目录
[1. Kafka 为什么偏向处理大数据量](#1. Kafka 为什么偏向处理大数据量)
[1.1 顺序追加写(Append Only)](#1.1 顺序追加写(Append Only))
[1.2 Partition 并行模型](#1.2 Partition 并行模型)
[1.3 零拷贝(Zero Copy)](#1.3 零拷贝(Zero Copy))
[1.4 批处理(Batch)](#1.4 批处理(Batch))
[1.5 高度依赖 OS PageCache](#1.5 高度依赖 OS PageCache)
[2. RocketMQ 相比 Kafka 在大数据处理上弱的原因](#2. RocketMQ 相比 Kafka 在大数据处理上弱的原因)
[2.1 多队列 + 多索引机制较重](#2.1 多队列 + 多索引机制较重)
[2.2 Kafka 的 Partition 更适合流式高吞吐](#2.2 Kafka 的 Partition 更适合流式高吞吐)
[2.3 可靠性特性更多(牺牲部分吞吐)](#2.3 可靠性特性更多(牺牲部分吞吐))
[3. 流量削峰选择 Kafka 还是 RocketMQ](#3. 流量削峰选择 Kafka 还是 RocketMQ)
[4. Kafka 如何做到只追加写入与零拷贝](#4. Kafka 如何做到只追加写入与零拷贝)
[追加写入:磁盘顺序写 + 段文件(Segment)](#追加写入:磁盘顺序写 + 段文件(Segment))
[零拷贝:sendfile → 内核直接将 PageCache 数据送到 NIC,无需用户态拷贝](#零拷贝:sendfile → 内核直接将 PageCache 数据送到 NIC,无需用户态拷贝)
