背景
在LLM涌现的早期已经有大量的研发人员开始思考、讨论和推广Multi-Agent的概念。它的基本实现逻辑就是:利用LLLM的归纳推理能力,通过为不同的Agent分配角色与任务,并配合相应的工具(tools)插件来完成复杂的任务。
但经过这两三年的发展,关于Multi-Agent的讨论依旧存在截然不同的观点,真实案例更寥寥可数,也没有形成标准的行业范式。在Manus内部人员的访谈记录中,也坦言,在Manus的功能实现中并没有使用复杂的Multi-Agent工程。
在本人主导开发的AI原生项目中,使用了大量的基于LLM的Workflow能力,但对于Multi-Agent也是望而却步,因为实践的结果与预期的差距太大。
这篇文章结合国外一篇关于Multi-Agent观念,一起聊聊对于Multi-Agent的观点和看法。
Agent时代的现状
随着LLM的快速突破,目前算是正式进入了LLM和AI Agent时代的早期。这个时期可以用Web开发来进行类比,就相当于正处于使用原始的HTML & CSS来开发网页的时代。至于像Web开发后面的React(及其衍生框架)以及相关的脚手架、构建模式以及开发哲学等,都还处于大众探索创新的阶段。
目前对于LLM和AI Agent的使用,大家都是在一边摸索一边前行,比如探索如何把这些功能拼到一起,如何提供良好的体验,如何保证系统的鲁棒性等。除了几种最基础的方式之外,还没有哪一种Agent构建方法成为主流标准。
即便是OpenAI的Swarm类库和微软的Autogen类库中推崇的一些概念,也没有得到普遍的认可,甚至是错误的Agent构建方法。
当进行Agent构建时,市面上已经有不少基础的脚手架项目,但真正拿它们来运用到生产项目中,还是有很长的距离。
长时运行Agent的构建理论
长时运行Agent(Long-running Agents),通常是指AI能够跨多个会话、多次工具调用和多阶段产物,来完成一个目标。长时运行Agent更强调大模型的自治以及动态上下文的管理,需要AI Agent能够支持长时间的运行来解决问题,同时,还需要更好的自主规划与调度能力,选择行使用上下文的能力等。
另外,一个很重要的指标就是可靠性,Agent想要真正的可靠、长时间运行、以及保持连贯对话,就必须做一些额外的事来控制错误的累积。否则,一个小的错误,在后续步骤中放大,形成错误链,造成整个Agent工程的不可控。而可靠性的核心保障就是"上下文工程"。
上下文工程
截至目前,市面上的大模型已经非常智能了,但就算最聪明的人,没有了解清楚自己被要求做什么的上下文,也无法高效工作。
