基础知识
latency:完成一个指令的耗时
memory latency:从memory获取内存数据等待的时间,是CPU的优化方向
throughput:单位时间内可以执行的指令数,是GPU的优化方向
multi-threading:多线程
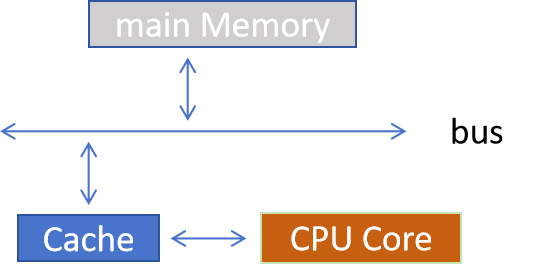
CPU Core从内存中读取数据分两种情形(简便起见,忽略多级的Cache)
- 缓存命中:数据请求时,所需数据已存在于缓存中,可直接读取。
- 缓存未命中:数据请求时,缓存中没有目标数据,需从下级memory、主存或其他存储层级加载,这个加载是比较耗费时间的,在等待数据加载完成这个等待的时间叫做stall
在这个金字塔中,越往上越靠近处理器,访问数据的速度越快,但是价格越贵
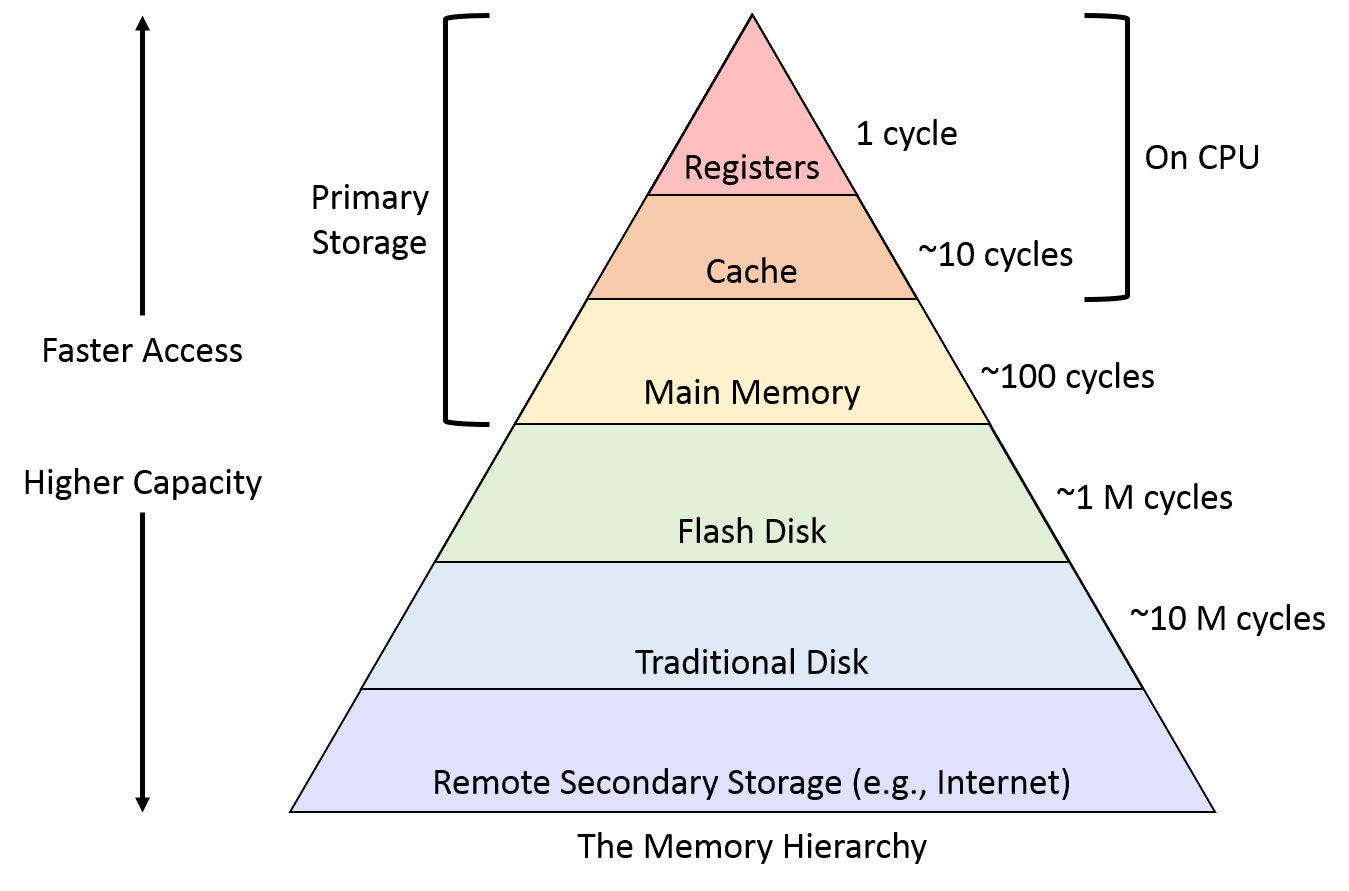
可以看到从不同的层级访问数据的难易程度是无法忽略的差距。

性能优化
CPU instruction pipeline
我们先看一个指令在CPU中是如何执行的

IF(Instruction Fetch): 取指阶段:从内存中读取当前要执行的指令。
ID(Instruction Decode): 译码阶段:解析指令的操作码和操作数地址,明确指令功能。
OF(Operand Fetch): 取操作数阶段:根据译码结果,从寄存器或内存中取出所需操作数。
EX(Execution): 执行阶段:通过 ALU(算术逻辑单元)完成指令规定的运算或操作。
WB(Execution): 写回阶段:将执行结果写回寄存器,供后续指令使用。
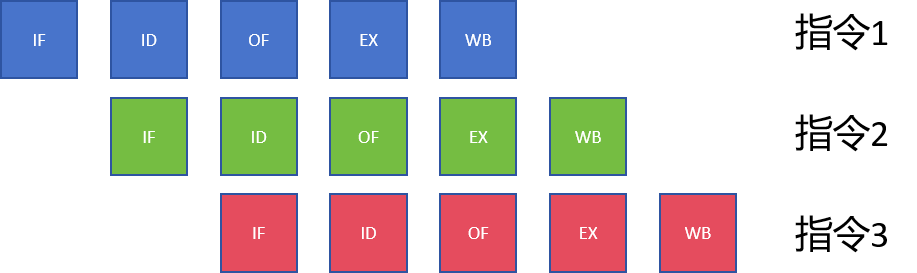
没有优化的指令是串行执行的,如下所示

那么流水线CPU instruction pipeline优化后,指令可以并发执行,这样多条指令执行的时间被大大压缩了。
Memory Hierarchy
- CPU 发起数据请求,首先查询L1 缓存(离 CPU 核心最近、速度最快、容量最小)。