[5. 用户空间 / 内核空间](#5. 用户空间 / 内核空间)
[用户空间(User Space)](#用户空间(User Space))
[内核空间(Kernel Space)](#内核空间(Kernel Space))
[6. Kafka 如何在高负载下实现扩展(对应 RocketMQ Slot)](#6. Kafka 如何在高负载下实现扩展(对应 RocketMQ Slot))
[7. RocketMQ 无序时 MessageQueue 的 offset](#7. RocketMQ 无序时 MessageQueue 的 offset)
[8. 架构图与流程图(ASCII 版本)](#8. 架构图与流程图(ASCII 版本))
[Kafka 架构(简化)](#Kafka 架构(简化))
[Kafka 零拷贝流程](#Kafka 零拷贝流程)
[RocketMQ 存储结构](#RocketMQ 存储结构)
1. Kafka 为什么偏向处理大数据量
Kafka 在大数据处理场景中表现突出主要因为:
1.1 顺序追加写(Append Only)
磁盘顺序写 + PageCache 命中率高。
1.2 Partition 并行模型
Topic → 多 Partition → 多副本 → 多 Broker 分散压力。
1.3 零拷贝(Zero Copy)
通过 sendfile 实现用户空间零拷贝,大幅降低 CPU 消耗。
1.4 批处理(Batch)
批量生产/消费减少系统调用次数。
1.5 高度依赖 OS PageCache
Kafka 不维护复杂索引,全部交给 OS 管理,性能极高。
2. RocketMQ 相比 Kafka 在大数据处理上弱的原因
虽然 RocketMQ 功能全面、支持更多业务特性,但其架构更偏业务语义、非纯吞吐设计:
