前言
学习机器学习的过程中,我逐渐意识到:
如果只有代码,而没有理论,就很难真正理解模型在做什么
如果只有概念,而缺少一个系统框架,又难以把知识串成体系
《统计学习方法》正好提供了这样一个结构清晰的入口------它把机器学习的核心思想和经典算法用统计学的语言表达出来,帮助我们理解算法背后的原理。

因此,我决定开启这个专栏,用自己的方式整理学习笔记。主要目标是:
- 用更直白的语言梳理书中的概念
- 把知识点整理成便于查阅和复习的形式
- 记录自己的理解和思考过程
这些笔记主要是我个人的学习记录,如果恰好对你也有帮助,那就更好了。希望通过这个过程,能让自己对机器学习的理论基础有更扎实的理解。
第5章------决策树(上)
本章先介绍决策树的基本概念,然后通过 ID3 和 C4.5 介绍特征的选择、决策树的生成以及决策树的修剪,最后介绍 CART 算法。
5.1 决策树模型与学习
决策树是一种基本的分类与回归方法。
5.1.1 决策树模型
分类决策树模型是一种描述对实例进行分类的树形结构。这种结构由结点和有向边组成,其中结点分为两类:椭圆形的内部结点代表特征或属性,矩形的叶结点代表类别。最上面的结点称为根结点,所有的分类判断都从这里开始。
整个模型通过树形结构,将复杂的分类问题分解为一系列简单的判断过程,使得分类逻辑清晰直观。
5.1.2 决策树与if-then规则
决策树本质上就是一系列if-then规则的集合,这是程序员最熟悉的一种逻辑表达方式。从根结点到每个叶结点的路径都对应着一条if-then规则。值得注意的是,一个矩形叶结点可能会有多条路径到达,正如"条条大路通罗马"。但对于每一个具体的实例,只能选择其中一条路径进行分类。
这些if-then规则具有两个重要特点:互斥性和完备性。
互斥性 是指决策树通过特征属性进行分叉后,不同分支之间没有交集;完备性则表示所有分支整合在一起包含了全部的分类情况,不会遗漏任何可能性。
5.1.3 决策树与条件概率分布
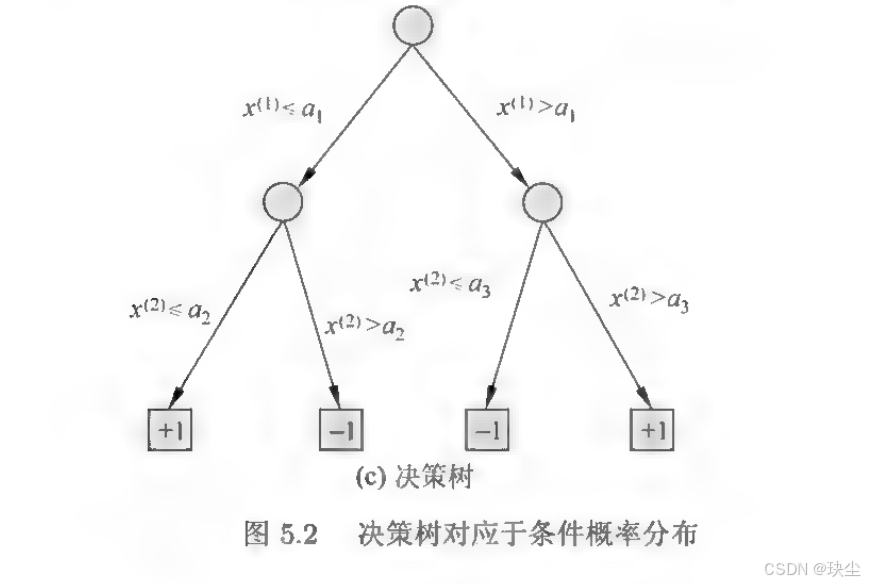
