Kafka-3 Kafka 中的生产者
前置文章中利用 docker 搭建了一个 kafka 实例:Docker 部署 Kafka,并结合 SpringBoot 进行了整合。
发送消息时我们只需要注入对应类型的 KafkaTemplate 并调用 send 方法即可,非常简单
java
@Service("kafkaProducerService")
@Slf4j
public class KafkaProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String message) {
kafkaTemplate.send("test-topic", "test", message);
log.info("Sent message: {}", message);
}
}操作的简单其实意味着内部封装了很多的细节,这篇文章就是用来详细分析 kafka producer
消息分区算法
在 Kafka 的基本概念中提到 topic 和 partition,producer 在发送消息时如果没有特殊说明,消息会发送到当前 topic 的某一个 partition 中,那么具体是发往哪一个呢?

类比一下 nginx 的负载均衡,一个 upstream 中有多个上游服务,根据某种策略选择合适的服务进行请求转发,kafka 的分区机制也有负载均衡的作用,因此消息分区机制其实也就是 kafka 的负载均衡算法。
对应配置项 spring.kafka.producer.properties.partitioner.class
轮询(RoundRobin)
轮询几乎是所有负载均衡算法中都会有的一个选项,好处非常明显,绝对的公平,实现起来也简单。
生产者只需要维护一个 Map,key 是 topic 的名字,value 是一个从 0 开始的整数,每次遇到消息时取出该 topic 对应的 value,对当前的 partition 数取余即可。
粘性分区(UniformSticky)
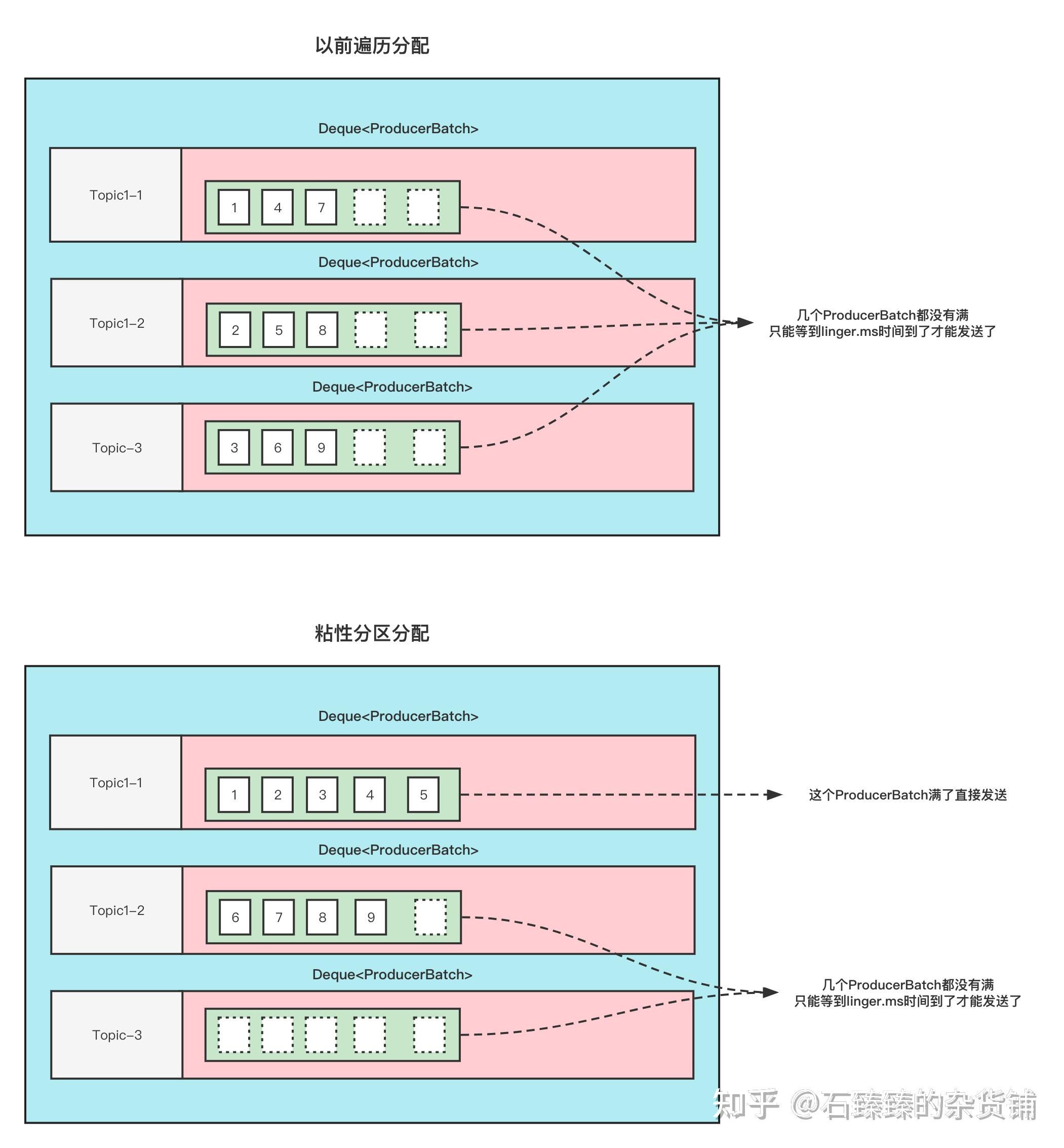
在了解粘性分区之前,先思考一个问题,如果生产者产生了一条消息就立刻发送,那么吞吐量一定不会太高,因为发送是需要走网络协议的,如果能减少请求次数,例如多个消息合并为一个批次进行发送,就有可能提高吞吐量。HTTP1.1性能优化 中其实也有这样的思想,对于多个小文件例如 css、js 等一次请求拿到所有结果。
Kafka 中该算法的思路是,为每个分区维护一个发送队列,队列中每个元素为固定大小的空间,消息会先放到该队列的最后一个未填满的元素上,直到该元素被填满或到达了等待时间。
假设每个消息的大小是固定的,每个元素能放置 5 个消息,如果有 3 个分区,9 条消息,按照轮询算法,每个分区的发送队列的最后一个元素都会放 3 个消息,没有一个填满的,都需要等到等待时间结束才能发送。而按照粘性分区算法,第1个分区的末尾元素能填满 5 条,第二个分区的末尾元素存放 4 条,这样分区 1 的这个元素就可以进行发送了。
消息键分区
Kafka 中除了上述的两种分区策略,还有一个 Default 分区策略,也是默认的分区策略
kafkaTemplate 的 send 方法有多个重载
java
