提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- [1. 项目前置](#1. 项目前置)
-
- [1.1 搜索的核⼼思路:](#1.1 搜索的核⼼思路:)
- [1.2 倒排索引](#1.2 倒排索引)
- [1.3 项⽬目标](#1.3 项⽬目标)
- [1.4 核⼼流程](#1.4 核⼼流程)
- [1.5 创建项目](#1.5 创建项目)
- [1.6 关于分词](#1.6 关于分词)
- [2. 实现索引模块](#2. 实现索引模块)
- [3. 实现Parser类](#3. 实现Parser类)
-
- [3.1 排除非html文件](#3.1 排除非html文件)
- [3.2 解析html文件](#3.2 解析html文件)
- [3.3 解析标题](#3.3 解析标题)
- [3.4 解析URL](#3.4 解析URL)
- [3.5 解析正文](#3.5 解析正文)
- 总结
前言
1. 项目前置
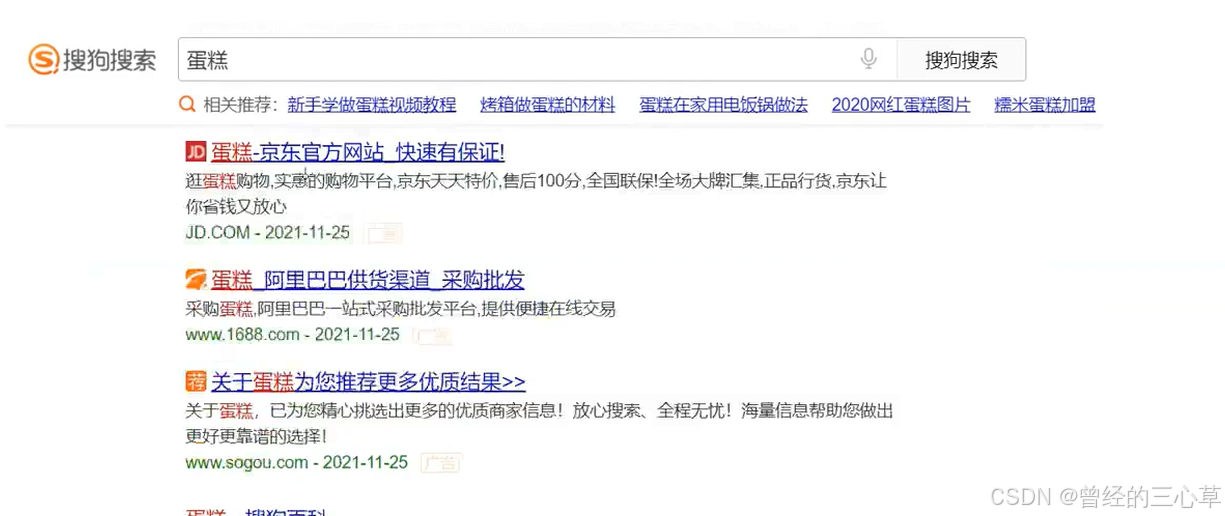
这个就是搜索引擎
搜索引擎的本质
输⼊⼀个查询词, 得到若⼲个搜索结果. 每个搜索结果包含了标题, 描述, 展⽰ url 和点击 url.
1.1 搜索的核⼼思路:
先获取很多网页,在根据用户输入,在网页中查找
页面怎么来?-----》爬虫
怎么去在网页中匹配查询词呢
⽅案⼀ -- 暴⼒搜索
每次处理搜索请求的时候, 拿着查询词去所有的⽹⻚中搜索⼀遍, 检查每个⽹⻚是否包含查询词字符串.
这个⽅法是否可⾏?
显然, 这个⽅案的开销⾮常⼤. 并且随着⽂档数量的增多, 这样的开销会线性增⻓. ⽽搜索引擎往往对于
效率的要求⾮常⾼
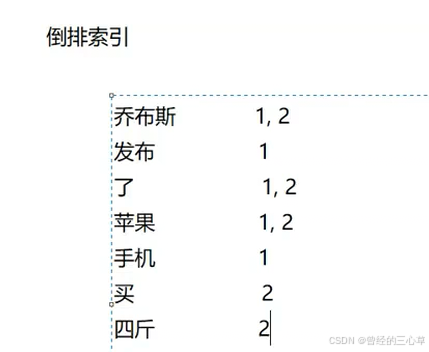
1.2 倒排索引
⽅案⼆ -- 倒排索引
这是⼀种专⻔针对搜索引擎场景⽽设计的数据结构.
