导入
在当今数据驱动的时代,数据分析能力已成为程序员和数据分析师的必备技能。Python凭借其强大的生态系统(pandas、numpy、matplotlib等)在数据处理和可视化领域占据重要地位。本文将通过四个真实场景的数据分析案例,全面展示Python在数据处理、统计分析和可视化方面的强大能力。
题目一:超市商品销售数据分析
"超市销售数据.csv" 包含字段:"日期""商品类别""商品名称""销售数量""单价 (元)""会员等级 (普通 / 银卡 / 金卡)"。
代码
python
import pandas as pd
import matplotlib.pyplot as plt
import datetime
# 1. 读取 CSV 文件数据,将 "日期" 转换为 datetime 格式。
df = pd.read_csv(
"超市销售数据.csv",
encoding="utf-8"
)
print(df)
df['日期'] = pd.to_datetime(df['日期'])
print(df['日期'].dtype)
# 2. 计算每类商品的总销售额(销售数量 × 单价)和平均销售单价。
df['销售额'] = df['销售数量'] * df['单价 (元)']
total_sales = df.groupby('商品类别')['销售额'].sum()
mean_sales = df.groupby('商品类别')['单价 (元)'].mean()
print("每类商品的总销售额为:\n", total_sales)
print("每类商品的平均销售单价为:\n", mean_sales)
# 3. 按 "会员等级" 分组,统计不同等级会员的总消费金额和平均单次消费金额。
total_sales = df.groupby('会员等级 (普通/银卡/金卡)')['销售额'].sum()
counts_sales = df.groupby('会员等级 (普通/银卡/金卡)')['销售数量'].sum()
mean_sales = total_sales / counts_sales
print("不同等级会员的总销售额为:\n", total_sales)
print("不同等级会员的平均单次消费金额为:\n", mean_sales)
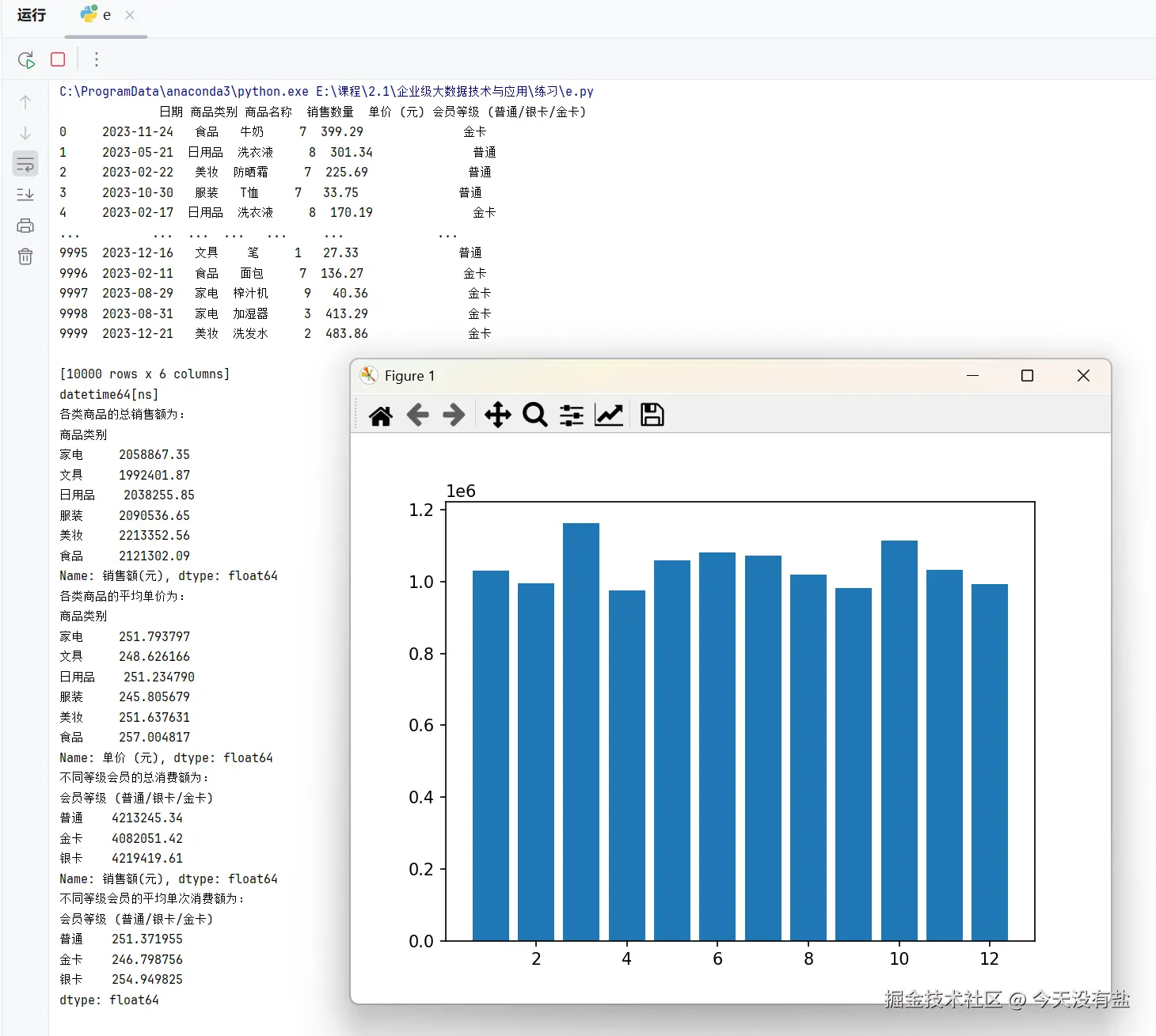
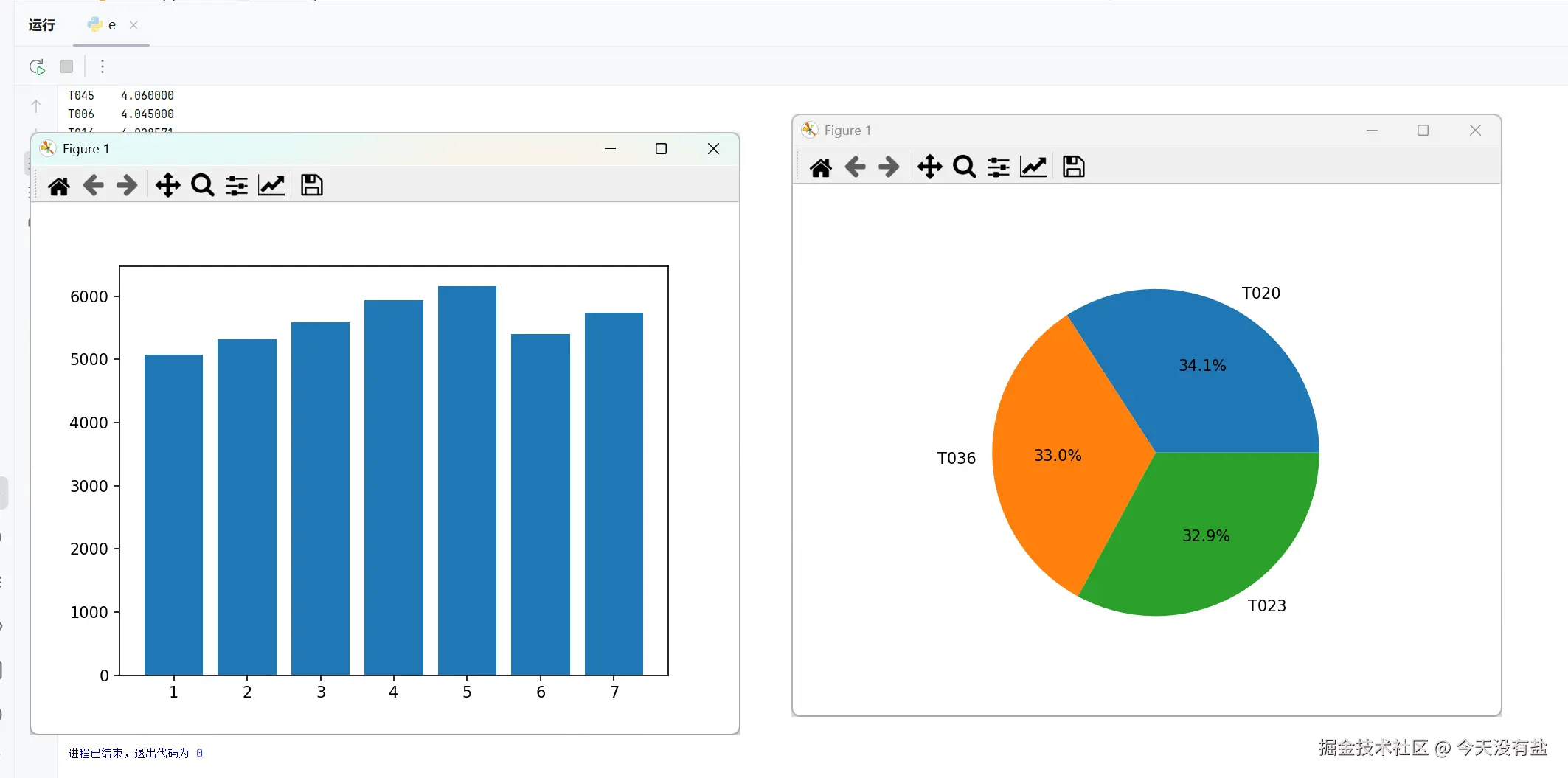
# 4. 提取 "日期" 中的月份,绘制每月总销售额的柱状图。
df['月份'] = df['日期'].dt.month
total_sales = df.groupby('月份')['销售额'].sum()
plt.bar(total_sales.index, total_sales)
plt.show()
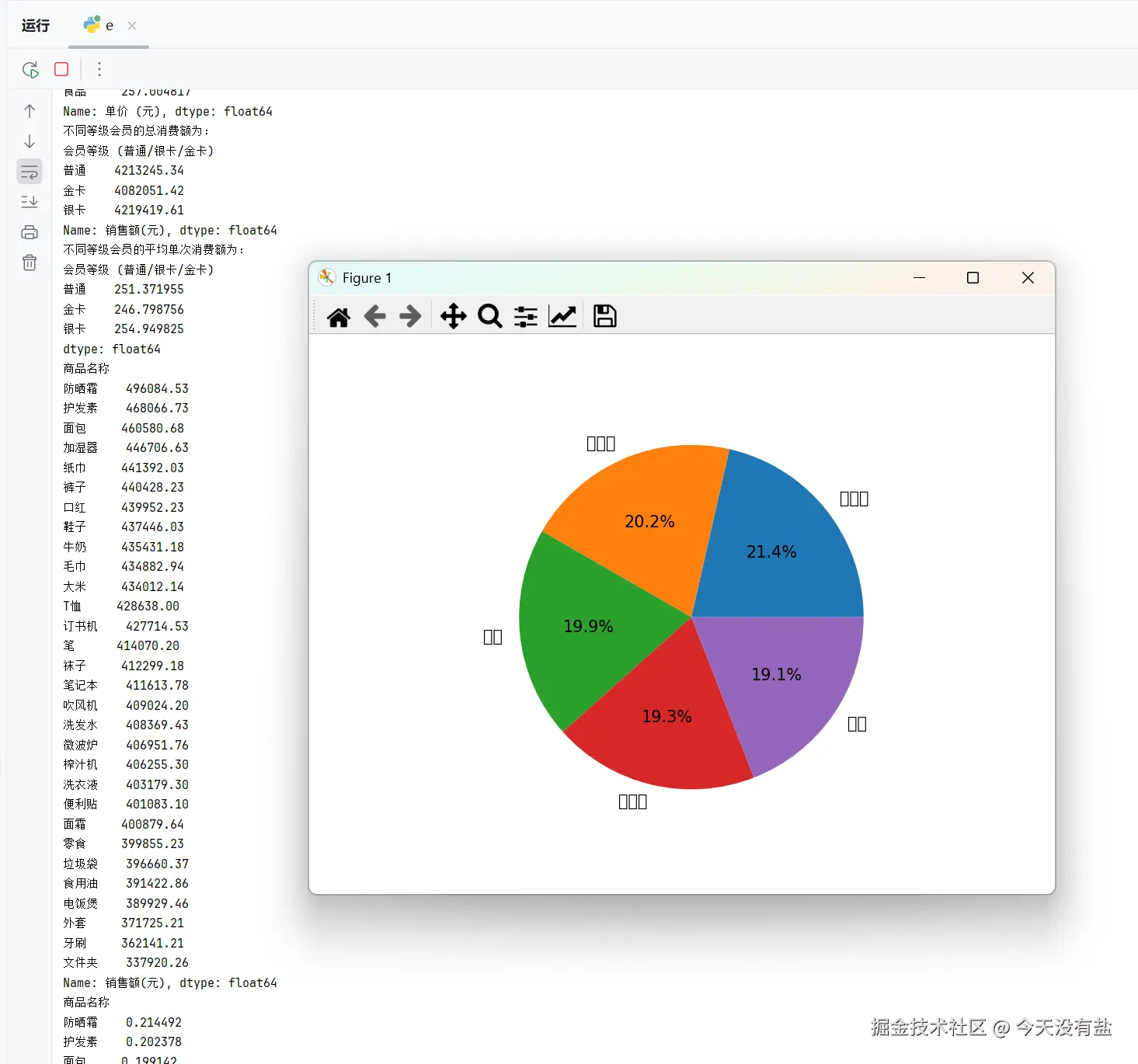
# 5. 找出总销售额最高的 5 种商品,用饼图展示它们的销售额占比。
plt.rcParams['font.sans-serif'] = ['SimHei']
