流式分布式计算框架
文章目录
-
- [1. 理论](#1. 理论)
-
- [1.1. flink on yarn 的工作原理](#1.1. flink on yarn 的工作原理)
- [1.2. 计算所需slot的数量](#1.2. 计算所需slot的数量)
- [1.3. 计算指定并行度所需的yarn内存](#1.3. 计算指定并行度所需的yarn内存)
- [1.4. kafka的分区数量要等于source算子的并行度](#1.4. kafka的分区数量要等于source算子的并行度)
- [1.5. 背压 backpressure](#1.5. 背压 backpressure)
- [1.6. 不同算子的子任务共享同一个slot](#1.6. 不同算子的子任务共享同一个slot)
- [2. 参数配置](#2. 参数配置)
-
- [2.1. 内存配置](#2.1. 内存配置)
1. 理论
1.1. flink on yarn 的工作原理
Flink 在 YARN 上的运行原理,本质上是把 Flink 自身的分布式组件(JobManager、TaskManager)作为普通 YARN 应用程序来启动,由 YARN 统一分配容器、监控生命周期的过程。整个流程可以拆成 6 个阶段,下面按时间顺序说明,并给出两种部署形态(Per-Job / Session)的差异点。
- 客户端准备阶段
- 用户执行
flink run -m yarn-cluster ...或yarn-session.sh - 客户端把 Flink 运行所需的 jar、conf、用户代码上传到 HDFS 指定目录,生成一份"资源清单"供后续 NodeManager 拉取 。
- YARN 申请第一个 Container
- 客户端向 YARN ResourceManager 提交 Application 上下文;
- RM 找一个空闲 NodeManager,启动 Flink ApplicationMaster(AM)容器 。
- AM 启动 Flink JobManager
- AM 内部会拉起 JobManager 进程(同一 Container 内);
- AM 把 JobManager 地址、RPC 端口等信息写回 HDFS,供后续 TaskManager 读取 。
- AM 二次向 RM 申请资源池
- 根据用户指定的并行度、slot 数、TM 内存等参数,AM 继续向 RM 要一批 Container;
- RM 把请求放入调度队列,按容量/公平策略返回可用的 Container 列表 。
- NodeManager 启动 TaskManager
- 各 NodeManager 拉取 HDFS 上的 Flink 依赖包,在得到的 Container 内启动 TaskManager;
- TaskManager 启动后向 JobManager 注册,并周期性心跳汇报 slot 存活情况 。
- 作业执行与容错
- JobManager 把 JobGraph 展开成 ExecutionGraph,按 slot 粒度调度任务;
- 如果某个 TM 容器挂掉,JobManager 通过 AM 重新向 RM 申请同等规格的 Container,实现"自修复" ;
- 作业结束后,AM 通知 RM 注销应用,所有 Container 被 YARN 回收,集群资源立即释放。
Per-Job 与 Session 模式对比
| 维度 | Per-Job 模式 | Session 模式 |
|---|---|---|
| 生命周期 | 一个作业对应一个 YARN 应用,作业退出即释放全部资源 | 先启动一个长驻的 Flink 集群(共享 JobManager & 固定 TM 池),可多次提交作业 |
| 资源隔离 | 作业间完全隔离,故障互不干扰 | 多作业共享 TM,可能出现资源竞争或单点故障蔓延 |
| 启动延迟 | 需要秒~分钟级新建 JobManager/TM,适合长周期流任务或批任务 | 作业直接复用已有 slot,秒级提交,适合短周期、交互式开发 |
| 适用场景 | 生产环境大型流/批作业,对隔离性要求高 | 开发、测试、低优先级小作业,需要快速迭代 |
一句话总结