2.1 多队列 + 多索引机制较重
RocketMQ 存储结构:
-
CommitLog(物理)
-
ConsumeQueue(逻辑)
-
IndexFile(倒排索引)
这比 Kafka 的简洁 Partition 更复杂。
2.2 Kafka 的 Partition 更适合流式高吞吐
RocketMQ 的 MessageQueue 本质仍是可扩展的业务队列,不是为极端吞吐设计。
2.3 可靠性特性更多(牺牲部分吞吐)
延迟消息、事务消息、死信等功能都会增加 IO 与 CPU 开销。
3. 流量削峰选择 Kafka 还是 RocketMQ
如果纯削峰、高吞吐:Kafka 更优。
如果削峰 + 强业务语义(事务/延迟/回查):RocketMQ 更优。
4. Kafka 如何做到只追加写入与零拷贝
追加写入:磁盘顺序写 + 段文件(Segment)
零拷贝:sendfile → 内核直接将 PageCache 数据送到 NIC,无需用户态拷贝
路径:
PageCache → Kernel Buffer → NIC
用户空间完全不参与 → CPU 基本不消耗
5. 用户空间 / 内核空间
用户空间(User Space)
普通应用程序运行的区域,无权限直接操作硬件。
内核空间(Kernel Space)
操作系统运行区域,负责 CPU、内存、磁盘、网络。
Kafka 零拷贝核心点:数据不从内核拷贝回用户态。
6. Kafka 如何在高负载下实现扩展(对应 RocketMQ Slot)
RocketMQ:Slot + 队列动态路由。
Kafka:Partition + Leader/Follower + Rebalance。
| RocketMQ | Kafka |
|---|---|
