大模型的"推理能力"能让机器具备与人类相似的认知和行为能力,能像人一样理解、思考、学习并解决复杂问题。而在众多推理能力评测场景中,数学推理任务是当前衡量和追踪模型推理能力进展的 "黄金标尺"。与此同时,主流数学推理评测体系正面临关键瓶颈:部分顶尖模型在常用的数学推理评测任务中,如 AIME24/25 的正确率已突破 90%,评测区分度大幅下降,难以再有效牵引模型向更高阶推理能力进化;此外,现有基准大多源于公开竞赛题库,存在数据穿越风险。

在此背景下,美团 LongCat 团队发布数学推理评测基准------ AMO-Bench 。该评测集共包含 50 道竞赛专家原创试题, 所有题目均对标甚至超越 IMO 竞赛难度。目前,头部大模型在 AMO-Bench 上的最好表现也尚未及格,SOTA 性能仅为 52.4%,绝大多数模型正确率低于 40%。AMO-Bench 既揭示出当前大语言模型在处理复杂推理任务上的局限性,同时也为模型推理能力的进一步提升树立了新的的标杆。
AMO-Bench 的评测榜单将保持更新,欢迎持续关注:
- 项目主页 :amo-bench.github.io/
- Github 地址 :github.com/meituan-lon...
- Hugging Face 地址 :huggingface.co/datasets/me...
