在 Retrieval-Augmented Generation (RAG) 架构中,大语言模型(LLM)的生成能力决定了回答的"下限",而检索系统的质量则决定了回答的"上限"。作为 RAG 的核心引擎,向量数据库及其底层的向量索引算法,直接决定了检索的召回率、准确率和响应延迟。
本文将从底层数学原理出发,深度剖析主流向量索引算法,全面拆解向量数据库的系统架构,并结合 RAG 实际场景提供选型与优化指南。

第一部分:向量检索的基石与核心概念
1.1 什么是向量与 Embedding?
在 RAG 中,非结构化数据(文本、图像、音频)必须通过 Embedding 模型(如 BGE, text-embedding-ada-002, Jina 等)映射到高维连续向量空间中。
- 语义空间映射:Embedding 的本质是将语义信息压缩为一个 d 维的浮点数数组(如 768 维或 1024 维)。语义相近的文本,在向量空间中的距离更近。
- 维度灾难 (Curse of Dimensionality):当维度 d 很高时,空间变得极其稀疏,传统的基于空间划分的数据结构(如 KD-Tree)会失效,这就是为什么我们需要专门的向量索引算法。
1.2 相似度度量方法 (Distance Metrics)
向量检索的核心是计算 Query 向量与数据库中 Document 向量的距离。常用的度量方式有三种:
- 余弦相似度 (Cosine Similarity) :
- 公式: Cosine(A, B) = \\frac{A \\cdot B}{\|\|A\|\| \\times \|\|B\|\|}
- 物理意义:衡量两个向量在方向上的夹角,忽略向量的绝对长度(模长)。
- 适用场景:文本检索中最常用,因为文本 Embedding 的模长往往受文本长度影响,而我们更关注语义方向。
- 欧氏距离 (Euclidean Distance / L2) :
- 公式: L2(A, B) = \\sqrt{\\sum_{i=1}\^{d} (A_i - B_i)\^2}
- 物理意义:空间中两点的绝对直线距离。
- 适用场景:图像检索或对向量模长敏感的场景。
- 内积 (Inner Product / IP) :
- 公式: IP(A, B) = \\sum_{i=1}\^{d} A_i \\times B_i
- 物理意义:如果向量已经过 L2 归一化,内积等价于余弦相似度。内积同时考虑了方向和模长。
- 适用场景:推荐系统、多模态检索(如 CLIP 模型输出通常使用内积)。
1.3 精确检索 (KNN) vs 近似最近邻检索 (ANN)
- KNN (K-Nearest Neighbors):暴力穷举,计算 Query 与库中所有向量的距离。召回率 100%,但时间复杂度为 O(N \\times d) 。当数据量达到百万、千万级时,延迟无法忍受。
- ANN (Approximate Nearest Neighbors) :通过牺牲少量的召回率(如 95%~99%),换取几个数量级的查询速度提升。时间复杂度可降至 O(\\log N) 甚至 O(1) 。现代向量数据库的核心就是各种 ANN 算法的工程实现。
第二部分:核心向量索引算法深度剖析
ANN 算法百花齐放,按其核心数据结构可分为四大流派:基于树、基于哈希、基于量化、基于图。
2.1 基于树的索引 (Tree-based)
传统空间划分树(如 KD-Tree)在高维失效后,研究者提出了随机投影树。
核心代表:Annoy (Approximate Nearest Neighbors Oh Yeah)
