💖💖作者:计算机毕业设计小途 💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目
@TOC
基于SpringBoot的水产养殖管理系统介绍
本系统命名为《基于SpringBoot的水产养殖管理系统》,旨在通过信息化手段全面提升水产养殖行业的现代化管理水平。该系统采用B/S(Browser/Server)架构,核心技术栈强大且灵活。在后端,系统主要基于Java语言开发,并深度整合了Spring Boot框架,充分利用了Spring的依赖注入、Spring MVC的请求处理能力以及MyBatis的持久层操作,实现了高效稳定的业务逻辑处理;同时,系统也提供了Python语言版本,基于Django框架实现,为用户提供了多样化的技术选择。前端界面则由Vue.js框架配合ElementUI组件库及HTML技术构建,确保了用户界面的响应式、交互性和美观性,为用户提供流畅的操作体验。数据存储方面,系统选择成熟稳定的MySQL数据库,确保了数据的高效存取与管理。开发工具推荐使用IntelliJ IDEA进行Java版本开发,或PyCharm进行Python版本开发。系统功能模块设计周密,涵盖了水产养殖管理的各个核心环节,包括用户管理、水产种类管理、水产信息管理、水产产地管理以及至关重要的水产订单管理,构建了从生产到销售的完整链条。此外,系统还具备详细的养殖记录管理功能,方便用户追溯与分析;通过饲料信息管理、采购入库管理与出库信息管理,实现了对养殖物资的精细化管控。为了提升养殖技能与知识水平,系统特别集成了养殖培训管理、培训类型管理及培训报名管理模块,为养殖户提供学习交流平台。在平台运营层面,系统提供了直观的系统首页、个性化的个人中心、全面的系统管理功能、公告资讯分类与轮播图管理,确保了平台的信息发布与日常运维。智能客服模块的引入,旨在提升用户服务效率与体验;详尽的系统日志功能则保障了系统的可追溯性和安全性。通过这些模块的有机结合,本系统致力于为水产养殖企业提供一个集约化、智能化、数据化的综合管理解决方案,助力行业实现可持续发展和效率飞跃。
基于SpringBoot的水产养殖管理系统演示视频
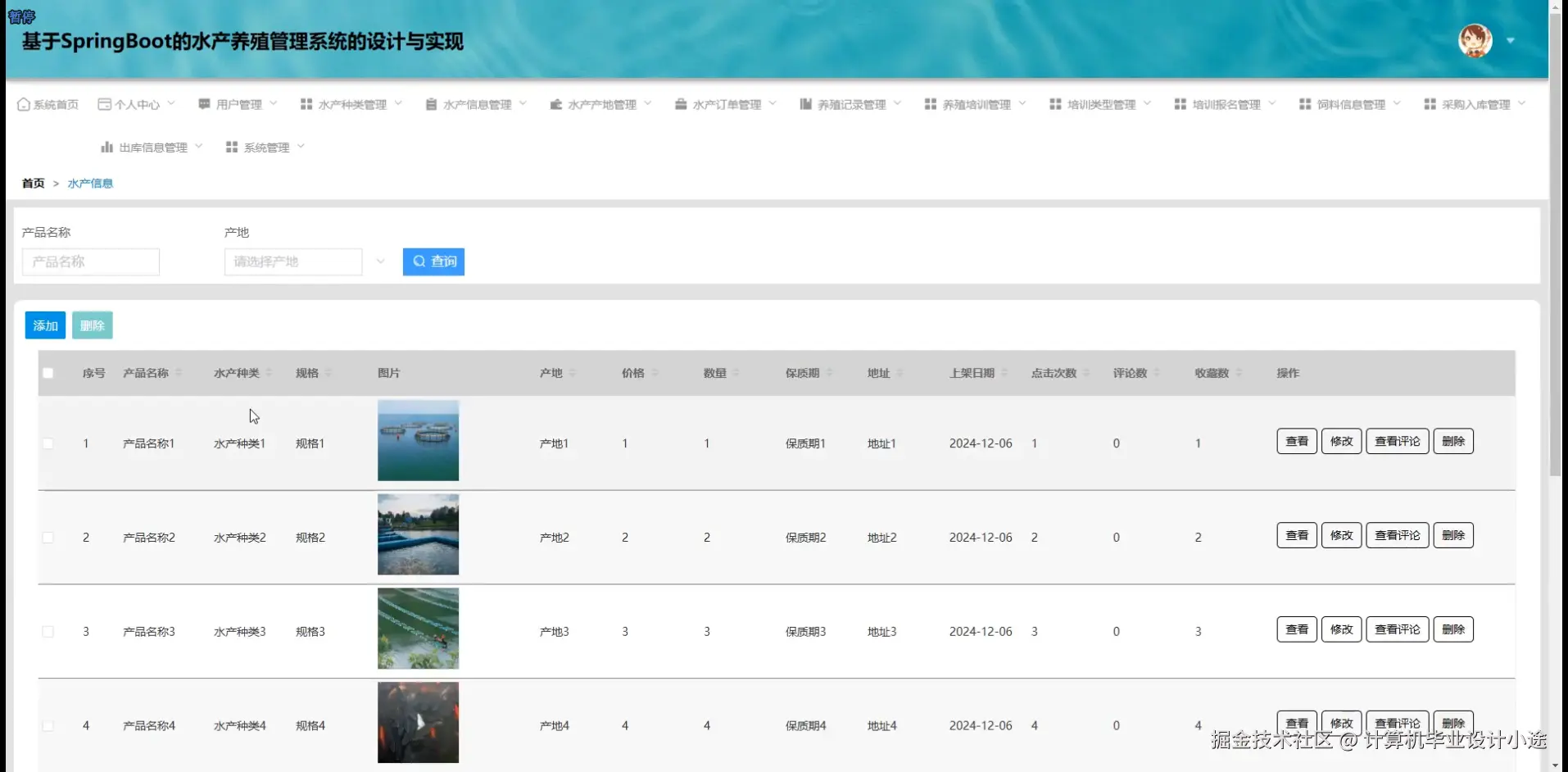
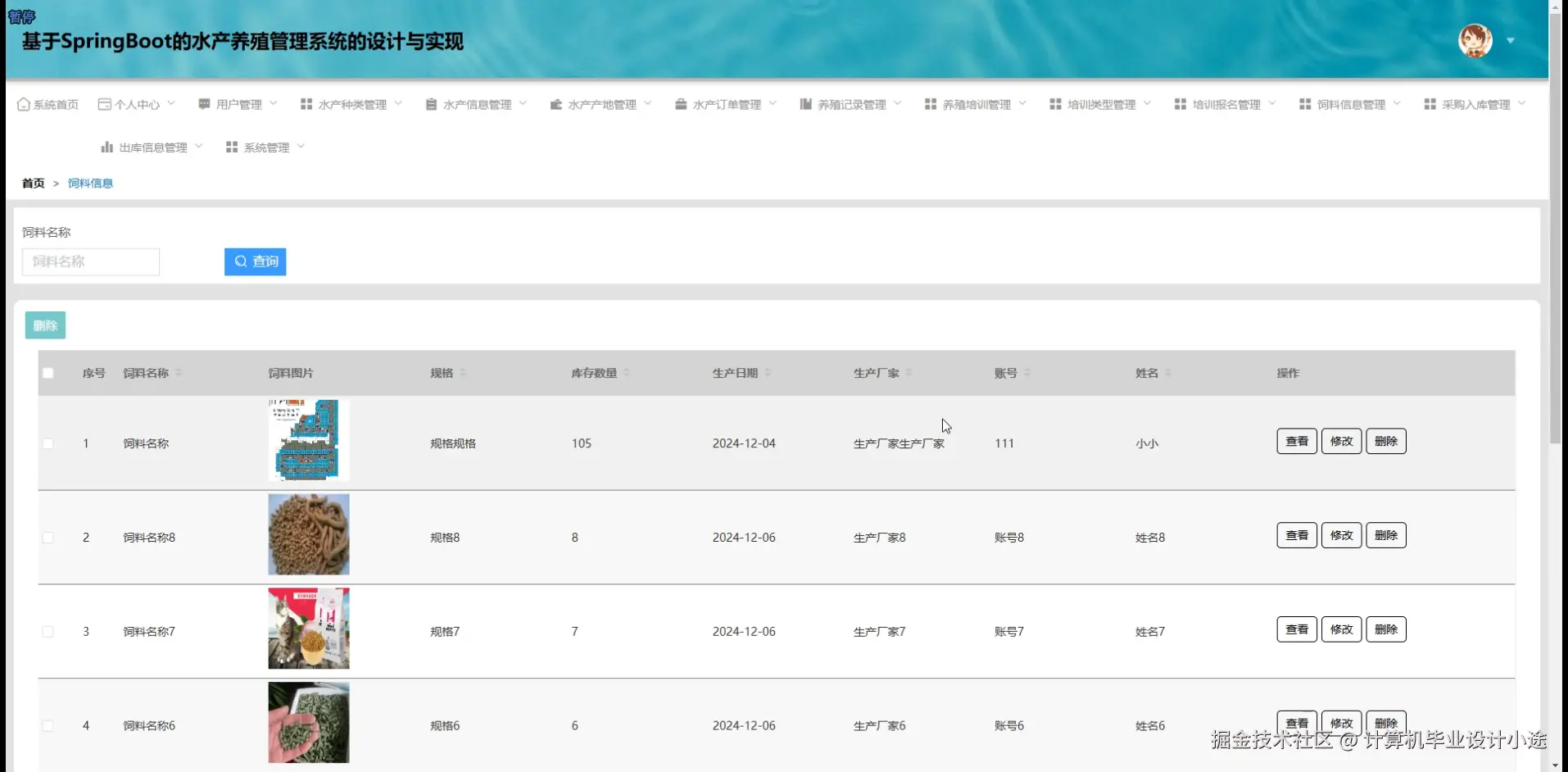
