文章目录
- 摘要
- Abstract
- [一、Huggingface 访问问题的解决记录](#一、Huggingface 访问问题的解决记录)
-
- [1. 报错信息](#1. 报错信息)
-
- [1.1 分析错误原因](#1.1 分析错误原因)
- [2. 解决方案](#2. 解决方案)
- 二、大模型学习
-
- [1. 模型量化:模型轻量化第三种方法](#1. 模型量化:模型轻量化第三种方法)
- [2. 信息检索](#2. 信息检索)
-
- [2.1 定义和测评:](#2.1 定义和测评:)
-
- [2.1.1 评测的指标](#2.1.1 评测的指标)
- [2.2 传统信息检索方法](#2.2 传统信息检索方法)
- [2.3 神经网络信息检索方法:](#2.3 神经网络信息检索方法:)
-
- [2.3.1 Cross-Encoder(交叉编码器)](#2.3.1 Cross-Encoder(交叉编码器))
- [2.3.2 Dual-Encoder(双编码器)](#2.3.2 Dual-Encoder(双编码器))
- [2.3.3 对比两种架构:](#2.3.3 对比两种架构:)
- 总结
摘要
本周理论方面主要学习模型轻量化的第三种方法:模型量化,该方法是将高精度数据转会为低精度数据从而实现模型的压缩。还学习了自然语言处理任务分类,了解到自然语言处理任务可以分为三类任务:理解,生成,问答。主要对理解任务具体应用:信息检索进行学习。学习了信息检索的定义,评估方法、传统信息检索方法以及神经网络信息检索方法,同时了解到传统信息检索方法存在的缺陷。
Abstract
This week, in terms of theoretical learning, I mainly studied the third method of model lightweighting: model quantization. This method converts high-precision data into low-precision data to achieve model compression. Additionally, I learned about the classification of Natural Language Processing (NLP) tasks and understood that NLP tasks can be divided into three categories: understanding tasks, generation tasks, and question answering (QA) tasks. I focused on the specific application of understanding tasks---information retrieval (IR). I studied the definition, evaluation methods, traditional information retrieval approaches, and neural network-based information retrieval methods of IR, while also gaining insights into the limitations of traditional information retrieval methods.
一、Huggingface 访问问题的解决记录
1. 报错信息
【MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /datasets/super_glue/resolve/main/README.md (Caused by ProxyError('Unable to connect to proxy', NewConnectionError('<urllib3.connection.HTTPSConnection obj】
【raise ProxyError(e, request=request) requests.exceptions.ProxyError: (MaxRetryError("HTTPSConnectionPool(host='hf-mirror.com', port=443): Max retries exceeded with url: /t5-base/resolve/main/config.json (Caused by ProxyError('Unable to connect to proxy', NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x0000020D0ED70550>: Failed to establish a new connection: WinError 10061 由于目标计算机积极拒绝,无法连接。')))"), '(Request ID: f7c5def7-c288-4464-b695-7f21ffc7a4d4)')】
1.1 分析错误原因
出错原因:连不上hugging face官网,是代理即网络出了问题。
【虽然配置了 hf-mirror.com 国内镜像,但网络中仍存在隐性代理,代理试图拦截访问 hf-mirror.com 的请求,却因代理本身不可用(或被拒绝)导致连接失败。】
补充:代理概念

2. 解决方案
第一步:彻底清除所有隐性代理(关键中的关键!)
1,清除系统级代理(再次确认):

注意:原本网络中的代理是关闭的,但是防火墙一直打开,但是将所有防火墙关闭后程序访问没有问题,因此考虑是防火墙的问题。
2,清除浏览器代理(避免影响 Python 网络请求):

3,清除第三方软件代理残留:

4,终端强制清除代理(覆盖所有场景):
打开 新的 CMD 终端(必须新打开,避免旧缓存),执行以下命令:
输出指令如下:
powershell
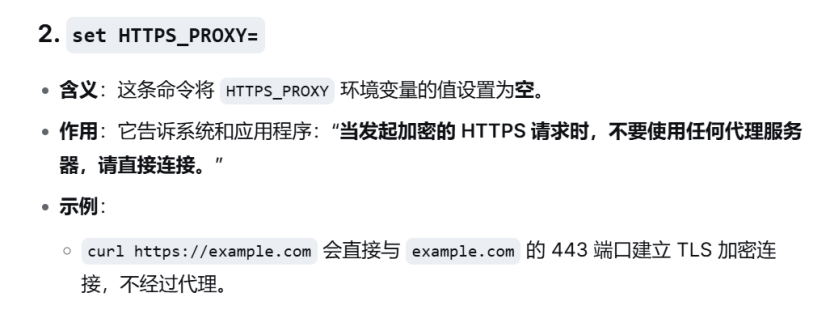
# 清除 HTTP/HTTPS 代理
set HTTP_PROXY=
set HTTPS_PROXY=
set ALL_PROXY=
# 清除 HF 相关代理(若有)
set HF_PROXY=
# 验证:输出为空则成功
echo %HTTP_PROXY%
echo %HTTPS_PROXY%补充相关知识:
1,清楚代理指令说明:


