在我们写代码的时候,不是每一次偶可以正确的运行成功,多多少少存在逻辑错误或语法错误,甚至都会有,而我们可以通过VS的调试功能来尽可能的规避这些错误,首先我们要先来了解几个知识点
什么是bug
bug本意是"昆⾍"或"虫子",现在⼀般是指在电脑系统或程序中,隐藏着的⼀些未被发现的缺陷或 问题,简称程序漏洞。 "Bug"的创始⼈格蕾丝·赫柏(GraceMurrayHopper),她是⼀位为美国海军⼯作的电脑专家, 1947年9月9日,格蕾丝·赫柏对HarvardMarkII设置好17000个继电器进⾏编程后,技术⼈员正在进⾏ 整机运行时,它突然停止了工作。于是他们爬上去找原因,发现这台巨⼤的计算机内部⼀组继电器的 触点之间有⼀只⻜蛾,这显然是由于⻜蛾受光和热的吸引,⻜到了触点上,然后被高电压击死。所以在报告中,赫柏用胶条贴上飞蛾,并把"bug"来表示"⼀个在电脑程序⾥的错误","Bug"这个说法⼀直沿用到今天

什么是调试(debug)
当我们发现程序中存在的问题的时候,那下⼀步就是找到问题,并修复问题。 这个找问题的过程叫称为调试,英文叫debug(消灭bug)的意思。 调试⼀个程序,首先是承认出现了问题,然后通过各种手段去定位问题的位置,可能是逐过程的调试,也可能是隔离和屏蔽代码的方式,找到问题所的位置,然后确定错误产生的原因,再修复代码,重新测试
在这里可以看到有一个Debug和一个Release,还有一个配置管理器(暂且不管)
Debug
通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序, 程序员在写代码的时候,需要经常性的调试代码,就将这⾥设置为debug ,这样编译产生的是debug 版本的可执行程序,其中包含调试信息,是可以直接调试的
Release
