现在不少干货内容,都是以图片形式展示的。这对我们有资料收集和存档需求的人来说,简直是个灾难:看着满屏文字,就是复制不下来。
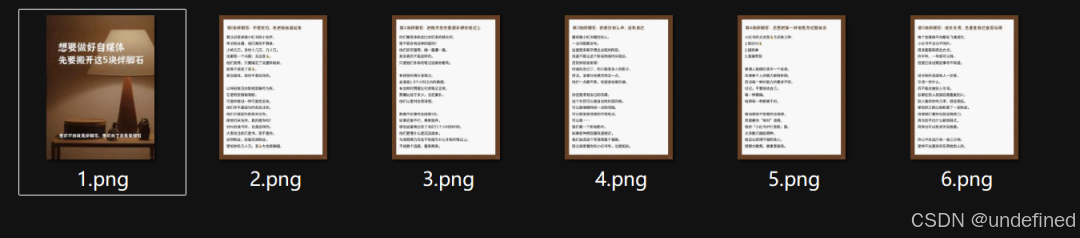
想转成文档存档?手敲是不可能的,动辄几百张图,得敲到什么时候;找OCR软件吧,好用的基本都收费,免费的又有次数限制。
作为一个不想花冤枉钱的"懒人",我折腾了3个用影刀RPA搞定的方案,主打一个零成本、自动化。
下面来说说这3种方案的实操逻辑和避坑指南,希望能帮你省下哪怕1个小时的摸鱼时间。
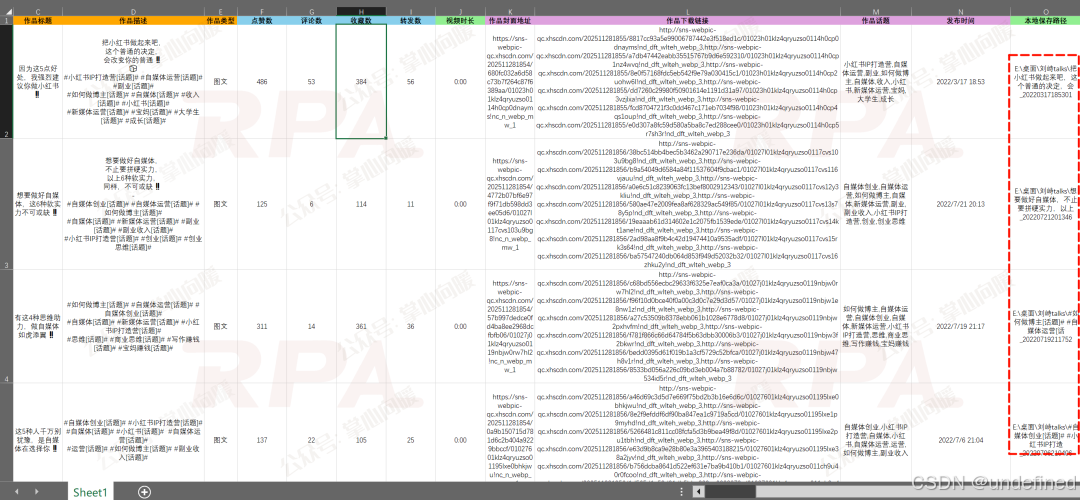
>> 具体场景实例 :之前我们用**批量采集红薯对标账号作品数据,14个数据字段+多条件筛选+导出Excel,盯竞品、做调研、搞二创都用得上!\| 影刀RPA**