一、评测现状:老题库 "失效",行业亟需高难度原创基准
现有数学评测 benchmark 因出现严重的性能饱和问题,已无法有效指引头部大语言模型推理能力的进一步提升。一方面,随着 AIME、HMMT 等竞赛题库的公开,模型有可能通过训练数据 "背诵答案",成绩可信度存疑;另一方面,随着模型的快速迭代升级,现有评测榜单上头部模型的得分趋同,因此逐渐失去鉴别模型能力差异的价值。为进一步提升评测集的难度,已有工作考虑直接使用 IMO 等等有挑战性的竞赛原题对模型进行评测。然而,现有 IMO 题目仍以证明题为主,极度依赖人工批改模型的复杂证明过程,单题批改需 30 分钟以上,评测效率低下且易受主观因素影响。
当前行业迫切需要一套 "高难度 + 原创 + 可自动化" 的评测方案。在这一背景下,AMO-Bench 的推出直击行业痛点------ 50 道竞赛专家原创题目、对标甚至超越 IMO 的试题难度、配套高效高准确率的自动化打分算法,为大模型推理能力评测提供了可落地的新标杆。
二、AMO-Bench:高难度数学推理评测的 "行业新标杆"
AMO-Bench 拥有一套系统化的数据构建逻辑、清晰的数据难度特征与针对性的模型打分算法,为行业提供了一套可信赖且置信的评测方案。
2.1 AMO-Bench 的构建