⽂档(doc): 被检索的html⻚⾯(经过预处理),每个待搜索的网页
正排索引: "⼀个⽂档包含了哪些词". 描述⼀个⽂档的基本信息, 包括⽂档标题, ⽂档正⽂, ⽂档标题和正⽂的分词,指的是文档id====》文档内容
倒排索引: "⼀个词被哪些⽂档引⽤了". 描述了⼀个词的基本信息, 包括这个词都被哪些⽂档引⽤, 这个词在该⽂档中的重要程度, 以及这个词的出现位置等.指的是词====》文档id

1.3 项⽬目标
实现⼀个 Java API ⽂档的简单的搜索引擎.
百度,搜狗,bing这种搜索引擎就是全站搜索,就是搜索整个互联网上所有的网站
站内搜索:只针对某个网站内部的内容进行搜索,我们实现这个
Java API ⽂档线上版本参⻅ https://docs.oracle.com/javase/8/docs/api/index.html
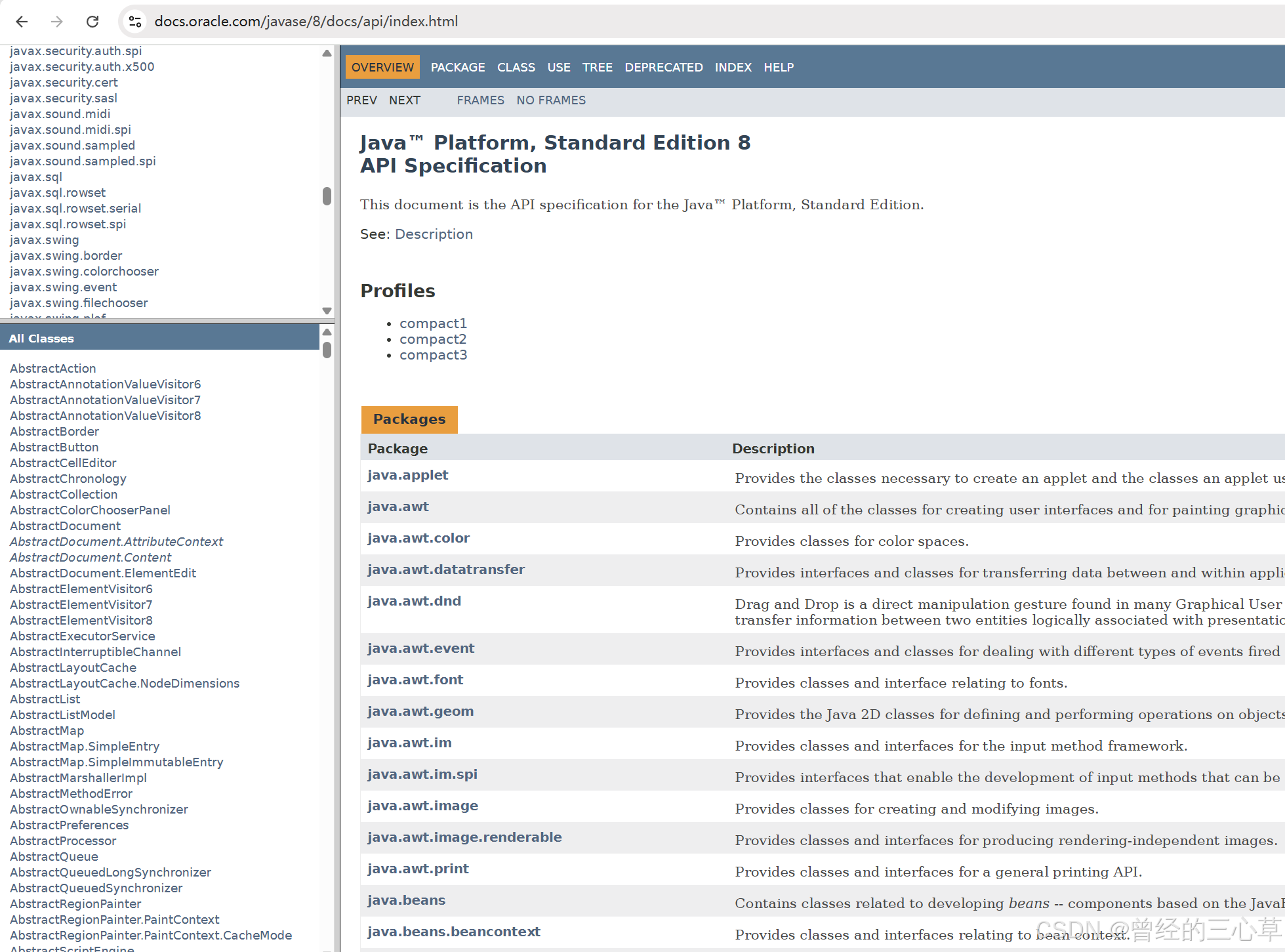
但是这个页面并没有搜索款---》不好寻找,我们就针对这个来实现搜索
先把相关的网页文档或网页获取到----》可以通过爬虫来获取,爬虫就是一个http客户端(和浏览器类似),这个爬虫就是自动化,批量化获取很多页面,下载到到本地,然后进行搜索,浏览器是我们手动获取页面
只要这个语言可以访问网络,就能实现爬虫
爬虫是获取一个网站页面的一种通用手段
针对java文档--》可以直接下载官网的下载文档
每个网站都会提供一个robots.txt这个文件,这个文件就会告诉你哪些内容可以爬虫,爬虫其他地方都是非法的
下载版本参⻅ https://www.oracle.com/technetwork/java/javase/downloads/index.html
点击java8

直接下载就可以了
进入\docs\api\java\util
点击上面的html文件就可以跳转了
这个和在线文档里面的内容是一致的,只不过我们本地打开的这个是离线的,和爬虫获取的是一样的
这个是在线文档的连接
https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html
file:///C:/Users/zjdsx/Desktop/docs/api/java/util/Arrays.html
我们发现后面的路径都是一样的,所以我们可以在本地基于离线文档制作索引,实现搜索,当用户点击搜索结果页点击具体的搜索结果的时候,就可以自动跳转到在线文档的页面
1.4 核⼼流程
- 索引模块: 扫描下载到的⽂档, 分析数据内容构建正排+倒排索引, 并把索引内容保存到⽂件中.
加载制作好的索引,并提供一些api实现正排和查倒排这样的功能 - 搜索模块: 加载索引. 根据输⼊的查询词, 基于正排+倒排索引进⾏检索, 得到检索结果.
输入:用户查询词
输出:很多条记录,每个记录都有标题,描述,展示url,并且能够点击跳转 - web模块: 编写⼀个简单的⻚⾯, 展⽰搜索结果. 点击其中的搜索结果能跳转到对应的 Java API ⽂档⻚⾯.实现一个简单的web程序,包含前端和后端
1.5 创建项目
创建maven项目java_doc_sercher
jdk选择1.8
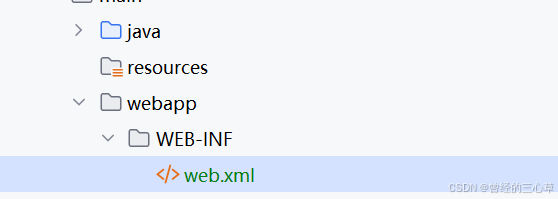
创建这个目录webapp/WEB-INF/和文件web.xml和java同级
web.xml里面内容为
sql
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd" >
<web-app>
<display-name>Archetype Created Web Application</display-name>