由 Spotify 开源,主要用于推荐系统。
- 核心思想:通过随机超平面将空间不断二分,构建多棵二叉树。
- 构建过程 :
- 随机选择两个点,计算它们的垂直平分超平面。
- 用该超平面将空间一分为二,左子树和右子树。
- 递归此过程,直到叶子节点包含的点数小于设定阈值(如 K )。
- 重复上述过程,构建 T 棵独立的树(森林)。
- 查询过程:对于 Query 向量,从每棵树的根节点开始,根据超平面方程判断走向左子树还是右子树,直到叶子节点。收集所有叶子节点中的候选集,进行精确距离计算并排序。
- 优缺点 :
- 优点:构建速度快,支持内存映射(MMap),多个进程可共享同一份内存数据,非常适合只读场景。
- 缺点:不支持动态插入(增删数据需要重建整棵树),高维下召回率不如图算法。
2.2 基于哈希的索引 (Hash-based)
利用哈希函数的特性,将相似的向量映射到同一个"桶 (Bucket)"中。
核心代表:LSH (Locality-Sensitive Hashing) 局部敏感哈希
- 核心思想 :设计一种特殊的哈希函数,使得相似的向量哈希碰撞的概率大,不相似的向量哈希碰撞的概率小。这与传统哈希(要求均匀分布、避免碰撞)截然相反。
- 数学定义:对于哈希函数 h ,若 d(x,y) \\le R_1 ,则 P(h(x)=h(y)) \\ge P_1 ;若 d(x,y) \\ge R_2 ,则 P(h(x)=h(y)) \\le P_2 。(其中 P_1 \> P_2 )。
- 构建与查询 :
- 使用多个 LSH 函数组成一个哈希表,构建多个哈希表(Multi-probe LSH)。
- 查询时,计算 Query 的哈希值,找到对应的桶,将桶内的点作为候选集。
- 优缺点 :
- 优点:理论保证强,查询速度极快,适合超大规模数据的初步过滤。
- 缺点 :为了达到高召回率,需要构建大量的哈希表,导致内存占用极其庞大;且对高维向量的效果衰减严重。目前在主流向量库中已较少作为主力索引。
2.3 基于量化的索引 (Quantization-based)
量化是目前工业界解决"内存瓶颈"最核心的技术。 它的本质是通过数据压缩,用极小的内存代价换取可接受的精度损失。
2.3.1 IVF (Inverted File Index) 倒排索引
严格来说 IVF 是聚类,通常与量化结合使用。
- 原理:使用 K-Means 算法将向量空间划分为 n_list 个簇(Voronoi 图)。每个簇有一个中心点(Centroid)。
- 查询:计算 Query 与所有中心点的距离,找到最近的 n_probe 个中心点,然后只在这 n_probe 个簇内进行搜索。
- 参数 :
nprobe决定了搜索的簇数量,越大召回率越高,速度越慢。
2.3.2 PQ (Product Quantization) 乘积量化
由 INRIA 提出,是向量压缩的里程碑。
- 核心思想:将高维向量"切块",在每个子空间内分别进行聚类量化。
- 详细步骤 :
- 切分:将 d 维向量等分为 m 个子向量,每个子向量维度为 d/m 。
- 子空间聚类 :对每个子空间独立运行 K-Means,得到 k 个聚类中心(通常 k=256 ,这样每个中心只需 1 字节 / 8 bit 表示)。这 k 个中心构成该子空间的码本 (Codebook)。
- 编码:原始向量被替换为 m 个聚类中心的索引(ID)。
- 内存节省计算 :假设原向量 128 维 float32(512 字节)。若 m=16, k=256 ,压缩后只需 16 个 8-bit 整数(16 字节)。内存压缩比高达 32 倍!
