论文题目:EfficientTrain++: Generalized Curriculum Learning for Efficient Visual Backbone Training(高效视觉骨干训练的通用课程学习)
期刊:TPAMI(计算机科学 Top)
摘要:现代计算机视觉主干的优越性能(例如,在imagenet1k / 22k上学习的视觉变形金刚)通常伴随着昂贵的训练过程。这项研究有助于解决这一问题,它将课程学习的概念推广到其原始公式之外,即使用易到难的数据来训练模型。具体来说,我们将训练课程重新制定为软选择函数,在训练过程中,在每个示例中逐步发现更困难的模式,而不是执行简单到困难的样本选择。我们的工作灵感来自于对视觉主干学习动态的有趣观察:在训练的早期阶段,模型主要学习识别数据中一些"容易学习"的判别模式。当通过频率和空间域观察到这些模式时,它们包含了低频分量和自然图像内容,而没有失真或数据增强。在这些发现的激励下,我们提出了一个课程,其中模型总是在每个学习阶段利用所有的训练数据,但首先开始接触每个示例的"容易学习"模式,随着训练的进展逐渐引入更难的模式。为了以高效的计算方式实现这一想法,我们在输入的傅里叶谱中引入了裁剪操作,使模型仅从低频分量中学习。然后我们表明,通过调制数据增强的强度可以很容易地实现自然图像的内容暴露。最后,我们将这两个方面结合起来,通过提出定制的搜索算法来设计课程学习计划。在具有挑战性的实际场景中,例如大规模并行训练,有限的输入/输出或数据预处理速度。由此产生的方法efficienttrain++简单、通用,但却出奇地有效。作为一种现成的方法,它将各种流行模型(例如,ResNet, ConvNeXt, DeiT, PVT, Swin, CSWin和CAFormer)的训练时间在ImageNet-1 K/22 K上减少了1.5 - 3.0倍,而不牺牲精度。它也证明了自我监督学习(例如MAE)的有效性。
EfficientTrain++:让视觉模型训练提速3倍的优雅方案
引言:训练大模型有多贵?
想象一下,训练一个ViT-H/14模型需要消耗2500 TPUv3核心天数------这相当于一台配备8块高端GPU的服务器不间断工作近一年!对于大多数研究者和工程师来说,这样的成本几乎是不可承受的。
更糟糕的是,随着模型规模和数据集的不断增长,这个问题只会越来越严重。那么,有没有办法在不牺牲模型性能的前提下,大幅降低训练成本呢?
清华大学的研究团队给出了一个优雅的答案:EfficientTrain++,发表在顶级期刊IEEE TPAMI 2024上。
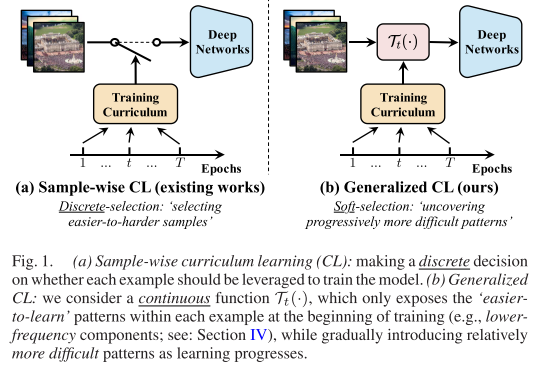
核心思想:不是选择样本,而是选择模式
传统课程学习的困境
传统的课程学习(Curriculum Learning)试图让模型从"简单样本"学到"困难样本"。但这种方法面临两个根本性挑战:
- 如何定义"简单"和"困难"? 不同任务、不同阶段的答案可能完全不同
- 困难样本就应该后学吗? 研究表明,有时"hard-to-easy"的反课程反而更有效
范式转变:广义课程学习
EfficientTrain++提出了一个突破性的观点:
问题不在于样本本身的难易,而在于每个样本包含的不同模式有难易之分
具体来说:
- ✅ 使用所有训练样本(不做样本选择)
- ✅ 早期只暴露"易学"的模式
- ✅ 逐渐引入"难学"的模式
这就像教孩子认识动物:不是先只看猫、再只看狗,而是先看所有动物的整体轮廓(低频信息),再逐步看清它们的细节纹理(高频信息)。
技术深度解析
发现一:神经网络优先学习低频信息
研究团队通过精心设计的实验发现了一个重要现象:
实验设计:
- 对训练图像进行低通滤波(只保留半径r内的低频成分)
- 在过滤后的数据上训练模型
- 观察验证精度随训练进行的变化
惊人发现:
- 当r较小时(只保留低频),训练早期的曲线与基线完全一致
- 只有训练到中后期,两条曲线才开始分离
- 随着r增大,分离点越来越晚
结论:模型在自然训练过程中,天然就是先学习低频信息,后学习高频信息!