</web-app>1.6 关于分词
用户输入的查询词,不一定是一个词,还可以是一句话
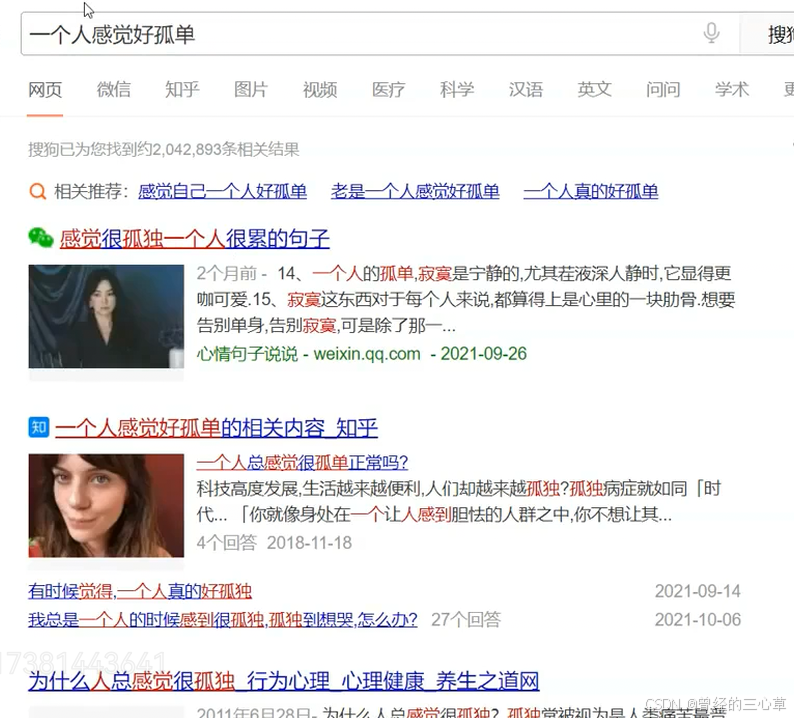
输入一句话的时候,就是把这句话分成多个词来进行搜索
所以要先对查询词来进行分词
分词就是把一个完整的句子切分为多个词:一个,人,感觉,好,孤单
分词原理:
1.基于词库
把所有得到词都进行穷举,把穷举结果放在词典文件中,然后就可以一次取句子里面的内容了,比如每隔一个字在词典里面查一下,看是不是词,或者每隔两个字取词典查一下,看是不是词,但是词是一直在生成的,词典是不够的
2.基于统计
收集很多很多语料库,===》进行人工标注/直接统计/人智能统计--》也就知道了哪些字在一起的概率比较大
两种方法要相互配合在一起使用
怎么用代码来分词呢
分词是搜索中的⼀个核⼼操作. 尤其是中⽂分词, ⽐较复杂
我们可以使⽤现成的分词库 ansj.
官⽹ 站: https://github.com/NLPchina/ansj_seg
使⽤的简单⽰例: https://blog.csdn.net/weixin_44112790/article/details/86756741
java
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
java
String str = "小明毕业于清华大学,然后去蓝翔技校和新东方深造";
ToAnalysis toAnalysis = new ToAnalysis();
List<Term> terms = toAnalysis.parse(str).getTerms();//因为toAnalysis.parse(str)返回的类是第三方的类,所有getTerms
//term就表示一个分词结果
for (Term term : terms) {
System.out.println(term.getName());//获取分词结果里面的词
}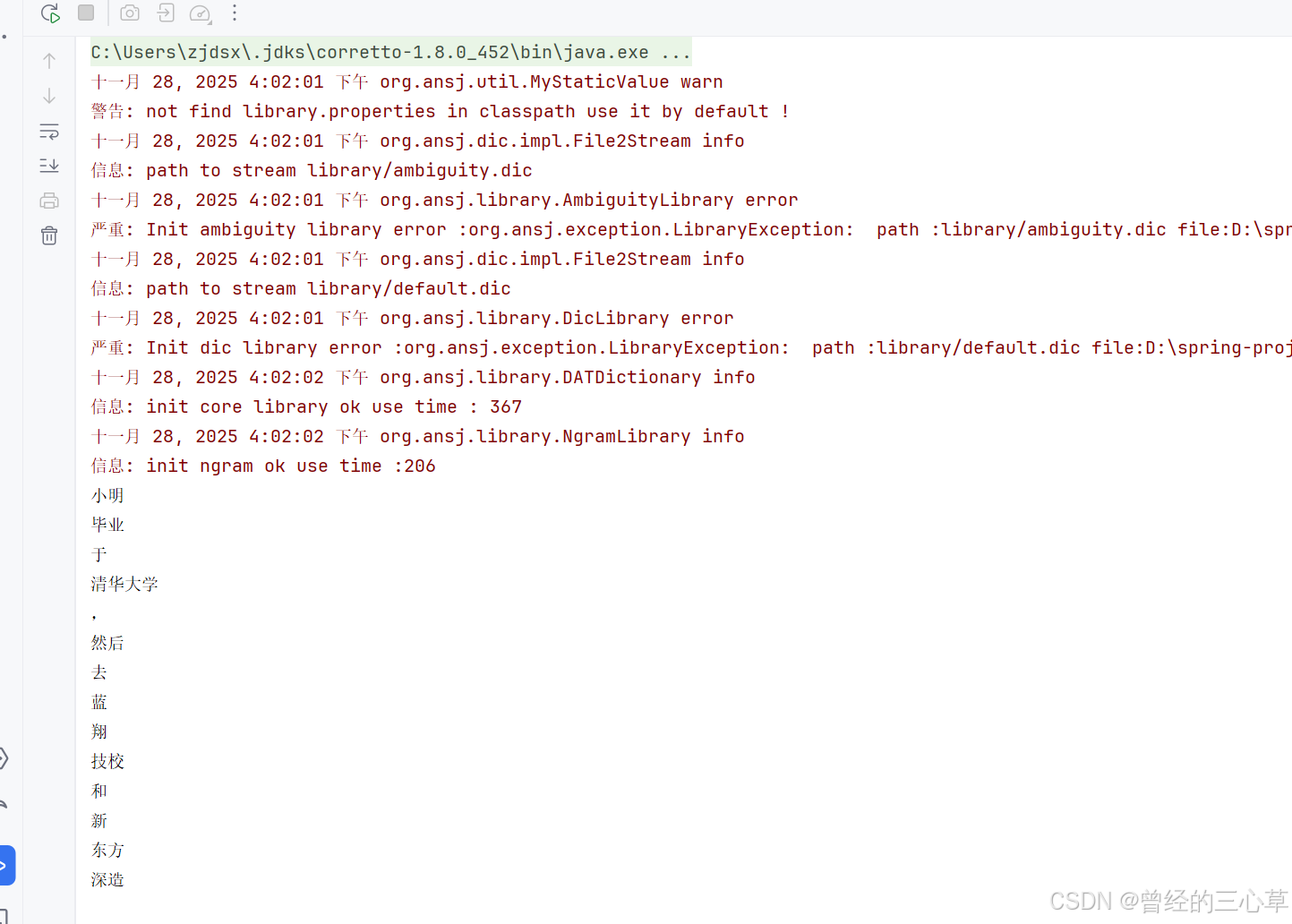
这些警告是因为,我们的ansj在分词的时候要加载一些词典文件----》加快分词速度和效果,但是没有词典也是可以分词的
还可以针对英文来分词
java
String str = "i have a stream";
ToAnalysis toAnalysis = new ToAnalysis();
List<Term> terms = toAnalysis.parse(str).getTerms();//因为toAnalysis.parse(str)返回的类是第三方的类,所有getTerms
//term就表示一个分词结果
for (Term term : terms) {
System.out.println(term.getName());//获取分词结果里面的词
}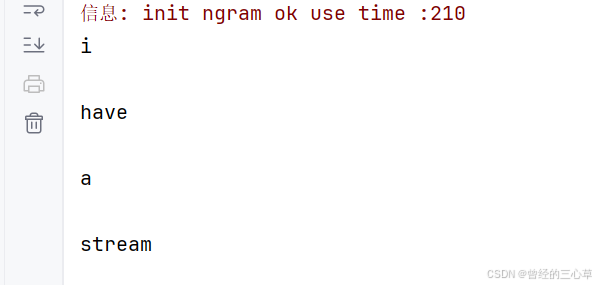
空格也被分出来了,大写的I也会被分为小写i
2. 实现索引模块
3. 实现Parser类
java
public class Parser {
//指定加载文档的路径'
private static final String INPUT_PATH = "C:/Users/zjdsx/Desktop/docs/api";
public void run(){
//入口
//1.根据上面指定路径,枚举出所有的文件(html),包括所有的子目录
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
