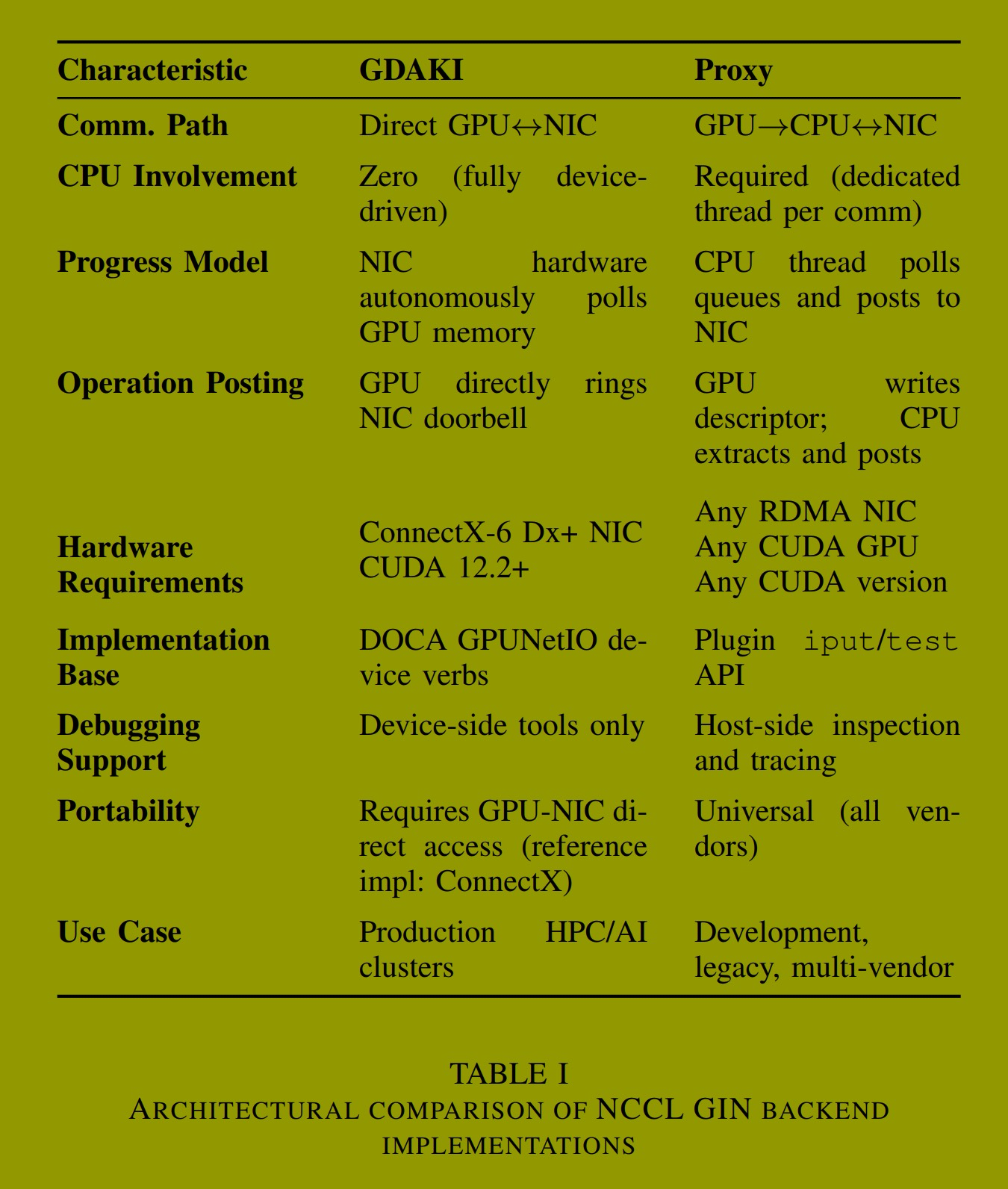
设备API抽象了两种不同的后端实现,它们实现了前面描述的双重插件语义。GDAKI后端 通过DOCA GPUNetIO实现直接的GPU到网卡通信,从而实现了GDAKI语义,该插件同时提供设备API和控制路径。Proxy后端通过CPU中介的传输实现Proxy语义,NCCL核心提供设备API,而插件仅提供基于CPU的数据路径操作。两个后端都暴露相同的面向设备的接口,从而能够在运行时透明地选择后端,而无需更改应用程序代码。
GDAKI后端:直接的GPU到网卡通信 。GDAKI后端通过利用DOCA GPUNetIO,以最纯粹的形式实现设备发起的网络,使GPU线程能够直接对网络接口卡进行编程,无需CPU参与。当内核调用put时,GPU线程在设备内存中构建RDMA工作队列条目,用源/目标地址和传输元数据填充它们,并直接写入网卡的门铃寄存器以触发DMA传输。网卡硬件自主管理操作进度:它轮询GPU内存以获取新的WQE,通过InfiniBand或RoCE执行RDMA事务,并在GPU可见内存中更新完成队列条目。这种直接的GPU-网卡路径消除了到CPU的PCIe往返,并为小消息实现了低延迟。然而,此方法需要现代的硬件和软件:具有GPU可访问控制结构的ConnectX-6 Dx或更新网卡,以及所需的CUDA 12.x版本(详见20)。此外,正确的系统配置------包括GPU直接RDMA内核模块(nv_peer_mem或dmabuf)以及共置的GPU-网卡PCIe拓扑------对于正确操作和最佳性能至关重要。
Proxy后端:CPU辅助通信 。Proxy后端以牺牲峰值性能为代价,换取硬件可移植性,方法是将CPU作为GPU和网卡之间的中介引入通信路径。GPU线程将操作描述符(64字节,包含源/目标窗口句柄、可能的源内联值、偏移量、大小和完成动作)使用"发射后不管"的存储操作入队到分配在CPU内存中的无锁队列。每个通信器有一个专用的CPU代理线程,固定在与本地节点GPU和网卡相近的NUMA节点上,持续轮询这些队列。当检测到新的描述符时,代理线程提取字段,并通过网络插件的iput/iput_signal接口提交网络操作,该接口映射到标准的InfiniBand动词或其他网络API。插件负责执行信号操作并确保所有先前放置操作的可见性。完成通知遵循相反的路径:代理线程使用网络插件的test接口轮询完成情况,将已完成的操作与其关联的GIN计数器匹配,并在GPU可见的内存(基于GDRCopy可用性,位于GPU或CPU)中更新完成状态。虽然这种CPU参与相比GDAKI引入了额外的延迟,但Proxy后端支持任意的CUDA版本、任何支持GPU直接RDMA的网卡(InfiniBand、RoCE、iWARP)以及Volta或更新的GPU。此外,CPU参与通过主机端检测简化了调试,并在无法使用直接GPU-网卡通信的系统上实现了优雅的性能降级。
