今天展示的案例是一个基于 Flux Depth LoRA 的 ComfyUI 工作流,利用深度信息来引导图像生成。该流程通过加载预训练的Flux主模型、LoRA扩展以及深度条件输入,结合文本提示进行生成,引导模型在空间结构和细节层面更精确地还原场景。

在效果演示中,可以看到飞翔在天空中的精灵形象不仅保持了光影与透视的自然感,同时细节表现更符合深度约束,直观地展现了深度条件在生成图像时的作用与优势。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [CLIPTextEncode 文本语义嵌入生成](#CLIPTextEncode 文本语义嵌入生成)
- [CLIPTextEncode (Negative Prompt) 负向语义控制](#CLIPTextEncode (Negative Prompt) 负向语义控制)
- [FluxGuidance 文本嵌入调控](#FluxGuidance 文本嵌入调控)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
这个工作流的整体结构围绕 Flux主模型、LoRA深度适配器、CLIP文本编码器、VAE解码器 等核心组件展开,目标是通过文本和深度图双重约束生成图像。深度引导不仅提升了结构合理性,还解决了复杂画面中空间层次模糊的问题。模型部分包括主干UNet扩散模型、对应的LoRA深度模块以及文本和视觉的双编码器CLIP,确保语义与结构信息被充分理解。工作节点中串联了图像加载、文本正负提示、深度条件融合、采样生成和最终图像解码与保存,每一个环节都围绕生成效果的质量和可控性展开。整体上,它展示了在ComfyUI环境中如何将深度约束与LoRA结合,实现更强的图像生成控制力。
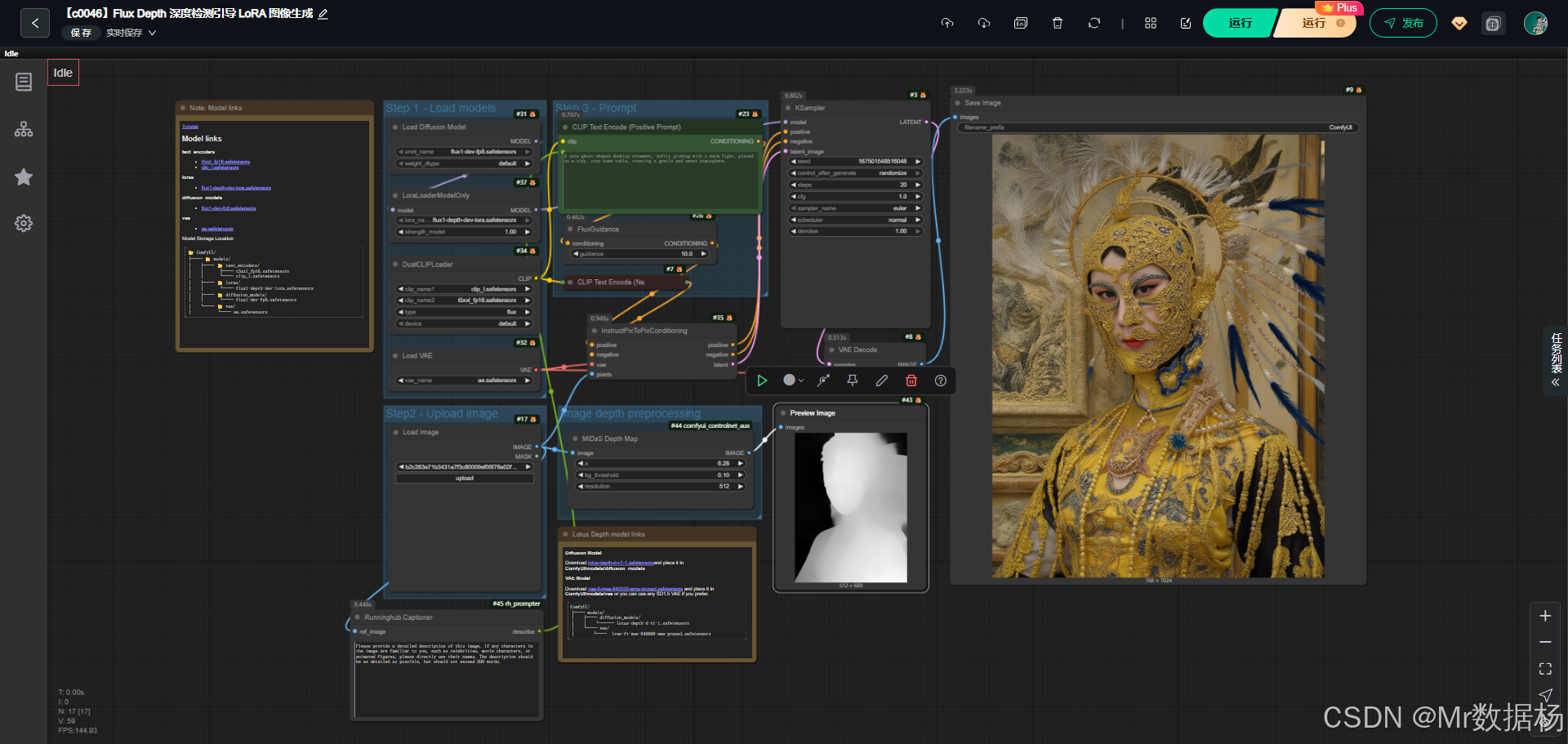
核心模型
核心模型由Flux的基础扩散模型、对应的LoRA深度微调模块以及CLIP文本编码器和VAE解码器构成。Flux 1-dev 作为生成的主力,保证了图像质量;LoRA 部分则引入了深度信息,让模型在生成过程中能够参考场景结构;CLIP文本编码器承担语义解析的任务,使自然语言描述能够被转化为可用的生成条件;VAE解码器则将潜空间中的结果还原为可见图像。这些模型协同作用,保证了从语义到结构再到像素层面的整体生成质量。
| 模型名称 | 说明 |
|---|---|
| flux1-dev.safetensors | Flux主扩散模型,负责图像生成的核心过程 |
| flux1-depth-dev-lora.safetensors | 深度LoRA模块,引入深度信息约束生成 |
| clip_l.safetensors | CLIP大模型,用于文本提示的语义理解 |
| t5xxl_fp16.safetensors | T5文本编码器,进一步增强语言解析能力 |
| ae.safetensors | VAE模型,用于潜空间到图像的解码 |
Node节点
Node节点的设置体现了从输入到输出的完整生成链路。图像输入由LoadImage完成,作为深度参考被传递到InstructPixToPixConditioning;文本提示由CLIP Text Encode进行处理并通过FluxGuidance调节生成的权重;模型加载部分包括UNETLoader与LoRALoader共同完成主模型与深度扩展的组合;在采样阶段,KSampler根据条件信息输出潜空间结果,再通过VAEDecode转化为可见图像,最终SaveImage节点将结果保存。各个节点配合形成一个闭环,确保深度信息与文本提示在生成过程中得到融合与发挥。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载输入图像,作为深度引导参考 |