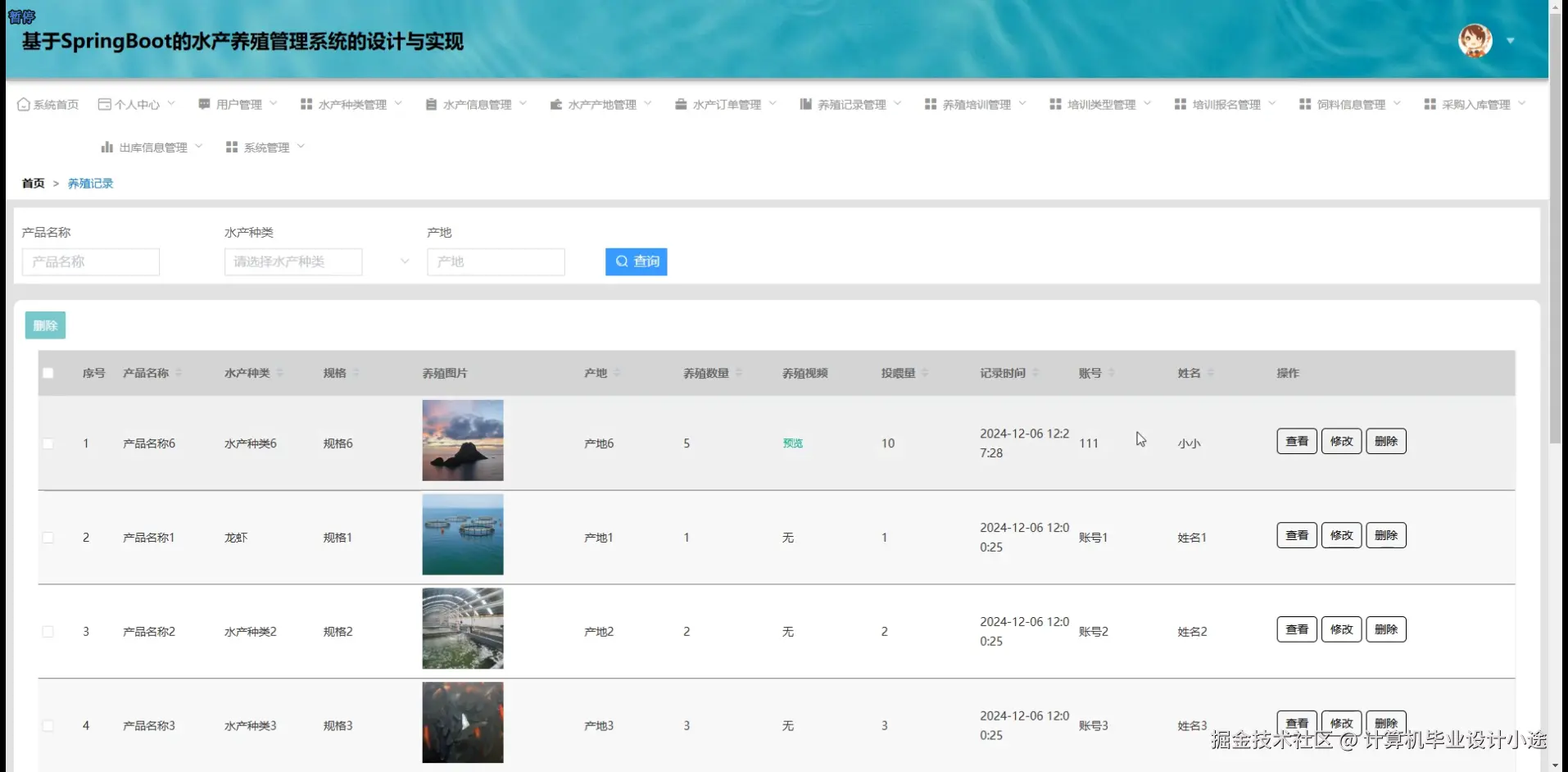
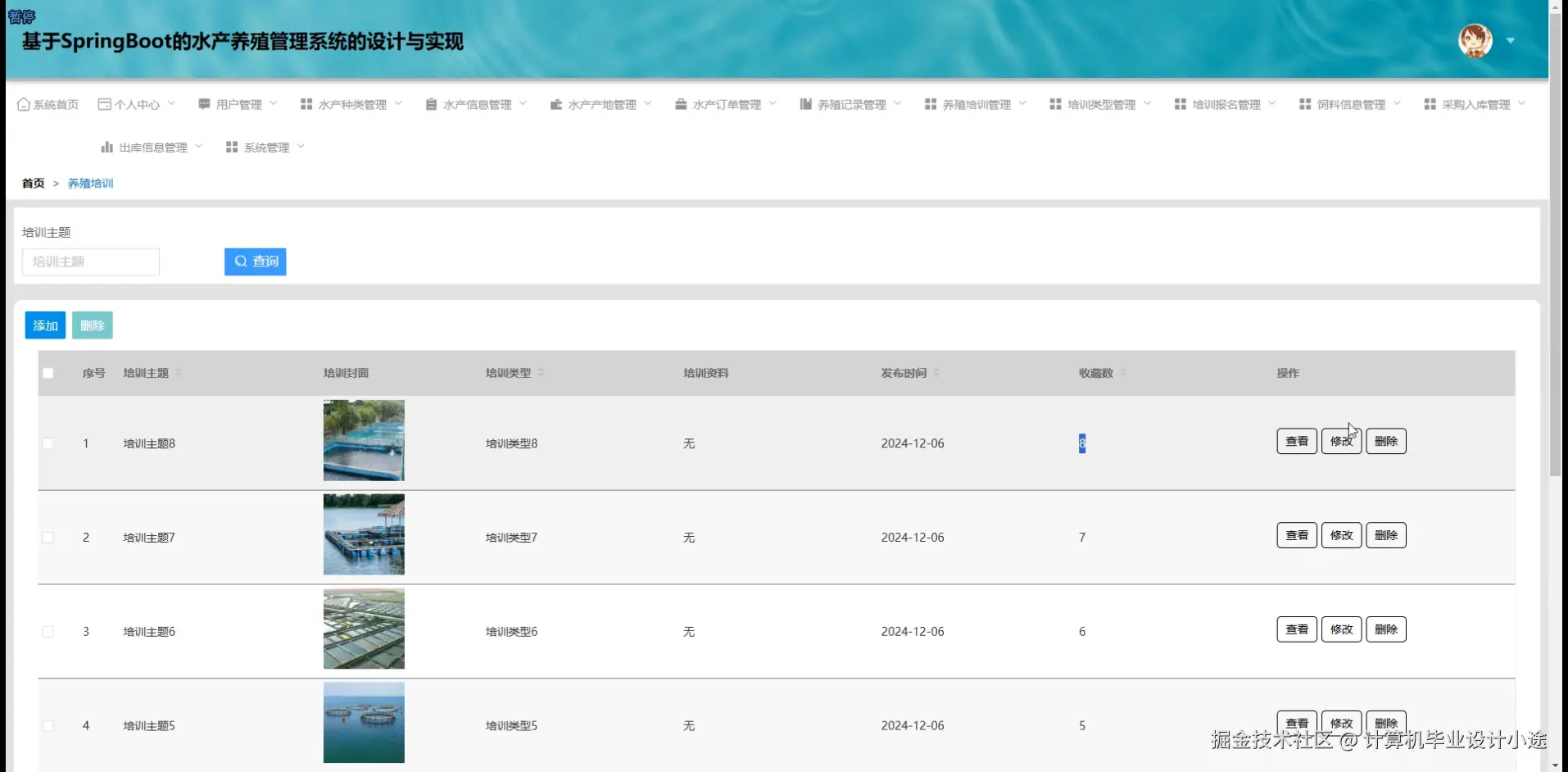
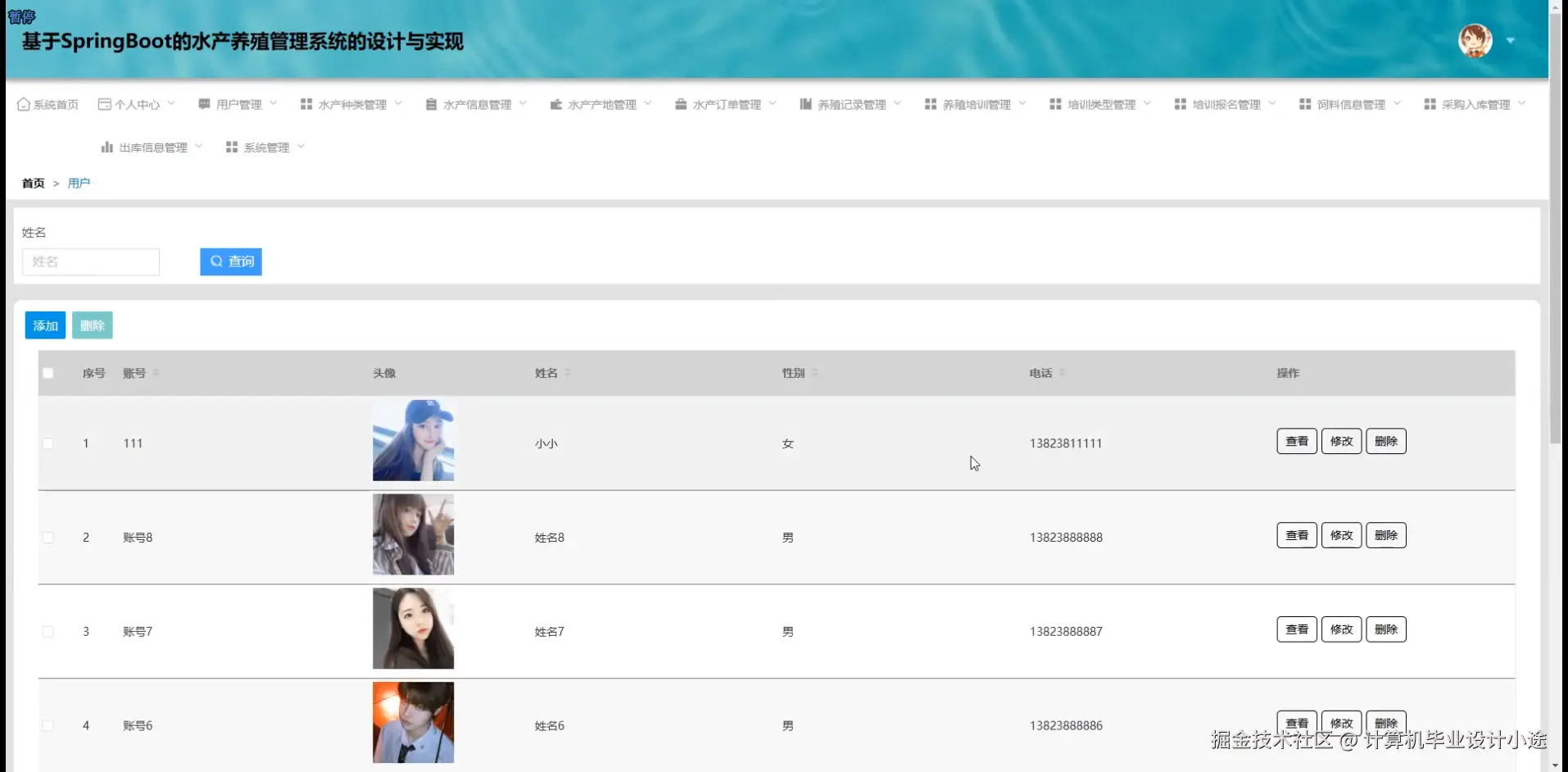
基于SpringBoot的水产养殖管理系统演示图片
基于SpringBoot的水产养殖管理系统代码展示
dart
# Big Data processing with SparkSession.builder is utilized for advanced analytics and recommendation engines.
# All necessary imports are grouped at the top.
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, datediff, to_date, lit, count, when
from pyspark.ml.recommendation import ALS