System.out.println(fileList.size());
//2. 针对上面罗列出的文件路径,打开文件,读取文件内容,解析,构建索引
//3.在内存中构造好的索引数据结果,保存到指定的文件中
}
private void enumFile(String inputPath, ArrayList<File> fileList) {
File rootPath = new File(inputPath);
File[] files = rootPath.listFiles();//listFiles获取到当前目录下的所有文件和文件夹,只有这一级目录的
for (File file : files) {
//根据f的类型,决定是否要递归,如果file是一个普通文件,加入fileList数组,如果是一个目录,就递归调用
if (file.isDirectory()) {
//是一个目录
enumFile(file.getAbsolutePath(), fileList);
}else {
fileList.add(file);
}
}
}
public static void main(String[] args) {
Parser p = new Parser();
p.run();
}
}
发现有些文件还不是html

3.1 排除非html文件
根据后缀名(扩展名)来判断就可以了---》可以打开扩展名
java
private void enumFile(String inputPath, ArrayList<File> fileList) {
File rootPath = new File(inputPath);
File[] files = rootPath.listFiles();//listFiles获取到当前目录下的所有文件和文件夹,只有这一级目录的
for (File file : files) {
//根据f的类型,决定是否要递归,如果file是一个普通文件,加入fileList数组,如果是一个目录,就递归调用
if (file.isDirectory()) {
//是一个目录
enumFile(file.getAbsolutePath(), fileList);
}else {
if (file.getAbsolutePath().endsWith(".html")) {
fileList.add(file);
}
}
}
}
这里可以自动换行,就不是一行展示,看不完了

发现少了不少了
3.2 解析html文件
一条搜索结果又标题,描述,展示url,这些都来自于html----》我们就来提取每个html的标题。描述,url
描述是正文的一段摘要
先搞正文,标题,url
java
private void parseHTML(File file) {
//1.解析出标题
String title = parseTitle(file);
//2.解析出html对应url
String url = parseUrl(file);
//3.解析出html正文
String content = parseContent(file);
}3.3 解析标题

html中的title标签就是标题
其实标题就是文件名,一模一样的
java
private String parseTitle(File file) {
String title = file.getName().substring(0,file.getName().length()-".html".length());//getName得到ArrayList.html,file.getAbsolutePath()是得到所有全路径