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {
ProducerRecord<K, V> producerRecord = new ProducerRecord(topic, data);
return this.doSend(producerRecord);
}
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
ProducerRecord<K, V> producerRecord = new ProducerRecord(topic, key, data);
return this.doSend(producerRecord);
}第二个重载方法中存在一个泛型 key,在默认分区策略中,如果 key 不会 null,就会根据 key 进行 hash 运算,对分区数进行取模,这样可以保证同一 key 的消息分布在同一个 partition,kafka 会保证同一个 partition 内的消息有序消费。
如果不指定 key,则会走粘性分区策略进行分区
自定义分区
Kafka 的分区机制是一个接口,只需要实现这个接口即可 org.apache.kafka.clients.producer.Partitioner.class
java
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class KafkaPartitionerConfig implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}自定义分区机制需要修改分区配置类才能生效!
同时也可以查找这个接口的实现类找到其他几个分区策略的实现

消息缓存模型
在分区机制的粘性分区中提到了:消息不是立刻就发送出去的,而是首先进入该分区对应的缓存队列的最后一个元素中,如果最后一个元素有足够空间,就追加进入,否则创建一个新的元素或直接分配足够大的空间写入。
在 Kafka 中这个元素的大小是一个配置项,默认值是 16384 (16K)
yaml
spring:
kafka:
producer:
bootstrap-servers: ****:9094
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
partitioner:
class: com.xsdl.config.KafkaPartitionerConfig
batch-size: 16384
buffer-memory: 33554432当要发送消息时,首先估算一下这个消息的大小,接着分配足够的空间
java
if (buffer == null) {
// 取一个 batchSize 的大小和消息的预估大小中的更大值
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(
RecordBatch.CURRENT_MAGIC_VALUE, compression.type(), key, value, headers));
// This call may block if we exhausted buffer space.