| Slot(路由表) | Partition 分片 |
| MQ 分配给消费者 | Partition 分配给消费者 |
| 多级索引 | 单一日志结构 |
Kafka 更适合大吞吐,因为分布式扩展模型更轻量。
7. RocketMQ 无序时 MessageQueue 的 offset
RocketMQ 每个 MessageQueue 都有自己的 offset:
Queue0 → offset0
Queue1 → offset0
Queue2 → offset0
消息是分散写入多个队列,各自独立递增 offset。
RocketMQ 没有像 Kafka 一样的 Partition 固定顺序,因此本质是无序队列结构。
8. 架构图与流程图(ASCII 版本)
Kafka 架构
简化:
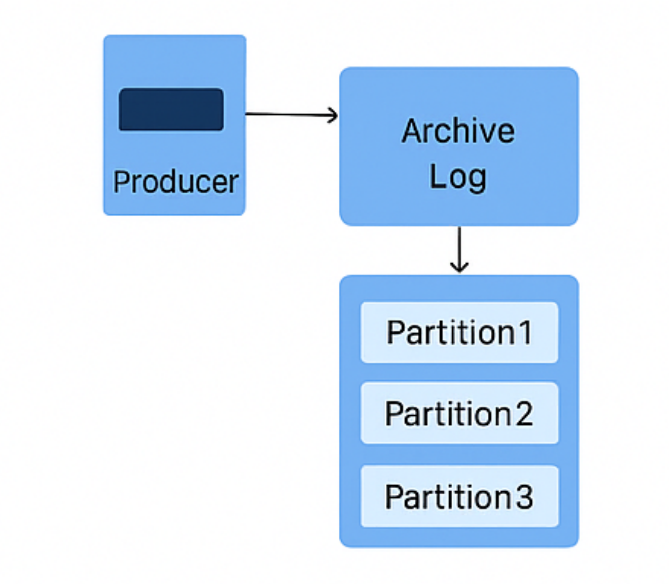
细化(网图):
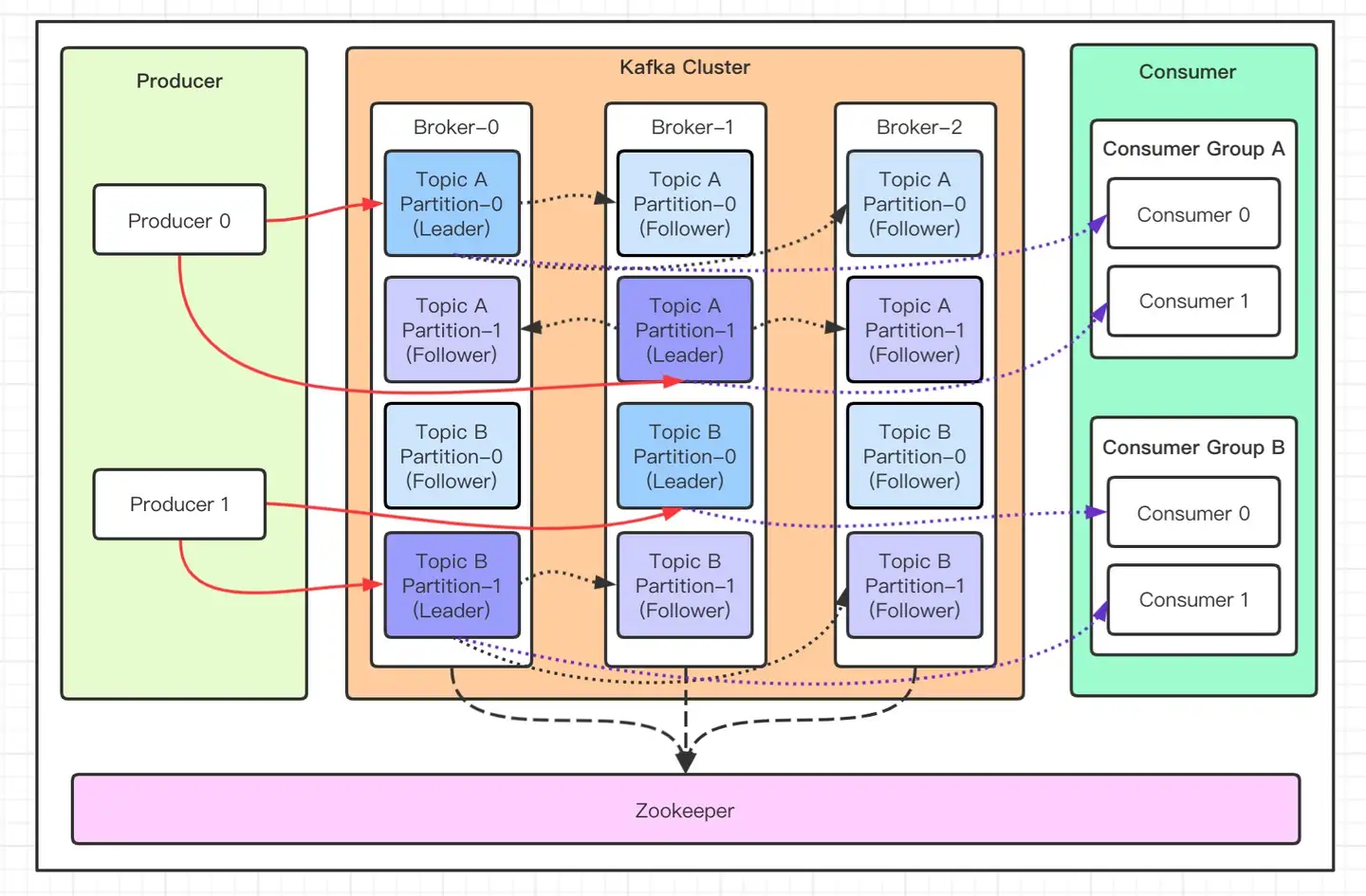
Producer → Partition0(Log) → BrokerA
→ Partition1(Log) → BrokerB
→ Partition2(Log) → BrokerC
Kafka 零拷贝流程
File(页缓存) → Kernel buffer → NIC
RocketMQ 存储结构
简化:
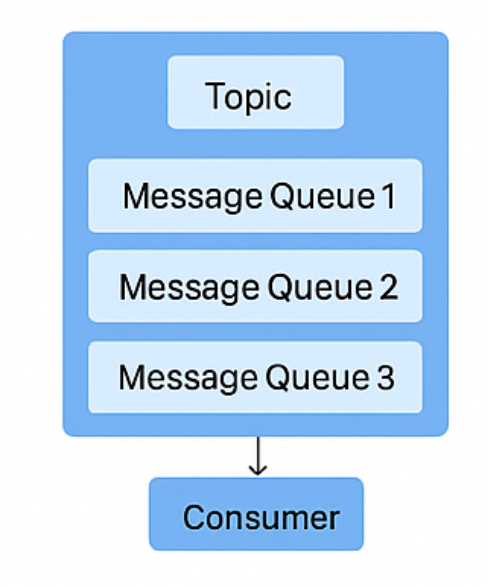
细化(网图):
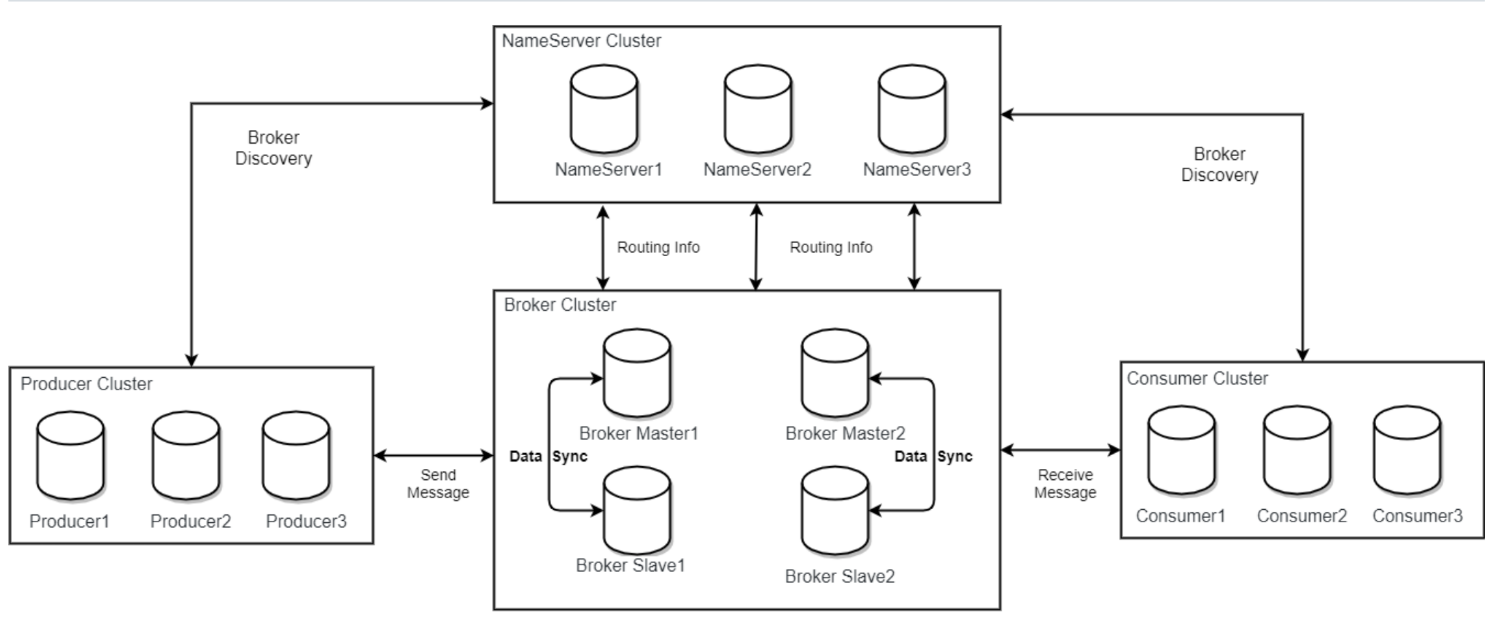
CommitLog ← 所有消息顺序写
ConsumeQueue ← 指向 CommitLog 的逻辑索引
IndexFile ← Key 索引(可选)