from pyspark.sql.types import StructType, StructField, IntegerType, FloatType
from datetime import datetime
import pandas as pd # Used for simulating small data for Spark DataFrame creation if needed, but not for core logic itself
# --- Core Functionality 1: 养殖记录管理 (Farming Record Analytics) ---
# Analyzes historical farming records using Spark to detect anomalies or predict trends.
def analyze_farming_records_spark(record_data_path: str, species_thresholds: dict):
spark = SparkSession.builder \
.appName("FarmingRecordAnalytics") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
df = spark.read.csv(record_data_path, header=True, inferSchema=True)
df = df.withColumn("record_date", to_date(col("record_date"), "yyyy-MM-dd")) \
.withColumn("feed_amount_kg", col("feed_amount").cast("double")) \
.withColumn("growth_rate_g_day", col("growth_rate").cast("double"))
growth_analysis = df.groupBy("species_id", "record_date") \
.agg(avg("growth_rate_g_day").alias("avg_growth_rate"))
anomalous_records = growth_analysis.join(
spark.createDataFrame(list(species_thresholds.items()), ["species_id", "min_growth_threshold"]),
on="species_id"
).filter(col("avg_growth_rate") < col("min_growth_threshold"))
anomalies_collected = anomalous_records.collect()
results = []
for row in anomalies_collected:
results.append(f"Anomaly detected for Species {row['species_id']} on {row['record_date']}: Average growth rate {row['avg_growth_rate']:.2f}g/day is below threshold {row['min_growth_threshold']:.2f}g/day.")