- 距离计算 (ADC - Asymmetric Distance Computation) :
- 查询时,如果将 Query 也量化,误差会叠加(SDC)。
- ADC 策略:Query 保持 float32 不压缩。预先计算 Query 的子向量到所有码本中心的距离,构建距离查找表 (Distance Lookup Table)。
- 计算库中向量距离时,只需查表并累加 m 个值,将复杂的浮点乘加运算转化为内存查表和整数加法,极大提升 CPU 缓存命中率。
2.3.3 SQ (Scalar Quantization) 标量量化
- 原理:不切分子空间,而是将每个维度的 float32 映射为 int8(或 int4)。通常使用 Min-Max 归一化或 FP16/BF16 转换。
- 对比 PQ:SQ 实现简单,计算快,但压缩率不如 PQ(通常只能压缩 4 倍到 8 倍),且在数据分布不均时精度损失较大。
工业界黄金组合:IVF-PQ / IVF-SQ8
先用 IVF 进行粗排(缩小搜索范围),再用 PQ/SQ 进行精排(降低内存和计算量)。这是十亿级向量检索的标配。
2.4 基于图的索引 (Graph-based)
图算法是目前综合性能(召回率+速度)最强的流派,是中大型向量数据库的默认首选。
核心代表:HNSW (Hierarchical Navigable Small World)
HNSW 结合了跳表 (Skip List) 的分层思想和小世界网络 (Small World) 的短程/长程连接特性。
- 小世界网络 (NSW) :
- 节点之间既有局部连接(聚类特性),又有少量的长程连接(捷径)。
- 查询时,通过长程连接快速跨越空间,通过局部连接精确逼近目标。
- 分层结构 (Hierarchical) :
- 为了解决 NSW 在大规模数据下"入口点"选择不佳和路由跳数过多的问题,HNSW 引入了分层。
- 底层(第 0 层)包含所有节点,连接最密集。
- 越往上层,节点越稀疏,连接越长。顶层只有极少数节点。
- 节点被分配到第 l 层的概率服从指数衰减分布: P(l) = \\frac{1}{\\ln(M)} \\cdot e\^{-l/\\ln(M)} 。
- 构建过程 :
- 为新节点随机分配一个最高层级 L 。
- 从顶层开始,贪心搜索找到距离新节点最近的节点,作为下一层的入口。
- 到达第 L 层后,开始在该层及以下的每一层寻找 M 个最近邻,并建立双向连接。
- 如果某节点的连接数超过 M_{max} ,则根据启发式规则(如保留角度差异大的邻居,避免连接聚集)裁剪连接。
- 查询过程 :
- 从顶层的入口点开始,贪心搜索当前层距离 Query 最近的节点。
- 将该节点作为下一层的入口点,重复上述过程,直到第 0 层。
- 在第 0 层进行局部搜索,返回 Top-K。
- 核心参数调优 :
M:每个节点的最大连接数。 M 越大,召回率越高,但内存占用越大,构建越慢。通常设为 16~64。efConstruction:构建索引时的候选集大小。越大构建越慢,但图的质量越好。通常设为 100~500。ef:查询时的候选集大小。动态控制召回率和延迟的权衡。ef必须 \\ge K 。
- 优缺点 :
- 优点:查询速度极快,召回率极高(轻松达到 99% 以上),支持动态插入。
- 缺点 :内存占用巨大(因为要存储图的边),构建时间长。不支持高效的删除操作(通常采用"软删除"标记)。
进阶图算法:DiskANN / Vamana
为了解决 HNSW 内存爆炸的问题,微软提出了 DiskANN。