// 分配足够大小的空间
buffer = free.allocate(size, maxTimeToBlock);
}Kafka 中使用了一块缓冲池,大小是 32M,也就是 buffer-memory 的 33554432,由于经常需要分配一个 16K 大小的空间,因此当该大小空间的消息发送出去后,这个内存并不会进行 GC 回收,而是简单 clear,并维护进入一个空闲队列,队列中每个空间的大小都是 16K,当再有需要时直接分配即可。

每一个 Producer 对象中有一个 RecordAccumulator 类型的属性,每个 RecordAccumulator 中维护了一个 Map,其中 key 是 topic,value 是一个 ProducerBatch 的 Deque。ProducerBatch 是发送的单位,一般是 16KB,但是也有比这个多(例如某记录特别大,单独创建了一个对应大小的 ProducerBatch )以及比这个少的(新消息来时发现前面的 ProducerBatch 的剩余容量已经不够了,因此前面这个是不满 16K 的)。
所以当创建 ProducerBatch 的时候可能有四种情况:
- 创建的大小是 16K 且空闲队列有空闲的 ProducerBatch,则直接分配即可
- 创建的大小是 16K 但空闲队列没有空闲的 ProducerBatch,则从剩余内存中创建一个 16K 的空间,分配给该消息使用,使用完成后 clear 进入空闲队列
- 创建的大小大于 16K 且除去空闲队列后的剩余空间足够,从剩余空间里分配,使用完后 GC 回收
- 创建的大小大于 16K 且除去空闲队列后的剩余空间不够,依次释放空闲队列中的 ProducerBatch,直到满足空间后分配,使用完后 GC 回收
消息确认机制
Kafka 如何确保消息不丢失,与消息确认机制密不可分。
首先总结一句话:Kafka 只对已提交的消息做最大程度的持久化保证。
- 已提交:如果 producer 使用的是异步发送,即 send 后就认为成功,此时如果服务异常停止,由于缓存模型的存在,可能消息并未成功发送,这种情况 kafka 自然不会有消息记录。同时当请求到达 Broker 端,如果 leader 节点保存成功就认为成功,那么突然发生断电,副本成为 leader 时由于还未同步刚刚的消息,自然也会丢失。
- 最大程度的保证:例如三节点环境的高可用我们一般指宕机一节点正常使用,如果三节点都挂了,自然无法提供服务,kafka 集群也是同理。
基于上述的分析,推荐的 Kafka 生产者端配置实践如下:
- 不要使用 producer.send(msg),而要使用带有回调通知的 send 方法。
- 设置 acks = all。acks 是 Producer 的一个参数,代表了你对"已提交"消息的定义。如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是"已提交"。这是最高等级的"已提交"定义。
- 设置 retries 为一个较大的值。这里的 retries 同样是 Producer 的参数,当出现网络的瞬时抖动时,消息发送可能会失败,此时配置了 retries > 0 的 Producer 能够自动重试消息发送,避免消息丢失。默认值应该是 Integer.MAX_VALUE,官方推荐是不要修改此配置,而是通过配置 request.timeout.ms 限制消息的超时时间而避免无限重试。
Kafka Broker 端配置如下:
- 设置 unclean.leader.election.enable = false。它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。
- 设置 replication.factor >= 3。这也是 Broker 端的参数。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
- 设置 min.insync.replicas > 1。这依然是 Broker 端参数,控制的是消息至少要被写入到多少个副本才算是"已提交"。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
- 确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas + 1。
Kafka 消费者端配置如下:
- 确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit,最好把它设置成 false,并采用手动提交位移的方式,对于单 Consumer 多线程处理的场景而言是至关重要的,它可以避免多线程消费失败但位移已提交而导致消息丢失的情况。
生产者拦截器
配置项:spring.kafka.producer.properties.interceptor.classes
yaml
spring:
kafka:
producer:
bootstrap-servers: ****:9094
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
interceptor:
classes: com.xsdl.config.KafkaInterceptor拦截器类只需要实现 ProducerInterceptor 接口
java
@Slf4j
public class KafkaInterceptor implements ProducerInterceptor {
@Override
public ProducerRecord onSend(ProducerRecord record) {
log.info("消息:{}被发送了", record.value());
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception == null) {