后端选择与可移植性 。表I总结了GDAKI和Proxy后端之间的架构差异。拥有现代NVIDIA端到端网络基础设施(ConnectX-6 Dx或更新网卡、最新的CUDA版本、正确配置的GPU直接RDMA)的高性能生产系统倾向于使用GDAKI,以获得最小延迟和零CPU开销。开发环境、传统硬件部署、多供应商网络结构或GPU直接支持配置不当的系统则依赖Proxy以确保功能正确性和操作灵活性。运行时在通信器初始化期间(ncclCommInitRank)自动检测可用的后端,通过能力查询探测DOCA GPUNetIO支持,并在必要时回退到Proxy。应用程序可以通过环境变量(NCCL_GIN_BACKEND)覆盖此选择,以进行调试或性能调优。这种设计确保了跨不同部署场景的可移植性,同时在硬件和软件基础设施允许的情况下保留了直接GPU-网卡通信的性能优势。
四、DEEPEP 集成
本节介绍将 NCCL GIN 集成到 DeepEP 中,以验证其在需要计算-通信融合和低延迟的工作负载上的有效性。DeepEP 是一个专门的 MoE 通信库,它使用 NVSHMEM 和 IBGDA 实现设备发起的稀疏全交换通信------即分发和组合原语。该库提供两种风格的分发和组合原语:分别用于训练/推理-预填充阶段的高吞吐量内核和用于推理-解码阶段的低延迟内核。此集成演示了如何使用 GIN API 实现 DeepEP 的设备发起通信模式,同时保持性能特征并与现有的 NVSHMEM 通信后端共存。
A. 集成需求
DeepEP 的通信模式提出了几个要求:i) 高 QP 并行度 ------HT 内核需要 24 个 QP,而 LL 内核需要 8-16 个 QP 以匹配本地专家数量;ii) 异构拓扑支持 ------HT 使用具有 NVLink 转发的对称节点到节点 RDMA,而 LL 使用完整的全交换 RDMA 网格;iii) 细粒度同步 ------用于环形缓冲区流控制的头/尾指针原子更新;iv) 后端共存------NVSHMEM IBGDA 和 GIN 后端必须共存,以便根据执行环境匹配用户偏好。
B. 后端集成策略
集成采用了一个最小抽象层来处理生命周期管理(初始化、内存分配、屏障),同时允许性能关键的操作通过条件编译在内核中直接使用后端特定的设备 API。这种设计适应了基本的语义差异:IBGDA 使用基于指针的寻址和内存原子操作,而 NCCL GIN 使用基于窗口的寻址和信号原子操作。
