文章目录
- Pre
- 引言:流数据时代的架构演进与挑战
- [1. Lambda架构简析与局限](#1. Lambda架构简析与局限)
- [2. Kappa架构原理及优势](#2. Kappa架构原理及优势)
- [3. Kafka支撑下的Kappa架构实战流程](#3. Kafka支撑下的Kappa架构实战流程)
- [4. 典型案例](#4. 典型案例)
- [5. Kappa架构常见疑问与场景分析](#5. Kappa架构常见疑问与场景分析)
- [6. 与流处理引擎生态的协同与演变](#6. 与流处理引擎生态的协同与演变)
- 结论:Kappa架构引领数据新范式
- 参考实践代码片段

Pre
大规模数据处理:04_大规模数据处理实战_从电商热销榜到分布式架构设计
大规模数据处理:05_分布式系统服务等级协议(SLA)实战评估与优化
大规模数据处理:06_分布式系统架构师必知的三大指标_扩展性、一致性与持久性
大规模数据处理:07_大规模数据处理模式深度剖析_批处理vs流处理
大规模数据处理:08_Workflow设计模式_大规模数据处理的架构利器
大规模数据处理:09_发布/订阅模式:流处理架构中的瑞士军刀
大规模数据处理:10_CAP定理深度解读与大规模数据处理系统架构设计
大规模数据处理:11_深入解析 Lambda 架构:亿级实时数据分析架构的技术原理与实战应用
引言:流数据时代的架构演进与挑战
随着数字化浪潮的推进,企业日益依赖于实时洞察 和大规模数据分析 。传统的批处理数据架构(如Hadoop模式)虽强大,但面对日渐增长的低延迟决策需求 和数据多样性 ,力有未逮。Lambda架构的问世一度缓解了批流融合难题,但它的复杂性与维护成本、双轨代码压力逐渐暴露。
在此背景下,Kappa架构 以"极致简化、全流处理"理念进入视野,成为大型互联网公司和数据驱动组织的新宠。核心代表技术Kafka从消息中间件演进为分布式数据流平台,为Kappa架构的落地提供了坚实支点。本文将系统梳理Kappa架构的原理、实践与典型案例,解析为何它正成为新一代大数据系统的主流范式。
1. Lambda架构简析与局限
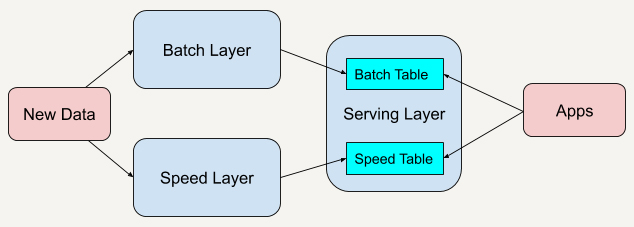
Lambda架构试图通过批处理层(Batch Layer)+流处理层(Speed Layer)+服务层(Serving Layer)的三级结构,实现既能应对延迟分析又满足实时查询。但应用中暴露如下问题:
- 代码冗余:批流需分别开发、测试与维护,研发成本高。
- 数据一致性难题:同一数据需在两套体系内保持一致,处理链路冗长且易错。
- 资源利用率低:重复计算与存储、资源浪费明显。
- 运维复杂性:系统上线、升级与监控难度大。
- 业务开发阻力:上线新功能涉及两套关键路径,响应慢,回归压力大。
2. Kappa架构原理及优势
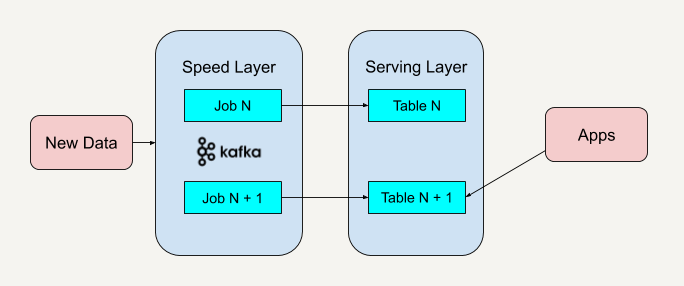
Kappa架构(Jay Kreps提出)强调"一切皆流",整个系统只保留流处理(Streaming)一条主路径,彻底摒弃批处理层。
核心思想:
- 数据统一入口:所有数据(历史和实时)统一经Kafka等流系统流入,完全以流方式存取与计算。
- 重处理(Reprocessing)机制简化:数据存在Kafka等可回放队列,需重新计算时,直接回读所有历史数据,无需为批处理单独编码。
- 更少的组件与代码冗余:简化架构,降低出错几率和维护成本。
- 本地状态与快照:结合流框架(如Flink、Kafka Streams)状态管理,实现高效、精准的一致性处理。
技术优势:
- 代码和流程极简:无批处理路径,开发效率极大提高。
- 可扩展性突出:流处理天然横向可扩展,匹配现代云原生趋势。
- 天然对抗数据倾斜与热点:Kafka等底层分区机制+并行消费,有优越的负载均衡能力。
- 实时性和"随需回溯"能力兼备:不仅低延迟,还可灵活回放历史数据进行修正。
3. Kafka支撑下的Kappa架构实战流程
Kafka并非"单纯消息队列",而是"分布式可持久化日志平台",助力Kappa架构落地的"基石":
-
数据采集与流入
- 日志、事件、IoT数据等通过Kafka Connect、异步API推送到Kafka主题。
- 设计合理的分区策略,保障数据倾斜最小化。
-
流处理引擎消费
- Kafka Streams、Flink、Spark Streaming、Beam等从Kafka消费数据,