Flink on YARN 就是把"Flink 集群"当成普通 YARN 应用来跑:先由 YARN 给 Flink 的 ApplicationMaster 容器,再由 AM 按需申请 TaskManager 容器,最终形成 Flink 运行时;用户根据隔离性与响应速度的需求,选择为每个作业单独建集群(Per-Job)还是让多个作业共享一个长驻集群(Session)。
1.2. 计算所需slot的数量
一般情况下slot数量等于最大并行度
1.3. 计算指定并行度所需的yarn内存
已知:
taskmanager进程内存30g- 每个
taskmanager有4个slot
当并行度 = 100 时 =》 所需 slot = 100 =》 所需taskmanager = ceil(100 / 4) = 25 =》 所需 yarn内存 = 25 * 30 = 750g
1.4. kafka的分区数量要等于source算子的并行度
这样source算子的每个subTask才能对应一个kafka分区。
严禁source算子的并行度大于kafka的分区数,因为这样会有source的subTask分不到分区,这些subTask从而就没有数据进入,导致slot和线程的浪费。
当source算子的并行度小于kafka的分区数时,会有subTask分到多个分区,这样是没问题的。
kafka增加分区数量: kafka-topics.sh --bootstrap-server broker1:9092 --alter --topic order_topic --partitions 100
kafka分区数量调整后需要重启flink作业,生产者方面不需要重启
1.5. 背压 backpressure
webui中算子上的backpressure 表示当前算子由于下游阻塞而等待的时间占比。
backpressure的原理:source -> map -> sink, 当sink由于写入外部系统而阻塞,导致其outputBuffer逐渐被填满,进而导致inputBuffer被填满,此时,上游的map由于无法输出,其outputBuffer也逐渐被填满,进而导致inputBuffer被填满,就这样压力一直传导到source,最终source暂停消费kafka。
backpressure的统计方式类似linux上cpu负载的统计方式,是统计几秒内的背压时间占总时间的平均占比。如:在5s内采样了1000次,其中空闲600次,busy300次,backpressure100次,于是
backpressure/idle/busy = 60%/30%/10%另外需要注意: webui算子上的
backpressure和busy其实是所有subTask中最大的取值,两个值可能分别来自不同的subTask,因此busy = 100%可能只有一个subTask是100%,其他subTask都是空闲的。
1.6. 不同算子的子任务共享同一个slot
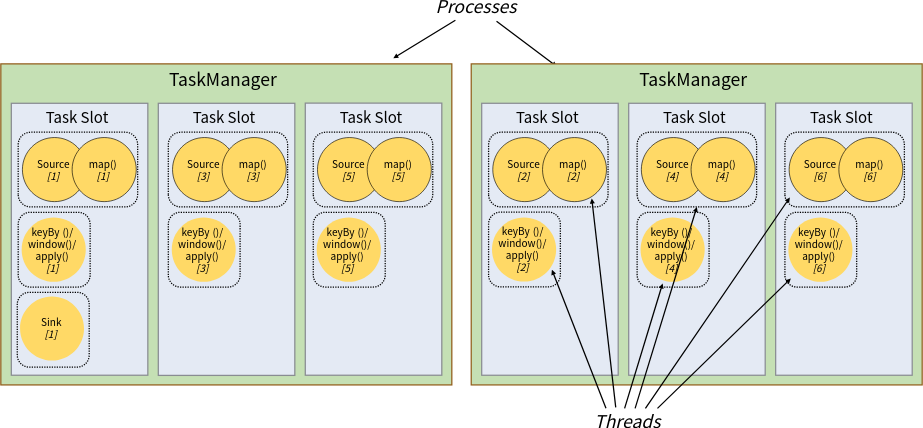
上图表示如下作业,作业的并行度为6:
source -> map -> keyBy()/window()/apply() -> sink
可以看到不同算子组成的整个管道可以共享同一个slot。由于并行度为6,所以整个作业有6条管道,每个管道使用一个slot,共6个slot。
虽然不同算子的subtask可以共享slot,但是每个subtask还是在自己单独的线程中运行。比较特殊的情况是source和map两算子组成的算子链是在一个线程中运行的。
一个taskmanager中可以有多个slot,每个slot均分managed内存(非堆),堆内存不会均分,而是被所有任务共享。
2. 参数配置
2.1. 内存配置
yaml
taskmanager.memory.process.size: 32g # 进程总内存,基于yarn时是向yarn申请容器的内存
taskmanager.numberOfTaskSlots: 4 # 每个taskmanager的slot数量
env.java.opts.taskmanager: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/heapdump -XX:+UseG1GC