称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的, 以便用户很好地使用,当程序员写完代码,测试再对程序进行测试,直到程序的质量符合交付给用户, 使用的标准,这个时候就会设置为 release ,编译产生的就是 release 版本的可执行程序,这个版本是用户使用的,无需包含调试信息
我们来敲两段代码看一下区别

此时编译器生成了一个Debug版本的ceshi.exe文件
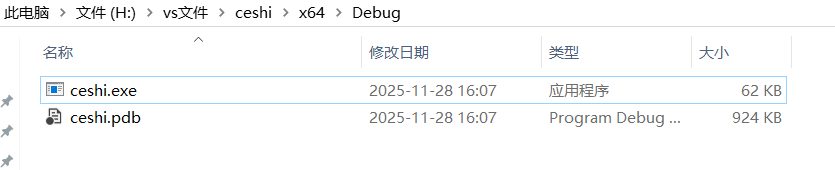
再来看一下Release
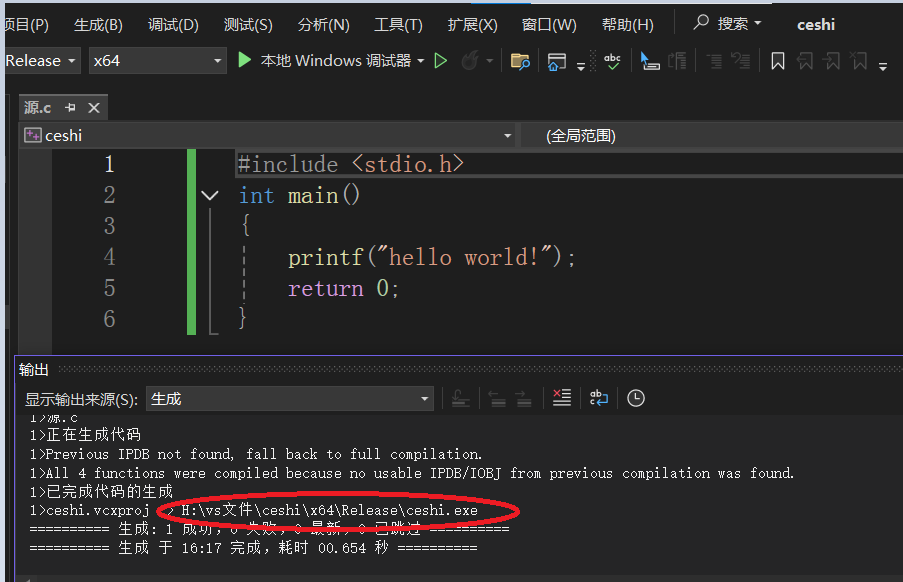

对比可以看到从同⼀段代码,编译⽣成的可执行文件的大小,release版本明显要小,而debug版本明显大
VS调试快捷键
调试最常使用的几个快捷键:
F9:创建断点和取消断点,断点的作用是可以在程序的任意位置设置断点,打上断点就可以使得程序执行到想要的位置暂停执行,接下来我们就可以使用F10,F11这些快捷键,观察代码的执行细节。 条件断点:满足这个条件,才触发断点
F5:启动调试,经常用来直接跳到下⼀个断点处,⼀般是和F9配合使用
F10:逐过程,通常用来处理⼀个过程,⼀个过程可以是⼀次函数调用,或者是⼀条语句
F11:逐语句,就是每次都执行⼀条语句,但是这个快捷键可以使我们的执行逻辑进⼊函数内部。在函数调用的地⽅,想进⼊函数观察细节,必须使用F11,如果使用F10,直接完成函数调用。 CTRL+F5:开始执行不调试,如果你想让程序直接运行起来而不调试就可以直接使用
监视和内存
在调试的过程中我们,如果要观察代码执⾏过程中,上下文环境中的变量的值,有哪些方法呢? 这些观察的前提条件⼀定是开始调试后观察
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int num = 100;
char c = 'w';
int i = 0;
for (i = 0; i < 10; i++)
{
arr[i] = i;