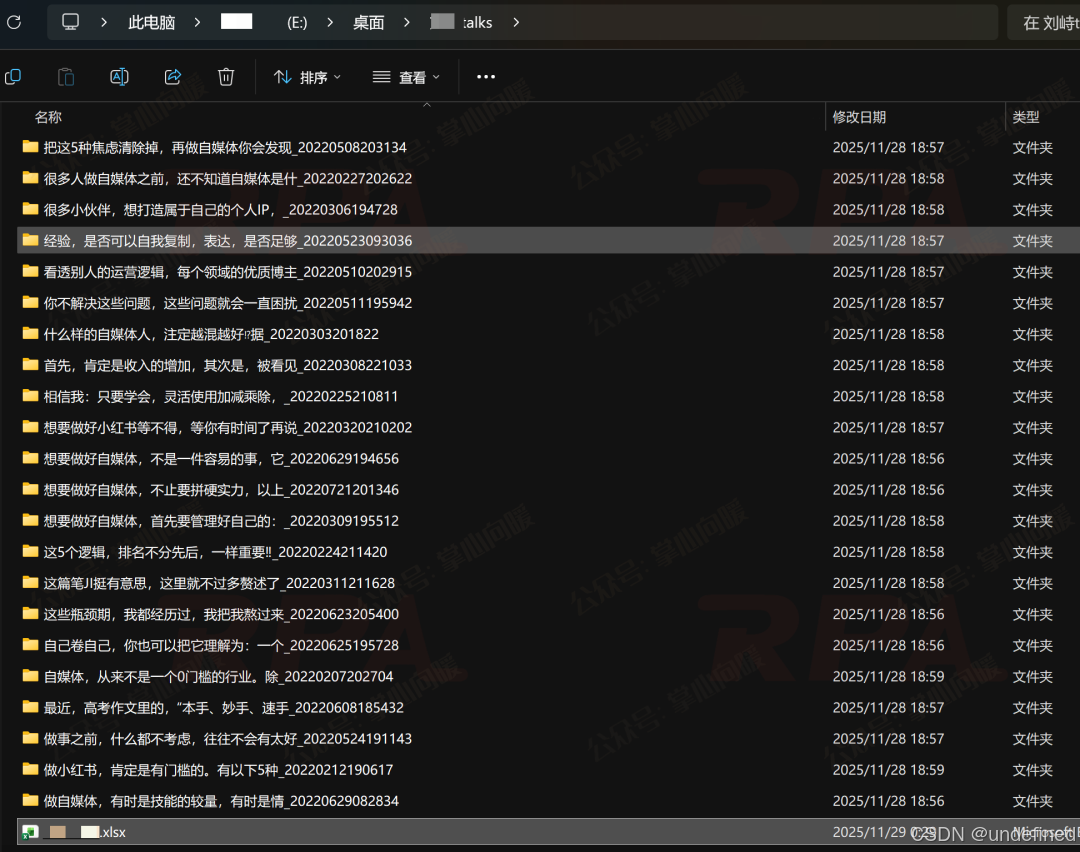
采集&下载到某博主的作品数据,得到一个Excel数据表 以及 以博主名称命名的本地文件夹:该文件夹下包含数十个独立子文件夹,每个子文件夹对应一篇笔记,里面存放着多张图片素材。
一、PixPin+RPA模拟人工
这个方案的逻辑很直观:模拟我们人的操作。打开图片 ->用截图工具框选 ->识别 ->粘贴进Word,主打一个"所见即所得"。为了保证识别质量,我配合了PixPin这款软件来实现整个自动化流程的搭建。
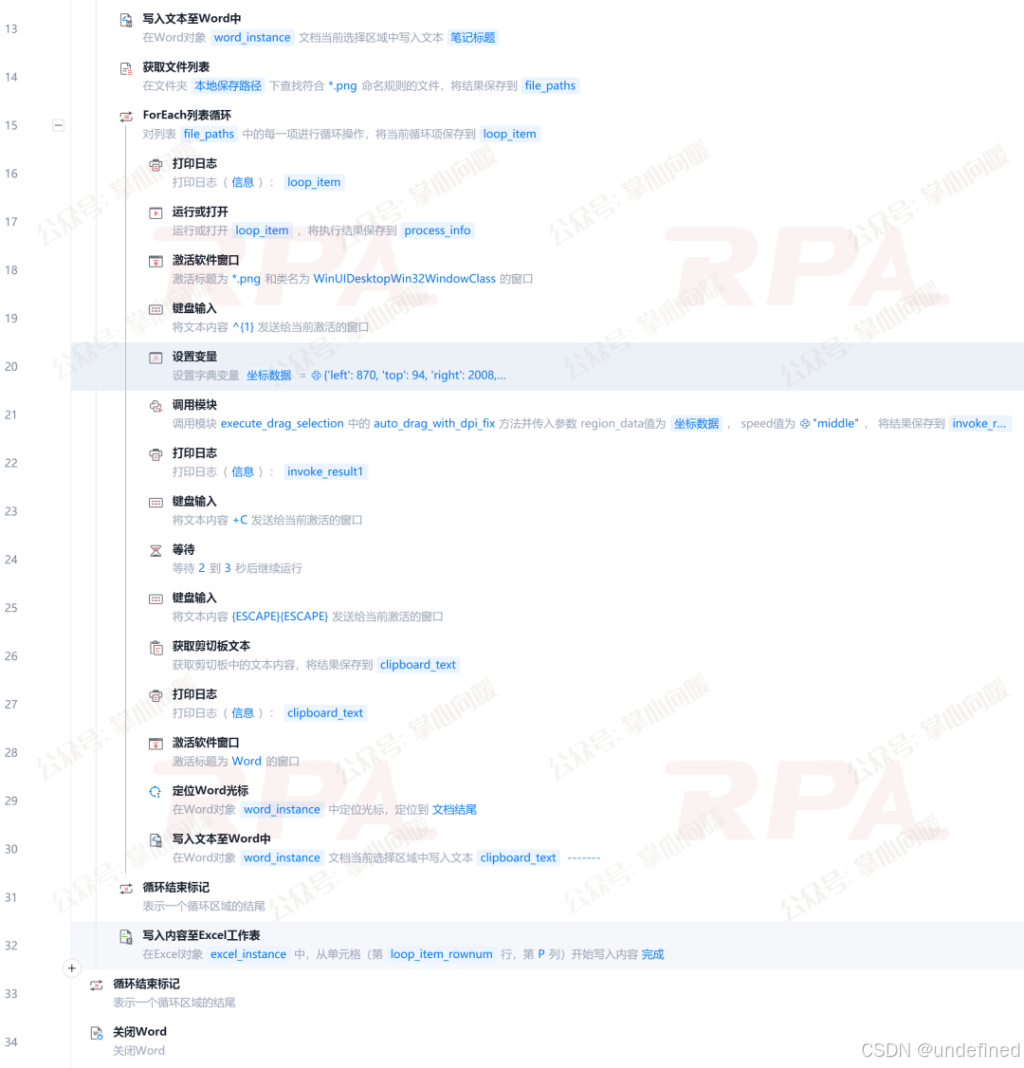
关键难点:通常RPA很难精准"拉选"指定区域(因为图片查看器会有干扰元素)。这里我们通过"**get_user_selection_region"**脚本辅助,先手动框选图片出现的屏幕区域,拿到坐标数据。