product_sales = df.groupby('商品名称')['销售额'].sum().sort_values(ascending=False)
print(product_sales)
top5 = product_sales.head(5) # 前5个
top5_sum = top5.sum()
top5_pie = top5 / top5_sum
print(top5_pie)
plt.pie(top5_pie, labels=top5_pie.index,autopct="%1.1f%%")
plt.show()代码结果
题目二:线上书店订单数据分析
"书店订单数据.csv" 包含字段:"订单 ID""用户 ID""图书类别""购买数量""图书定价 (元)""折扣率 (0.7-1.0)""支付时间"。
代码
python
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取 CSV 文件数据,计算实际支付金额(图书定价 × 折扣率 × 购买数量),添加为新列。
data = pd.read_csv(
"书店订单数据.csv",
encoding="utf-8",
index_col="订单ID"
)
print(data)
data['实际支付金额'] = data['图书定价 (元)'] * data['折扣率 (0.7-1.0)'] * data['购买数量']
print(data)
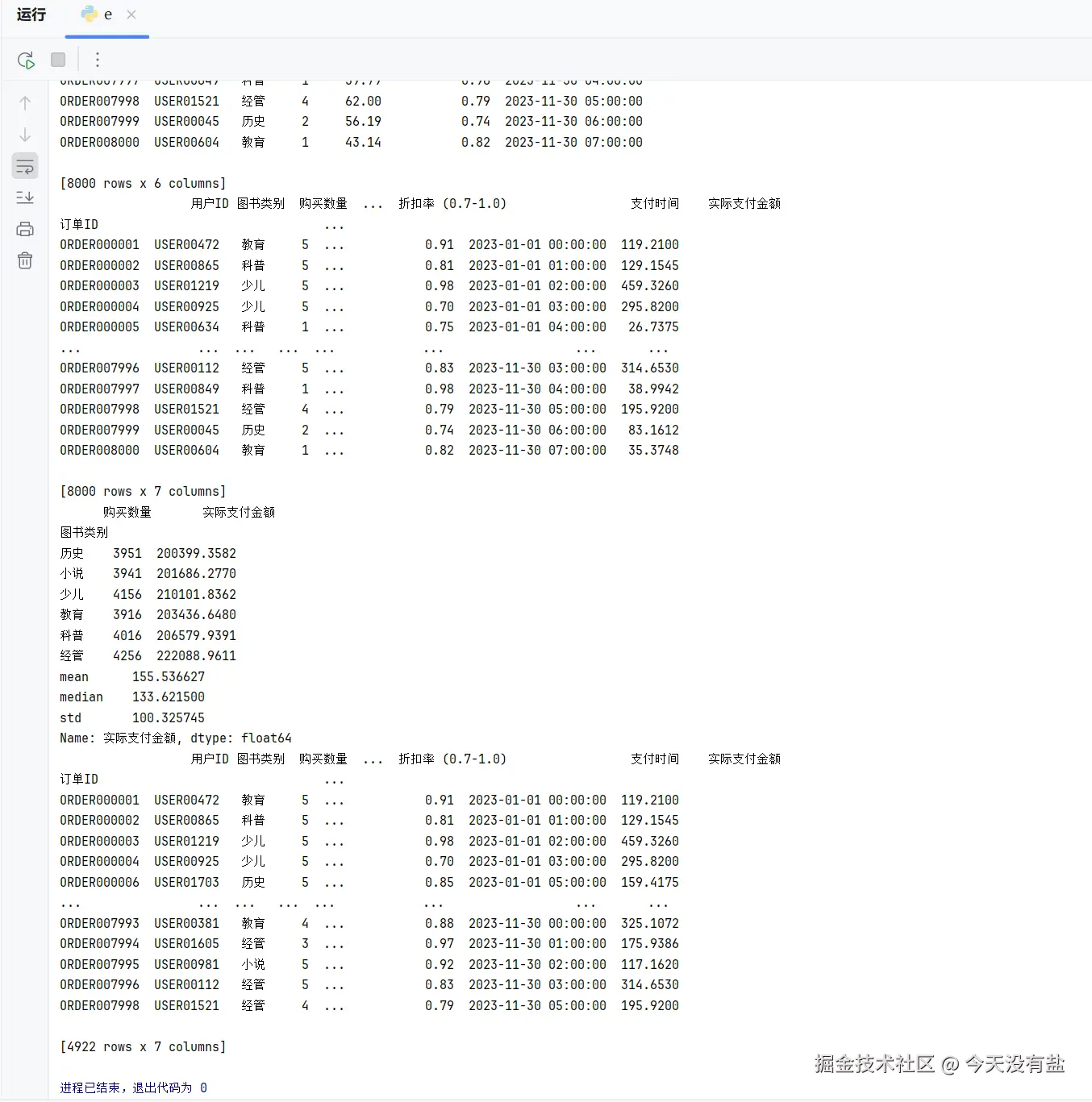