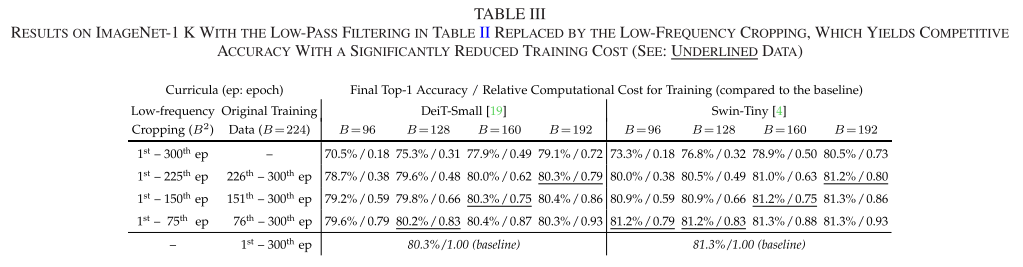
创新二:频域裁剪操作

基于上述发现,一个自然的想法是:既然早期只需要低频信息,为什么不让模型只处理低频信息,从而降低计算成本?
核心操作:低频裁剪(Low-Frequency Cropping)
# 伪代码示意
def low_freq_crop(image, bandwidth_B):
# 1. 转到频域
freq_spectrum = FFT2D(image) # H×W → H×W频谱
# 2. 中心裁剪(保留低频)
cropped_spectrum = center_crop(freq_spectrum, B, B) # B×B
# 3. 转回空间域
cropped_image = IFFT2D(cropped_spectrum) # B×B图像
return cropped_image三大优势:
- 无损提取:精确保留所有B×B范围内的低频信息
- 严格消除:完全去除高频成分
- 降低计算:输入尺寸从H×W降到B×B,计算量降低(H×W)/(B×B)倍
论文还严格证明了(命题1):这种方法在理论上优于简单的图像下采样。
创新三:智能课程搜索算法
有了低频裁剪这个工具,下一个问题是:如何确定训练过程中B的变化计划?
新颖的优化问题:
最大化:最终验证精度
约束条件:总训练成本 ≤ β × 基线成本其中β是预设的成本节省比例(如β=2/3表示只用基线2/3的成本)。
Algorithm 2的巧妙之处:
- 顺序搜索:从第一阶段到最后阶段依次确定B值
- 动态平衡:B小时增加训练步数,B大时减少步数,保持每阶段计算量相等
- 代理评估:通过短期微调快速评估不同B的效果
- 一次搜索,处处适用:在小模型上搜索得到的课程可直接用于大模型
结果:搜索成本比原方法降低2.56倍,且得到的课程效果更好!
创新四:解决工程瓶颈
理论再美,也要能高效实现。EfficientTrain++还提出了两个关键的工程技术:
1. Early Large Batch(解决并行扩展性)
问题:当B很小时(如96),单批次计算太快,GPU利用率低,难以充分利用多卡并行。
解决方案:
# 动态调整学习率和批次大小
max_lr_B = min(
max_lr_224 * sqrt(batch_size_B / batch_size_224),
max_lr_upper_bound
)效果:64 GPU训练时加速比与16 GPU相当!