//标题不需要html这个后缀,,,ArrayList.html,,,,,,,点的位置就是总长度减去5就是9,substring是左闭右开
return title;
}求长度
针对数组: .length属性
针对字符串: .length()方法
针对LIst等集合: .size()方法
3.4 解析URL
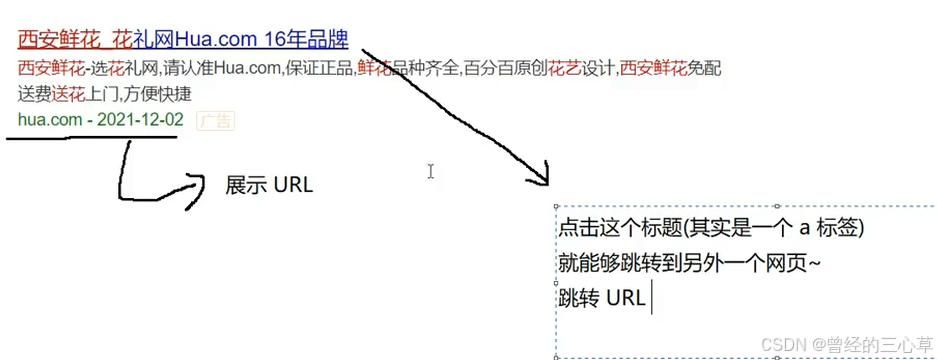
真实的搜索引擎中展示url和跳转url不是同一个(可以右键复制一下看看),我们这里就不区分了

我们就使用一个URL了就可以了
对于搜狗来说,广告结果的可以根据点击计费
自然搜索结果(不带广告):根据点击来优化用户体验,看这个是不是用户需要的
JavaAPI文档存在两份,一个是本地的,一个是线上的文档
我们可以以https://docs.oracle.com/javase/8/docs/api/作为前缀+本地的相对的路径,就可以拼接出URL了
java
private String parseUrl(File file) {
//先获取一个固定的前缀
String part1 = "https://docs.oracle.com/javase/8/docs/api/";
// file.getAbsolutePath().substring(INPUT_PATH.length());//这个就是截取INPUT_PATH.length()下标到最后
String part2 = file.getAbsolutePath().substring(INPUT_PATH.length());
String result = part1 + part2;
System.out.println(result);
return result;
}
但是这样不太好,因为斜杠错乱了
但是浏览器是可以识别https://docs.oracle.com/javase/8/docs/api/\\overview-frame.html的
主流浏览器,是可以容错这种斜杠的,这是容错性,也就是鲁棒性
3.5 解析正文
一个完整的htnl文件===html标签+内容
所以我们去掉html标签就可以了
我们可以通过正则表达式来去标签----》字符串匹配处理的常见手段
看某个字符串是否符合这些特征
去除html标签,可以用正则表达式---》但是比较麻烦
html标签都是非常有特点的----》左右尖括号的形式
一次读取,遇到左尖括号,那么从左尖括号开始,到右尖括号的内容都不放在字符串中,如果遇到的不是左尖括号------》拷贝到结果中,定义一个开关就可以了
html内容中是不会存在左右尖括号的
html内容要求<代替<,使用>代替>
java
private String parseContent(File file) {
//先按照一个字符一个字符来读取,字符流
try(FileReader fileReader = new FileReader(file)) {
//加上一个是否要进行拷贝的开关
boolean isCopy= true;
StringBuilder content = new StringBuilder();
while (true){
int read = fileReader.read();//一次读取一个字符,返回值是一个int
if (read == -1){
break;//表示文件读完了
}
char c = (char) read;
if (isCopy){
if(c=='<'){
isCopy=false;
continue;