从概率论的角度看,决策树的根本是一个条件概率模型 。一棵决策树可以表示成给定特征条件下类的条件概率分布,记作P(Y|X)。这里X代表给定的特征,Y代表在该特征条件下所对应的类别。
这种条件概率分布实际上相当于对特征空间进行了划分(partition) ,每个叶结点对应特征空间中的一个单元(cell)或区域(region),该区域内的所有实例都被归为同一类别。
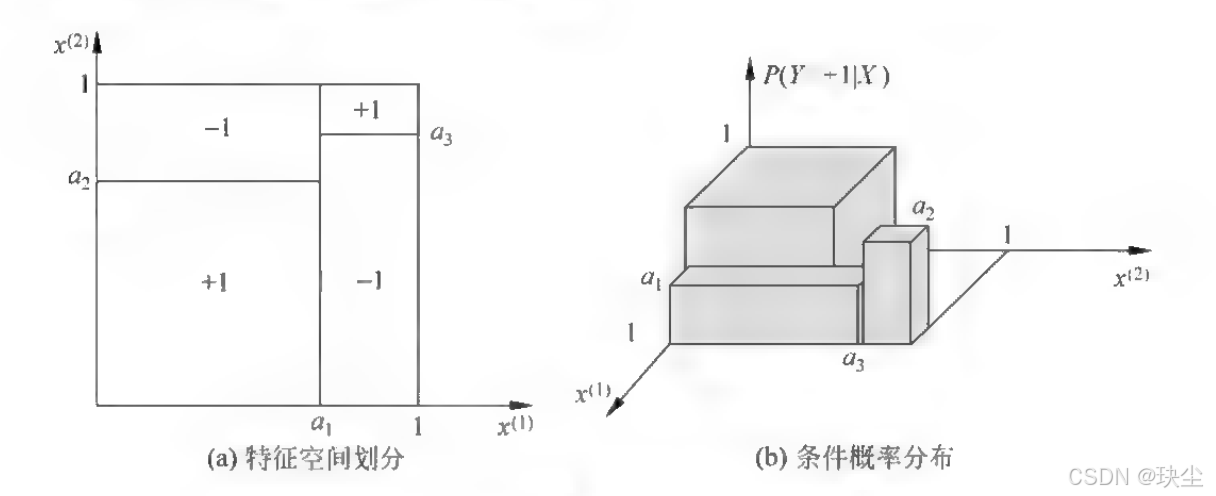
通过这种方式,决策树将高维的特征空间分割成若干个不相交的子空间,每个子空间对应一个类别标签。
5.1.4 决策树学习
决策树学习的核心是从训练数据集中归纳出一组分类规则。
给定训练数据集 D={(x1,y1),(x2,y2),⋯,(xn,yn)}D = \{{(x₁,y₁), (x₂,y₂), ⋯, (xₙ,yₙ)}\}D={(x1,y1),(x2,y2),⋯,(xn,yn)},其中xixᵢxi是特征向量,yiyᵢyi是类标记,决策树学习的目标是构建一个既能正确分类训练数据,又具有良好泛化能力的决策树模型。
从本质上看,决策树学习是通过训练数据估计条件概率模型的过程。由于满足条件的决策树可能有无穷多个,我们需要选择一个不仅对训练数据拟合良好 ,而且对未知数据预测准确的模型。这个目标通过损失函数来表达,通常采用正则化的极大似然函数,学习策略就是最小化这个损失函数。
决策树的构建过程是一个递归的特征选择和数据分割过程。从根结点开始,选择一个最优特征将训练数据分割成子集,使每个子集在当前条件下达到最好的分类效果。如果子集已经能被基本正确分类,则构建叶结点;否则继续选择新的最优特征进行分割,直到所有数据子集被正确分类或没有合适特征为止。
生成的决策树可能对训练数据分类很好,但容易出现过拟合问题。因此需要进行剪枝操作,自下而上地去掉过于细分的叶结点,使其回退到父结点或更高层结点,从而简化模型,提高泛化能力。此外,当特征数量很多时,也可以在学习开始前进行特征选择,只保留具有足够分类能力的特征。
决策树学习算法主要包含三个过程:特征选择、决策树生成和决策树剪枝。其中,决策树生成关注局部最优,通过递归分割实现;决策树剪枝则考虑全局最优,通过简化模型提高泛化性能。不同深度的决策树对应着不同复杂度的概率模型。