# 2. 按 "图书类别" 分组,统计各类别的总销量和总实际支付金额。
states = data.groupby('图书类别').agg({"购买数量":"sum", "实际支付金额":"sum"})
print(states)
# 3. 计算所有订单的实际支付金额的均值、中位数和标准差。
new_states = data['实际支付金额'].agg(['mean', 'median', 'std'])
print(new_states)
# 4. 筛选出购买数量 ≥3 本的订单,保存为新 CSV 文件 "大额订单.csv"(不含索引)。
tmp = data[data['购买数量'] >= 3]
print(tmp)
tmp.to_csv(
'大额订单.csv'
)代码结果
题目三:学生考试成绩数据分析
"考试成绩数据.csv" 包含字段:"班级""学号""姓名""语文""数学""英语""理综 / 文综""考试时间"。
代码
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 1. 读取 CSV 文件数据,计算每位学生的总分(四门科目之和)和平均分,添加为新列。
df = pd.read_csv(
"考试成绩数据.csv"
)
print(df)
subjects = ['语文','数学','英语','理综/文综']
df['总分'] = df[subjects].sum(axis=1)
df['平均分'] = df[subjects].mean(axis=1)
print(df)
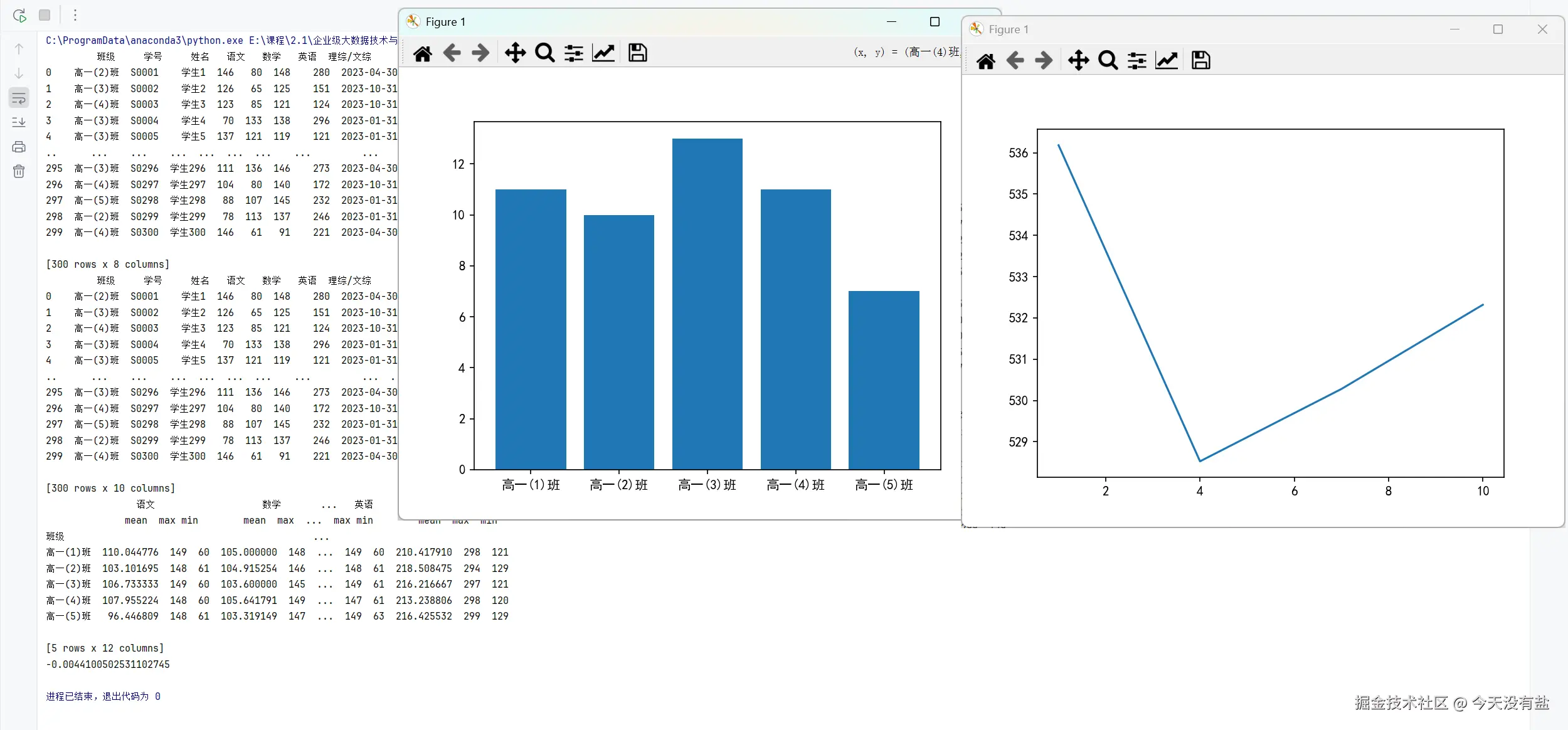
# 2. 按 "班级" 分组,统计各科目的平均分、最高分和最低分(使用 agg 函数批量统计)。
states = df.groupby('班级')[subjects].agg(['mean','max','min'])
print(states)
# 3. 筛选出总分 ≥600 分的学生,统计每个班级的高分人数,绘制柱状图。
plt.rcParams['font.sans-serif'] = ['SimHei']
high_student = df[df['总分'] >= 600]
high_counts = high_student['班级'].value_counts().sort_index()
plt.bar(high_counts.index, high_counts)
plt.show()
# 4. 计算数学成绩与理综/文综成绩的相关系数。
corr = df['数学'].corr(df['理综/文综'])
print(corr)
# 5. 提取 "考试时间" 中的月份,统计不同月份的平均总分变化,绘制折线图。
df['考试时间'] = pd.to_datetime(df['考试时间'])
df['月份'] = df['考试时间'].dt.month
month_score = df.groupby('月份')['总分'].mean()
