一、大模型部署
首先需要有一个可访问的大模型,通常有三种选择:
- 使用开放的大模型API。
- 在云平台部署私有大模型。
- 在本地服务器部署私有大模型。
使用开放大模型API的优缺点如下:
- 优点:
- 没有部署和维护成本,按调用收费。
- 缺点:
- 依赖平台方,稳定性差。
- 长期使用成本较高。
- 数据存储在第三方,有隐私和安全问题。
云平台部署私有模型:
- 优点:
- 前期投入成本低。
- 部署和维护方便。
- 网络延迟较低。
- 缺点:
- 数据存储在第三方,有隐私和安全问题。
- 长期使用成本高。
本地部署私有模型:
- 优点:
- 数据完全自主掌控,安全性高。
- 不依赖外部环境。
- 虽然短期投入大,但长期来看成本会更低。
- 缺点:
- 初期部署成本高。
- 维护困难。
二、本地部署大模型
很多云平台都提供了一键部署大模型的功能。我们讲讲如何手动部署大模型。
手动部署最简单的方式就是使用Ollama,这是一个帮助你部署和运行大模型的工具。官网如下:
2.1 下载安装ollama
首先,我们需要下载一个Ollama的客户端,在官网提供了各种不同版本的Ollama,大家可以根据自己的需要下载。
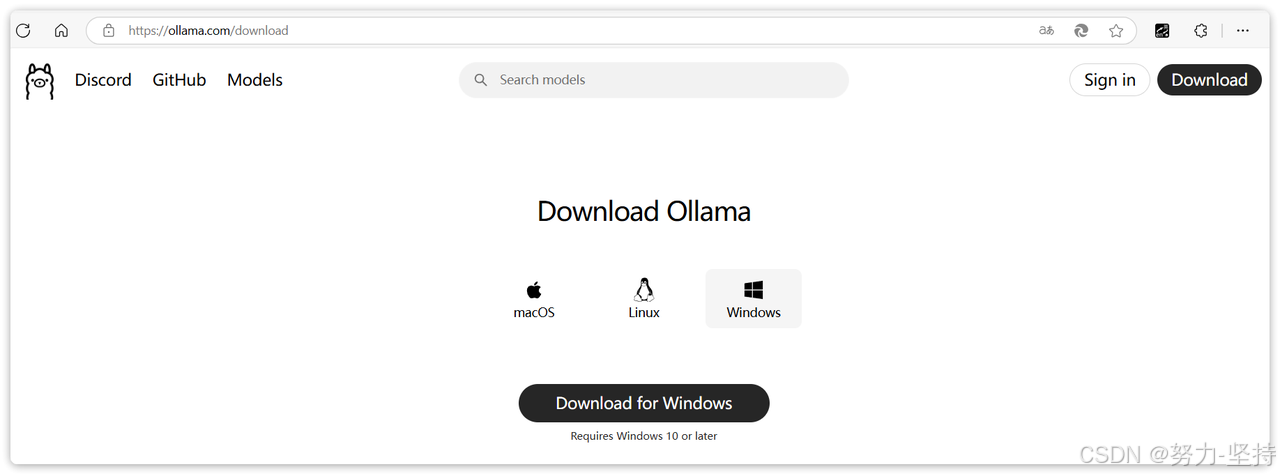
下载后双击即可安装。
注意:
Ollama默认安装目录是C盘的用户目录,如果不希望安装在C盘 的话,就不能直接双击安装了。需要通过命令行安装。
命令行安装方式如下:
在OllamaSetup.exe所在目录打开cmd命令行,然后命令如下:
Bash
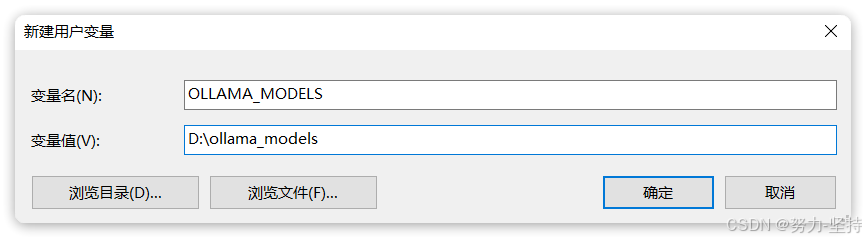
OllamaSetup.exe /DIR=你要安装的目录位置OK,安装完成后,还需要配置一个环境变量,更改Ollama下载和部署模型的位置。环境变量如下:
Bash
OLLAMA_MODELS=你想要保存模型的目录环境变量配置方式,配置完成如图:
2.2 搜索模型
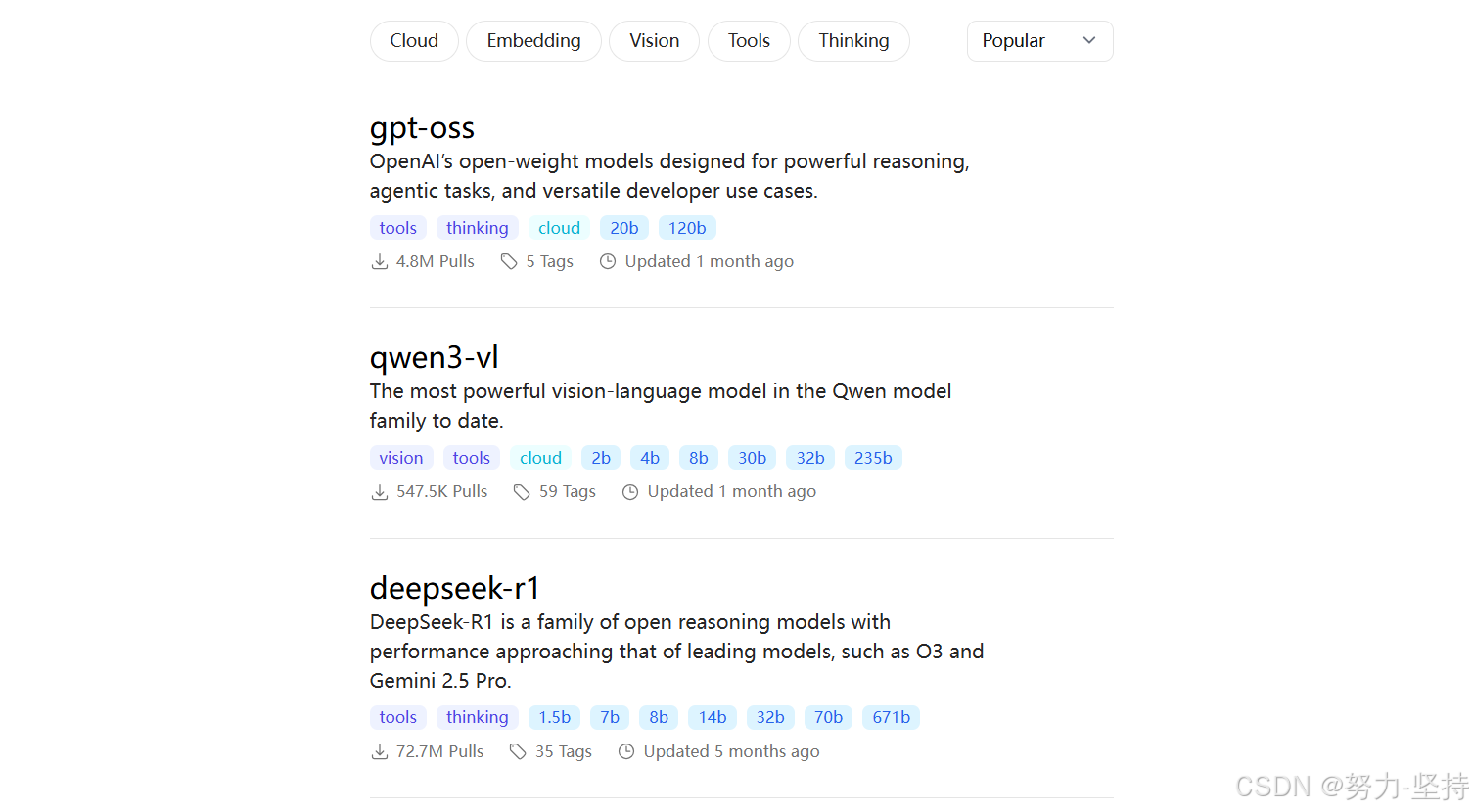
ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型,我们可以在其官网上搜索自己需要的模型:
如图,目前热度排第一的就是deepseek-r1:
点击进入deepseek-r1页面,会发现deepseek-r1也有很多版本:
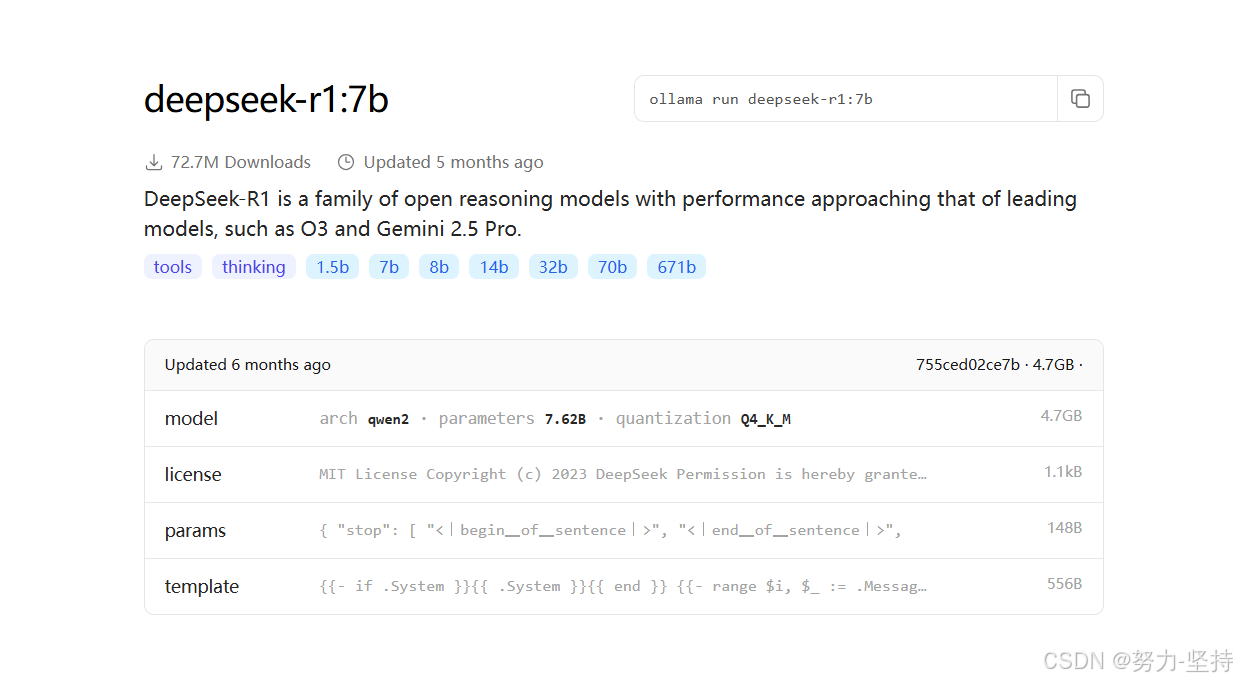
这些就是模型的参数大小,越大推理能力就越强,需要的算力也越高。671b版本就是最强的满血版deepseek-r1了。需要注意的是,Ollama提供的DeepSeek是量化压缩版本,对比官网的蒸馏版会更小,对显卡要求更低。对比如下:
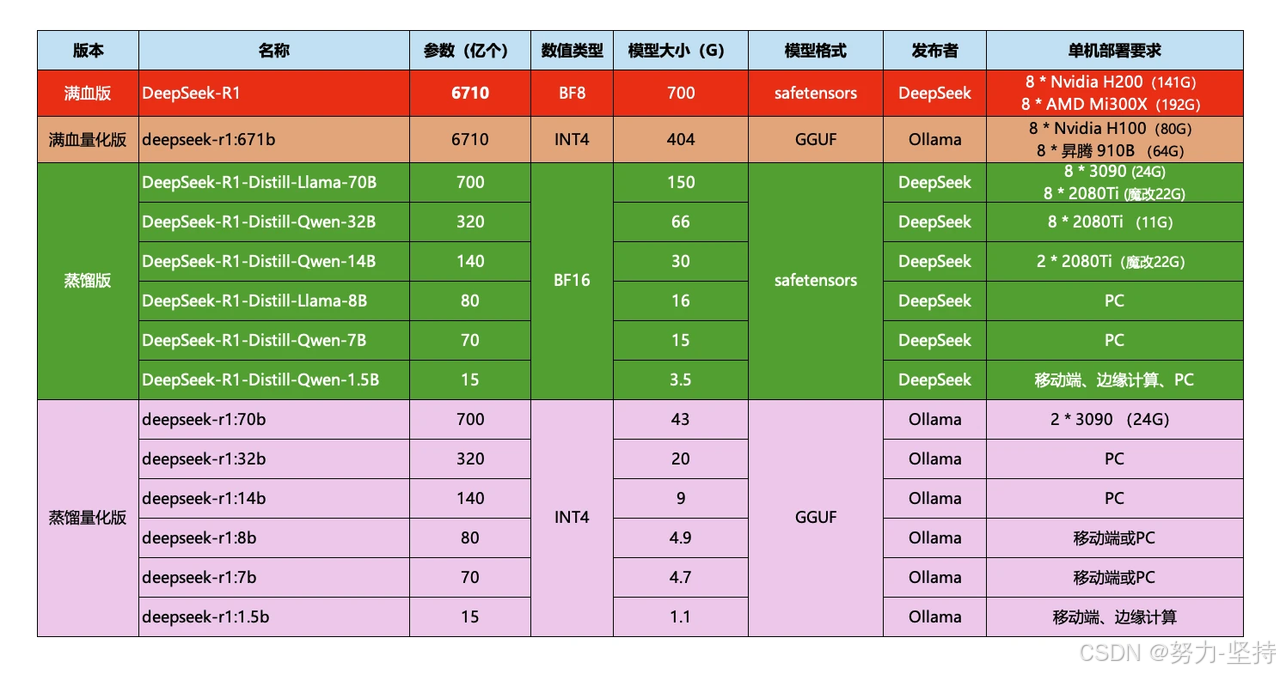
我选择部署的是7b的模型,当然8b也是可以的,都是可以流畅运行的。
2.3 运行模型
选择自己合适的模型后,ollama会给出运行模型的命令:

复制这个命令,然后打开一个cmd命令行,运行命令即可,然后你就可以跟本地模型聊天了:
注意:
- ollama控制台是一个封装好的AI对话产品,与ChatGPT类似,具备会话记忆功能。
Ollama是一个模型管理工具,有点像Docker,而且命令也很像,比如:
ollama serve # Start ollama
ollama create # Create a model from a Modelfile
ollama show # Show information for a model
ollama run # Run a model
ollama stop # Stop a running model
ollama pull # Pull a model from a registry
ollama push # Push a model to a registry
ollama list # List models
ollama ps # List running models