集成解决了四个关键的转换挑战。首先,多通信器映射 :由于 NCCL GIN 每个通信器提供 4 个上下文,满足 DeepEP 的 QP 要求需要 ⌈QPs/4⌉ 个通信器,工作通过确定性选择进行分配(comm_id = id / 4, ctx_id = id % 4)。其次,内存管理 :后端将分配的缓冲区注册到所有通信器,并将设备可访问的窗口句柄存储在 GPU 内存中,使内核能够将指针运算转换为(窗口,偏移量)对。第三,同步 :预分配的结构化信号布局将基于内存的原子操作映射到信号原语(HT:每个通道两个信号用于头/尾;LL:每个专家一个信号)。第四,语义保留:带有原子信号的零字节放置操作模拟了释放-获取语义,确保在发出完成信号之前先前的传输是可见的。
C. 操作语义映射
从 NVSHMEM 迁移到 NCCL GIN 需要在不同的编程模型之间进行转换,同时保留通信语义。NVSHMEM 提供了一个 PGAS(分区全局地址空间)抽象,具有基于指针的寻址和基于内存的同步原语,而 NCCL GIN 遵循基于窗口的单边模型,具有基于信号的完成跟踪(先前在第三-B节中回顾过)。表 II 将 DeepEP 的通信模式映射到相应的 NVSHMEM 和 GIN 原语,突出了集成所需的关键语义转换。对于数据传输,内核动态计算窗口相对偏移,并根据通道或专家 ID 确定性选择通信器,实现跨 QP 的负载均衡。对于同步,基于信号的设计将数据移动与完成通知解耦:批量传输使用不带立即信号的 put(),随后是显式的 signal() 操作,该操作仅在所有先前操作完成后才原子更新远程计数器。这种模式通过网络原语而非内存排序来实现释放-获取语义,确保在信号到达完成时数据是可见的。
D. 高吞吐量内核集成
HT 内核针对大批次(4096 个令牌)使用分层通信进行优化。GPU 通过对称 RDMA 连接将数据发送到远程节点,然后这些节点通过 NVLink 将令牌转发到目标 GPU。这最小化了节点间流量,同时最大化节点内带宽。RDMA 缓冲区包含多个充当 QP 的通道,每个通道都有发送/接收缓冲区。头和尾指针跟踪缓冲区占用情况,提供环形缓冲区流控制。

分发内核为 SM 分配了专门的角色。奇数编号的 SM 充当发送器 (将令牌传输到远程节点)和 NVLink 接收器 (最终目的地),而偶数编号的 SM 充当转发器(接收 RDMA 令牌并通过 NVLink 转发它们)。这种专业化支持并发的双向通信。为了减少争用,数据/尾更新和头指针更新使用单独的通道,将工作分布到不同的通信器上。