plt.plot(month_score.index, month_score)
plt.show()代码结果
题目四:教师教学评价数据分析
"教学评价数据.csv" 包含字段:"教师 ID""学科""授课班级""学生评分 (1-5 分)""评价人数""评价日期"。
代码
python
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取 CSV 文件数据,将 "评价日期" 转换为 datetime 格式。
data = pd.read_csv(
"教学评价数据.csv"
)
print(data)
data['评价日期'] = pd.to_datetime(data['评价日期'])
print(data)
# 2. 计算每位教师的总评分(学生评分 × 评价人数)和平均评分,添加为新列。
data['总评分'] = data['学生评分 (1-5分)'] * data['评价人数']
mean_score = data.groupby('教师ID')['学生评分 (1-5分)'].mean()
print(data)
print(mean_score)
# 3. 按 "学科" 分组,统计各学科的平均评分和总评价人数。
states = data.groupby('学科').agg({
'总评分':'mean',
'评价人数':'sum'
})
states = states.rename(columns={'总评分':'平均评分'})
print(states)
# 4. 提取 "评价日期" 中的星期信息,统计每周各天的评价数量,绘制柱状图。
data['评价日期'] = pd.to_datetime(data['评价日期'])
data['星期'] = data['评价日期'].dt.weekday + 1
counts = data.groupby('星期')['评价人数'].sum()
print(counts)
plt.bar(counts.index, counts)
plt.show()
# 5. 找出平均评分最高的 3 位教师,用饼图展示他们的总评分占比。
mean_score = mean_score.sort_values(ascending=False) # 降序排序
print(mean_score)
top3 = mean_score[:3]
total = mean_score.sum() # 总评分
top3_rate = top3 / total
plt.pie(top3_rate, labels=top3_rate.index,autopct="%1.1f%%")
plt.show()代码结果
总结
-
数据读取与预处理
- 多种数据格式的读取(CSV)
- 数据类型转换(日期时间处理)
- 数据清洗和列操作
-
数据计算与转换
- 派生列的计算创建
- 分组聚合统计
- 多维度数据透视
-
统计分析技术
- 描述性统计(均值、中位数、标准差)
- 相关性分析
- 排名和筛选
-
数据可视化
- 多种图表类型应用(柱状图、饼图、折线图)
- 中文显示处理
- 图表美化和标签设置