ollama cp # Copy a model
ollama rm # Remove a model
ollama help # Help about any command2.4 调用大模型
大模型开发并不是在浏览器中跟AI聊天。而是通过访问模型对外暴露的API接口,实现与大模型的交互 。
所以要学习大模型应用开发,就必须掌握模型的API接口规范。
目前大多数大模型都遵循OpenAI的接口规范,是基于Http协议的接口。因此请求路径、参数、返回值信息都是类似的,可能会有一些小的差别。具体需要查看大模型的官方API文档。
2.4.1大模型接口规范
我们以DeepSeek官方给出的文档为例:
Python
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
# 1.初始化OpenAI客户端,要指定两个参数:api_key、base_url
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# 2.发送http请求到大模型,参数比较多
response = client.chat.completions.create(
model="deepseek-chat", # 2.1.选择要访问的模型
messages=[ # 2.2.发送给大模型的消息
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False # 2.3.是否以流式返回结果
)
print(response.choices[0].message.content)2.4.2 接口说明
- 请求方式:通常是POST,因为要传递JSON风格的参数
- 请求路径:与平台有关
- DeepSeek官方平台:https://api.deepseek.com
- 阿里云百炼平台:https://dashscope.aliyuncs.com/compatible-mode/v1
- 本地ollama部署的模型:http://localhost:11434
- 安全校验:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
- 请求参数:参数很多,比较常见的有:
- model:要访问的模型名称
- messages:发送给大模型的消息,是一个数组
- stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
- temperature:取值范围[0:2),代表大模型生成结果的随机性,越小随机性越低。DeepSeek-R1不支持
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
- role:消息对应的角色
- content:消息内容
其中消息的内容,也被称为提示词 (Prompt ),也就是发送给大模型的指令。
2.4.3 提示词角色
通常消息的角色有三种:
| 角色 | 描述 | 示例 |
|---|---|---|
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
| user | 终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) | 写一首关于Java编程的诗 |
| assistant | 由大模型生成的消息,可能是上一轮对话生成的结果 | 注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果。 |
其中System类型的消息非常重要!影响了后续AI会话的行为模式。
比如,我们会发现,当我们询问这些AI对话产品"你是谁"这个问题的时候,每一个AI的回答都不一样,这是怎么回事呢?
这其实是因为AI对话产品并不是直接把用户的提问发送给LLM,通常都会在user提问的前面通过System消息给模型设定好背景:
所以,当你问问题时,AI就会遵循System的设定来回答了。因此,不同的大模型由于System设定不同,回答的答案也不一样。