"Prompt engineering"曾是LLM聊天机器人需要将任务以理想格式表达时的产物,而"上下文工程"则是下一个阶段。它的意义,是要在动态系统中自动完成这件事。这更微妙,基本上也是Agent工程师的首要工作。
举个常见的Agent例子:
- 把自己的任务分解成几个部分;
- 启动子Agent处理这些部分;
- 最后把各部分结果合并起来
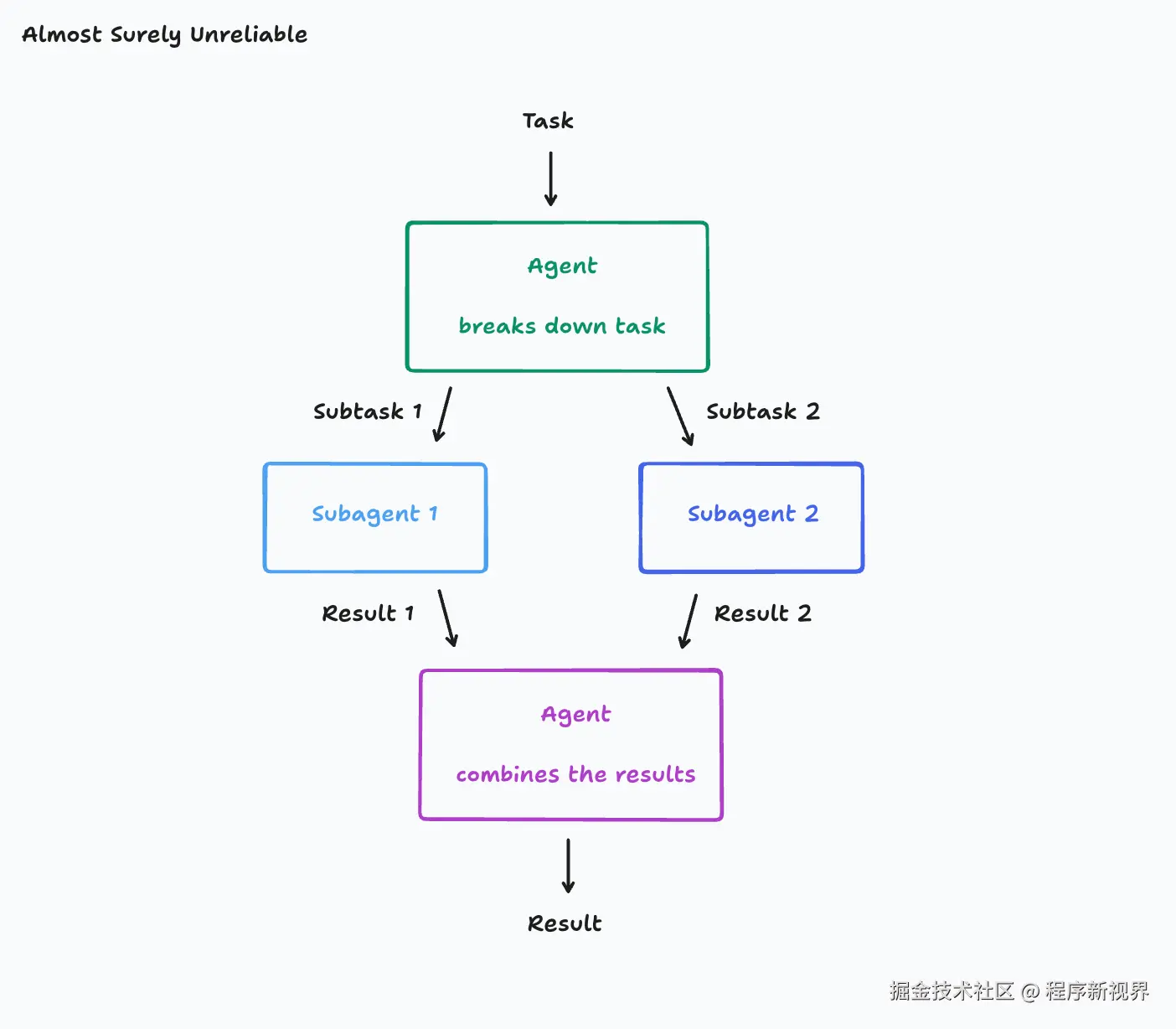
这种架构很有诱惑力,特别是在处理多个并行组件的任务时。不过,这种架构也非常脆弱,它的核心问题是:
假设所需的任务是"做一个Flappy Bird的克隆版"。任务会被拆分为两个子任务:子任务一是"做一个有绿色管道和碰撞盒的移动游戏背景",子任务二是"做一个能上下移动的小鸟"。
结果,Subagent1 搞错了子任务,做出了一个看起来像超级马里奥兄弟的背景。Subagent2 实现了小鸟,但它既不像游戏素材,也没有 Flappy Bird 的移动方式。现在最终的 Agent 只能把这两个误解的结果拼到一起,变成一个尴尬的合成品。
也许这个例子有点生硬,但现实中的任务往往有许多细微层面,每一层都有可能被误解。