2. Replay Buffer(降低数据预处理负载)
问题:B小时模型训练快,但需要更高的数据预处理吞吐量,CPU/内存成为瓶颈。
解决方案:
- 缓存最近预处理的数据
- 交替进行:采样nbuffer次缓存数据 + 预处理1批新数据
- 降低预处理负载(nbuffer+1)倍
实验结果
标准监督学习(ImageNet-1K)
跨架构的一致性提升:
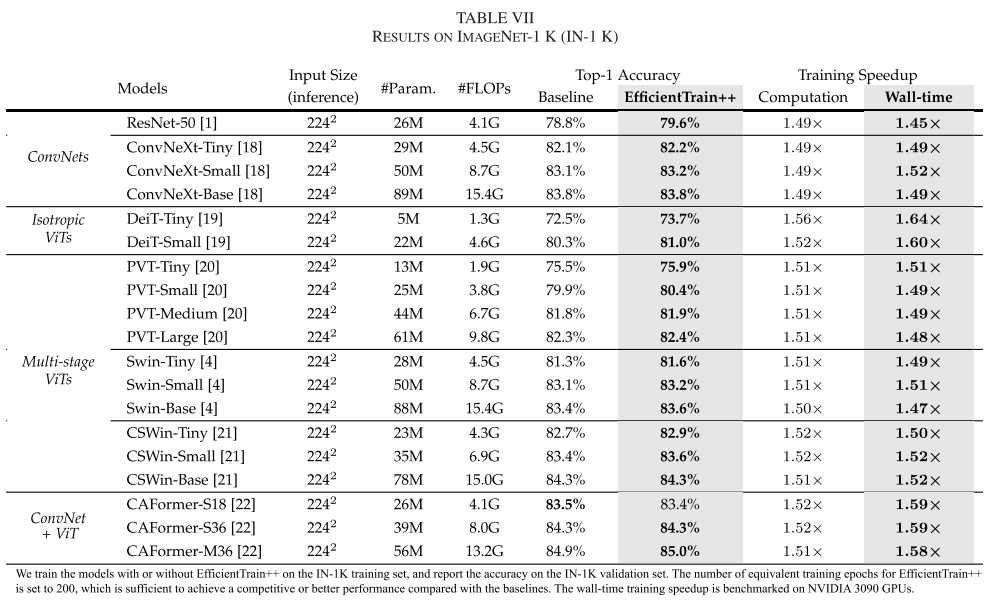
在相同训练成本下(200 equivalent epochs):
- DeiT-Small: 80.4% → 81.0% (+0.6%)
- Swin-Tiny: 81.2% → 81.3% (+0.1%)
- ConvNeXt-Tiny: 82.1% → 82.1% (持平)
- CAFormer-M36: 84.9% → 85.0% (+0.1%)
墙时训练加速:1.5-1.6×
达到相同精度时:
- 训练成本节省:2-3×
- 特别是在训练预算受限时效果更明显
大规模预训练(ImageNet-22K)
这是EfficientTrain++最令人印象深刻的结果:
CSWin-Large:
- 基线训练时间:237.8 GPU天
- EfficientTrain++:79.3 GPU天
- 节省158.5 GPU天!(在8卡服务器上相当于节省近20天)
- 加速比:3.0×
- 精度:持平或更优
自监督学习(MAE)
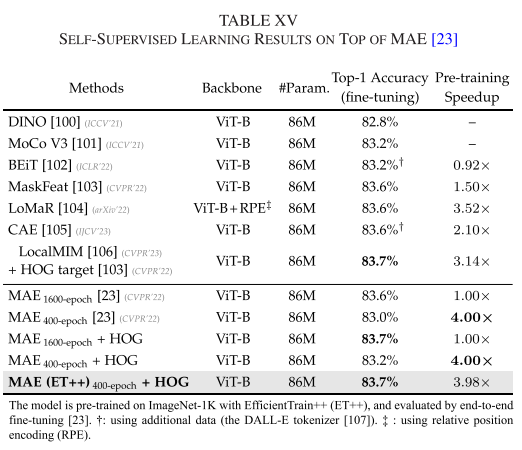
EfficientTrain++不仅适用于监督学习,在自监督学习中同样有效:
MAE + EfficientTrain++:
- 预训练成本:300 epochs → 200 epochs
- ImageNet-1K精度:83.6% → 83.6%(持平)
- COCO目标检测:APbox 51.6 → 51.7(微升)
迁移学习:预训练收益完整传递
一个关键问题是:用EfficientTrain++训练的模型,迁移能力会受影响吗?