- 若 L1 缓存命中,直接读取数据并返回 CPU,流程结束。
- 若 L1 未命中,查询L2 缓存(速度次之、容量大于 L1,通常为核心独享或共享)。
- 若 L2 命中,读取数据并同步到 L1 缓存(为后续请求提速),再返回 CPU。
- 若 L2 未命中,查询L3 缓存(所有核心共享、容量更大、速度慢于 L1/L2)。
- 若 L3 命中,数据同步到 L2 和 L1 缓存后返回 CPU;若 L3 未命中,最终访问主存(容量大、速度最慢)。
- 主存中的数据会逐级写入 L3、L2、L1 缓存,再返回 CPU,确保后续同类请求能命中缓存。
|---------|-----------|-------------|--------------|----------------------|
| L1 缓存 | 最快(100%) | 几 KB--几十 KB | 最低(1x) | 核心专属,存储最常访问数据 / 指令 |
| L2 缓存 | 次之(~80%) | 几十 KB--几 MB | 较低(3x--5x) | 补充 L1,部分核心独享或小集群共享 |
| L3 缓存 | 中等(~50%) | 几 MB--几十 MB | 中等(10x--20x) | 全核心共享,承接 L2 未命中请求 |
| 主存(RAM) | 较慢(~10%) | 几十 GB--数 TB | 较高(100x+) | 存储 CPU 未缓存的所有数据 / 程序 |
Pre-fetch
- CPU 会分析历史数据访问规律,比如连续地址读取、指令流执行顺序等。
- 基于这些规律预判后续可能需要的数据或指令,在 CPU 实际发起请求前主动加载。
- 加载路径是从低层级存储(主存或下一级缓存)到高速缓存(如 L1/L2),提前 "备货"。
- 减少缓存未命中率,避免 CPU 等待主存加载数据的漫长延迟。
- 让 CPU 执行指令时,所需数据大概率已在缓存中,提升整体运算效率。
- 适配程序的局部性原理(时间局部性、空间局部性),最大化缓存利用率。
举个例子:
未Pre-fetch

存在Pre-fetch
如果碰到条件的指令怎么办,机器如何Pre-fetch?