你可能会认为,简单的办法就是把原始任务内容也复制给Subagent作为上下文,这样它们就不会误解自己的子任务了。但别忘了,在实际生产系统中,Agent 往往涉及多轮对话,经常需要调用工具来决定如何拆解任务,很多细节都会影响对任务的解读。
原则一:共享上下文,并且共享完整的Agent轨迹(trace),而不仅仅是单独的信息文本。
现在对Agent架构进行下一步改进,这次要确保每个Agent都能获得前面Agent的完整上下文。
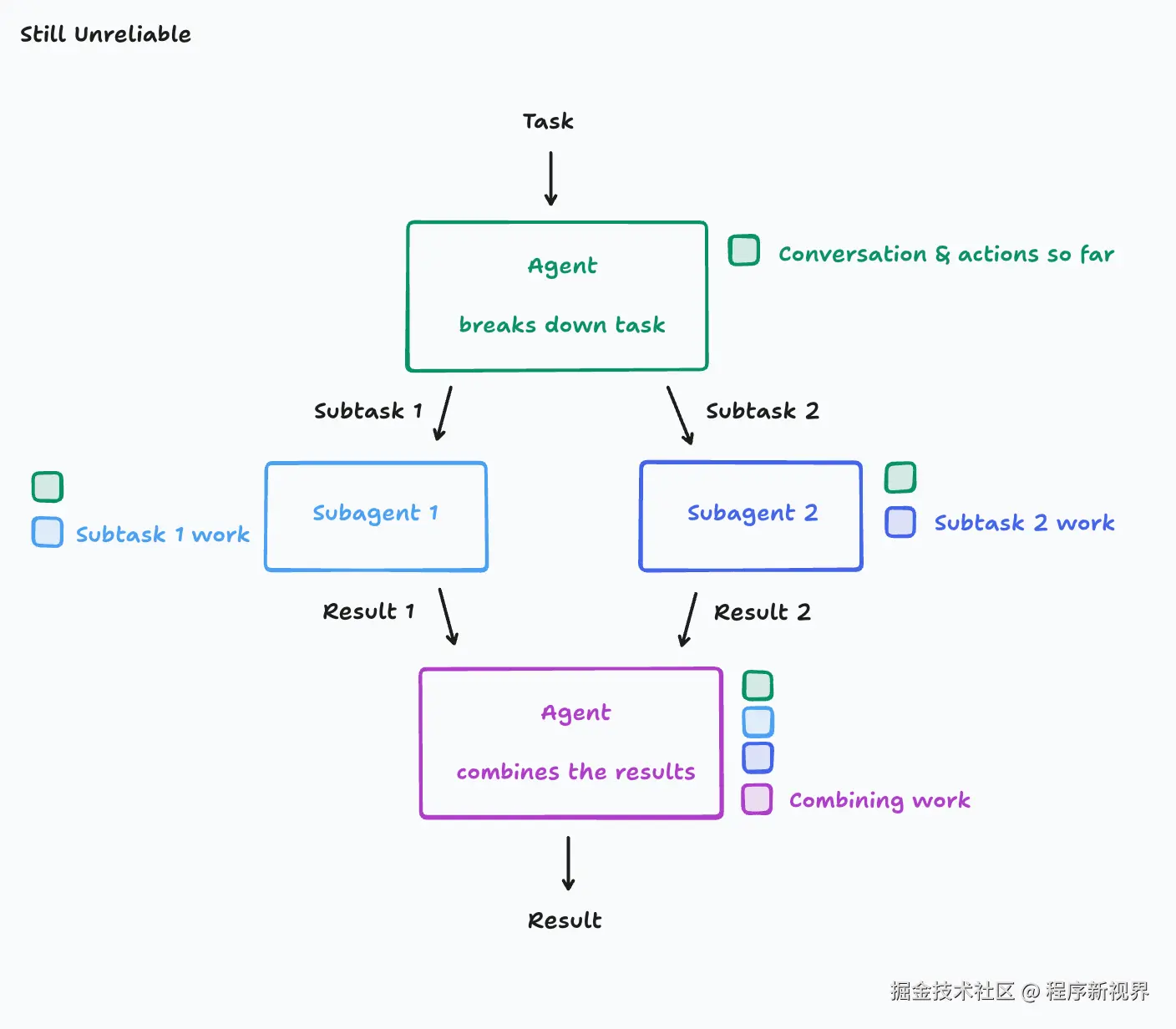
很遗憾,事情还没那么简单。当再次给Agent提出Flappy Bird的克隆任务时,最终可能得到的是一只小鸟和一个背景,但它们的视觉风格完全不同。Subagent1 和Subagent2 并不知道对方在做什么,所以各自完成的部分根本不统一。
Subagent1和Subagent2所采取的动作,都是基于各自不同且事先未明确规定的假设。
原则二:动作会带来隐含的决策,而冲突的决策会带来糟糕的结果。
原则一和原则二非常关键,几乎没有违背它们的理由,所以默认就应该排除任何不遵守这两个原则的Agent架构。也许你觉得这样有些局限,但其实还有很多可以探索的不同架构方式。
遵循这些原则最简单的方法,就是采用单线程、线性式的Agent:
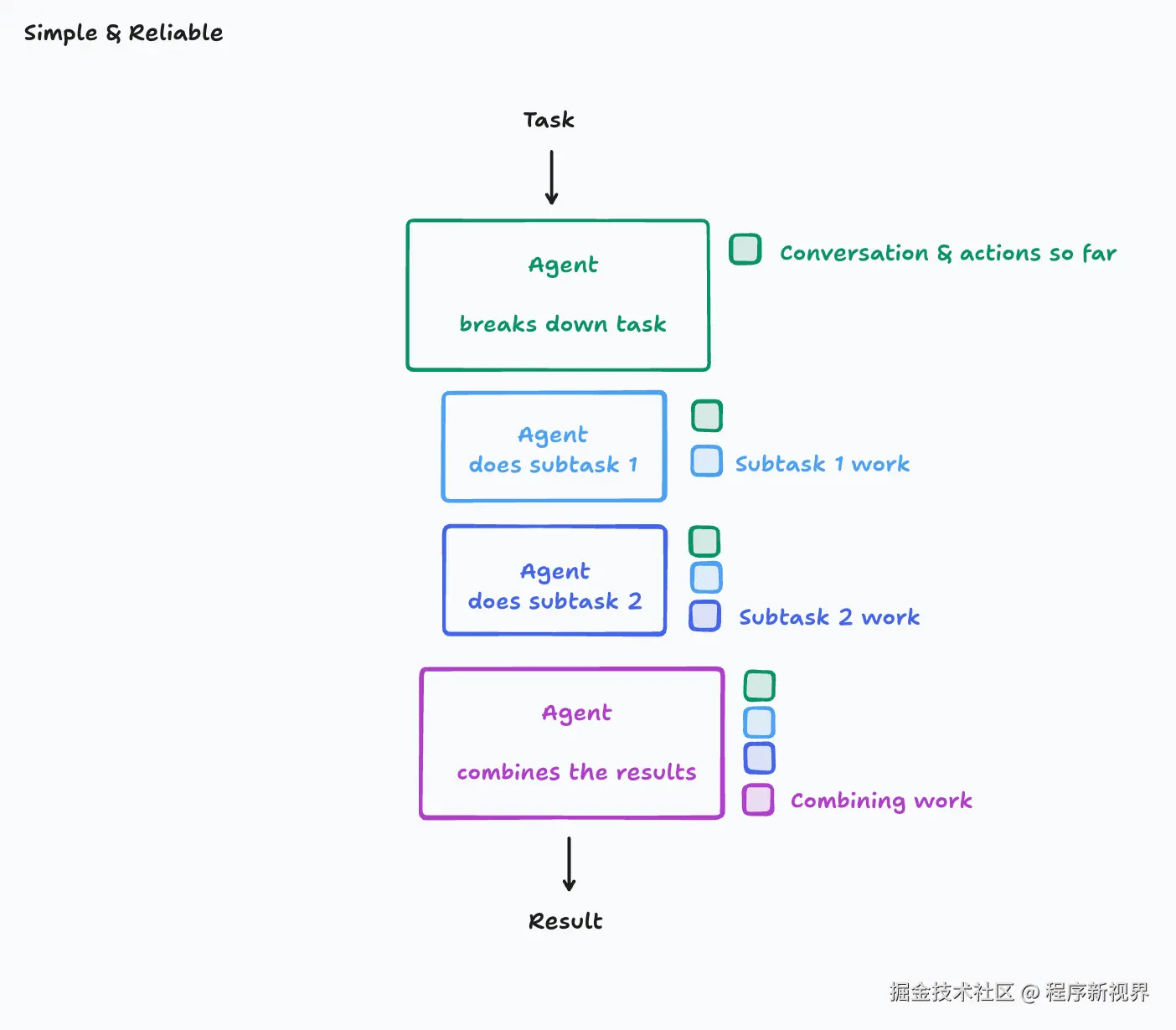
在这种架构下,上下文是连续的。不过,如果任务非常庞大、包含大量子任务,可能会遇到上下文窗口溢出的情况。
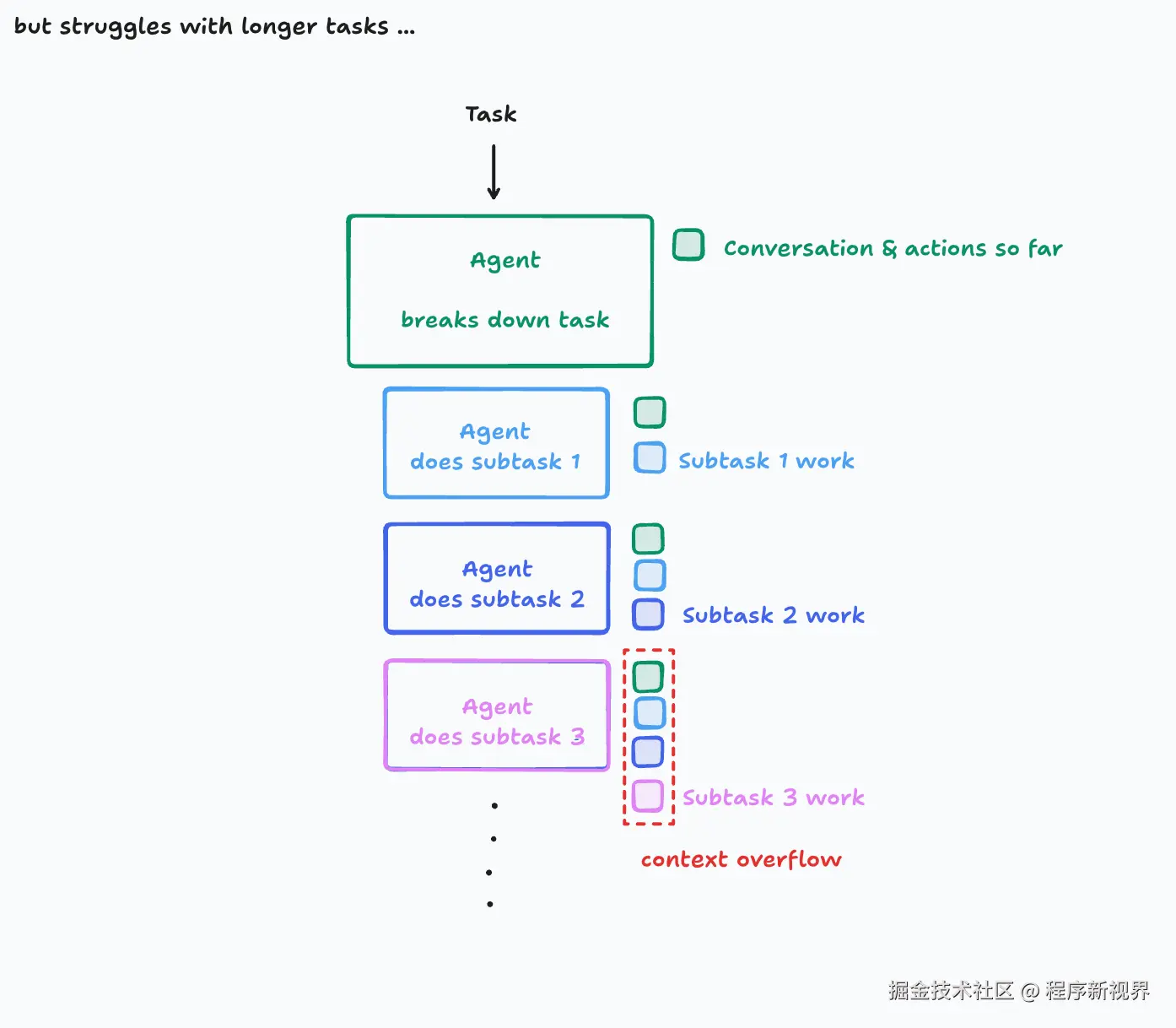
这种简单的架构已经能应对绝大多数场景,但如果你的任务真的需要长时间运行,并且你愿意投入更多精力,其实还可以做得更好。
比如:
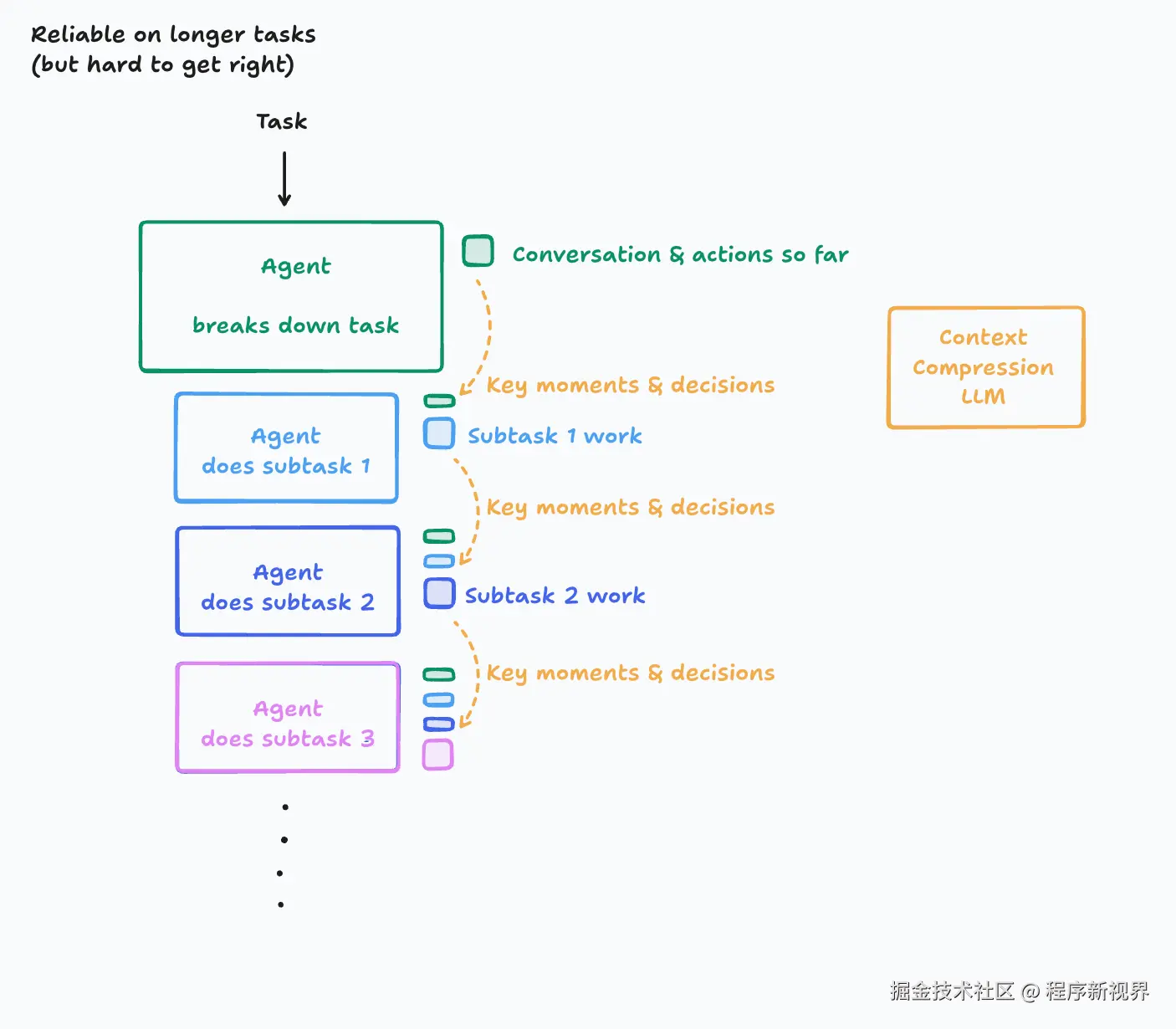
在这个架构中,引入了一个新的 LLM 模型,其核心作用是将一系列的动作和对话历史压缩成关键细节、事件和决策。
这其实很难做好,需要投入精力搞清楚哪些才是真正重要的信息,并搭建一个模型擅长识别这些内容的系统。根据不同领域,甚至可能需要微调一个更小的模型。
这样做的好处是,可以让Agent在更长的上下文中仍然高效工作。当然,最终还是会遇到上下文长度的极限。
原则的应用案例
作为Agent的开发者,要确保Agent的每一步操作都参考了系统其它部分已经做出的所有相关决策的上下文。理想情况下,每个动作都能"看到"其它所有动作的信息。
可惜,受限于上下文窗口和实际工程权衡,这往往做不到,需要结合可靠性目标,决定Agent能接受多复杂的架构。