}
content.append(c);
}else if (c=='>'){
isCopy=true;
}
}
return content.toString();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
但是这里有很多的换行,很多空换行
所以还要去掉空换行
java
private String parseContent(File file) {
//先按照一个字符一个字符来读取,字符流
try(FileReader fileReader = new FileReader(file)) {
//加上一个是否要进行拷贝的开关
boolean isCopy= true;
StringBuilder content = new StringBuilder();
while (true){
int read = fileReader.read();//一次读取一个字符,返回值是一个int
if (read == -1){
break;//表示文件读完了
}
char c = (char) read;
if (isCopy){
if(c=='<'){
isCopy=false;
continue;
}
if(c=='\n' || c == '\r'){//\r表示回车符
c=' ';
}
content.append(c);
}else if (c=='>'){
isCopy=true;
}
}
return content.toString();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
这样就成功了
java
public class Parser {
//指定加载文档的路径'
private static final String INPUT_PATH = "C:/Users/zjdsx/Desktop/docs/api";
public void run(){
//入口
//1.根据上面指定路径,枚举出所有的文件(html),包括所有的子目录
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
// System.out.println(fileList);
// System.out.println(fileList.size());
//2. 针对上面罗列出的文件路径,打开文件,读取文件内容,解析,构建索引
for (File file : fileList) {
System.out.println("开始解析:"+file.getAbsolutePath());
parseHTML(file);//解析html文件
}
//3.在内存中构造好的索引数据结果,保存到指定的文件中
}
private void parseHTML(File file) {
//1.解析出标题
String title = parseTitle(file);
System.out.println(title);
//2.解析出html对应url
String url = parseUrl(file);
//3.解析出html正文
String content = parseContent(file);
System.out.println(content);
}
private String parseContent(File file) {
//先按照一个字符一个字符来读取,字符流
try(FileReader fileReader = new FileReader(file)) {