Branch-Prediction (CPU专属)
- CPU 会基于分支指令的历史执行记录(比如之前多次走哪个分支),预判本次最可能的执行方向。
- 提前按预判方向加载并执行后续指令,若预判正确,流水线持续高效运行;若预判错误,丢弃已执行的错误指令,重新加载正确指令(会产生少量延迟)。
关键作用
- 解决流水线 "断流" 问题:没有分支预测时,CPU 需等待分支指令执行完毕才能确定下一条指令,导致流水线阻塞。
- 大幅提升 CPU 吞吐量:现代 CPU 分支预测准确率可达 90% 以上,让流水线始终保持高利用率。
- 适配复杂程序逻辑:满足多分支、循环嵌套等场景的高效执行需求。
举个例子:
无Branch-Prediction
Stall状态下是灰色的
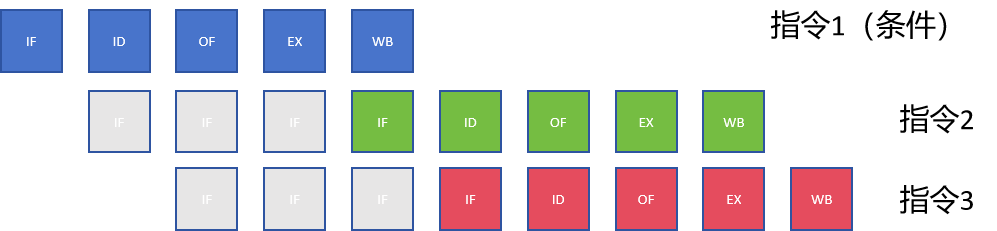
存在无Branch-Prediction
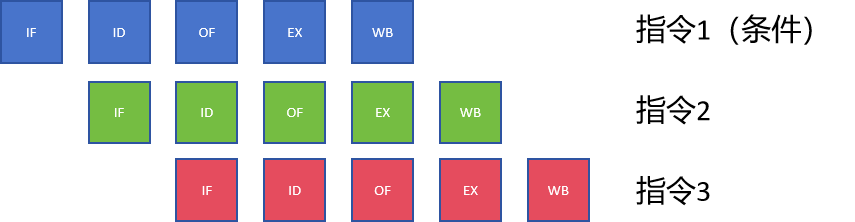
多指令并发执行,当指令1的EX(上图第一行的EX)的执行结果是false,不能执行指令2、3时,只需要撤回就好。
Multi-threading
- 线程是进程的最小执行单元,多个线程共享所属进程的内存、文件句柄等资源,创建和销毁的开销远低于进程。
- 逻辑上实现 "并行":单核心 CPU 通过时间片轮转(快速切换线程执行)模拟并行;多核心 CPU 可让不同线程在不同核心上真并行执行。
- 配合 CPU 调度机制:当一个线程等待 I/O 或资源时,CPU 可切换到其他就绪线程,避免核心闲置。
关键作用
- 提升程序响应速度:比如软件 UI 操作与后台数据处理并行,避免操作卡顿。
- 最大化 CPU 利用率:让多核心 CPU 的每个核心都有任务执行,减少资源浪费。
- 适配多任务场景:支持同一程序同时处理多个请求(如服务器同时响应多个用户)。
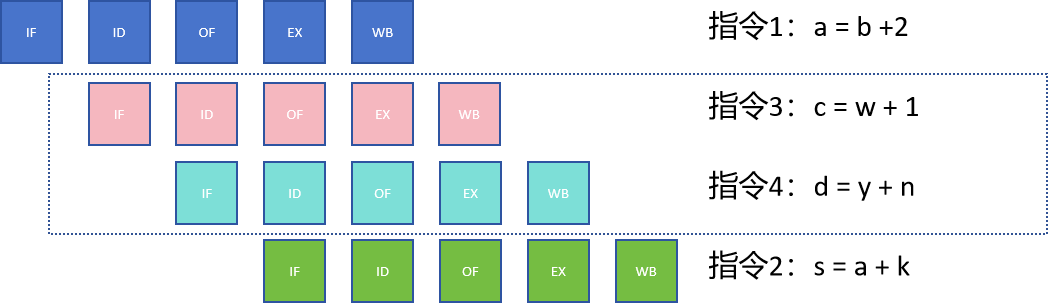
举个例子
两个指令存在数据依赖关系,指令2在执行OF前需要等待a的结果写回,所以有两个cycle的等待时间

那么cpu可以在stall时候执行其他的指令使得计算资源不至于被浪费
总结
CPU优化路线有两个方向
减少memory latency
- cache hierarchy
- pre-fetch
- branch prediction
提高throughput
- pipeline
- multi-threading
CPU需要处理大量的复杂逻辑运算,所以增加core的带来throughput的收益一般不太高
而没有复杂逻辑运算,单纯大量数据计算的时候,增加core的throughput的收益就很高,所以这类运算就被放在GPU上了,可以说GPU就是为计算而生的。
CPU和GPU架构对比