二、大模型学习
1. 模型量化:模型轻量化第三种方法
核心思想:将模型中通常使用的高精度浮点数(如32位浮点数,float32)转换为低精度整数(如8位整数,int8)来表示和计算。
量化的作用:
(1)减少数据的存储空间。由于数据大小减小,因此花费的存储空间也减少。
(2)加快计算速度
量化的基本原理:

其中round为四舍五入函数
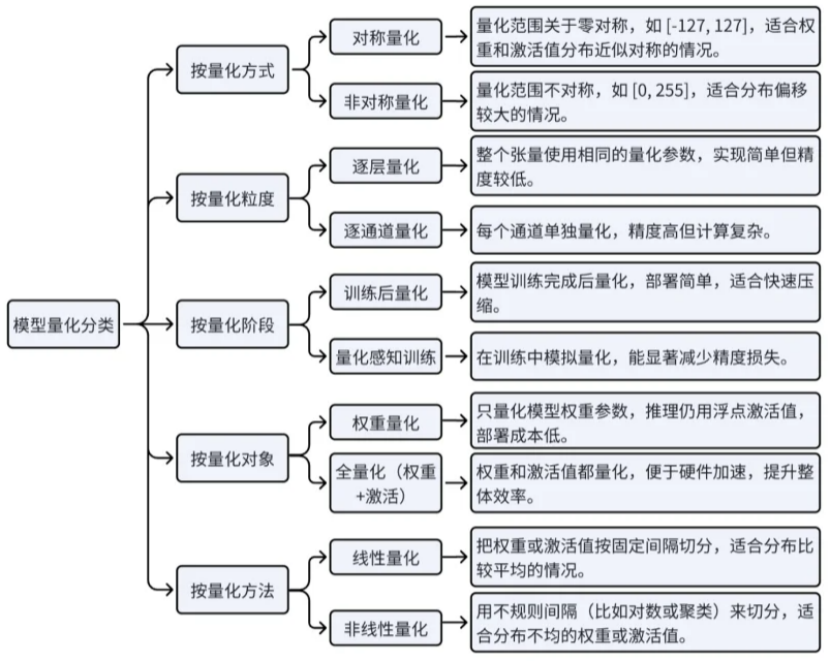
模型量化的分类:
2. 信息检索
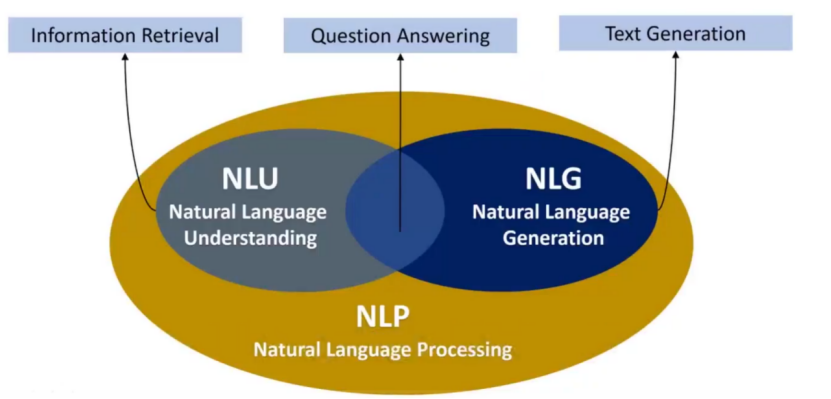
自然语言处理任务分类:
自然语言的理解任务(NLU):理解文本内容,信息检索
自然语言的生成任务(NLG):写文
机器问答:综合自然语言的理解任务和自然语言的生成任务。
2.1 定义和测评:
定义:
1,给定一个query:可以是查询关键词,可以是问题
2,给定文档库doucments:
3,信息检索系统会根据q,d对产生相关性分数根据分数对文档库的文档进行排序。
其中q为query,用户输入的查询词;d为document,文档库中存储的每一个待匹配单元。"q,d 对":即 "一个查询 + 一个文档" 的组合,系统会计算该组合的相关性分数。
测评只需要测评返回的前K个信息与query的相关性:
2.1.1 评测的指标
1,MRR平均倒数排名 (Mean Reciprocal Rank)
查询集Q的第一个相关结果的倒数排名的平均
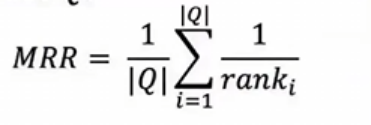
具体举例:

