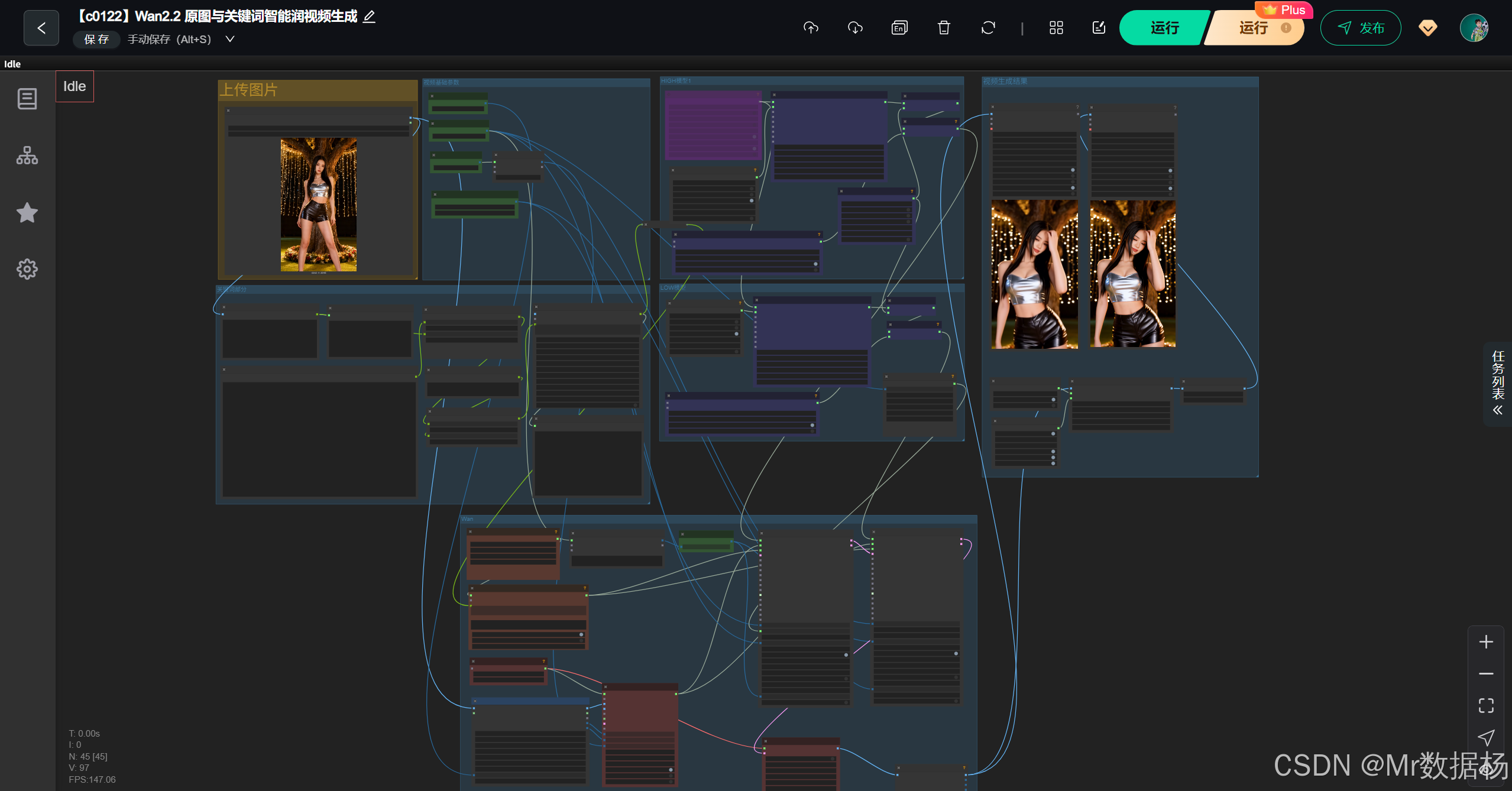
这次为大家演示的,是一个基于 Wan2.2 的原图与关键词智能润色视频生成工作流。它通过对输入图像进行特征抽取、尺寸适配与编码,再结合自动生成的中文描述和翻译后的英文关键词,让模型以更贴近原图风格的方式完成从图到视频的生成。整个流程会自动处理文本、图像结构、LoRA 风格融合、模型加载、采样与解码,因此即使面对复杂的画面也能生成连贯、轻盈且带有真实光影的动态视频。
文章目录
- 工作流介绍
-
- 核心模型
- [Node 节点](#Node 节点)
- 工作流程
- 大模型应用
-
- [RH_Captioner 原图语义抽取器](#RH_Captioner 原图语义抽取器)
- [RH_Translator 关键词润色翻译器](#RH_Translator 关键词润色翻译器)
- [WanVideoTextEncode 文本语义嵌入编码器](#WanVideoTextEncode 文本语义嵌入编码器)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
这个工作流围绕 Wan2.2 系列 I2V 模型构建,通过多级文本处理、图像编码、LoRA 调整与双模型采样组合,让原图的主体特征保持稳定,同时根据关键词润色细化画面动作与风格。核心模型负责视频生成的结构基础,LoRA 进一步塑造视觉风格,而节点系统则串联起从输入、分析、编码、推理到最终解码的完整链路。所有节点相互配合,使工作流在稳定、速度和画面细节之间取得了平衡。
核心模型
核心模型采用 Wan2.2 系列的高低精度 I2V 版本,包括 Wan2_2-I2V-A14B-HIGH_fp8... 和 Wan2_2-I2V-A14B-LOW_fp8... 两套模型,用于构建双采样路径。高精度模型负责画面细节与动态一致性,低精度模型负责生成速度提升与资源占用优化。加载流程还结合 VAE 组件与 T5 文本编码器,让画面结构、颜色、动作的解析都能更贴近输入图像的真实特征。
| 模型名称 | 说明 |
|---|---|
| Wan2_2-I2V-A14B-HIGH_fp8 模型 | 主生成模型,负责细节塑形与动态生成 |
| Wan2_2-I2V-A14B-LOW_fp8 模型 | 辅助生成模型,兼顾速度、节省显存 |
| Wan2.1 系列 VAE | 用于将 latent 解码成最终视频帧,保证画面通透度 |
| umt5-xxl 文本编码器 | 将中文与英文关键词编码成风格、动作等语义特征 |
Node 节点
节点系统是整个流程的骨架。Captioner 会先从原图提取细节描述,再由 Translator 将描述转成英文强语义提示。ImageScaleByAspectRatio 负责处理图像比例,维持一致的画面结构。WanVideoLoraSelect 则在模型推理阶段融合风格 LoRA。随后多个 BlockSwap、CompileSettings、ModelLoader 共同完成模型构建。采样部分由双 WanVideoSampler 同时参与,最后通过 VAE 解码与 GetImageSizeAndCount 输出视频帧,让画面自然流畅。
| 节点名称 | 说明 |
|---|---|
| RH_Captioner | 自动从输入图像提取详细中文描述 |
| RH_Translator | 将描述翻译并整理为英文提示词 |
| ImageScaleByAspectRatio | 调整原图尺寸与比例以适配视频生成 |
| WanVideoModelLoader | 加载 Wan2.2 I2V 视频模型 |
| WanVideoLoraSelect | 选择并融合风格 LoRA |