然后在影刀RPA的OCR识别主流程中调用"**execute_drag_selection"**脚本,让RPA根据坐标数据自动"画框框"。
使用体验 :精准度很高,而且可以设置标题大纲。但有个大坑:慢,真的慢。每张图都要打开、框选、识别、关闭,看着RPA在一张张操作,急性子可能会抓狂。它更适合作为一种思路参考,或者处理少量、对格式有一定要求的内容。
二、影刀原生"离线OCR"指令
如果不想依赖PixPin这种第三方软件,影刀自带的"离线OCR"指令其实是个不错的选择。
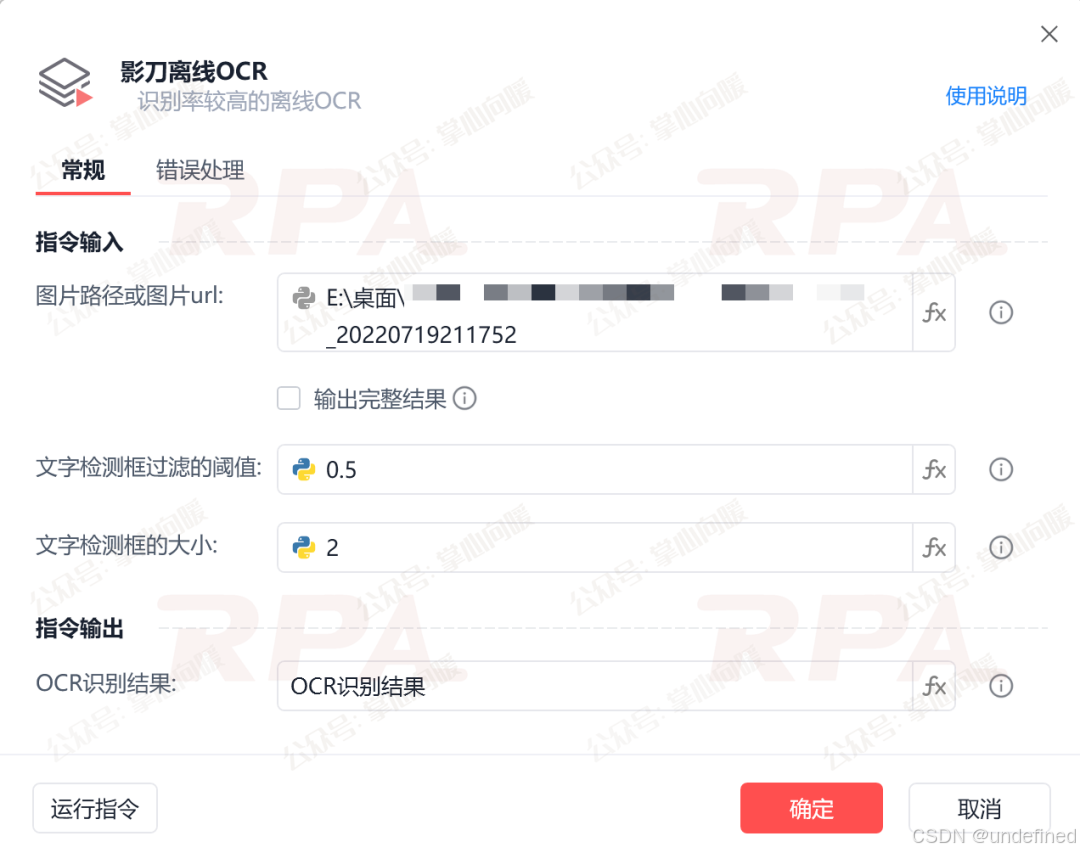
操作拆解:主流程跟方案一差不多,但是不再需要打开图片,而是直接读取图片路径、调用官方OCR指令进行识别。指令返回的是一个列表,我们需要加一个 ForEach 循环,把这些零散的文字一行行写入Word文档。