2,MAP平均精确度 (Mean Average Precision)
对一组query求平均精确分数,考虑所有相关文档:
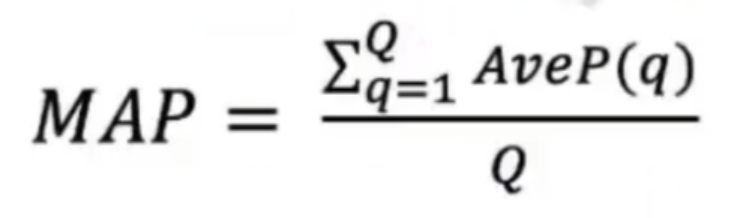
其中Q为query的数量
具体例子:
给定两个query,第一个query有4个相关文档,且每个文档都成功召回。第二个query有5个相关文档,其中只有3个成功召回。
最后对两个query的平均精度再求平均值。

数据说明:平均精确度的计算是对相应文本排列序号取倒数再乘文本位置,例如query1中,第四个相关文本,排在第七位,因此为4/7。
3,NDCG归一化的累积折损增益 (Normalized discounted cumulative gain)
将文档设置为不同相关等级,等级越高,相关程度越高。NDCG计算方式

参数说明:
DCG为:黄金标准相关文件的价值。
IDCG 是当前查询能达到的 "理论最高 DCG"。
i为文档所在位置,rel为文档等级。
具体例子:

2.2 传统信息检索方法
BM25
给定一个query={w1,w2...wn}和一个文档集合D={ ...,di,...}
BM25计算相关q,d对分数公式如下:
参数说明:
1,K,b为分数公式的超参数,|di|是di每篇文章的长度,avgdl为整个文档库中文档的平均文档长度。
2,TF(Term Frequency)词频,是query中每个词在文档中出现的频率,如果文档中词的匹配率越高,可以认为文档与查询的相关程度更高。
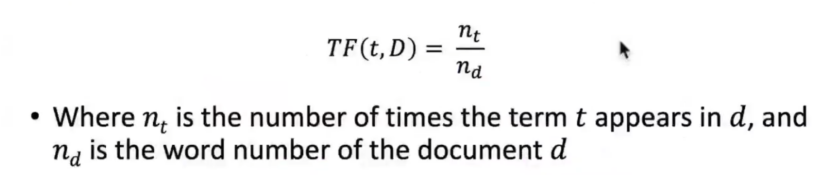
3,IDF(Inverse Document Frequency)逆文档频率,表示一个词汇在所有文档中常见或者稀有程度,如果一个词在所有文档中都很常见,IDF可能会很低,IDF如果较高说明该词包含的信息量大。

BM25存在的问题:
1,词汇失配。无法进行同义词的查询,下面例子中,car=vehicle,但是文章2就无法匹配,因为只能进行同一个词汇的匹配。
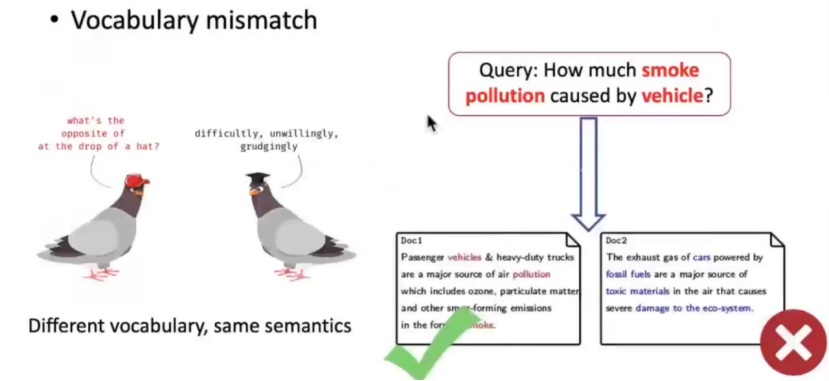
2,语义失配。文档和词汇存在很高的词汇匹配率,但是两者间含义完全不同。