long offset = metadata.offset();
log.info("消息的偏移量是:{}", offset);
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}- onSend:该方法会在消息发送之前被调用。
- onAcknowledgement:在消息成功提交或发送失败之后被调用,这个方法处在 Producer 发送的主路径中,如果放很重的业务逻辑会严重影响消息的发送速度。
注意:onSend 和 onAcknowledgement 是不同线程中调用的,注意线程安全。
幂等性(Idempotence)
幂等主要避免的是重复发送,像我们在一些购物软件上购买相同产品时,可能会提示您与当前商户已经有一笔同金额的消费记录,请确认是否重复支付。
在 producer 发送消息等待 broker 返回响应的过程中,如果网络异常,导致 broker 响应超时,producer 会根据 retries 参数进行重试,如果不考虑幂等性可能会导致相同的消息被重复发送。
幂等这个概念其实涉及可靠性保障:
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(at least once):消息不会丢失,但有可能被重复发送。
- 精确一次(exactly once):消息不会丢失,也不会被重复发送。
如果最多一次,则 acks 参数设置为 0 即可,producer 发送完消息就认为成功,而如果至少一次,则无限制重试即可,直到有一次成功。无论是至少一次还是最多一次,都不如精确一次来得有吸引力。大部分用户还是希望消息只会被交付一次,这样的话,消息既不会丢失,也不会被重复处理。或者说,即使 Producer 端重复发送了相同的消息,Broker 端也能做到自动去重。在下游 Consumer 看来,消息依然只有一条。
Kafka 保证幂等性的方法大致如下,通过 Broker 端多保存一些字段。当 Producer 发送了具有相同字段值的消息后,Broker 能够自动知晓这些消息已经重复了,于是可以在后台默默地把它们"丢弃"掉。
【1】为每个 producer 维护一个 Pid。
【2】生产者 producer 维护一个 Map<Partitoon,Seq> key 是分区,value 是当前 producer 发送消息的序列号,一个从 0 开始的递增值
【3】broker 维护一个 <Pid, Partition, SN>,SN 是 broker 期望收到的下一条消息的 seq
例如 producer 发送了一个 <1,100> 的消息,broker 写入成功,更新自己该分区应该收到的下一条消息的 sn是 101,但是 ack 失败,由于 retries 的设置,producer 进行重试,broker 再次接收到消息后,发现 seq 100 < 预期收到的下一条消息 sn 101,认为已经成功写入,因此直接返回成功,以此来保证消息的幂等性。
通过上述的实现方式,可以看出一些幂等性的局限性:
- 只能实现单会话上的幂等性,不能实现跨会话的幂等性,因为 producer 更改会话后后 pid 会更新
- 只能保证单分区上的幂等性,即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性
开启的方法非常简单,producer 的 properties 中配置 enable.idempotence 为 true 即可,默认值就是 true。
事务性(Transaction)
ACID 的特性就不赘述了,事务型 Producer 能够保证将消息原子性地写入到多个分区中。
开启方式:
- enable.idempotence = true
- 设置 Producer 端参数 transctional. id。最好为其设置一个有意义的名字。springboot 中设置事务 id 前缀 spring.kafka.producer.transaction-id-prefix
在 Consumer 端,读取事务型 Producer 发送的消息也是需要一些变更的,需要设置 isolation.level 参数的值。当前这个参数有两个取值:
- read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer 提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。(因为无论事务最终是否成功,其实成功写入的消息已经存储了)
- read_committed:表明 Consumer 只会读取事务型 Producer 成功提交事务写入的消息。当然了,它也能看到非事务型 Producer 写入的所有消息。
序列化与消息压缩
其实除了上面提到的内容,还有关于【序列化】和【消息压缩的知识】,如果你用过 redisTemplate,那么基本也知道需要配置序列化器,否则 redis 会直接使用 jdk 的序列化方式,导致存到 redis 中的 key 和 value 看起来是乱码,Kafka 也是同理,需要在 producer 和 consumer 端配置对应的 key 和 value 的序列化方式。
消息压缩(配置参数:compression.type)是为了节省带宽而选择消耗 cpu 的权衡,压缩后消息体积会变小,自然能节省网络带宽,相应的需要增加客户端侧的 cpu 使用率。对于消息的流转:**Producer 端压缩、Broker 端保持、Consumer 端解压缩。**Broker 端会尊重 Producer 端的压缩算法选择,如果显示指定了 Broker 端和 Producer 端采用不一致的压缩方式,Broker 端的 cpu 使用率会增加,附图是可选压缩算法的分析:

如果服务器带宽一般,客户端 CPU 还不错,建议开启 zstd 压缩,这样能极大地节省网络资源消耗。
参考资料
【2】知乎-Kafka专栏
【3】B站-Kafka教程