答案是:不仅不会,反而更好!
下游任务表现:
目标检测(Mask R-CNN on COCO):
- Swin-T基线:APbox 46.0, APmask 41.6
- ET++ Swin-T:APbox 46.9 (+0.9), APmask 42.3 (+0.7)
语义分割(UperNet on ADE20K):
- DeiT-S基线:mIoU 44.0
- ET++ DeiT-S:mIoU 45.1 (+1.1)
细粒度分类(Stanford Dogs):
- DeiT-S基线:89.0%
- ET++ DeiT-S:89.7% (+0.7%)
这些结果表明,EfficientTrain++训练的模型不仅在ImageNet上表现好,特征的通用性和可迁移性也更强。
为什么EfficientTrain++如此有效?
理论解释
- 符合学习规律:利用了神经网络天然的学习顺序(低频→高频)
- 信息无损:低频裁剪精确保留所有重要信息
- 计算高效:输入尺寸减小直接降低计算量
- 逐步增强:配合数据增强强度递增,完整利用数据
与其他方法的对比优势
| 特性 | 传统课程学习 | 渐进式训练 | EfficientTrain++ |
|---|---|---|---|
| 样本利用 | 部分样本 | 全部样本 | 全部样本 |
| 难度定义 | 需要度量器 | 固定规则 | 自然规律 |
| 实现复杂度 | 高 | 中 | 低 |
| 通用性 | 差 | 中 | 强 |
| 效率提升 | 1-1.3× | 1.2-1.5× | 1.5-3.0× |
实用建议:如何使用EfficientTrain++
1. 开箱即用
对于常见场景(ImageNet-1K训练,最终输入224×224),直接使用论文提供的课程:
# 训练阶段配置
stages = [
{'epochs': '0-40%', 'B': 96, 'augment_mag': '0→m0'},
{'epochs': '40-70%', 'B': 128, 'augment_mag': '→m0'},
{'epochs': '70-100%', 'B': 224, 'augment_mag': 'm0'},
]2. 自定义场景
如果目标输入尺寸不是224,简单调整即可:
# 对于最终输入γ×γ
stages = [
{'epochs': '0-40%', 'B': 96, ...},
{'epochs': '40-70%', 'B': (96+γ)/2, ...},
{'epochs': '70-100%', 'B': γ, ...},
]3. 新数据集
多数情况下,ImageNet-1K课程可直接迁移。如果要优化:
- 在小模型上运行Algorithm 2(成本仅为训练该模型2-3次)
- 得到的课程可用于所有模型
4. 工程部署
- 多卡训练:启用Early Large Batch
- CPU/内存受限:启用Replay Buffer
- 两者都启用:获得最佳实际加速比
局限性与未来方向
当前局限
- 聚焦计算机视觉:主要在图像数据上验证
- 固定课程:所有模型使用相同课程
- 手工设计:低频提取基于先验知识
未来方向
- 可学习的模式提取:用神经网络自动学习"易学"模式
- 扩展到其他模态:NLP、音频、多模态学习
- 自适应课程:根据训练动态调整
- 与其他技术结合:混合精度训练、知识蒸馏等
结论:效率与性能的完美平衡
EfficientTrain++向我们展示了一个重要启示:
效率提升不一定以牺牲性能为代价,关键在于找到符合学习规律的方法
它的成功源于:
- ✅ 深刻的理论洞察(低频优先学习)
- ✅ 优雅的技术方案(频域裁剪)
- ✅ 实用的工程设计(搜索算法、实现技巧)
- ✅ 全面的实验验证(多模型、多任务、多场景)
对于研究者和工程师,EfficientTrain++提供了一个极具吸引力的选择:
- 简单:几行代码即可集成
- 通用:适用于各种架构和任务
- 高效:1.5-3.0倍加速,节省大量时间和成本
- 有效:不降低甚至提升模型性能
在AI大模型时代,这样的方法显得尤为珍贵。它不仅帮助我们训练更好的模型,也让AI研究更加绿色、经济、可持续。