为打造兼具高质量、强原创性与高挑战性的数据集,LongCat 团队构建了一套 "数据创建 - 质量审查 - 原创性审查 - 难度审查" 全链路流程。
数据创建:专家原创,自带 "解题说明书"
- 题目由具备数学奥林匹克竞赛获奖经历或相关竞赛出题经验的顶尖专家独立设计,每道试题不仅提供最终答案,还详细撰写了 step-by-step 解题路径 ------ 从关键定理应用到逻辑推导节点,每一步都清晰标注,既为后续审查提供依据,也为模型错误分析预留 "参考坐标"。
质量审查:三重盲审,杜绝 "题不对标"
- 每道题需经 3 位以上专家 "盲审"质检,重点核查两大核心:一是题目表述与解题逻辑是否无歧义,避免因题干模糊导致的模型误判;二是所需数学知识是否严格匹配数学奥赛考察的知识范围(如代数、几何、数论等核心领域),确保不超纲、不偏题,真正考验模型的推理能力。
原创性审查:题库匹配 + 人工核验,切断 "数据穿越"
- 采用 "技术核验 + 专家经验" 双重保障:通过 n-gram 文本匹配与互联网检索等方式,与 AIME24/25 等主流竞赛数据集和在线数据库进行比对,排除与现有数据资源中高度相似的题目;同时依靠专家经验进行人工核验,确保与过往竞赛题无高度重合,杜绝模型 "背答案" 的可能。
难度审查:双标筛选,确保 "够硬核"