2.3 神经网络信息检索方法:
存在两种架构:
2.3.1 Cross-Encoder(交叉编码器)
任务:给 "查询 q(比如'Transformer 混合精度训练')" 和 "文档 d(比如一篇讲 FP16/FP32 转换的文章)" 打一个 "相关性分数"(0~1 之间,分数越高越匹配)。
模型好处是比较精细,检索性能好,缺点是代价大
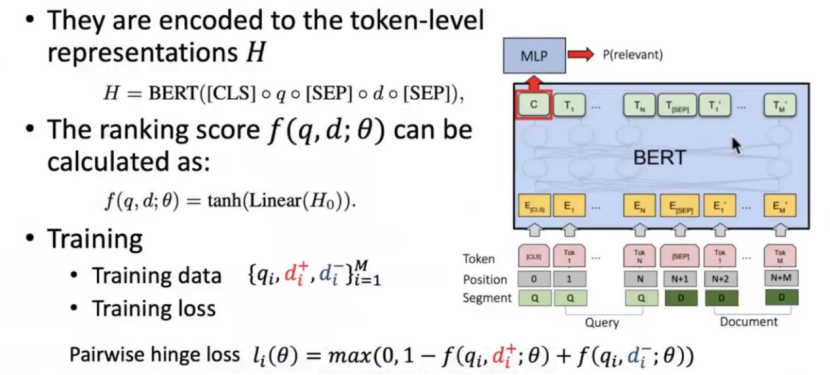
过程说明:
1,会将q,d进行拼接,再一起进入大模型
参数说明:
CLS:"分类标记",相当于这 "一句话" 的 "总结句符号",后面会用它的输出做最终判断;
SEP:"分隔标记",相当于 "逗号 + 句号",明确划分 q 和 d 的边界(告诉模型 "前面是查询,后面是文档")。
2,拼接完成后的sequence会经过一个多层transformer
每一层都在做 "q 和 d 的 token 级交互"
3,将最后一层的CLS token作为q,d的共同表示
经过多层 Transformer 编码后,序列中每个 token 都会输出一个 "高维向量"(比如 768 维),代表这个 token 在 "q+d" 语境下的语义特征。
疑问:为什么选 CLS token?
- CLS是序列的第一个 token,在训练时就被设计成 "整个序列的全局表示"------ 它的向量会融合 q 和 d 所有 token 的互动信息,相当于把 "q 和 d 的关联性" 浓缩成了一个 768 维的 "总结向量";
- 其他 token 的向量只代表单个词的局部特征,而 CLS token 的向量是 "全局关联特征",最适合用来判断整体相关性。
4,经过nlp投射,变成标量分数
CLS token 的 768 维向量是高维数据,无法直接作为 "分数" 使用,这一步要做 "降维 + 映射",具体操作:
- 先通过一个 "全连接层(线性层)":把 768 维向量降维到 1 维(比如从 "0.2, 0.5, ..., 0.8" 变成 "1.23");
- 再通过一个激活函数(比如 Sigmoid):把 1 维数值映射到 0~1 之间的标量分数(比如 1.23→0.85);
- 最终输出:0.85 这个分数,就代表 q 和 d 的相关性(0.85 属于高相关,会排在前面)。
训练的时候:每一个query配备一个相关文档与至少一篇不相关文档
2.3.2 Dual-Encoder(双编码器)
任务:给 q 和 d 打相关性分数,但额外要求:支持百万 / 亿级文档库的快速检索。对query和document分别进行编码,形成两个独立向量,计算向量间的相似性
核心优势:q 和 d "分头做事",文档向量可提前预存
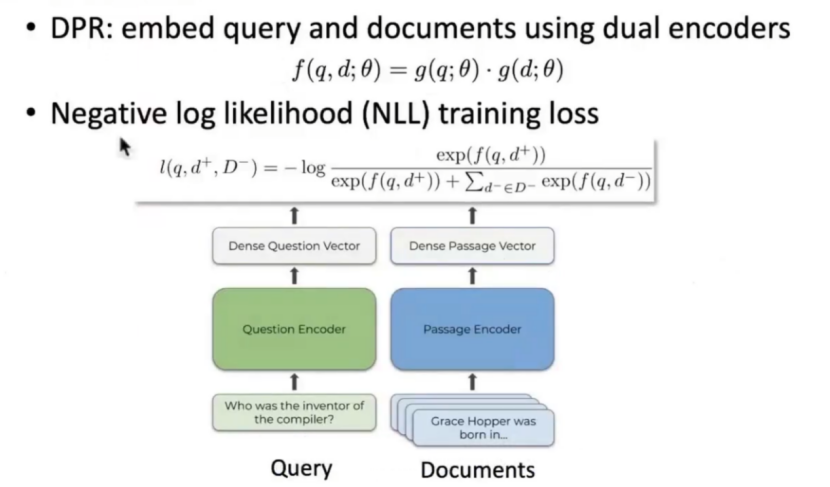
过程说明:
1,离线预计算
过程简述:所有文档d → 单独预处理(加CLS和SEP) → 共享编码器编码 → 提取d的CLS向量(vec_d) → 存入向量数据库
这一步在 "用户查询之前" 完成,只做一次(文档更新时再增量更新),核心是给每个文档 d 生成 "语义向量标签"。
