10 Regularization to Reduce Overfitting
10.1 The Problem of Overfitting
过拟合 Overfitting,通常也可以描述为 High Variance (高方差)
欠拟合 Underfitting,通常也可以描述为 High Bias (但这个词也有很多别的用法)
正则化 Regularization 是常用的缓解过拟合问题的方法
泛化 Generalization 指模型在没见过的新的例子上也能表现良好的能力
过拟合的例子(泛化能力差):
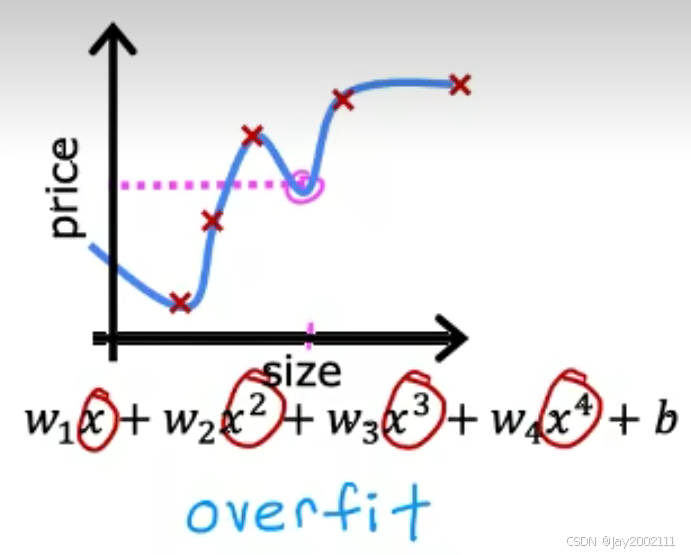
10.2 解决过拟合 Addressing Overfitting
- 收集更多的训练数据
- 考虑使用更少的特征,最合适的特征
通常,特征数量少于合理值导致欠拟合,特征数量多于合理值导致过拟合
要选择最合理的特征,泛化强的特征 --> Feature Selection - 正则化 Regularization
减少过大的特征参数权重wjw_jwj,防止某一特征产生过大的影响
与策略2去除特征类似,但是更温和,不是完全把wjw_jwj置0
注:一般只正则化w,而参数b是否正则化通常不会造成很大影响
总结一下:

10.3 Cost Function with Regularization
可以让成本函数加上若干倍想降低的wjw_jwj的平方:
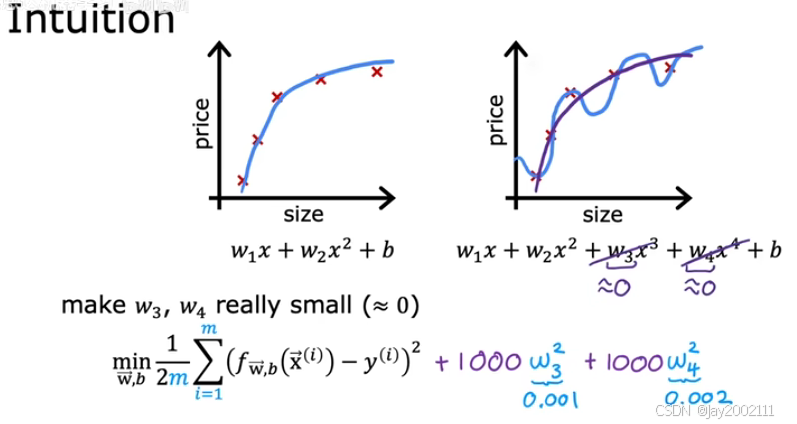
但大多数情况下,特征很多,我们也并不知道哪些特征要被弱化/惩罚
所以,对所有wjw_jwj都这样操作正则化,缩小所有wjw_jwj,可以得到一个更平滑的函数,不容易过拟合
注:大多数情况下,参数b是否正则化影响并不大,所以一般不必对b进行正则化
现在,我们记m代表有m个训练样本,n代表有n个特征,那么,我们有:
J(w⃗,b)=12m∑i=1m(fw⃗,b(x⃗(i))−y(i))2+λ∑j=1nwj2J(\vec w, b) = \frac{1}{2m}\sum_{i=1}^{m}(f_{\vec w, b}(\vec x^{(i)})-y^{(i)})^2 + \lambda\sum_{j=1}^{n}w_j^2J(w ,b)=2m1i=1∑m(fw ,b(x (i))−y(i))2+λj=1∑nwj2
但是通常我们会将λ\lambdaλ也进行12m\frac{1}{2m}2m1的缩放,事实证明这样操作的话,λ\lambdaλ的取值在m增大,即训练集规模增大的同样表现良好:
J(w⃗,b)=12m∑i=1m(fw⃗,b(x⃗(i))−y(i))2+λ2m∑j=1nwj2J(\vec w, b) = \frac{1}{2m}\sum_{i=1}^{m}(f_{\vec w, b}(\vec x^{(i)})-y^{(i)})^2 + \frac{\lambda}{2m}\sum_{j=1}^{n}w_j^2J(w ,b)=2m1i=1∑m(fw ,b(x (i))−y(i))2+2mλj=1∑nwj2
注:
- 这里的λ\lambdaλ称作 正则化参数(Regularization Parameter) ,类似学习率α\alphaα,也是一个需要确定的超参数
- 现在我们的目标是最小化J(w⃗,b)J(\vec w, b)J(w ,b),它由两项组成,前者是均方误差(Mean Squared Error,MSE),后者是正则化项(Regularization Term),而λ\lambdaλ描述了对两者之间的重要性的权衡,前者鼓励算法的预测值更贴近训练集的真实值,而后者鼓励算法减小w而减少过拟合
- 极端情况:如果λ\lambdaλ置0,那么完全没有正则化项,预测函数可能过拟合得非常严重;如果λ\lambdaλ置为一个极大的数,那么以线性回归为例,所有的w为了满足使正则化项变小,w将会变得趋于0,那么只剩下b,预测函数将会趋于直线b,严重欠拟合。所以,λ\lambdaλ的值控制了模型过拟合和欠拟合的平衡
10.4 Regularized Linear Regression
回顾之前的线性回归梯度下降公式:
wj=wj−α∂∂wjJ(w⃗,b)b=b−α∂∂bJ(w⃗,b)w_j = w_j - \alpha \frac {\partial} {\partial w_j}J(\vec w, b) \\ b = b - \alpha \frac {\partial} {\partial b}J(\vec w, b)wj=wj−α∂wj∂J(w ,b)b=b−α∂b∂J(w ,b)
添加正则化项的情况下不难发现,b的表达式并不会变化,因为我们没有对b正则化。w的表达式,正则化项会引入一个新的导数项,那么有:
∂∂wjJ(w⃗,b)=1m∑i=1m(fw⃗,b(x⃗(i))−y(i))xj(i)+λmwj∂∂bJ(w⃗,b)=1m∑i=1m(fw⃗,b(x⃗(i))−y(i))\frac {\partial} {\partial w_j} J(\vec w, b) = \frac 1 m \sum_{i=1}^{m}(f_{\vec w, b}(\vec x^{(i)})-y^{(i)})x_j^{(i)} + \frac \lambda m w_j \\ \frac {\partial} {\partial b} J(\vec w, b) = \frac 1 m \sum_{i=1}^{m}(f_{\vec w, b}(\vec x^{(i)})-y^{(i)})∂wj∂J(w ,b)=m1i=1∑m(fw ,b(x (i))−y(i))xj(i)+mλwj∂b∂J(w ,b)=m1i=1∑m(fw ,b(x (i))−y(i))
完整地写出来:
wj=wj−α1m∑i=1m(fw⃗,b(x⃗(i))−y(i))xj(i)+λmwjb=b−α1m∑i=1m(fw⃗,b(x⃗(i))−y(i))w_j = w_j - \alpha \\frac 1 m \\sum_{i=1}\^{m}(f_{\\vec w, b}(\\vec x\^{(i)})-y\^{(i)})x_j\^{(i)} + \\frac \\lambda m w_j \\ b = b - \alpha \frac 1 m \sum_{i=1}^{m}(f_{\vec w, b}(\vec x^{(i)})-y^{(i)})wj=wj−αm1i=1∑m(fw ,b(x (i))−y(i))xj(i)+mλwjb=b−αm1i=1∑m(fw ,b(x (i))−y(i))
我们把关于wjw_jwj的式子改写一下:
wj=wj(1−αλm)−α1m∑i=1m(fw⃗,b(x⃗(i))−y(i))xj(i)w_j = w_j(1-\alpha \frac{\lambda}{m}) - \alpha \frac 1 m \sum_{i=1}^{m}(f_{\vec w, b}(\vec x^{(i)})-y^{(i)})x_j^{(i)}wj=wj(1−αmλ)−αm1i=1∑m(fw ,b(x (i))−y(i))xj(i)
后一项与不带正则化项的梯度下降一致,唯一的区别在于wjw_jwj在更新中不断缩小(1−αλm1-\alpha \frac{\lambda}{m}1−αmλ是一个略小于1的数值)
10.5 Regularized Logistic Regression
和不带正则化的逻辑回归类似,带正则化的逻辑回归的梯度下降也与线性回归的表达式看起来类似,但同样需要注意,里面的fw⃗,b(x⃗)f_{\vec w, b}(\vec x)fw ,b(x )不一样。
wj=wj(1−αλm)−α1m∑i=1m(fw⃗,b(x(i))−y(i))xj(i)b=b−α1m∑i=1m(fw⃗,b(x(i))−y(i))w_j = w_j(1-\alpha \frac{\lambda}{m})-\alpha\frac{1}{m}\sum_{i=1}^{m}(f_{\vec w, b}(x^{(i)})-y^{(i)})x_j^{(i)} \\ b = b-\alpha\frac{1}{m}\sum_{i=1}^{m}(f_{\vec w, b}(x^{(i)})-y^{(i)})wj=wj(1−αmλ)−αm1i=1∑m(fw ,b(x(i))−y(i))xj(i)b=b−αm1i=1∑m(fw ,b(x(i))−y(i))