spark.stop()
return results
# --- Core Functionality 2: 水产订单管理 (Aquaculture Order Processing) ---
# Processes new aquaculture product orders, including stock validation and inventory updates.
# Simulates database interactions using global dictionaries.
db_products_sim = {
1: {"id": 1, "name": "Tilapia", "price": 12.5, "stock": 100},
2: {"id": 2, "name": "Shrimp", "price": 25.0, "stock": 200},
3: {"id": 3, "name": "Salmon", "price": 30.0, "stock": 50},
}
db_orders_sim = {}
db_order_items_sim = []
order_id_counter = 1
def process_aquaculture_order(user_id: int, order_items_data: list):
global order_id_counter
if not order_items_data:
raise ValueError("Order must contain items.")
total_amount = 0.0
products_to_update = {}
for item_data in order_items_data:
product_id = item_data.get("product_id")
quantity = item_data.get("quantity")
if not product_id or not quantity or quantity <= 0:
raise ValueError("Invalid product ID or quantity in order item.")
product = db_products_sim.get(product_id)
if not product:
raise ValueError(f"Product with ID {product_id} not found.")
if product["stock"] < quantity:
raise ValueError(f"Insufficient stock for product {product['name']}. Available: {product['stock']}, Requested: {quantity}.")
sub_total = product["price"] * quantity
total_amount += sub_total
products_to_update[product_id] = {"product_ref": product, "quantity": quantity, "unit_price": product["price"]}
new_order_id = order_id_counter
order_id_counter += 1
new_order = {
"id": new_order_id,
"user_id": user_id,
"order_date": datetime.now(),
"total_amount": total_amount,
"status": "CONFIRMED",
"items": []
}
db_orders_sim[new_order_id] = new_order
for product_id, item_info in products_to_update.items():
order_item = {
"order_id": new_order_id,
"product_id": item_info["product_ref"]["id"],
"quantity": item_info["quantity"],
"unit_price": item_info["unit_price"]
}
db_order_items_sim.append(order_item)
item_info["product_ref"]["stock"] -= item_info["quantity"]
return {"order_id": new_order["id"], "total_amount": new_order["total_amount"], "status": new_order["status"]}
# --- Core Functionality 3: 水产推荐系统 (Aquaculture Product Recommendation Engine) ---
# Generates personalized aquaculture product recommendations using Spark's ALS algorithm.
def get_aquaculture_recommendations_spark(interaction_data_path: str, user_id_to_recommend: int, num_recommendations: int = 5):
spark = SparkSession.builder \
.appName("AquacultureRecommendationEngine") \
.config("spark.some.other.config.option", "another-value") \
.getOrCreate()
schema = StructType([
StructField("user_id", IntegerType(), True),
StructField("product_id", IntegerType(), True),
StructField("rating", FloatType(), True)
])
interactions_df = spark.read.csv(interaction_data_path, header=True, schema=schema)
als = ALS(maxIter=5, regParam=0.01, userCol="user_id", itemCol="product_id", ratingCol="rating",
coldStartStrategy="drop")
model = als.fit(interactions_df)
user_df = spark.createDataFrame([(user_id_to_recommend,)], ["user_id"])
recommendations = model.recommendForUserSubset(user_df, num_recommendations)
recommended_product_ids = []
if recommendations.count() > 0:
for row in recommendations.collect()[0]["recommendations"]:
recommended_product_ids.append(row["product_id"])
spark.stop()
return recommended_product_ids基于SpringBoot的水产养殖管理系统文档展示

💖💖作者:计算机毕业设计小途 💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目