5.2 特征选择
5.2.1 特征选择问题
特征选择的目的是从众多特征中挑选出对训练数据具有分类能力的特征,从而提高决策树学习的效率。如果某个特征用于分类的效果与随机分类没有显著差别,说明这个特征不具备分类能力,可以将其舍弃。实践表明,去掉这类无效特征对决策树的分类精度影响很小,反而能简化模型,加快学习速度。
举个简单的例子:假设我们要预测一个人是否喜欢运动,有三个候选特征------年龄、鞋码和兴趣爱好。通过分析发现,年龄和兴趣爱好与是否喜欢运动有较强的关联性,而鞋码的大小与是否喜欢运动几乎没有关系。因此,鞋码这个特征的分类能力很弱,可以在构建决策树时将其排除,只保留年龄和兴趣爱好这两个更有价值的特征。
特征选择的常用准则是信息增益 或信息增益比,它们能够量化特征的分类能力。
5.2.2 信息增益
前提知识
在信息论中,熵(Entropy) 用来度量一个随机变量的不确定性。对离散随机变量 XXX,其分布为 P(X=xi)=piP(X=x_i)=p_iP(X=xi)=pi,熵定义为:
H(X)=−∑i=1npilogpi H(X) = -\sum_{i=1}^n p_i \log p_i H(X)=−i=1∑npilogpi
若某事件的概率为 1,则熵为 0,说明没有任何不确定性;而当分布越均匀时,熵越大,不确定性也越高。
在此基础上,可以进一步考虑"已知某一特征后,随机变量的不确定性还剩多少"。这就引出了 条件熵(Conditional Entropy) 。如果已知变量 XXX,那么变量 YYY 的剩余不确定性由条件熵描述,其定义为:
H(Y∣X)=∑ipiH(Y∣X=xi) H(Y|X) = \sum_{i} p_iH(Y|X=x_i) H(Y∣X)=i∑piH(Y∣X=xi)
也就是说,我们按照特征 (X) 的不同取值将样本划分成多个子集,并在每个子集中计算标签 (Y) 的熵,最后对这些熵按子集大小作加权平均。
信息增益