| CLIP Text Encode (Positive/Negative Prompt) | 解析文本提示,转化为语义条件 |
| FluxGuidance | 控制文本条件的引导强度 |
| InstructPixToPixConditioning | 将图像像素、文本条件和VAE信息整合为潜变量输入 |
| UNETLoader | 加载Flux主模型 |
| LoraLoaderModelOnly | 加载深度LoRA模块并与主模型结合 |
| KSampler | 基于条件与模型进行潜空间采样 |
| VAEDecode | 将潜空间样本解码为最终图像 |
| SaveImage | 保存生成结果 |
工作流程
整个工作流的执行逻辑是围绕图像输入、文本提示、深度信息融合、潜空间采样和图像解码展开的。流程的起点是图像与文本的输入,深度信息通过图像加载与LoRA模块结合,语义信息通过CLIP文本编码器转换为条件向量,二者在InstructPixToPixConditioning节点中统一处理,随后进入KSampler进行潜空间采样,最后由VAE完成图像解码与输出。整个链路保证了深度结构、文本描述和模型潜空间生成的协调性,使结果具备高保真度和强可控性。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 输入阶段 | 加载参考图像与文本提示,建立生成约束条件 | LoadImage、CLIP Text Encode |
| 2 | 条件融合 | 将深度图像、正负文本提示与VAE特征整合为潜变量条件 | InstructPixToPixConditioning |
| 3 | 模型加载 | 引入Flux主模型和深度LoRA模块,形成具备深度约束的生成模型 | UNETLoader、LoraLoaderModelOnly |
| 4 | 引导与采样 | 通过FluxGuidance设定文本条件引导强度,使用KSampler在潜空间进行采样 | FluxGuidance、KSampler |
| 5 | 图像生成 | 将潜空间结果解码为图像,并保存为最终输出 | VAEDecode、SaveImage |
大模型应用
CLIPTextEncode 文本语义嵌入生成
在 Flux Depth 深度检测引导 LoRA 图像生成工作流中,CLIPTextEncode 节点负责将用户提供的正向 Prompt 转化为 CLIP 嵌入,用于指导生成模型在深度图条件下生成目标图像。Prompt 描述直接决定角色特征、场景布局和整体画面风格,是生成高精度、可控图像的语义核心。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Positive Prompt) | The fairy flying in the sky | 将正向 Prompt 转化为 CLIP 嵌入,用于控制图像生成的语义、角色和场景特征,使生成结果符合用户描述的视觉效果。 |
CLIPTextEncode (Negative Prompt) 负向语义控制