遵循操作映射(表 II),每个 SM 角色使用基于信号的原子操作进行指针管理,并使用基于窗口的 put() 进行数据传输。远程尾信号使用 gin.signal(SignalAdd, 1) 递增,而头指针流控制依赖于通过 gin.readSignal(signal_id) 轮询本地头信号。数据传输使用单线程 NCCL GIN put(),后跟 __syncwarp() 以保留线程束集体语义。通知分发内核使用一个协调器 SM 来刷新所有写入 (gin.flush()),跨对称 RDMA 节点执行屏障,重置头/尾信号,并在开始主分发之前交换元数据。
组合内核镜像了分发内核的专业化分工,每个 SM 使用 25 个线程束。偶数编号的 SM 充当 NVLink 发送器 (将输入令牌分发到本地缓冲区)、RDMA 接收器 (将远程令牌与偏置项集成)和监控接收器进度的协调器 。奇数编号的 SM 充当 NVLink 和 RDMA 转发器 (合并本地令牌并将其转发到远程节点),并由相应的协调器监控转发器。操作映射与分发类似:转发器线程束使用单线程 put() 和 __syncwarp() 进行数据传输,使用 readSignal() 进行头指针轮询,以及使用 signal() 进行尾更新。接收器线程束使用 readSignal() 监控尾指针,而协调器线程束通过 signal() 更新头指针。
E. 低延迟内核集成
LL 内核针对小批次(1-128 个令牌)使用完整的全交换 RDMA 网格连接进行优化,实现直接的 GPU 到 GPU 通信。令牌流式传输嵌入了路由元数据,无需单独的通知阶段,从而最小化分发-组合周期时间。每个专家的信号分配提供了跨集群任何专家对之间的直接协调。
SM 分配使用每个 SM 上 G = ⌈N/S⌉ 个线程束组来分布专家,其中 N 是专家总数,S 是可用 SM 数量。每个 SM 通过 expert_idx = sm_id * G + warp_group_id 分配专家。在每个线程束组内,大多数线程束处理 FP8 量化和令牌发送,而一个计数线程束管理所有分配专家的专家计数和元数据。这种组织实现了跨数百个专家(例如,跨 132 个 SM,每个 SM 3 个线程束组,共 288 个专家)的高效并行化。
LL 内核利用混合 NVLink-RDMA 通信。对于每个令牌传输,内核通过自定义函数 nccl_get_p2p_ptr 检查 NVLink 可用性。如果可用,则使用线程束级内存操作直接复制令牌;否则,使用 NCCL GIN 的 put() 执行 RDMA 传输(表 II)。令牌首先从 PyTorch 张量复制到 RDMA 发送缓冲区,可选地在此阶段应用 FP8 量化。完成到目标的令牌传输后,一个计数线程束使用带有 SignalAdd 的零字节 put() 发送每个专家的令牌计数,确保所有先前的数据传输已完成并可见,然后才传递计数------这实现了后端集成策略中描述的释放-获取语义。接收器使用 gin.readSignal(signal_id) 进行轮询,直到令牌到达。