| WanVideoSampler | 执行视频的扩散生成过程 |
| WanVideoDecode | 将 latent 解码为视频帧 |
| GetImageSizeAndCount | 输出最终帧图像尺寸与数量 |
工作流程
整个工作流程围绕"图像理解 → 文本生成 → 图像编码 → 视频扩散 → 最终解码"展开。前段以 Captioner 和 Translator 生成精准语义提示,让模型理解画面主体和动作需求。中段由模型加载、尺寸处理与 latent 初始化奠定生成结构,再结合 LoRA、采样器和双模型路径,让视频动作既贴近原图又具备柔和的动态延展。最后由 VAE 解码并输出完整帧序列,使画面在色彩、清晰度和动感上保持一致。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 原图解析 | 自动提取人物外观、场景细节,生成中文描述 | RH_Captioner |
| 2 | 关键词润色 | 将中文描述翻译成更适合模型的英文提示词 | RH_Translator |
| 3 | 图像适配 | 调整分辨率与比例,为视频生成建立统一结构 | ImageScaleByAspectRatio |
| 4 | 模型构建 | 加载 Wan2.2 高低精度模型与相关参数 | WanVideoTorchCompileSettings、WanVideoModelLoader |
| 5 | 风格融合 | 合并 LoRA 以增强动作风格或视觉特征 | WanVideoLoraSelect、WanVideoSetLoRAs |
| 6 | 嵌入生成 | 将图像与文本转换为生成所需 latent 信息 | WanVideoImageToVideoEncode、WanVideoTextEncode |
| 7 | 扩散生成 | 双路径采样生成平滑连贯的视频动态 | WanVideoSampler |
| 8 | 结果解码 | 将 latent 解码成最终的视频帧序列 | WanVideoDecode |
| 9 | 输出整理 | 读取分辨率与帧数,完成最终输出 | GetImageSizeAndCount |
大模型应用
RH_Captioner 原图语义抽取器
RH_Captioner 专门负责理解输入图像的内容,并依照给定 Prompt 生成结构化的中文描述。它的任务是将视觉信息转换成可被后续模型使用的语义文本,因此 Prompt 在这里决定描述的范围、细节密度与语言风格。例如本工作流中要求描述外貌、姿态、服装和环境等细项,模型会严格遵循 Prompt 的指令输出内容,用于后续的英文润色与视频生成提示词构建。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| RH_Captioner | 请提供此图像的详细说明。 包括人物的外貌特征,身材,服装,场景等等。 描述应尽可能详细,但不应超过200字。 | 依据 Prompt 指令,从图像中提取可用于视频生成的结构化中文描述,确保视觉信息被完整转为文本语义。 |
RH_Translator 关键词润色翻译器
RH_Translator 负责将 Captioner 产出的中文描述转换成英文提示词,并依据 Prompt 指令进行语义强化。Prompt 在此节点的作用是控制翻译风格,例如更具动作感、更具场景描述性,或更倾向模型可识别的表达方式。本工作流中其任务是把中文描述整理成 AI 视频生成模型最易理解的 positive prompt,从而控制画面质感、节奏与动作表达。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| RH_Translator | (节点本身 Prompt 为空,由输入文本触发翻译) | 将输入的中文描述翻译并润色为模型更易解析的英文提示词,强化动作、场景和风格语义。 |