- 实时完成 ETL、聚合、分组、窗口分析等操作。
-
中间状态与一致性
- 部分流计算需要状态存储(如计数、排序、流表Join等),可用RocksDB或外部存储。
- 结合Kafka事务与Exactly-once语义,实现无重复、无丢失处理。
-
结果下游入库/推送
- 处理结果推送至数据库(ClickHouse、Druid)、搜索引擎、下游服务或备用主题。
-
重处理与版本演进
- 当处理逻辑变更或修复历史BUG,只需新建Consumer Group重新消费全量历史数据,无需复杂的批流程。
4. 典型案例
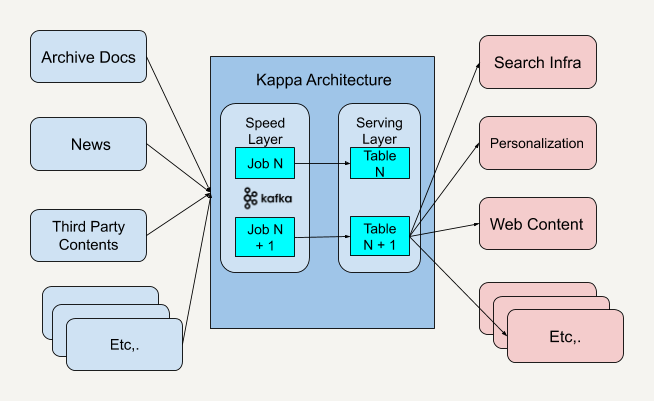
纽约时报(The New York Times)采用Kafka + Kappa架构,彻底"流式化"新闻内容生产、推送链路:
- 数据流统一:全站新闻、评论、阅读事件均通过Kafka分区主题流转,不区分实时与历史路径。
- 多样处理方式:基于Kafka的Consumer可做即时内容加工、推荐、审校、分发等。
- 随需回放:业务代码更新时,只需新Consumer回溯消费全部历史事件,业务一致性与可追溯性极强。
- 弹性扩展:热点新闻突发大流量可秒级感知与动态扩容,无需改造存量批处理。
经验总结:
- 数据治理层必须完善(数据多版本兼容、Schema管理等)。
- 历史数据存档策略需与Kafka保留周期配套。
- 较高的流处理开发能力要求,团队需成长。
5. Kappa架构常见疑问与场景分析
| 场景 | Lambda | Kappa |
|---|---|---|
| 数据一致性 | 易出现差异 | 只需保证流主路一致、易保障 |
| 功能上线/修正 | 两套变更 | 仅需更新流处理逻辑 |
| 历史数据修复/重放 | 必须批处理 | 直接Kafka回放 |
| 运维与监控 | 双路径 | 单路径、更易观测 |
| 业务响应速度 | 慢 | 快 |
常见疑惑:
- **Kappa适合所有流批需求吗?**答案是并不绝对。极需低延迟、数据量大、迭代频繁的OLAP/OLTP场景尤适合Kappa,依赖复杂历史跨批分析的方案(如年度大报表)仍可需批流混合。
- **Kafka存储压力、性能瓶颈如何解决?**依赖合理分区、容量扩展、冷热分层与高效归档手段。
- **实时分析漏洞咋修?**Kappa下重处理非常普遍------直接新建Consumer回滚全量事件、输出即可;需校验幂等设计。
6. 与流处理引擎生态的协同与演变
- Flink:天然适配Kappa架构,支持状态一致、高容错流处理,易与Kafka集成,可视为"Kappa最佳拍档"。
- Beam:跨平台流批统一,适合保留批流兼容性的企业过渡期。
- Spark Streaming/Structured Streaming:偏微批,但能简易对接Kafka做兼容性流任务。
- 云原生与Serverless流处理服务(如Confluent Cloud、Amazon MSK):管理、扩展、监控皆"云托管",极大降低技术门槛。
结论:Kappa架构引领数据新范式
- 技术变革加速,"一切皆流"正成为泛互联网、金融、传统大企业的主流路线。
- Kappa架构在开发效率、运营弹性、数据一致性等方面显著优于早期分层模式。
- 新形态下对流处理"全链路"能力 、Kafka生态治理等综合素质要求提升,需团队持续学习。
对于每一位后端/数据开发者,"全流路径"思维不仅是技术升级,更是生产力变革。善用Kappa架构与Kafka强大能力,能让业务创新快人一步、错一可回------成为真正的数据屠龙刀。
参考实践代码片段
java
// Kafka Producer 示例
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("news_topic", "event_001", "article content"));
// Kafka Streams Aggregation 示例
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> stream = builder.stream("news_topic");
KTable<String, Long> counts = stream
.flatMapValues(value -> Arrays.asList(value.split(" ")))
.groupBy((key, word) -> word)
.count();