- 采用双重难度筛选标准来保证每一道题目都具备足够挑战性:首先使用国内外最顶尖模型进行筛选,要求至少 2 款模型在 3 次独立测试中无法全部答对;其次候选题目需要经过第三方专家进行二次审核题目难度,确保题目难度不低于 IMO 标准。
2.2 数据集:覆盖核心领域,推理复杂度显著升级
AMO-Bench 的 50 道题目覆盖数学奥赛核心领域,且从解题复杂度上实现对现有基准的全面超越。
题目分类:覆盖五大核心领域
参照国际数学竞赛官方竞赛大纲,题目被划分为五大类:代数方程与不等式(11 题,占比 22%)、函数与数列(13 题,占比 26%)、几何(5 题,占比 10%)、数论(9 题,占比 18%)、组合数学(12 题,占比 24%),覆盖数学奥赛核心知识点,考察模型在不同领域是否存在能力短板。

解题复杂度:答案长度远超传统基准
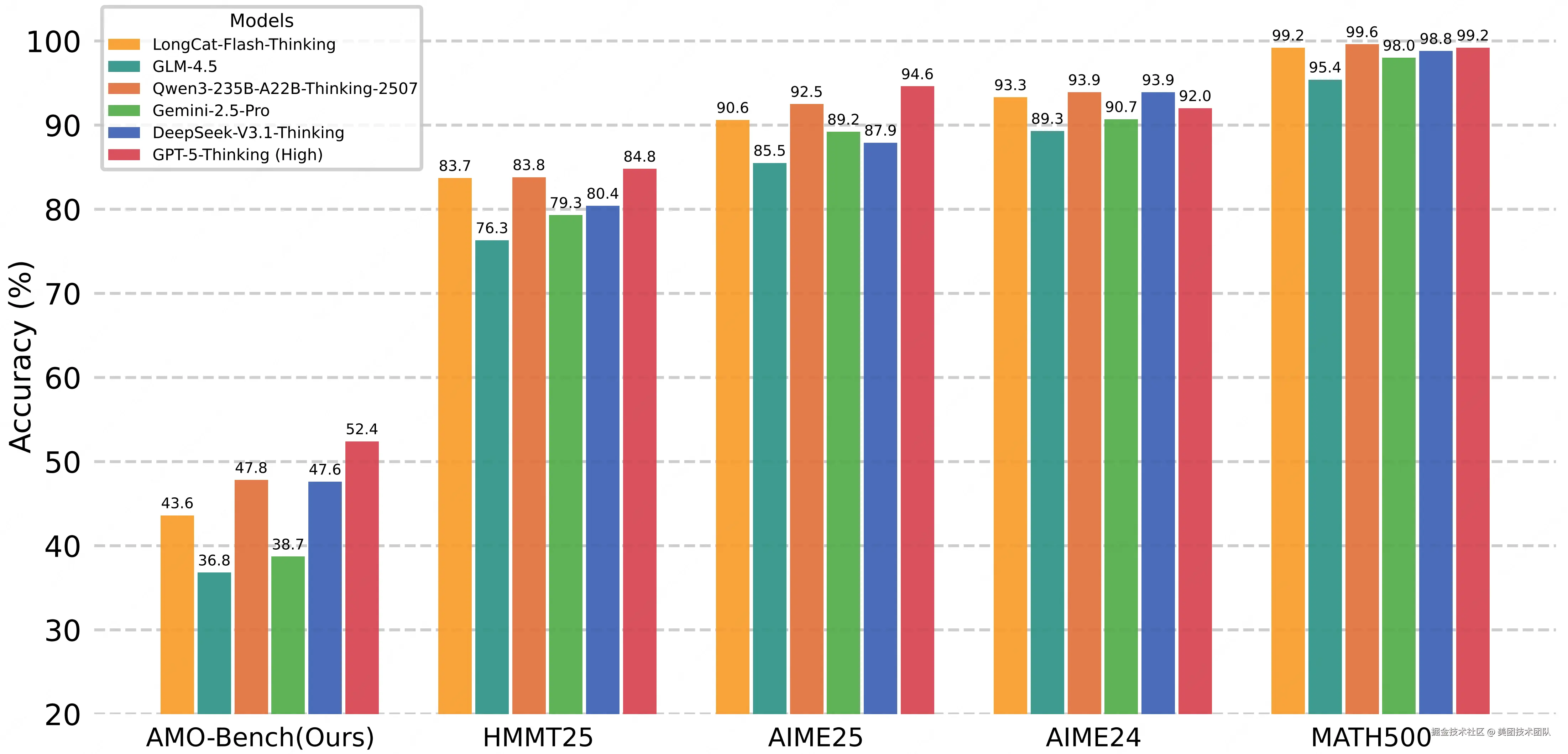
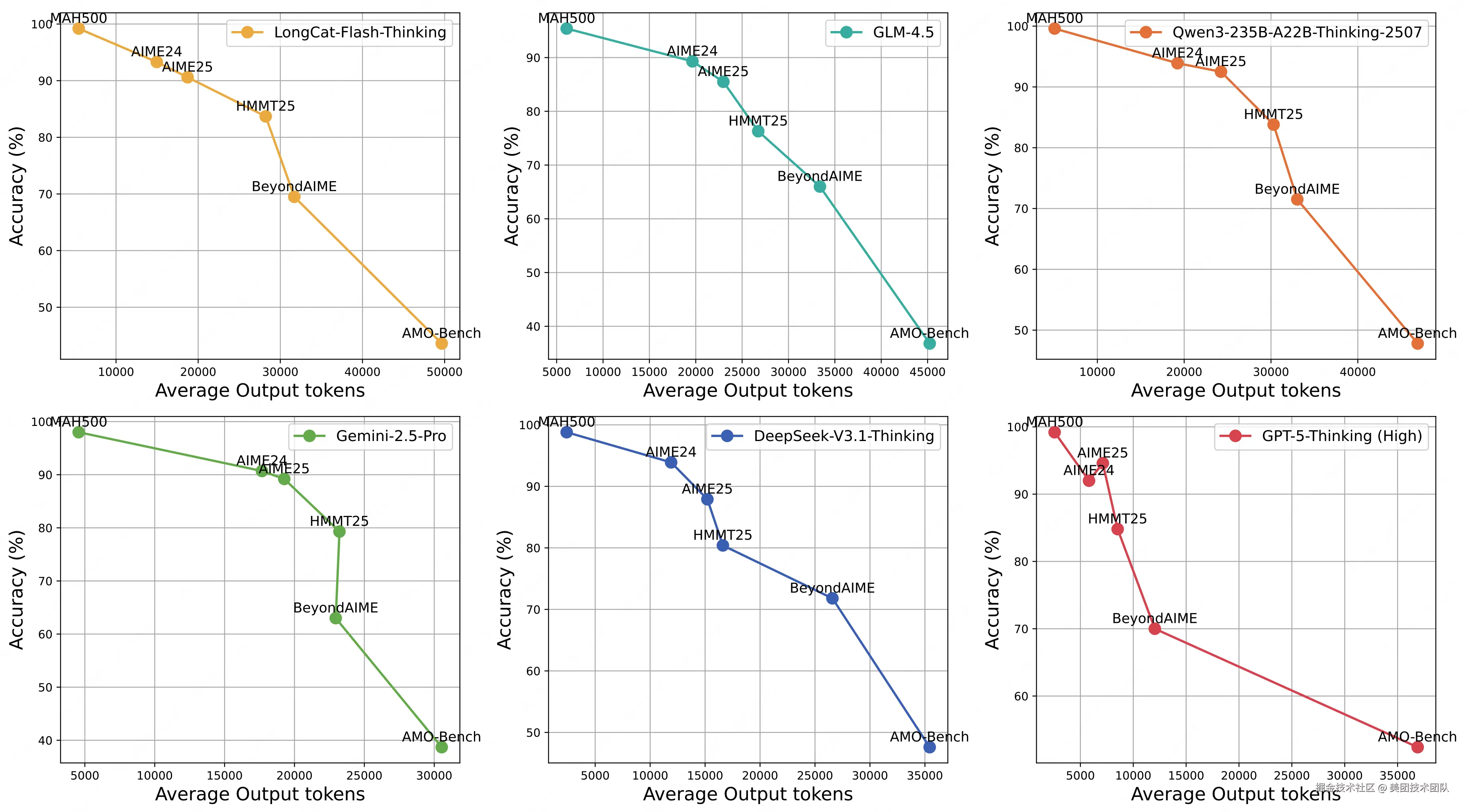
通过对比大模型在 AMO-Bench 和现有数学评测集上的输出长度,可以看到,随着数据集难度的提升,模型表现在逐渐走低的同时,其输出 token 数量也会大幅增加。
大模型在 AMO-Bench 上的解题步骤长度显著长于现有 AIME/HMMT 等评测集,这意味着 AMO-Bench 的题目需要模型构建更长、更复杂的逻辑链才能解答,本质上更具挑战性,能更精准地检验大模型的深度数学推理能力。