组合内核将专家输出路由回源节点,并进行加权规约。它使用相同的混合 NVLink-RDMA 方法,并可选地使用 LogFMT 压缩来减少数据量。传输专家输出后,标志信号使用结合了 SignalAdd 的零字节 put() 通知目的地,确保在接收器开始累加之前完成。接收器使用 TMA 加载线程束将专家输出获取到共享内存中,然后使用 FP32 的规约线程束应用 top-k 权重,最后转换为 BF16 输出。
五、性能评估
本节通过两种互补的方法评估 NCCL GIN 和 NVSHMEM。我们首先从点对点微基准测试(第五-A节)开始,以分离协议级性能特征,然后评估与生产级 MoE 通信库 DeepEP 版本 1.2.1 的集成。DeepEP 评估¹ 涵盖了用于训练和推理-预填充的高吞吐量内核(第五-B节),以及用于推理-解码的低延迟内核(第五-C节),测试环境包括混合 RDMA+NVLink 和纯 RDMA 配置。
所有实验均在配备 H100 GPU 的 NVIDIA EOS 集群上运行(表 III),使用 NVSHMEM 版本 3.4.5 和 NCCL 版本 2.28。DeepEP 基准测试为每个 GPU 分配 24 个 SM,通信根据自动选择的通道配置分布在 NVLink 和 RDMA 上。
A. 点对点微基准测试
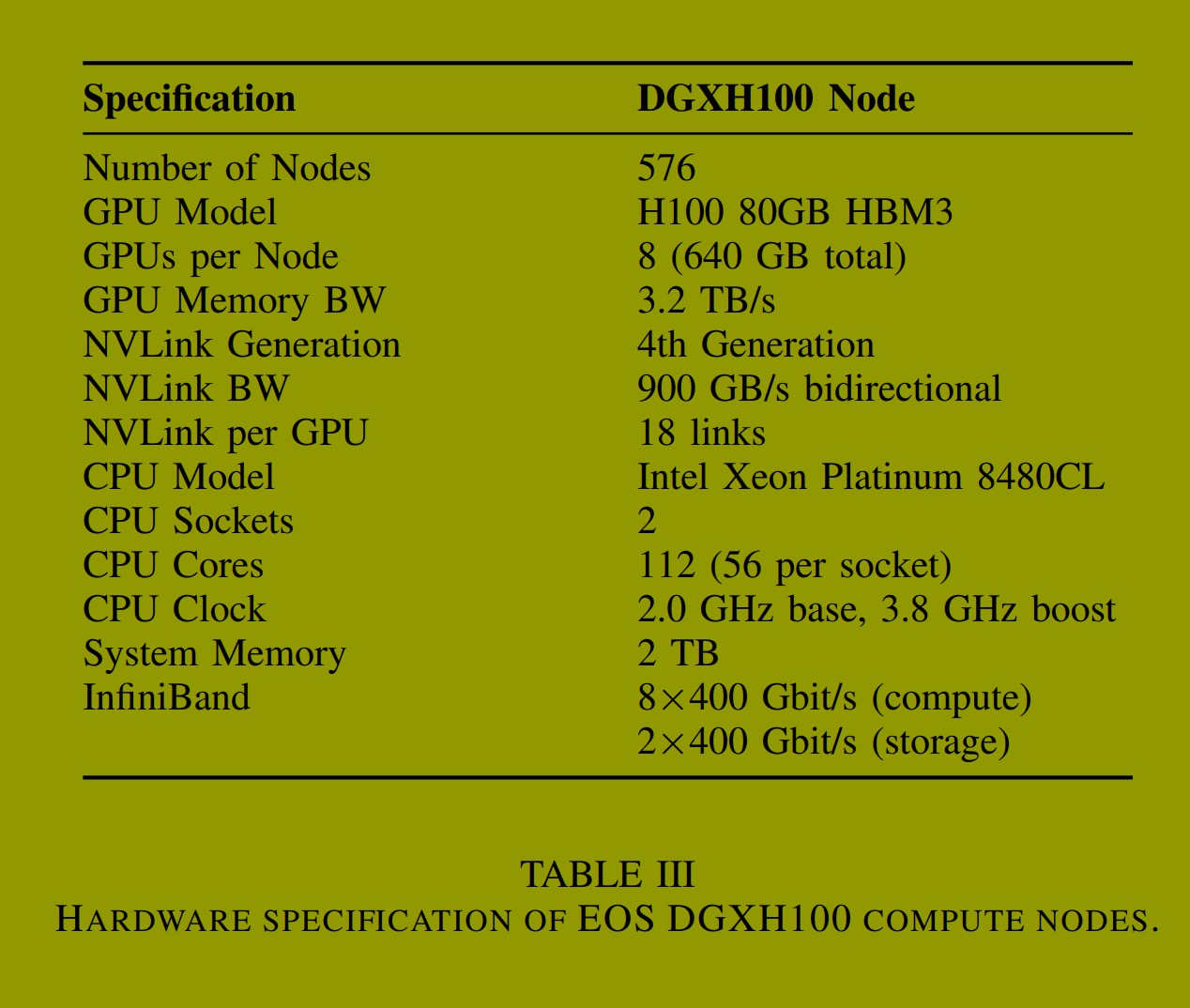
为建立基线性能,我们测量了两个 H100 GPU 之间在 4 字节到 4 MB 消息大小范围内使用乒乓测试的 put with signal 延迟。图 4 展示了 NCCL GIN 的双后端(GDAKI 和 Proxy)与 NVSHMEM IBGDA 和 IBRC 传输的性能比较。
对于小消息(4--128 字节),NCCL GIN GDAKI 实现了 16.7 µs 的往返延迟,与 NVSHMEM IBRC 的 16.0 µs 相当,而 NVSHMEM IBGDA 为 24.3 µs。GDAKI 后端的直接 GPU 到网卡路径消除了 CPU 代理开销,而 Proxy 后端尽管需要遍历 GPU 到 CPU 队列,仍实现了 18.0 µs 的延迟。在较大消息尺寸下,带宽限制占主导地位,所有实现的性能趋同,验证了 NCCL GIN 在应用集成方面的基本性能特征。