- 核心思想 :将图索引存储在 NVMe SSD 上,利用 SSD 的高并发随机读取能力。通过 Vamana 图构建算法优化磁盘 I/O,结合内存中的 PQ 压缩向量进行路由,实现在有限内存下检索十亿级向量。
2.5 算法横向对比与选型指南
| 算法类别 | 代表算法 | 查询速度 | 召回率 | 内存占用 | 构建速度 | 动态更新 | 适用场景 |
|---|---|---|---|---|---|---|---|
| 树 | Annoy | 中 | 中 | 低 | 快 | 不支持 | 只读、内存受限、推荐系统 |
| 哈希 | LSH | 极快 | 低-中 | 极高 | 快 | 支持 | 超大规模初筛、对精度要求不高 |
| 量化 | IVF-PQ | 快 | 中-高 | 极低 | 中 | 支持 | 十亿级以上、内存极其受限 |
| 图 | HNSW | 极快 | 极高 | 高 | 慢 | 支持 | 千万到亿级、追求极致性能 |
第三部分:向量数据库架构与核心技术
理解了索引算法,我们来看向量数据库。FAISS 只是一个"向量索引库",而 Milvus、Pinecone 等才是真正的"向量数据库"。向量数据库 = 向量索引 + 分布式存储 + 事务管理 + 标量过滤 + 生态集成。
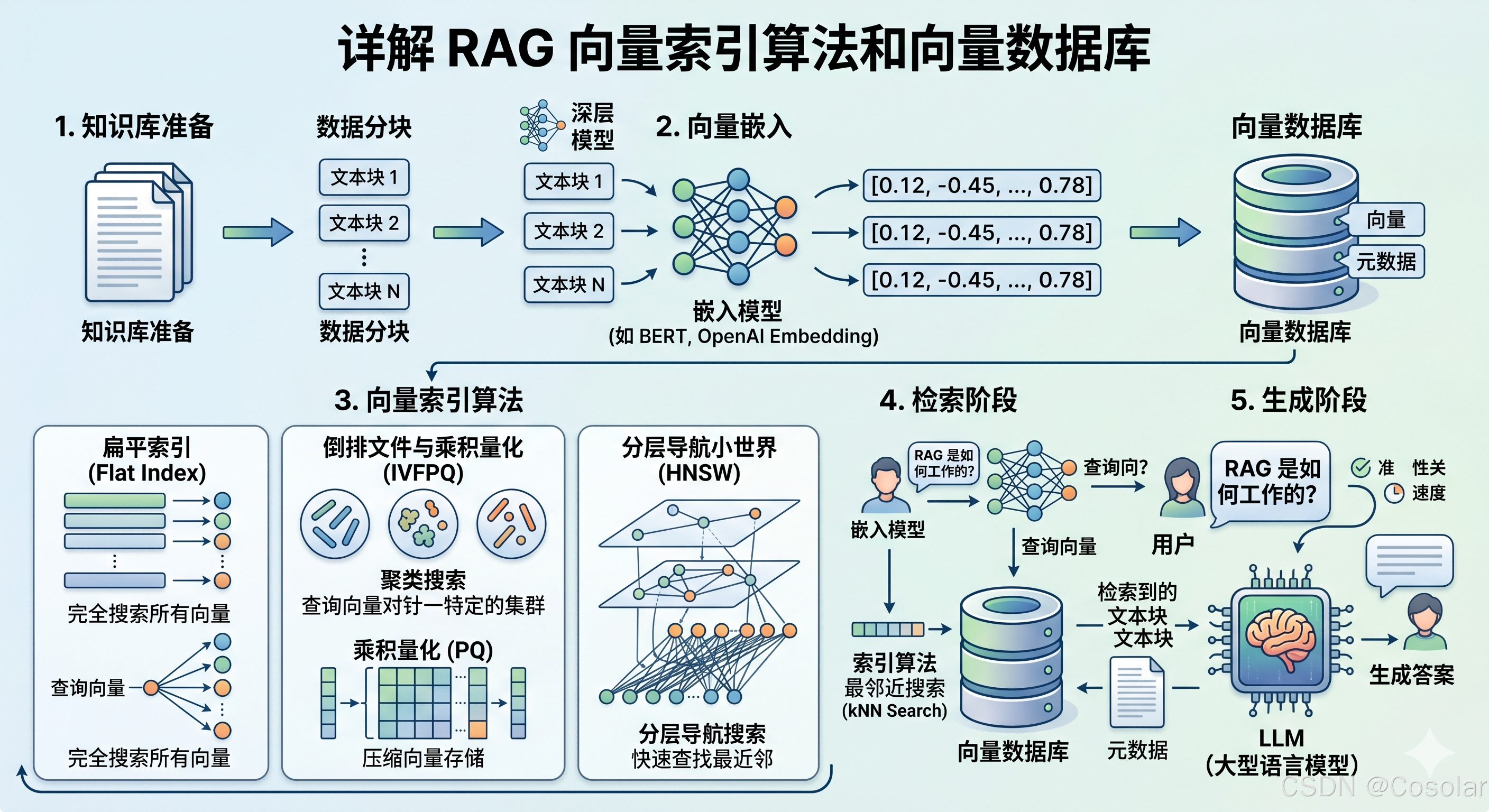
3.1 向量数据库的核心组件架构
一个成熟的向量数据库通常包含以下核心层:
- 接入层 (Access Layer) :
- 处理客户端请求,进行鉴权、限流、路由。
- 提供多语言 SDK (Python, Java, Go, Node.js) 和 RESTful/gRPC API。
- 协调层 (Coordinator Layer) :
- 元数据管理:存储 Collection 结构、索引配置、分片信息(通常依赖 etcd/ZooKeeper)。
- 查询协调:将用户的查询请求拆分、下发到多个数据节点,并聚合结果。
- 计算/索引层 (Worker/Index Node) :
- 负责构建向量索引(CPU/GPU 密集型任务)。
- 执行向量检索和标量过滤。
- 利用 SIMD (AVX2/AVX-512) 指令集或 GPU CUDA 核心加速距离计算。
- 存储层 (Storage Layer) :
- WAL (Write-Ahead Logging):保证数据的持久化和崩溃恢复。
- 对象存储/分布式文件系统:如 S3, HDFS, MinIO,用于持久化存储庞大的向量数据文件和索引文件(存算分离架构的核心)。
- 内存缓存:将热点数据或图索引加载到内存中。
3.2 分布式架构:存算分离与数据分片
面对十亿、百亿级数据,单机内存无法容纳,必须采用分布式架构。
- 存算分离 (Disaggregated Storage and Compute) :
- 计算节点(无状态)和存储节点(有状态)独立扩缩容。
- 向量数据持久化在廉价的对象存储(如 S3)中,计算节点按需拉取数据到内存构建索引。这极大降低了存储成本,并支持秒级弹性扩缩容。
- 数据分片 (Sharding/Partitioning) :
- Hash 分片:根据主键 Hash 将数据打散到不同节点。
- Range 分片:按时间或 ID 范围分片。
- Partition Key :在 RAG 中,通常按
tenant_id或document_id进行物理分区,查询时直接路由到特定分区,避免全局扫描。
3.3 RAG 核心痛点:混合检索与标量过滤 (Metadata Filtering)
在 RAG 中,纯向量检索往往不够。例如:"查找 2023 年发布的关于 Transformer 架构的论文"。这里"2023年"是硬过滤条件,"Transformer"是语义条件。