2.3 评分方法:兼顾 "自动化" 与 "准确性"
AMO-Bench 的问题答案类型可以概括为四种类型,为兼顾打分准确率和打分效率,我们针对不同的答案类型匹配相应的评分方式:
-
数值 / 集合 / 变量表达式类(39 题):采用 "parser-based 自动评分",要求模型将答案按指定格式(答案)输出,使用 Math-Verify 工具核验模型结果与标准答案的等价性;
-
描述性答案(11 题):采用 "LLM 评分 + Majority Voting",在实验中使用了 o4-mini(Low)为评分模型,对同一答案进行 5 次独立评分采样,取多数结果作为最终得分,以减小打分模型采样的波动性。
为了验证打分方案的准确率,我们随机抽取了 10 款不同模型生成的 1000 组答案打分结果进行人工检查,结果显示 AMO-Bench 的评分方案准确率高达 99.2%,为大规模自动化评测提供了坚实保障。




三、实验与分析:AMO-Bench 揭示大模型数学推理的能力边界
为全面揭示当前大模型数学推理的能力边界,LongCat 团队分别从 "开源 / 闭源"和"推理 / 非推理" 两方面共筛选了 26 个头部大语言模型,真实的反应了当前主流模型在数学推理能力上的实际表现。
3.1 整体能力格局:顶尖模型仍 "不及格",能力梯度差异显著
从核心指标来看,当前大部分大模型在 AMO-Bench 上的表现远未达及格水平,且不同类型模型间呈现明显能力分层:
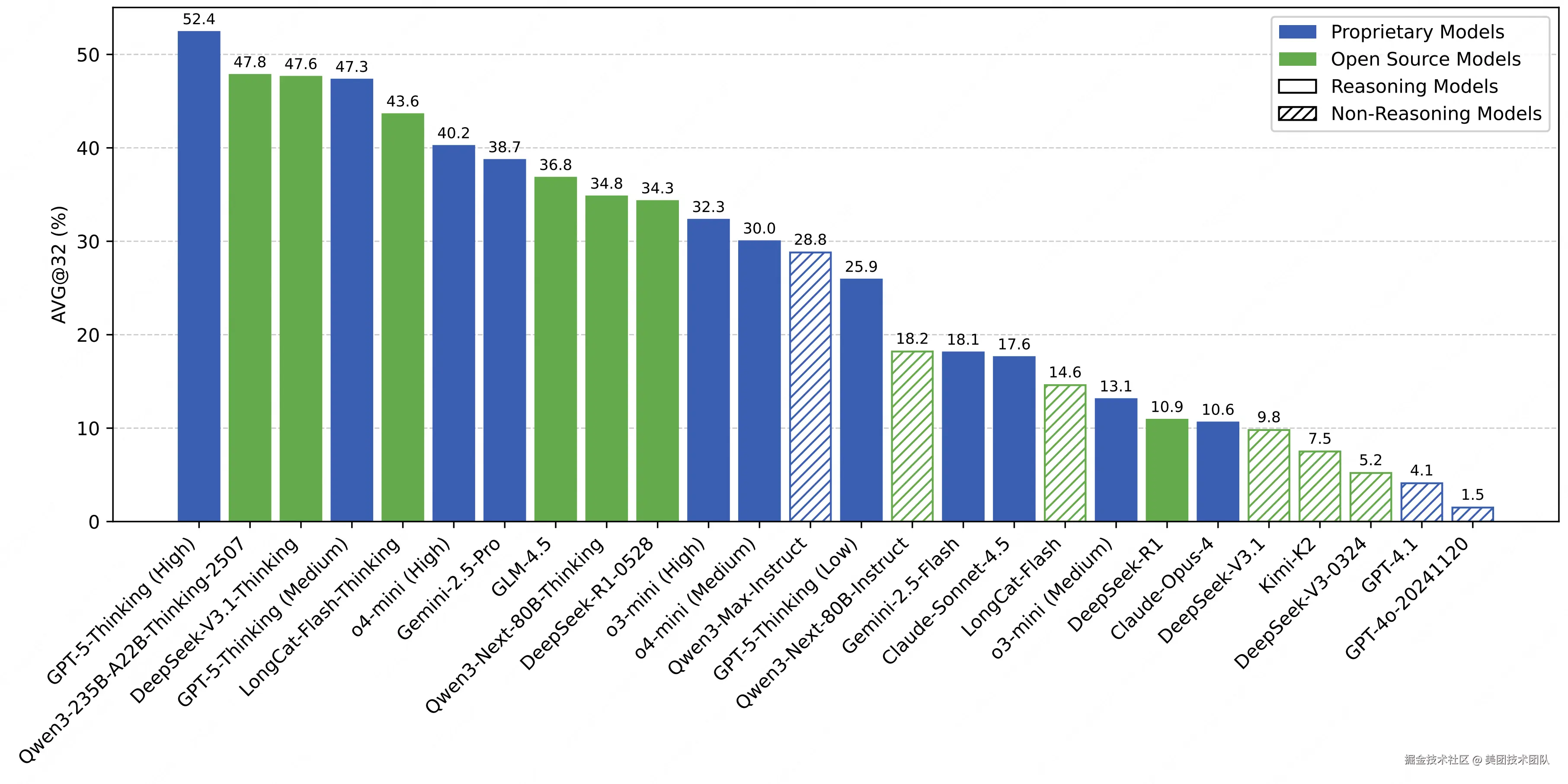
- 闭源推理模型领跑,仍有巨大提升空间:表现最优的 GPT-5-Thinking(High)正确率仅 52.4%,且大部分模型表现低于 40%,即便头部闭源模型,也未突破 "及格线",凸显 IMO 级难度的原创题对当前 AI 的挑战性;
- 开源模型仍有差距,但已在全力追赶:开源模型中 Qwen3-235B-A22B-Thinking-2507 正确率为 47.8%,DeepSeek-V3.1-Thinking 为 47.6%,距离最好表现的 GPT-5 仍有一定差距,但已明显超越 o4-mini 和 Gemini-2.5-Pro,展示出开源模型奋起直追的势头。
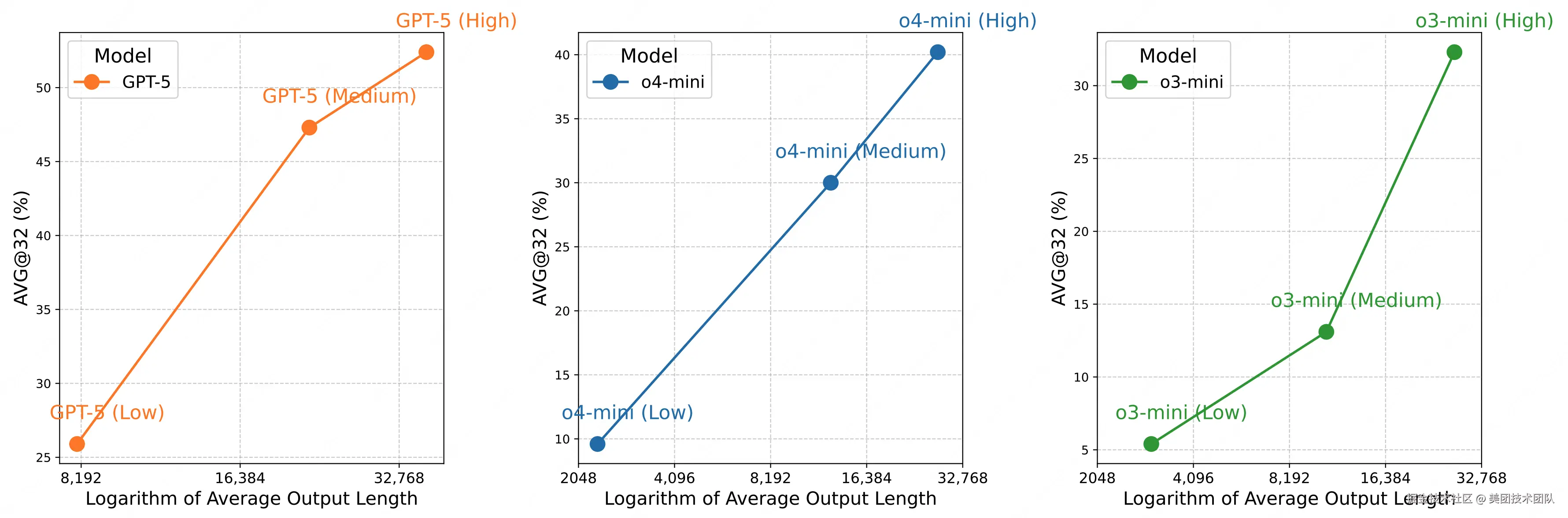
3.2 推理效率关联:Test-Time Scaling 效果显著
通过分析模型在 AMO-Bench 上输出长度与模型表现的关系,LongCat 团队指出,当前 test-time scaling 仍然是提升模型推理表现的有效手段。