B. 高吞吐量内核
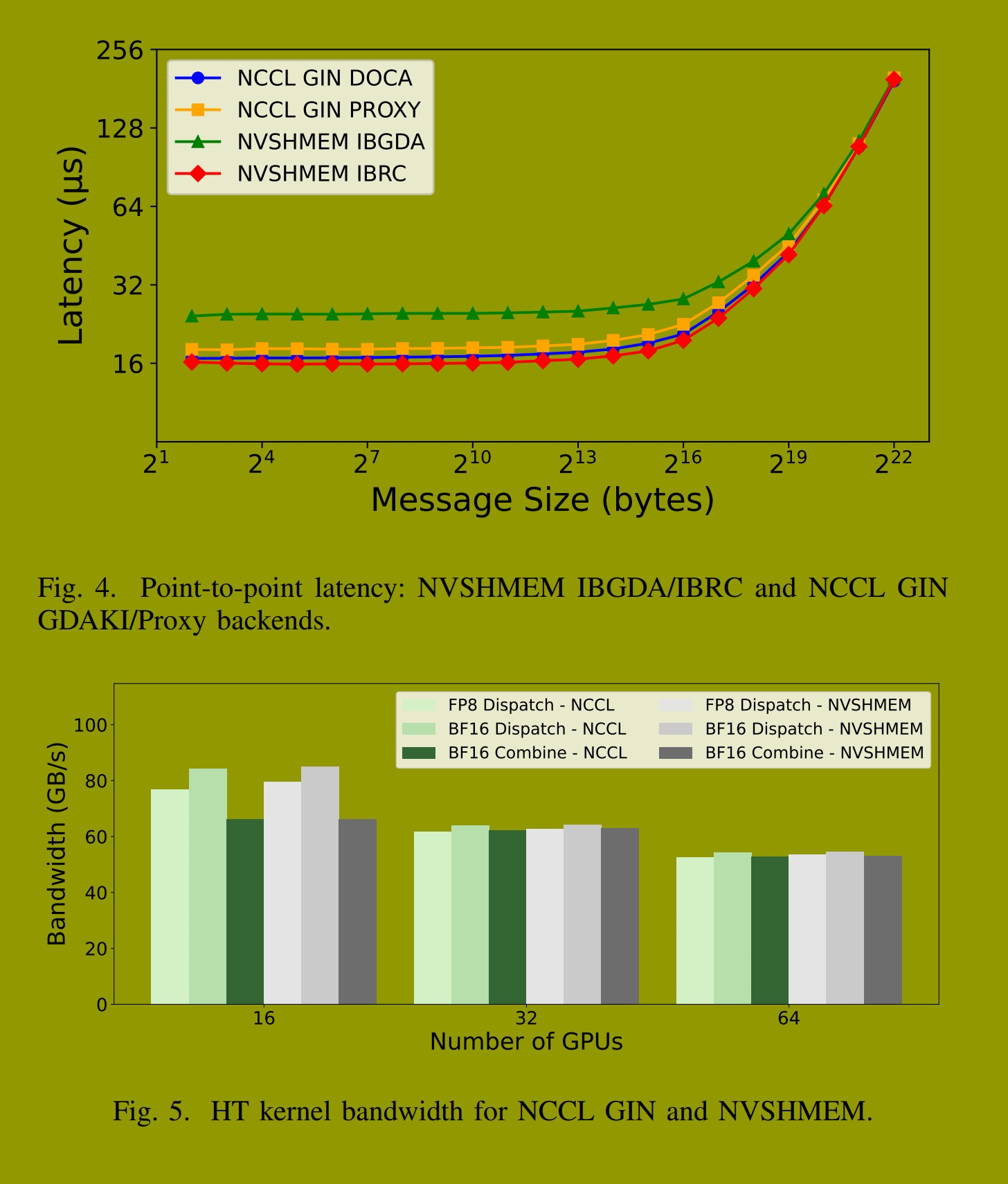
HT 内核针对具有大令牌批次(4096 个令牌)的 MoE 训练和推理-预填充进行了优化,使用分层通信,其中专门的 SM 角色(发送器、转发器、NVLink 接收器)最小化节点间 RDMA 流量,同时最大化节点内 NVLink 带宽。图 5 展示了在 2、4 和 8 个节点上,FP8 和 BF16 精度的分发和组合带宽,并分别报告了 RDMA 和 NVLink 指标。
在所有配置中,两种实现都提供了相近的性能。在 2 节点(16 GPU)BF16 精度下,分发操作在 NCCL GIN 上达到 84.36 GB/s 的 RDMA 带宽,在 NVSHMEM 上达到 84.97 GB/s。在 8 节点(64 GPU)下,两种实现的分发操作均维持约 53--54 GB/s 的 RDMA 带宽。在不同规模、精度模式和操作类型下,结果差异保持在 1--2% 以内,表明 NCCL GIN 在保留 HT 吞吐量的同时,实现了对 NCCL 基础设施的标准化支持。
C. 低延迟内核
LL 内核(第四部分)针对具有小令牌批次(1--128 个令牌)的 MoE 推理-解码进行了优化,使用具有每个专家信号和混合 NVLink-RDMA 路径的完整全交换 RDMA 网格连接。在 BF16 精度和隐藏维度 7168 下,分发操作传输 14,352 字节的消息(14,336 字节令牌数据 + 16 字节令牌源索引元数据),而组合操作传输 14,336 字节的消息。带信号的零字节 put 操作实现了用于数据可见性的释放-获取语义。我们在启用混合 RDMA+NVLink 和纯 RDMA 配置下进行评估,以衡量不同部署场景的性能。
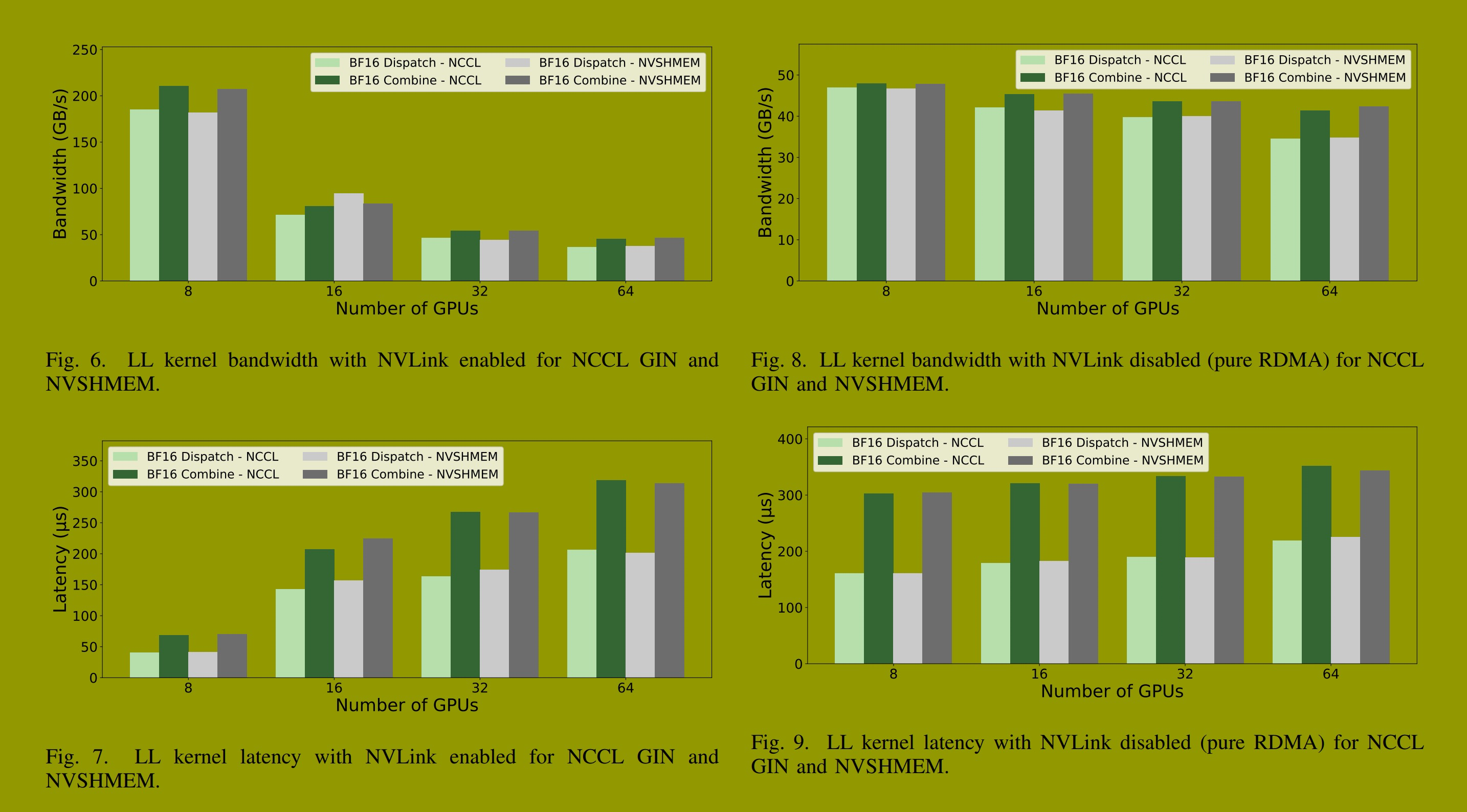
启用 NVLink 的 LL 内核(RDMA+NVLink)。此配置代表了具有节点内 NVLink 和节点间 RDMA 的典型部署。图 6 和图 7 显示了带宽和延迟比较。在 1 节点(8 GPU)下,NCCL GIN 性能略优于 NVSHMEM:分发操作达到 185.28 GB/s 和 40.62 µs,而 NVSHMEM 为 182.15 GB/s 和 41.43 µs;组合操作性能几乎相同(211 GB/s, 69 µs)。
在多节点规模下,两种实现显示出相近的性能,仅有微小差异。NCCL GIN 在不同规模下始终提供更低的延迟(例如,在 2 节点时低 9%:142.51 µs 对比 157.00 µs)。组合操作在所有规模下的差异保持在 1--3% 以内。