在决策树学习中,我们最关心的是某个特征是否能"减少对类别的不确定性"。因此引入 信息增益(Information Gain),即观察特征 (A) 之后,类别的不确定性减少了多少。其定义为:
g(D,A)=H(D)−H(D∣A) g(D,A) = H(D) - H(D|A) g(D,A)=H(D)−H(D∣A)
其中 H(D)H(D)H(D) 是数据集在不考虑任何特征时的经验熵 ,表示分类任务整体的不确定性;而 H(D∣A)H(D|A)H(D∣A) 是在特征 AAA 给定的前提下,数据集分类的不确定性。二者的差值越大,说明特征 AAA 对分类越有帮助。
因此,决策树在进行特征选择时,会计算所有候选特征的信息增益,并选择 信息增益最大的特征 作为当前节点的划分依据。信息增益越大,该特征对类别的解释能力越强,也更适合作为分裂节点。
计算步骤
输入 :训练数据集 DDD 和特征 AAA
输出 :特征 AAA 对训练数据集 DDD 的信息增益 g(D,A)g(D,A)g(D,A)
① 计算经验熵 H(D)H(D)H(D):
H(D)=−∑k=1K∣Ck∣∣D∣log2∣Ck∣∣D∣ H(D) = -\sum_{k=1}^K \frac{|C_k|}{|D|} \log_2 \frac{|C_k|}{|D|} H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣
② 按特征 AAA 的取值划分数据集,计算经验条件熵H(D∣A)H(D|A)H(D∣A):
H(D∣A)=∑i=1n∣Di∣∣D∣H(Di)=−∑i=1n∣Di∣∣D∣∑k=1K∣Dik∣∣Di∣log2∣Dik∣∣Di∣ H(D|A) = \sum_{i=1}^n \frac{|D_i|}{|D|} H(D_i) = -\sum_{i=1}^n \frac{|D_i|}{|D|} \sum_{k=1}^K \frac{|D_{ik}|}{|D_i|} \log_2 \frac{|D_{ik}|}{|D_i|} H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣
③ 得出信息增益:
g(D,A)=H(D)−H(D∣A) g(D, A) = H(D) - H(D|A) g(D,A)=H(D)−H(D∣A)
例题解析(P75)
这块不再讲解,感兴趣可以自己去看下。
5.2.3 信息增益比
信息增益虽然能够有效衡量特征的分类能力,但存在一个明显问题:它偏爱取值数量多的特征。比如用"身份证号"这个特征来划分数据,由于每个人的身份证号都不同,信息增益会很大,但实际上这对分类毫无意义。
为了解决这个问题,我们引入信息增益比来校正这种偏向性。
5.2.3 信息增益比
信息增益虽然能够有效衡量特征的分类能力,但存在一个明显问题:它偏爱取值数量多的特征。比如用"身份证号"这个特征来划分数据,由于每个人的身份证号都不同,信息增益会很大,但实际上这对分类毫无意义。
为了解决这个问题,我们引入信息增益比来校正这种偏向性。
特征A对训练数据集D的信息增益比gR(D,A)g_R(D,A)gR(D,A)定义为:
gR(D,A)=g(D,A)HA(D)g_R(D,A) = \frac {g(D,A)}{H_A(D)} gR(D,A)=HA(D)g(D,A)
其中,Hᴀ(D)=−∑i=1n∣Di∣∣D∣log2∣Di∣∣D∣Hᴀ(D) = -\sum_{i=1}^n \frac{|Dᵢ|}{|D|}log₂ \frac{|Dᵢ|}{|D|}Hᴀ(D)=−∑i=1n∣D∣∣Di∣log2∣D∣∣Di∣, n是特征AAA取值的个数。
简单来说,信息增益比就是用信息增益除以特征AAA的固有值Hᴀ(D)Hᴀ(D)Hᴀ(D)。这个固有值反映了特征取值的分散程度------取值越多,固有值越大。通过这种除法运算,相当于对取值多的特征进行了"惩罚",使得特征选择更加公平合理。
信息增益比越大,说明该特征在排除取值数量影响后,仍然具有较强的分类能力,因此更值得选择。
5.3 决策树的生成
本节先介绍决策树学习的生成算法。首先介绍ID3的生成算法,然后再介绍C4.5中的生成算法。这些都是决策树学习的经典算法。
5.3.1 ID3算法
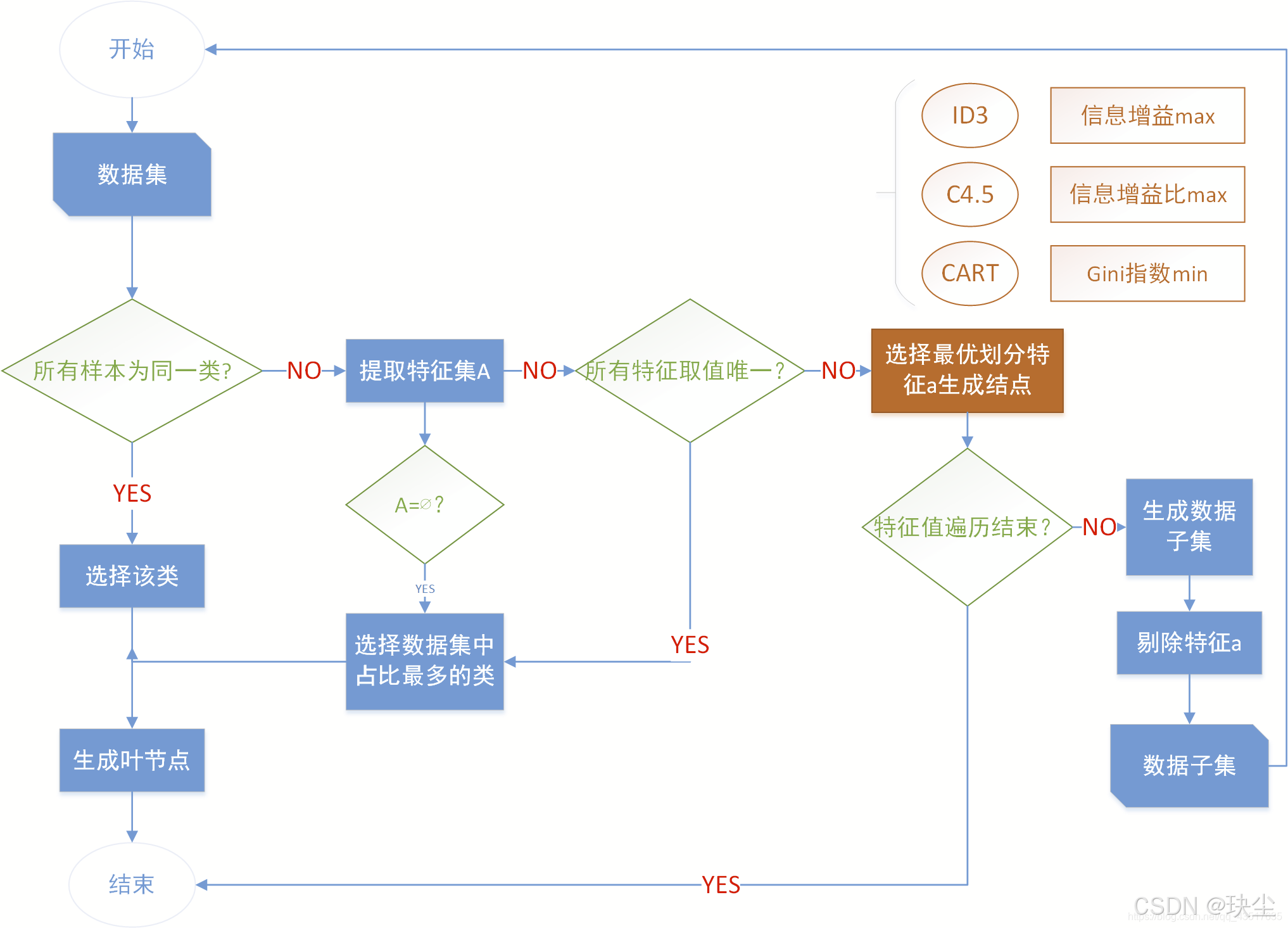