}
return 0;
}监视
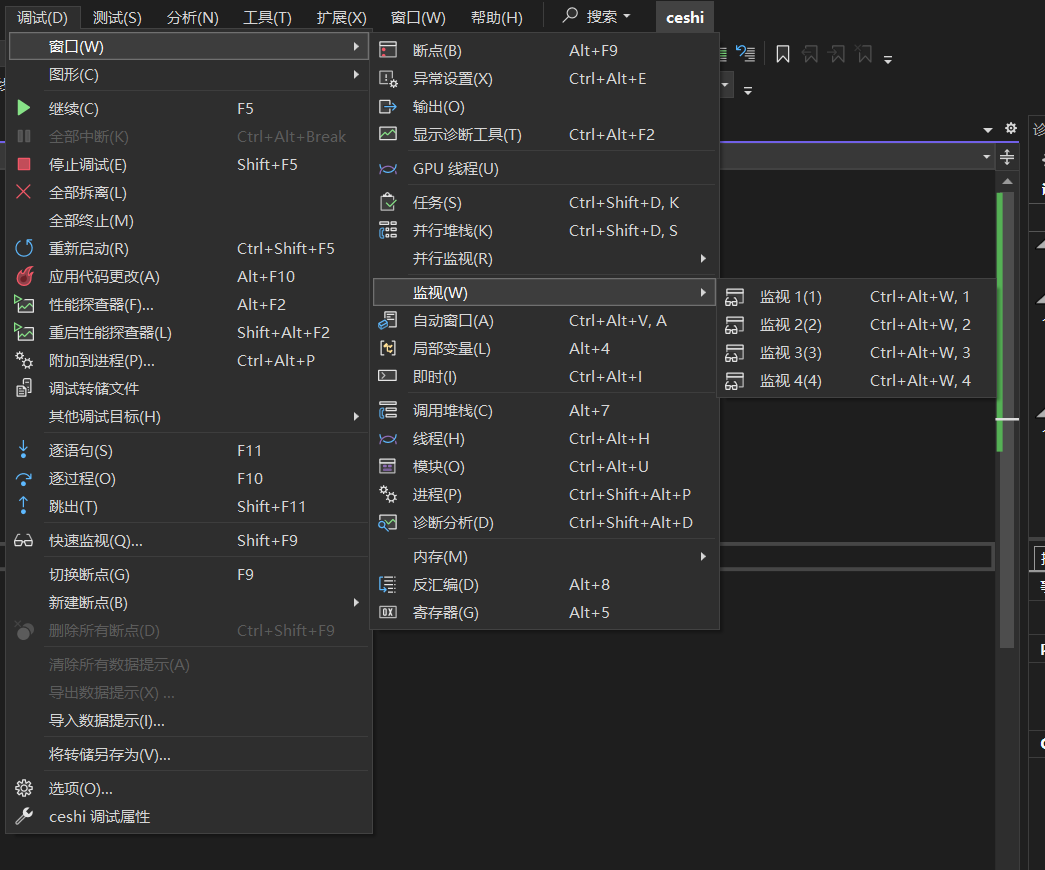
开始调试后!!!,在菜单栏中【调试】->【窗⼝】->【监视】,打开任意⼀个监视窗口,输⼊想要观察的对象
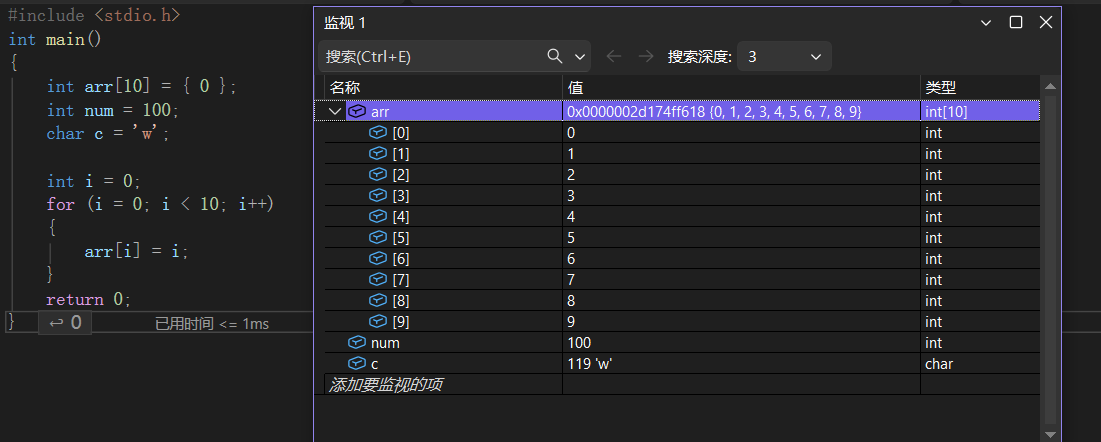
内存
如果监视窗⼝看的不够仔细,也是可以观察变量在内存中的存储情况,还是在【调试】->【窗⼝】-> 【内存】

调试举例1
求1!+2!+3!+4!....+10!的和
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d", &n);
int i = 1;
int ret = 1;
for (i = 1; i <= n; i++)
{
ret *= i;
}
printf("%d\n", ret);
return 0;
}可以自己调试一下错误(下面是正确代码)
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d", &n);
int i = 1;
int ret = 1;
int sum = 0;
for (i = 1; i <= n; i++)
{
ret *= i;
sum += ret;
}
printf("%d\n", sum);
return 0;
}调试举例2
在VS2022、X86、Debug的环境下,编译器不做任何优化的话,下⾯代码执行的结果是什么
#include <stdio.h>
int main()
{
int i = 0;
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
for(i=0; i<=12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0程序运行,死循环了,调试看看为什么?