禁用 NVLink 的 LL 内核(纯 RDMA)。禁用 NVLink 后,所有通信都通过 RDMA 进行------这测试了诸如跨交换机拓扑或没有 NVLink 的系统等场景。图 8 和图 9 显示的测量结果表明,两种实现在不同规模下保持了相近的性能,大多数指标差异在 1--2% 以内。在 1 节点(8 GPU)下,分发操作在 NCCL GIN 上达到 47.00 GB/s 带宽和 160.82 µs 延迟,而 NVSHMEM 达到 46.79 GB/s 和 160.67 µs。在 8 节点(64 GPU)下,两种实现均维持约 34--35 GB/s 的带宽和 219--225 µs 的延迟。
D. 讨论
评估结果表明,NCCL GIN 提供了与 NVSHMEM 性能特征相似的设备发起通信能力。跨微基准测试和应用工作负载(HT 和 LL 内核),GIN 将设备发起原语与 NCCL 的拓扑感知集合操作集成在单一运行时中,结合了设备端 API 的灵活性和 NCCL 的生产就绪基础设施。GIN 实现仍在积极开发中,计划中的优化包括批处理工作队列条目和分摊多个操作的门铃成本,以进一步提升性能。
六、相关工作
设备发起通信库。OpenSHMEM 12, 29 为对称内存和单边操作建立了 PGAS 语义,但早期的 GPU 扩展仍然是 CPU 中介的 14。NVSHMEM 8, 13 支持从 CUDA 内核调用设备可调用操作,通过消除内核启动开销实现了 60--75% 的速度提升。然而,NVSHMEM 作为一个独立的运行时,与现有的集合通信框架分离。早期的 GPU 发起 RDMA 努力,如 GPUrdma 19 和 GIO 17,面临着 GPU-网卡内存一致性的挑战,通过内核驱动程序扩展为不规则应用带来了 44% 的性能提升。DOCA GPUNetIO 20, 30 为 InfiniBand 和 RoCE 提供了生产级的设备端 RDMA API,构成了 GIN 的 GDAKI 后端的基础。
集合通信运行时。NCCL 6, 24 为分布式训练提供了拓扑感知的集体算法和生产就绪的基础设施,传统上使用主机发起的通信。MPI RMA 31 操作仍然是主机发起的,而 UCX 32 和 UCC 33 提供了统一的通信框架,但没有设备可调用原语。NCCL 2.28 通过设备 API 对此进行了扩展,将设备发起的通信能力(LSA, Multimem, GIN)集成到 NCCL 现有的基础设施中。
MoE 通信库。MoE 架构需要具有不可预测消息大小的不规则全交换路由 25。DeepSpeed-MoE 34 采用分层并行,而 FasterMoE 35 和 Tutel 36 优化了专家调度。DeepEP 26 和 pplx-kernels 27 提供了低延迟的 GPU 发起原语,但独立于集合通信框架运行。