(1)文档预处理:每个文档 d 单独处理,不需要和 q 拼接,仅在开头加CLS(后续用它的向量代表文档)
格式为:CLS + d + SEP
对应例子:CLS 混 合 精 度 训 练 通 过 FP16 运 算 提 速 , FP32 保 存 参 数 保 证 精 度 SEP
(2)文档编码器编码:把预处理后的 d 输入 "文档编码器"(本质是 Transformer 编码器),经过多层自注意力编码后,提取最后一层的CLS向量 ------ 这就是文档 d 的 "语义向量"(比如 768 维,记为vec_d)。
关键 :所有文档共享同一个 "文档编码器",编码过程相互独立,可批量并行处理(比如一次处理 1000 个文档)。
(3)向量入库:把所有文档的vec_d(100 万个 768 维向量)存储到专门的 "向量数据库"(如 FAISS、Milvus)
向量数据库的作用是 "快速查找相似向量",支持毫秒级匹配百万级向量。
2,在线检索
过程简述:用户查询q → 单独预处理(加CLS和SEP) → 同一共享编码器编码 → 提取q的CLS向量(vec_q) → 向量数据库计算vec_q与所有vec_d的相似度 → 按分数排序输出结果
(1)查询预处理:和文档预处理格式一致,单独处理 q
格式为:CLS + q+ SEP
对应例子:CLS Transformer 混 合 精 度 训 练 SEP
(2)查询编码器编码:把预处理后的 q 输入 "查询编码器"
注意:查询编码器和文档编码器是同一个模型(或共享参数),保证 q 和 d 的向量维度一致、语义空间对齐。经过多层编码后,提取最后一层的CLS向量,得到 q 的 "语义向量"(768 维,记为vec_q)。
(3)向量相似度匹配:把vec_q输入向量数据库,快速计算vec_q和所有vec_d的 "相似度分数",这就是 q 和 d 的相关性分数
常用 "余弦相似度"(取值 - 1~1,越接近 1 越相关)或 "点积"(数值越大越相关)。
核心:向量数据库用 "近似最近邻(ANN)" 算法,不用遍历所有文档,毫秒级就能召回 Top-N(比如 Top-100)最相似的文档。
(4)输出排序结果:把召回的 Top-100 文档按相似度分数从高到低排序,呈现给用户(比如分数 0.92 的 d 排在第 1,0.85 的排在第 2,以此类推)。
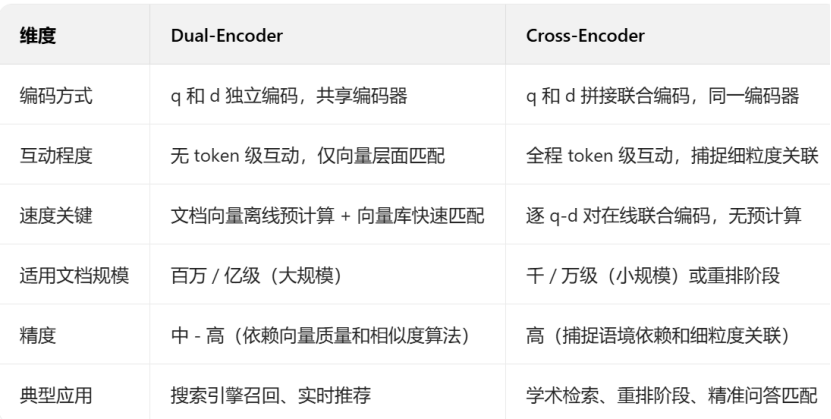
疑问一:为什么Dual-Encoder精度比 Cross-Encoder 低?
没有 "token 级互动":q 和 d 是分开编码的,只能捕捉 "全局语义相似",无法捕捉 "语境依赖的细粒度关联";
疑问二:为什么不用SEP分隔?
因为 q 和 d 是单独编码的,没有拼接,SEP只用来标记序列结束(和 BERT 的单句输入格式一致),核心还是靠CLS向量做全局表示。
2.3.3 对比两种架构:
总结
本周解决了困扰已久的huggingface访问问题,并对整个解决流程进程回忆总结。同时学习了大模型的相关理论知识,下周将加上大模型的相关代码实操。