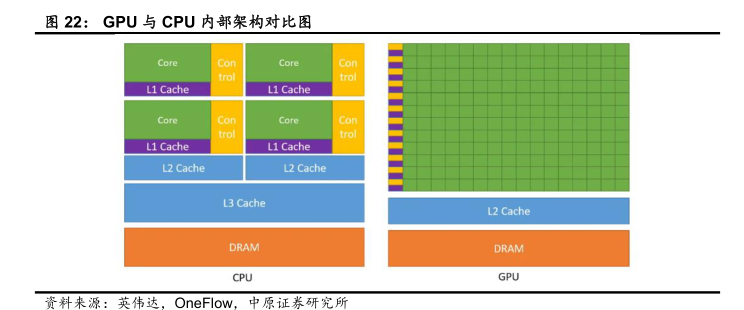
- 设计目标
- CPU:追求低延迟、高单线程性能,适配复杂多样的任务(如系统调度、逻辑判断、单任务运算)。并行处理threads数量规模数十个。
- GPU:追求高吞吐量、大规模并行,专注重复且数据独立的任务(如图形渲染、AI 训练、数值计算)。并行处理threads数量规模达上千甚至上万。
- 核心与控制单元
- CPU:核心数量少(常见 4-64 核),每个核心配备完善的控制单元(如分支预测、乱序执行),缓存层级丰富(L1/L2/L3 缓存),擅长复杂指令流处理。
- GPU:核心数量极多(数千甚至数万流处理器 / CUDA 核心),控制单元简化(弱化分支预测、少乱序执行),缓存容量小且以共享缓存为主,侧重简单指令的批量执行。
- 并行能力
- CPU:支持任务级并行(多线程),适合少量任务的并行处理,单个核心能高效应对复杂逻辑。
- GPU:支持数据级并行,通过 "SIMT(单指令多线程)" 架构,让大量核心同时执行相同指令、处理不同数据,并行规模远超 CPU。
- 内存访问
- CPU:优先访问高速缓存,缓存命中率对性能影响极大,主存访问延迟低但带宽相对有限。
- GPU:缓存命中率要求低,依赖高带宽显存(HBM/GDDR) 弥补缓存不足,通过批量数据访问掩盖内存延迟。
每个core的运算逻辑很简单
- CUDA Core
D = A * B + C
- Tensor Core:
4*4*4的matrix 计算
D = A * B + C
SIMT
- 一条指令同时控制多个独立线程,每个线程处理一份数据。线程有独立的寄存器、程序计数器,可灵活分支(但分支会降低效率),是 GPU 专门针对大规模并行任务设计的架构。
- threads的调度是有wrap来管理的,GPU体系中,wrap schedular专门负责线程调度
|------|--------------|---------|----------------|
| SISD | 一条指令仅处理一份数据 | 无并行(串行) | 早期 CPU、简单串行计算 |
| SIMD | 一条指令同时处理多份数据 | 数据级并行 | CPU 向量运算、多媒体处理 |
| SIMT | 一条指令控制多个独立线程 | 线程级并行 | GPU 大规模并行计算 |
- SIMD 是 "数据打包" 并行,多个数据必须执行相同操作(无独立分支);
- SIMT 是 "线程独立" 并行,线程可有不同分支(但同批次线程分支一致时效率最高);
- SISD 无任何并行,完全串行执行,是最基础的计算架构。
注意事项
由于GPU的并行程度高,所以memory latency带来的性能损耗并不明显,但是CPU与GPU以及不同GPU通信时产生的memory latency需要关注。