GIN 的定位。GIN 通过双后端独特地将设备发起的网络原语集成到 NCCL 的生产就绪基础设施中:GDAKI 用于直接的 GPU 到网卡通信,Proxy 用于在商用硬件上进行 CPU 辅助操作。这种集成保留了 NCCL 的生态系统兼容性,同时为 MoE 推理和内核融合模式等新兴工作负载启用了设备驱动的通信。
七、结论与未来工作
现代AI工作负载------包括MoE推理和编译器生成的融合内核------需要GPU直接控制网络操作,这超出了NCCL传统主机启动模型的能力范围。本文介绍了GIN,作为NCCL 2.28设备API 9 的一部分,它使得GPU线程能够直接从CUDA内核发出单边RDMA操作。GIN提供了一个统一的三层架构(主机API、设备API以及具有双重语义的可插拔网络后端),并支持通过GDAKI的直接GPU到网卡通信以及在标准RDMA硬件上的CPU辅助操作。我们的评估验证了GIN的实际可行性:GDAKI后端在小消息上实现了16.7微秒的往返延迟,并且与DeepEP的集成展示了其在高吞吐量和低延迟内核上具有竞争力的性能,且代码改动极小。
重要的是,GIN的价值超越了原始性能,更在于生态系统的统一,它通过与NCCL生产就绪的基础设施集成,提供了可扩展性和可扩展性。应用程序得以访问一套统一的通信抽象------用于NVLink/PCIe的加载/存储可访问模式、用于NVLink SHARP的多内存模式以及用于网络RDMA的GIN------从而能为每种模式选择最合适的原语。至关重要的是,这种集成保留了NCCL的生产就绪特性:用于多维并行(专家并行、张量并行、流水线并行)的分层通信器、用于弹性大规模训练的容错和弹性机制,以及拓扑感知优化。这些能力消除了部署多个通信运行时的操作复杂性,同时为MoE推理和编译器生成的融合内核等新兴工作负载提供了所需的灵活性。
未来的工作将侧重于推动GIN在生产应用中的更广泛采用,例如PyTorch分布式训练、TensorRT-LLM推理服务、用于LLM推理的vLLM和SGLang,以及JAX/Triton编译器生成的内核。我们还计划扩展GIN的API,增加更多单边原语,以支持新兴的通信模式和分布式算法需求。
致谢
作者感谢NCCL和NVSHMEM团队的贡献。作者也感谢Jeff Hammond和Matthew Nicely对稿件进行的仔细审阅以及他们富有洞察力的反馈。
作者声明使用了Cursor AI来协助本文稿的撰写和编辑。作者已审阅并核准所有内容以确保其准确性和原创性。