标量过滤 (Metadata Filtering) 的实现机制是向量库设计的难点:
- 后置过滤 (Post-filtering) :
- 先进行向量 ANN 检索,取出 Top-K 结果,然后再用标量条件过滤。
- 致命缺点:如果过滤条件很严格,Top-K 中可能没有符合条件的数据,导致召回率断崖式下跌。
- 前置过滤 (Pre-filtering) :
- 先用标量条件(如倒排索引、Roaring Bitmap)过滤出符合条件的文档 ID 集合。
- 然后在这个子集中进行向量检索。
- 缺点:如果过滤后的子集依然很大,向量检索退化为暴力扫描;如果子集很小,图索引(HNSW)的连通性被破坏,导致搜索失败。
- 内联过滤 (In-line Filtering / 混合索引) :
- 当前最优解。在 HNSW 遍历图节点时,实时检查节点的标量属性。如果不符合条件,则跳过该节点,继续沿着边寻找。
- 或者采用 IVF + 倒排索引 结合的方式,在 IVF 的每个簇内维护一个倒排索引,实现高效的双向过滤。
3.4 混合检索 (Hybrid Search):向量 + 全文检索
向量检索擅长语义泛化(如"苹果"匹配"水果"),但对精确关键词(如产品型号"iPhone 15 Pro Max"、专有名词、人名)的匹配能力极差。
- BM25 (全文检索):基于词频和逆文档频率,擅长精确词元匹配。
- 融合策略 :
- 分别执行向量检索和 BM25 检索。
- 使用 RRF (Reciprocal Rank Fusion) 算法融合排序:
Score(d) = \\sum_{i} \\frac{1}{k + rank_i(d)} ( k 通常取 60)。 - RRF 不需要对两种分数进行复杂的归一化,鲁棒性极强,是目前 RAG 提升召回率的标配。
第四部分:主流向量数据库全景剖析与选型
市场上的向量数据库主要分为两大阵营:专用向量数据库 (Native) 和 传统数据库的向量扩展 (Extension)。
4.1 专用向量数据库 (Native Vector DBs)
专为向量计算设计,性能上限高,功能丰富。
- Milvus / Zilliz
- 特点:老牌开源王者,云原生架构,存算分离。支持极其丰富的索引类型(HNSW, DiskANN, IVF 等)和距离度量。生态最完善。
- 适用场景:大型企业、数据量亿级以上、需要深度定制和私有化部署、对高可用和分布式要求极高的场景。
- 缺点:架构较重,组件多(依赖 etcd, MinIO, Pulsar/Kafka),运维门槛较高。
- Pinecone
- 特点:全托管 SaaS 闭源服务。开箱即用,免运维,Serverless 架构。
- 适用场景:海外出海业务、缺乏底层运维团队的初创公司、追求极速上线的 SaaS 产品。
- 缺点:闭源、数据合规性考量、大规模使用成本较高、不支持私有化。
- Qdrant
- 特点 :Rust 编写,内存安全,性能优异。其最大的亮点是极其强大的标量过滤性能(Payload 索引优化得非常好)。
- 适用场景:对混合检索(过滤+向量)要求极高的 RAG 场景、喜欢 Rust 生态的团队。
- Weaviate
- 特点:内置模块化设计,可以直接在数据库内部调用 Embedding 模型(向量化模块)。提供 GraphQL API。
- 适用场景:希望简化 RAG 管道、不想在应用层处理 Embedding 逻辑的开发者。
- Chroma / FAISS (轻量级/本地库)
- 特点:Chroma 是 Python 优先的轻量级库,FAISS 是 Meta 开源的底层 C++ 算法库。