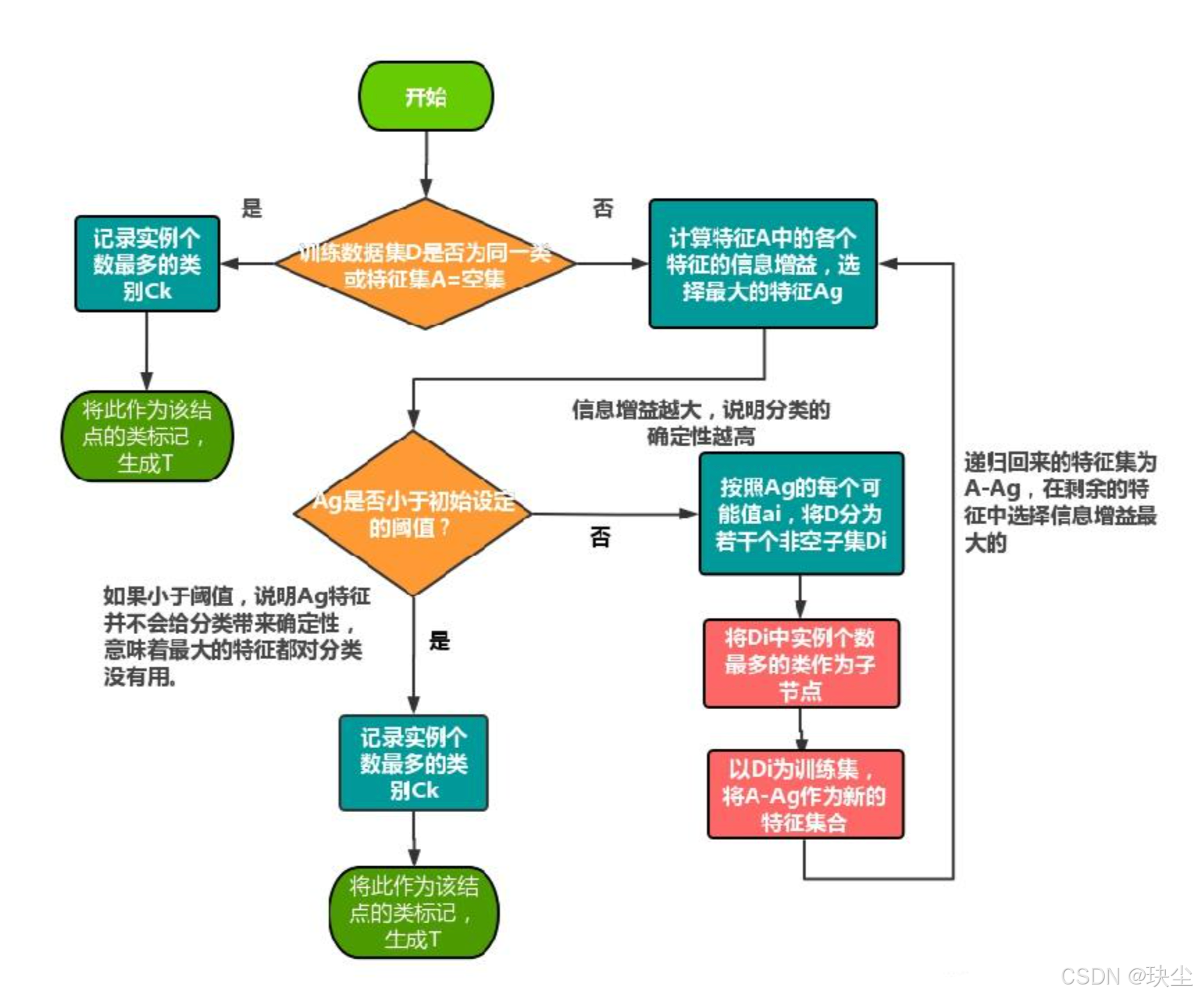
ID3算法是最经典的决策树学习算法之一,它采用信息增益作为特征选择的标准,通过自顶向下的递归方式构建决策树。算法的输入是训练数据集D、特征集A和阈值ε,输出是一棵决策树T。
算法的基本流程
首先判断当前数据集是否需要继续划分。
- 如果数据集D中所有实例都属于同一类别Cₖ,说明分类已经完成,直接生成单结点树并标记为类别Cₖ返回。
- 如果数据集D中的特征集A已经为空(A=∅) ,说明没有特征可用了,这时生成单结点树,将D中实例数最多的类别Cₖ作为该结点的类标记并返回,这体现了多数表决的原则。
如果上述两种终止条件都不满足,算法进入特征选择阶段。计算特征集A中每个特征的信息增益,选出信息增益最大的特征AgA_gAg。此时再次判断:
-
如果AgA_gAg的信息增益小于阈值ε,说明继续划分的价值不大,同样生成单结点树T,采用多数表决确定类标记并返回。
-
如果AgA_gAg的信息增益大于阈值ε,就按照特征AgA_gAg的各个可能取值aiaᵢai将数据集D分割成多个非空子集DiDᵢDi。对每个子集DiDᵢDi,将其中实例数最多的类别作为标记,构建对应的子结点,由这些子结点和父结点共同构成树T。
最后是递归过程。对于第 i 个子结点,以DiDᵢDi作为新的训练集,以A−AgA-{A_g}A−Ag(去除已使用特征AgA_gAg后的特征集)作为新的特征集,递归调用上述步骤生成子树TiTᵢTi。这个过程会不断重复,直到所有分支都满足终止条件。
ID3算法的核心在于通过信息增益贪心地选择最优特征进行划分,并通过阈值ε控制树的生长,避免过度拟合。当信息增益不足或数据已被正确分类时,算法就会停止该分支的生长,从而构建出一棵有效的决策树。
算法流程图
5.3.2 C4.5的生成算法
C4.5算法是ID3算法的改进版本,两者的整体流程完全相同,唯一的区别在于特征选择准则:C4.5算法使用信息增益比代替信息增益来选择划分特征。由于信息增益比校正了信息增益偏好取值较多特征的问题,C4.5算法在特征选择上更加合理,能够更有效地避免选择那些取值数量多但实际分类能力弱的特征。