该节点生成负向嵌入,用于抑制生成图像中不希望出现的元素或风格,使生成图像更加干净、自然。负向 Prompt 可防止生成杂乱背景、畸形细节或不符合语义的元素。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode (Negative Prompt) | 无 | 将负向 Prompt 转化为 CLIP 嵌入,用于抑制不希望出现的视觉元素,保证生成图像质量和风格一致性。 |
FluxGuidance 文本嵌入调控
此节点接收 CLIPTextEncode 输出嵌入,通过 CFG 值调节文本嵌入在生成模型中的影响力,实现语义强化或柔化。Prompt 在此节点主要体现为嵌入权重调节,确保生成图像在深度引导和 LoRA 条件下保持风格一致且细节丰富。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| FluxGuidance | CFG: 10 | 调整 CLIP 嵌入在生成模型中的权重,使生成图像在深度图和 LoRA 引导下保持语义准确、细节丰富和风格统一。 |
使用方法
该工作流结合深度图、LoRA 模型和文本嵌入,实现高精度可控图像生成。用户提供原图,CLIPTextEncode 将正向 Prompt 转化为嵌入,FluxGuidance 调整嵌入权重后输入 InstructPixToPixConditioning 节点进行条件生成,同时结合深度图信息生成潜在图像。KSampler 完成潜变量采样,VAELoader 和 VAEDecode 将潜在图像解码成最终图像,由 SaveImage 输出。用户可通过修改 Prompt 或 CFG 值调整生成效果,实现可控、精致且风格一致的图像生成。
| 注意点 | 说明 | |
|---|---|---|
| Prompt 描述精细 | 确保角色特征、场景和动作符合预期 | |
| 使用负向 Prompt | 避免生成杂乱或不符合语义的元素 | |
| 深度图质量高 | 深度图越精准,生成图像结构越清晰 | |
| CFG 值合理 | 控制文本嵌入对生成模型的影响,平衡自由度和语义准确性 | |
| LoRA 模型兼容 | 保证 LoRA 权重与生成模型匹配,确保风格一致 |
应用场景
这一工作流的应用场景广泛,特别适合需要结构一致性和深度信息约束的生成任务。在角色设计中可以确保姿态与背景结构自然统一;在建筑与场景还原中能保证透视关系与空间层次感;在创意绘画与影视概念设计中则能快速生成符合空间逻辑的高质量画面。对典型用户而言,设计师、影视制作人和研究人员都能借助该流程实现结构化生成,输出效果更精准,且在多样性和可控性方面远超单一文本生成模式。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 角色设计 | 生成符合深度结构的角色形象 | 插画师、游戏美术 | 人物姿态、光影表现 | 保持动作合理性与细节真实感 |
| 建筑还原 | 构建符合透视规律的建筑场景 | 建筑设计师、3D建模师 | 室内外建筑草图 | 结构层次分明,空间透视自然 |
| 场景设计 | 快速生成具备深度感的场景画面 | 影视概念艺术家 | 整体场景草图 | 氛围统一,空间感强烈 |
| 创意绘画 | 基于深度图与文本约束生成艺术化图像 | 数字艺术创作者 | 超现实主义或实验性画作 | 图像更具创意性和结构合理性 |
| 研究实验 | 探索深度信息对生成效果的影响 | AI研究人员 | 不同深度约束下的生成对比 | 提供数据支持与实验参考 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用