- 适用场景 :本地开发、PoC 验证、单机小规模数据(百万级以下)。不建议直接用于生产环境的分布式集群。
4.2 传统数据库的向量扩展 (Vector Extensions)
在现有关系型/文档型数据库上增加向量能力。
- PostgreSQL + pgvector
- 特点 :PG 生态的延伸。支持 ACID 事务,向量数据与业务关系数据在同一张表中,Join 操作极其方便。
- 适用场景:中小规模数据(千万级以下)、已有 PG 技术栈、对数据强一致性要求高、不想引入新组件的团队。
- 缺点:受限于 PG 的单机架构和 MVCC 机制,在超大规模数据和高并发写入下的向量检索性能不如 Milvus 等专用库。
- Elasticsearch / OpenSearch (k-NN 插件)
- 特点:天生具备强大的 BM25 全文检索和分布式能力。8.x 版本后原生支持 HNSW。
- 适用场景:已经重度使用 ES 作为搜索引擎的企业,需要无缝集成向量检索实现混合搜索。
- Redis / MongoDB 向量搜索
- 特点:利用 Redis 的内存极速特性或 MongoDB 的文档灵活性。
- 适用场景:作为向量缓存层,或对实时性要求极高的特定场景。
4.3 选型决策树
- 数据量 < 100万,本地开发/Demo \\rightarrow Chroma / FAISS
- 数据量 < 1000万,已有 PG 栈,重事务和 Join \\rightarrow PostgreSQL + pgvector
- 数据量 < 5000万,已有 ES 栈,重全文+向量混合 \\rightarrow Elasticsearch 8.x
- 数据量 > 5000万,需要极致的过滤+向量性能 \\rightarrow Qdrant
- 数据量 亿级以上,分布式、高可用、私有化部署 \\rightarrow Milvus
- 不想运维,预算充足,出海业务 \\rightarrow Pinecone
第五部分:RAG 场景下的向量检索优化实战
在 RAG 实际落地中,仅仅把文本扔进向量库是远远不够的。以下是提升 RAG 检索质量的"高级战术"。
5.1 提升召回率 (Recall) 的策略
召回率解决的是"找没找到"的问题。
- Chunking (分块) 策略优化 :
- 痛点:固定长度切分容易破坏语义完整性。
- Parent-Child (父子块) 检索:将文档切分为大块(Parent,如 1000 token,用于送 LLM 生成)和小块(Child,如 200 token,用于 Embedding 和检索)。检索时匹配 Child,但返回对应的 Parent。这兼顾了检索的精准度和生成的上下文完整性。
- Sliding Window (滑动窗口):块与块之间保留 10%-20% 的重叠 (Overlap),防止关键信息被切断。
- Query 改写与扩展 (Query Transformation) :
- 痛点:用户的提问往往很短、模糊,或者包含错别字,直接 Embedding 效果差。
- Multi-Query (多路查询):用 LLM 将用户问题改写为 3-5 个不同角度的子问题,分别检索后合并去重。
- HyDE (Hypothetical Document Embeddings) :先让 LLM 根据问题"幻觉"生成一段假设性的答案,然后用这段答案的 Embedding 去检索真实文档。因为"答案"和"文档"在语义空间上比"问题"和"文档"更接近。
- Embedding 模型微调 (Fine-tuning) :