在思考如何架构Agent、避免冲突决策时,这里有一些真实案例可以参考:
Claude Code 子Agent
Claude Code是一个能够生成子任务的 Agent 示例。不过,它不会跟子Agent并行做事,而且子Agent通常只是被要求回答一个问题,不会去写任何代码。
为什么?因为子Agent缺少主Agent的上下文,除了回答那些定义非常清晰的问题,其他任务就无法做。而如果让多个并行的子Agent协作,结果可能互相冲突,导致在Agent架构上遇到之前说的可靠性问题。
在Claude Code的设计里,子Agent的全部调研工作不需要留在主Agent的历史记录中,这样可以更长时间保留上下文。设计者刻意采用了简化方案。
Edit Apply 模型
2024年,许多模型在编辑代码上的表现非常差。很多Coding Agent、IDE、App Builder 等(包括 Devin),都采用了"edit apply model"(编辑应用模型)。
核心思路是,与其让大模型输出格式正确的diff,不如让小模型根据Markdown格式的编辑说明重写整个文件来得可靠。
所以实际操作中,开发者让大模型输出Markdown说明代码改动,然后把这些说明交给小模型来重写文件。但这种系统仍然容易出错。比如,小模型可能会错误理解大模型的指令,只要指令中稍有歧义,就会导致错误编辑。现在,代码编辑和应用更多是由一个模型一步完成。
多 Agent 协作
如果真要让系统并行处理任务,你可能也会想到让决策者之间"互相沟通"共同解决问题。
这也是人类遇到分歧(理想情况下)会做的事。如果工程师 A 的代码与工程师 B 的代码发生合并冲突,标准流程就是大家相互交流,达成一致。但时至今日,AI Agent之间尚不具备像人一样,能在超长上下文下高可靠性地主动沟通。
自从ChatGPT推出后,大家一直在探索多 Agent 交互协作来解决问题。从长期来看,Agent协作的长期很乐观,但目前多Agent协作系统还是非常脆弱。还存在决策太分散,Agent之间上下文也无法充分共享等问题。
当然,未来单线程Agent和人类沟通越来越顺畅后,这个难题自然而然就会解决。那时候会彻底释放更高并行度和效率。
小结
这些关于上下文工程的观察和讨论,只是未来成为Agent构建标准原则的一个起点。实际上还有很多各种挑战和技术没讨论。同时,Agent构建也是非常重要的前沿方向。
我们在实践中,可以利用本文提到的一些原则和解决方案,指导内部工具和框架的开发,通过实践和总结来不断完善Agent工程的落地。