WanVideoTextEncode 文本语义嵌入编码器
WanVideoTextEncode 的角色是把最终英文 prompt 编码成视频生成模型可直接理解的语义向量。这里 Prompt 信息对应用户输入的 positive_prompt,在文件中示例为「女人拿着相机拍照」。Prompt 在这个节点的影响最直接,决定了模型生成视频时的内容倾向、动作表现与风格尺度。越明确的 Prompt 越能让模型生成更一致、更贴近目标的视频内容。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| WanVideoTextEncode | 女人拿着相机拍照 色调艳丽,过曝,静态,细节模糊不... | 将最终英文 Prompt 转为语义向量,直接影响模型生成的视频内容、风格与动作信息。 |
使用方法
整个工作流的运行逻辑围绕"图像输入 → 中文描述生成 → 英文提示词润色 → 文本编码 → 视频生成"展开。用户只需要替换角色图,Captioner 会自动解析图像特征;关键词部分由 Translator 输出适合视频生成模型理解的 Prompt;如果用户还添加了自定义 Prompt 或负向 Prompt,也会被合并进入最终的文本编码节点中。动作图、音频等无需额外处理,核心驱动完全依赖 Prompt 和图像语义,模型会自动完成尺寸适配、latent 生成、采样、解码,最终输出连贯的视频结果。
| 注意点 | 说明 |
|---|---|
| Prompt 越明确效果越好 | 描述姿态、动作、节奏、光线有助于提高视频一致性 |
| 原图需清晰 | 清晰的主体与场景能让 Captioner 输出更准确的描述 |
| 避免冲突描述 | Prompt 中出现矛盾信息会导致动态不稳定 |
| 英文提示优先级更高 | 翻译后的英文 prompt 在视频生成中最为关键 |
| 建议保持单人主体 | 多人物结构可能降低模型的动作稳定性 |
| LoRA 与 Prompt 需协调 | 风格类 LoRA 会强化视觉特征,与 Prompt 内容需对应 |
应用场景
这个工作流适用于所有希望让单张图像自然地延展为短视频的创作需求。它的自动描述、关键词润色与双模型采样能在保持主体辨识度的前提下,让画面获得更细腻的动作变化。无论是做人物动效、美妆展示、剧情片段、静态摄影延展,还是对画面做风格加强,这个工作流都能形成从图到动的连续内容。其结构完整、节点健全,对新手友好,对创作者而言也能作为视频生成的高质量起点。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 人物写真延展 | 让单张写真转为轻盈动态 | 摄影师、自媒体创作者 | 人物特写、身姿、眼神动态 | 自然动作、光影连贯、同脸一致 |
| 商业短视频生成 | 以原图为基础生成产品动效 | 品牌方、电商、广告创作者 | 产品展示、场景氛围 | 保持产品结构清晰,加入空间动感 |
| 原画到动效 | 让插画、立绘具备动画质感 | 二创作者、游戏美术 | 角色立绘、场景原画 | 微动、视差、飘动特效 |
| 截图动效化 | 将影视或截图转为流畅短动效 | 混剪作者、剧情向账号 | 截图、人物镜头 | 连续动作过渡自然,不突兀 |
| 情绪氛围视频 | 基于关键词润色生成情绪化镜头 | 视频创作者、剪辑师 | 情绪、光影、节奏画面 | 更统一的色调与环境动态 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用