调试可以上⾯程序的内存布局如下
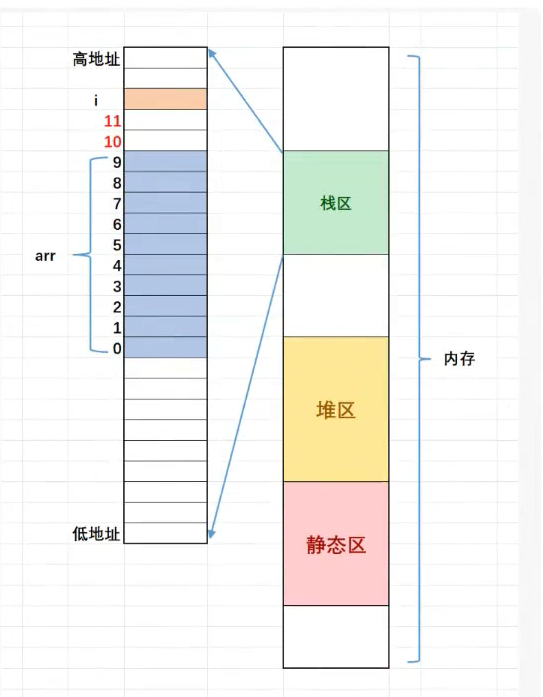
栈区内存的使⽤习惯是从⾼地址向 低地址使用的,所以变量i的地址是较⼤的。arr数组的地址整体是小于i的地址。
- 数组在内存中的存放是:随着下标的增长,地址是由低到高变化的。 所以根据代码,就能理解为什么是左边的代码布局了。 如果是左边的内存布局,那随着数组下标的增长,往后越界就有可能覆盖到i,这样就可能造成死循环的。 这⾥肯定有人有疑问:为什么i和arr 数组之间恰好空出来2个整型的空间 呢?这里面确实是巧合,在不同的编译 器下可能中间的空出的空间大小是不 ⼀样的,代码中这些变量内存的分配 和地址分配是编译器指定的,所以的不同的编译器之间就有差异了。所以 这个题目是和环境相关的(换成Release)
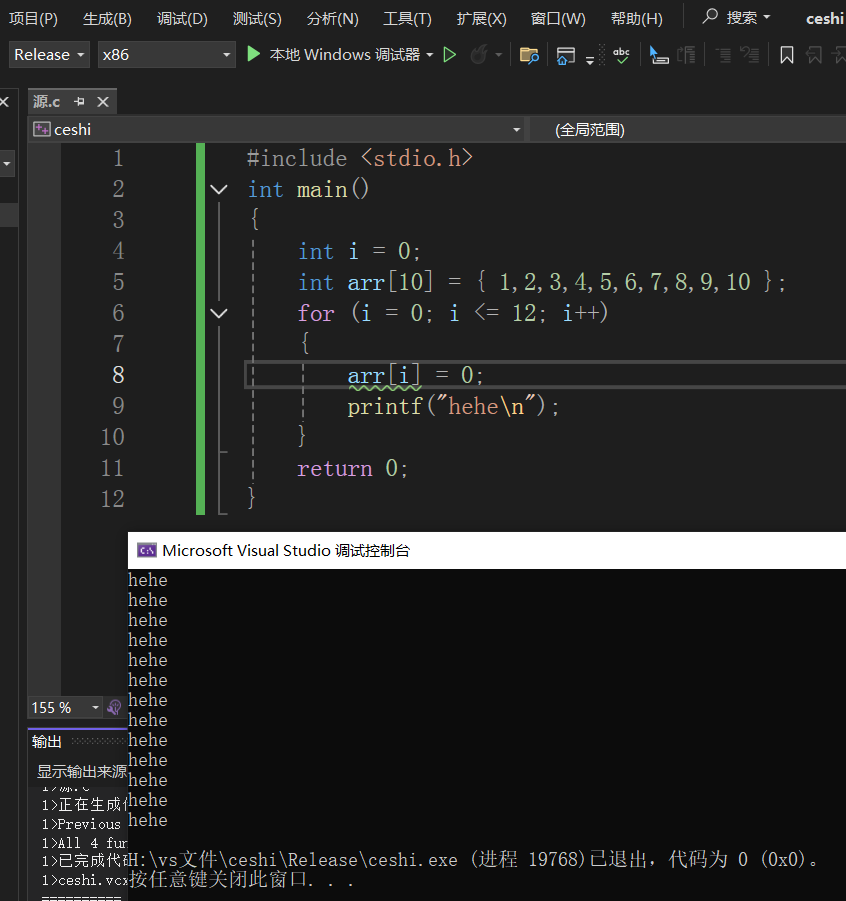
注意:栈区的默认的使⽤习惯是先使用高地址,再使用低地址的空间,但是这个具体还是要编译器的实现