使用体验:相比方案一,这个方案清爽很多。不用频繁开关窗口,也不用写Python脚本去算坐标,稳定性强了不少。**识别精准度也在线,不用联网也能跑。**遗憾的是:速度依然不够快。虽然省去了UI交互的时间,但单张图片的识别处理还是需要时间,面对海量数据时,效率依然是瓶颈。
三、魔法指令+Umi-OCR
这是我目前测试下来,效率最高的方案。
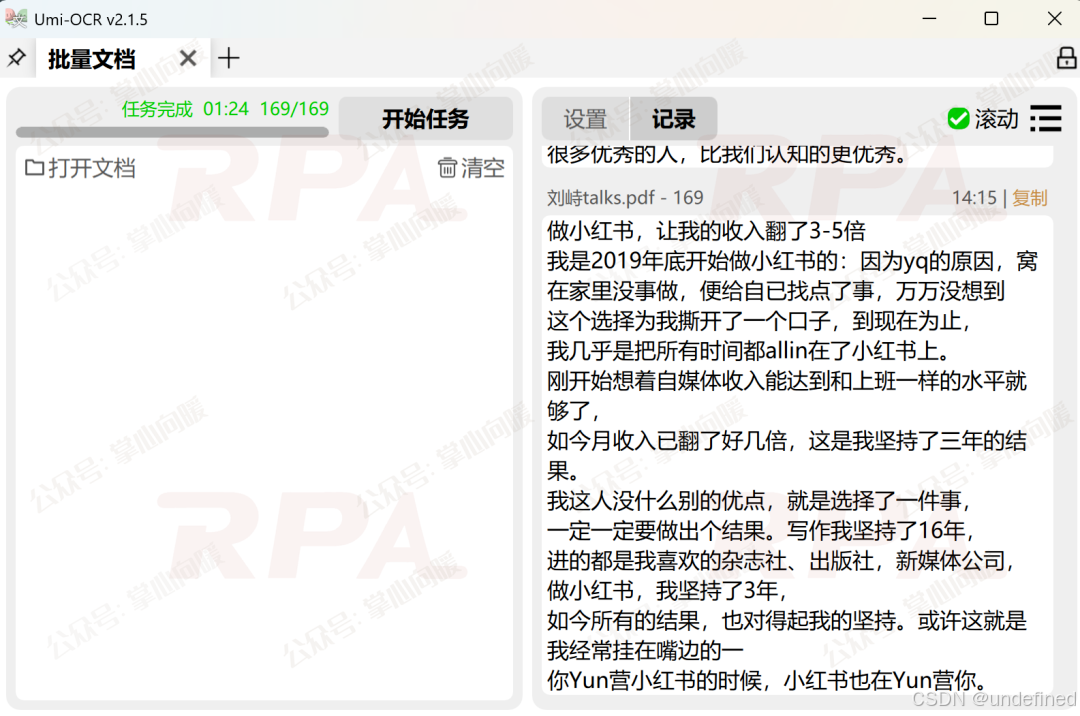
操作拆解:用一条魔法指令将路径下每个子文件夹里的图片合并成一个PDF,再把所有PDF再合并成一个总文件。
最后使用 Umi-OCR 软件的"批量文档OCR"功能,快速识别处理,处理结束后会在指定路径下生成一个TXT文本文件。