- 高得分模型依赖更多 token 输出:AVG@32 超 40% 的模型(如 GPT-5-Thinking、DeepSeek-V3.1-Thinking),平均输出 token 量均超 35K,意味着当前的头部推理模型能通过构建显著更长的逻辑链来达到更好的解题表现。
- 同系列模型迭代体现效率提升:以 o 系列模型为例,o4-mini(High)在相近 token 量下,正确率(40.2%)显著高于 o3-mini(High)(32.3%);DeepSeek-V3.1-Thinking 较前代 DeepSeek-R1-0528,则进一步用更少 token(32K vs 38K)实现了更高正确率(47.6% vs 34.3%),证明新一代模型可以用更高的效率获取更强的推理性能。
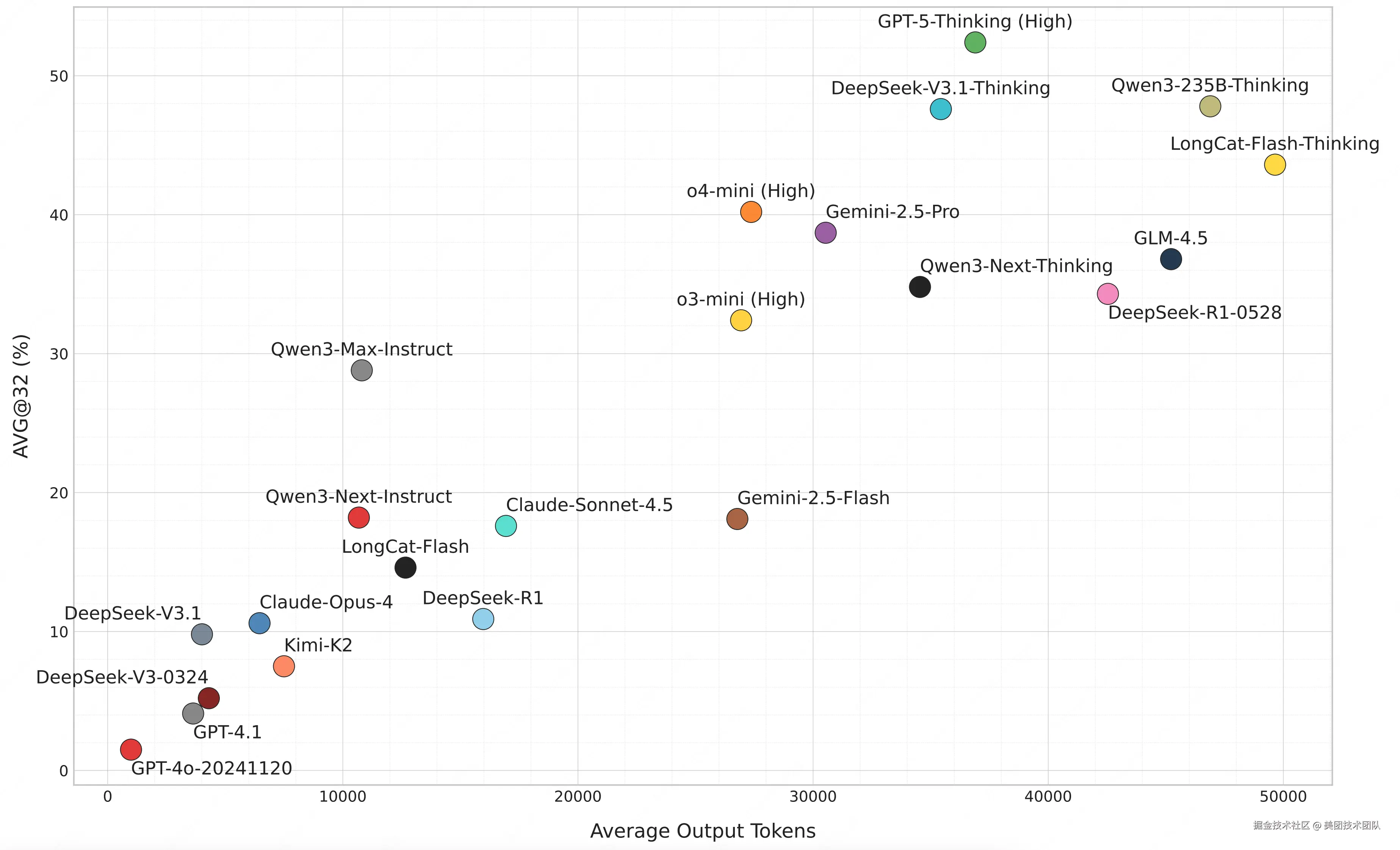
- 推理投入与得分呈对数线性增长:同一模型正确率与输出长度对数呈近线性正相关,且这一趋势与现有工作在 MATH500、AIME24 等基准上的实验观察一致,证明增加推理计算投入仍是提升模型解决复杂任务能力的有效路径。
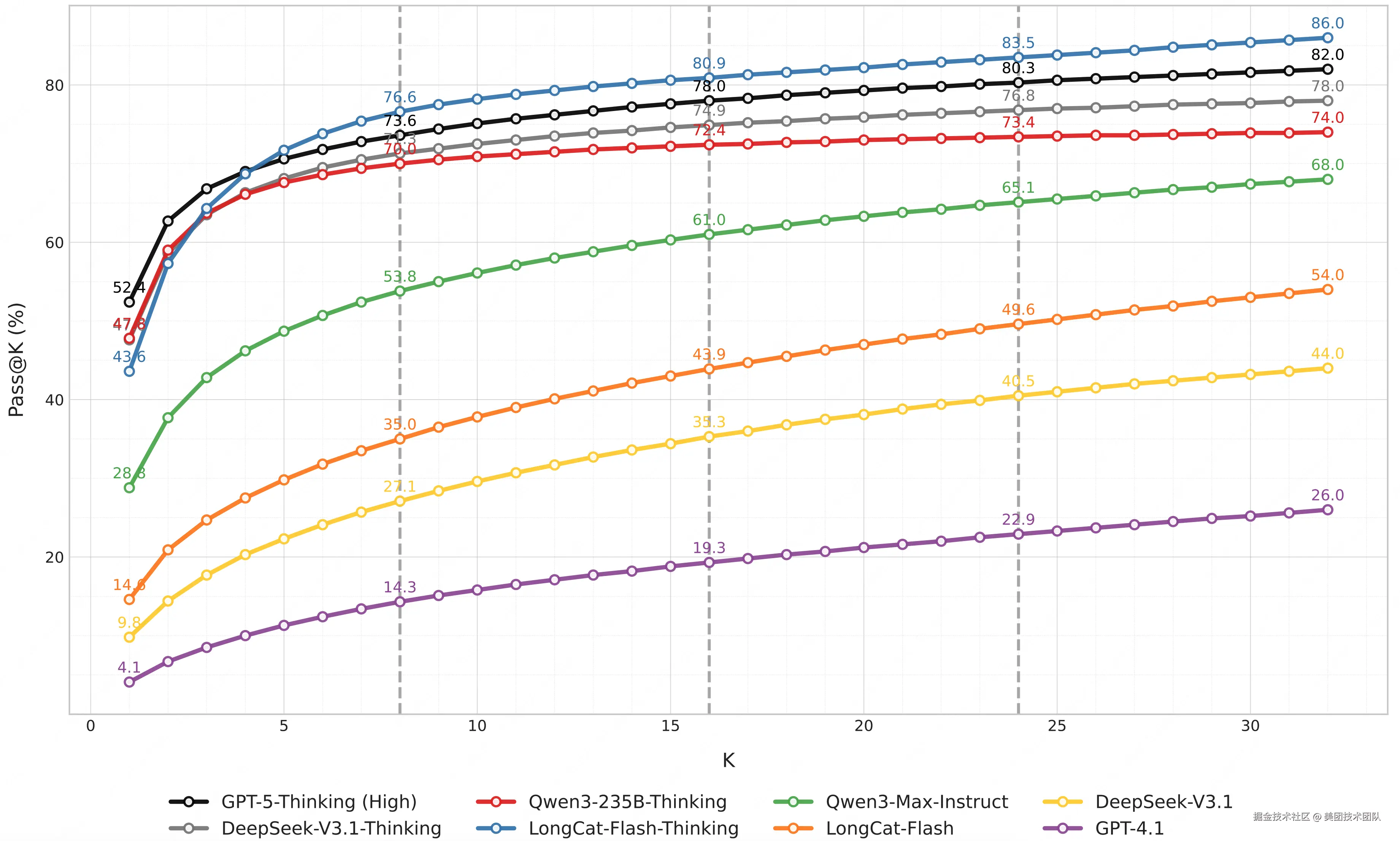
3.3 潜在能力挖掘:模型多次尝试下的探索潜力
通过进一步分析模型的 "Pass@k" 表现(k 次尝试至少答对 1 次),LongCat 团队指出,前沿推理模型如 GPT-5-Thinking(High)、DeepSeek-V3.1-Thinking 等在 AMO-Bench 上能达到 Pass@32 超 70%,表明当前大模型暗含解决难题的潜力,其性能仍有巨大提升空间。
四、总结与展望
综上,AMO-Bench 相比 AIME24/25 等主流数学评测集具备了更好的区分度和模型提升空间,同时通过 IMO 级别的原创题解决了因数据泄露的潜在风险造成的评估失真问题,以及凭借 99.2% 的高打分准确率保证了自动化评测的准确性。未来,美团 LongCat 团队将持续更新 AMO-Bench 评测集,扩大题目覆盖类型与优化评测方案,同时会进一步探索包括通用和学科推理在内的高难度评测集建设,助力业界大模型在推理能力上的持续提升。
阅读更多
| 关注「美团技术团队」微信公众号,在公众号菜单栏对话框回复【2024年货】、【2023年货】、【2022年货】、【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明"内容转载自美团技术团队"。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。