//加上一个是否要进行拷贝的开关
boolean isCopy= true;
StringBuilder content = new StringBuilder();
while (true){
int read = fileReader.read();//一次读取一个字符,返回值是一个int
if (read == -1){
break;//表示文件读完了
}
char c = (char) read;
if (isCopy){
if(c=='<'){
isCopy=false;
continue;
}
if(c=='\n' || c == '\r'){//\r表示回车符
c=' ';
}
content.append(c);
}else if (c=='>'){
isCopy=true;
}
}
return content.toString();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private String parseUrl(File file) {
//先获取一个固定的前缀
String part1 = "https://docs.oracle.com/javase/8/docs/api/";
// file.getAbsolutePath().substring(INPUT_PATH.length());//这个就是截取INPUT_PATH.length()下标到最后
String part2 = file.getAbsolutePath().substring(INPUT_PATH.length());
String result = part1 + part2;
// System.out.println(result);
return result;
}
private String parseTitle(File file) {
String title = file.getName().substring(0,file.getName().length()-".html".length());//getName得到ArrayList.html,file.getAbsolutePath()是得到所有全路径
//标题不需要html这个后缀,,,ArrayList.html,,,,,,,点的位置就是总长度减去5就是9,substring是左闭右开
return title;
}
private void enumFile(String inputPath, ArrayList<File> fileList) {
File rootPath = new File(inputPath);
File[] files = rootPath.listFiles();//listFiles获取到当前目录下的所有文件和文件夹,只有这一级目录的
for (File file : files) {
//根据f的类型,决定是否要递归,如果file是一个普通文件,加入fileList数组,如果是一个目录,就递归调用
if (file.isDirectory()) {
//是一个目录
enumFile(file.getAbsolutePath(), fileList);
}else {
if (file.getAbsolutePath().endsWith(".html")) {
fileList.add(file);
}
}
}
}
public static void main(String[] args) {
Parser p = new Parser();
p.run();
}
}但是还没有把解析出来的内容放入索引中