使用体验 :这就不是快一点点了,是数量级的提升。但是因为不涉及逻辑判断,识别结果没办法设置标题大纲级别。如果你只在乎内容分析(比如做词频统计、洗稿素材),不在乎排版,强烈推荐选这个方案。

为了方便大家选择,我做了一个简单的对比:
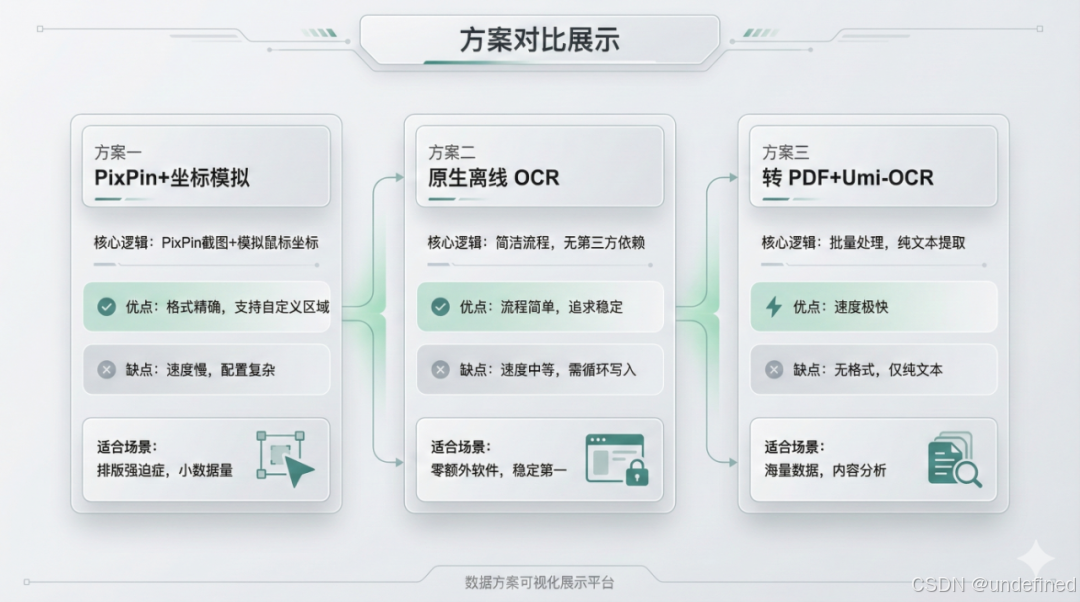
如果你需要跑成百上千张图片,无脑选方案三 。如果你只是想存档几个优质账号,需要保留阅读体验,方案一或方案二会更适合。
工具是死的,思路是活的。不要为了自动化而自动化,能解决问题的就是好方案。以上和你分享,有用请点赞,感谢支持!

-END-
- 爱练字的96年ISTJ型互联网人/信息整合怪/工具人/影刀高级认证工程师。
- 专注分享:RPA&AI自动化场景提效方案、效率软件安利、实用技能。"所有的生产要素都可以被构建,只有认知是壁垒",欢迎関注。