- 通用模型在特定垂直领域(如医疗、法律、内部代码库)表现不佳。使用领域内的 QA 对,通过 Contrastive Learning(对比学习)微调 Embedding 模型,可显著提升领域内召回率。
5.2 提升准确率 (Precision) 的策略
准确率解决的是"找得准不准"的问题。RAG 最怕"检索出无关内容,导致 LLM 产生幻觉"。
- 引入 Reranker (重排序模型) :
- 两阶段检索架构 :
- 第一阶段 (Retrieval):使用向量数据库(Bi-Encoder 双塔模型)快速粗排,召回 Top-50。速度极快,但精度一般。
- 第二阶段 (Reranking):使用 Cross-Encoder(交叉编码器,如 BGE-Reranker, Cohere Rerank)对 Top-50 进行精排,输出 Top-5。
- 原理:Cross-Encoder 将 Query 和 Document 拼接在一起输入 Transformer,进行深度的注意力交互,打分极其精准,但计算成本高,只能用于小候选集。
- 两阶段检索架构 :
- 动态元数据过滤 :
- 在 RAG 管道中,使用 LLM 或 NER(命名实体识别)从 Query 中提取时间、作者、类别等实体,转化为向量库的 Metadata Filter,大幅缩小搜索空间,排除干扰信息。
- 上下文压缩 (Context Compression) :
- 检索出文档后,使用 LLM 或专门的压缩模型(如 LLMLingua),剔除文档中与 Query 无关的冗余句子,只保留核心信息送给生成模型,减少 Token 消耗并降低幻觉。
5.3 评估体系:如何衡量 RAG 检索效果?
不要凭感觉优化,必须建立量化评估体系(如使用 Ragas, TruLens, ARES 框架):
- Context Recall (上下文召回率):检索出的内容是否包含了回答问题的所有必要信息?(需要 Ground Truth 答案作为参考)。
- Context Precision (上下文精确率):检索出的内容中,与问题相关的信息是否排在前面?无关信息是否被过滤?
- Faithfulness (忠实度):LLM 生成的答案是否完全基于检索出的上下文?(衡量幻觉)。
结语
向量数据库和索引算法是 RAG 系统的"心脏"。从早期的 FAISS 单机索引,到如今 Milvus、Pinecone 的分布式云原生架构;从单一的 HNSW 图搜索,到 IVF-PQ 的极致压缩,再到混合检索与 Rerank 的深度融合,技术演进始终围绕着 "更大规模、更低延迟、更高精度、更低成本" 展开。
未来趋势展望:
- 多模态向量库:随着 GPT-4o 等多模态大模型的爆发,向量库将原生支持图、文、音、视频的统一 Embedding 存储与跨模态检索。
- GraphRAG (图增强 RAG):传统的向量检索缺乏对全局结构和实体关系的理解。将知识图谱 (Knowledge Graph) 与向量检索结合,利用图数据库(如 Neo4j)进行多跳推理,将是解决复杂逻辑问答的下一代范式。
- 硬件级加速:随着 CXL (Compute Express Link) 内存扩展技术和专用 AI 推理芯片(如 Groq, 各种 NPU)的成熟,向量检索的瓶颈将从 CPU/内存 转移到专用的硬件加速流水线,实现真正的微秒级十亿检索。
- 端到端可学习检索:检索器和生成器不再割裂,通过强化学习(RL)或联合微调,让 LLM 直接指导向量索引的更新和检索策略,实现真正的"检索即生成"。
掌握向量索引的底层逻辑与数据库架构,不仅是构建高质量 RAG 系统的必经之路,更是通往下一代 AI 数据基础设施的核心钥匙。希望本文能为您在 AI 时代的工程实践中提供坚实的理论与实战支撑。