Java Excel 导入导出神器:解决大数据、科学计数法和国际化难题
--- 由于是一个多租户本地化部署的工业系统,随意引入依赖的成本较高,因此需要为现有POI设计一个量身订造的轮子。
痛点复盘:一个"合格"的 Excel 工具类,到底要解决什么?
回顾系统中出现的生产级痛点,我意识到一个合格的企业级 Excel 工具,必须同时解决以下三个核心矛盾:
- 性能与内存矛盾: 如何在导出大量数据时,不让 JVM 堆内存直接爆炸(OOM)?
- 准确性与格式矛盾: 如何保证导入的数字数据(如长 ID、卡号)在 Excel 自动格式化(科学计数法)后,依然能精确还原?
- 扩展性与硬编码矛盾: 如何在多语言项目(i18n)中,优雅地实现表头翻译,而不是写死一堆中文标题?
基石设计:@ExcelField 驱动的极简主义
所有的强大功能都建立在一个干净的、面向对象的映射机制上。我们摒弃了传统的"按列索引硬编码"的方式,采用了基于注解的声明式配置。
java
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ExcelField {
// ...
String titleKey() default ""; // 国际化 Key,这是我们实现 i18n 的入口
int order() default 0; // 控制导出/导入的列顺序,确保稳定
int type() default 3; // 灵活控制字段是导出、导入还是双向
}通过反射和 ConcurrentHashMap 缓存(这也是一个性能优化点,避免高并发下的重复反射开销),我们将 DTO 字段与 Excel 列进行了高效绑定,确保了代码的整洁和执行效率。
核心亮点 I:大数据 OOM 终结者 ------ 流式导出的设计哲学
问题: 传统 XSSFWorkbook 导出一万行数据可能就要占用几十兆内存,十万行直接崩掉。
我的思考与方案: 既然内存顶不住,那就将数据流式写入磁盘。
我们选择了 Apache POI 的 SXSSFWorkbook,它是一个基于 SAX 模式的流式 Excel 写入器。
java
// 使用 SXSSFWorkbook(100),每 100 行数据刷新一次到临时文件
SXSSFWorkbook workbook \= new SXSSFWorkbook(100);
// ...
// 导出完成后,必须进行资源清理,这是流式写入的关键步骤
finally {
workbook.dispose();
}这种设计是处理大数据报表的唯一正确姿势。它牺牲了少许写入速度(因为涉及磁盘 I/O),换来了系统运行时的绝对稳定性。结合代码中的样式复用和 Row/Cell 高度设置,导出的文件既稳定又美观。
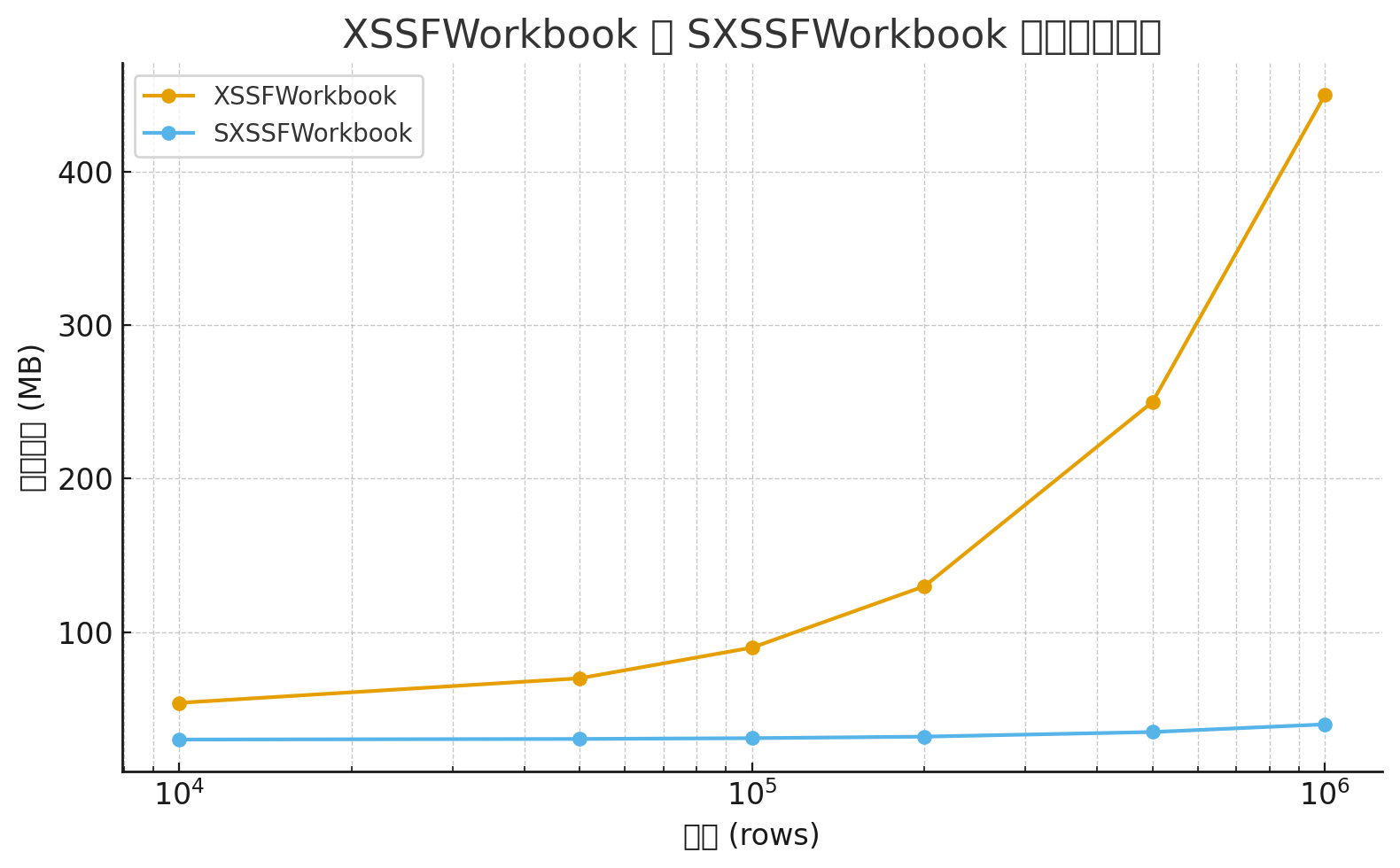
传统XSSFWorkbook与SXSSFWorkbook的内存占用对比图
核心亮点 II:导入数据的"护航舰" ------ 精度丢失的完美修正
问题: 用户在 Excel 中输入的 18位身份证号 或 20位银行卡号,在 POI 读取时,单元格类型被识别为 CELL_TYPE_NUMERIC,但值却是科学计数法。这直接导致业务数据的错误。
我的思考与方案: 不去相信 Excel 默认的数字读取,而是强制以最高精度 和纯字符串形式还原。
我们聚焦于 parseExcelWithDesc 方法中的这段核心逻辑:
java
// \--- 核心优化:鲁棒的科学计数法修正逻辑 (目标String字段) \---
if (field.getType() \== String.class && cellType \== Cell.CELL\_TYPE\_NUMERIC) {
double doubleValue \= cell.getNumericCellValue();
try {
// 关键步骤:使用 BigDecimal 接收 double 值,并用 toPlainString() 彻底消除科学计数法 E
java.math.BigDecimal bd \= new java.math.BigDecimal(String.valueOf(doubleValue));
val \= bd.toPlainString();
// 精细化处理:移除数字末尾可能带有的 .0
if (val.toString().endsWith(".0")) {
val \= val.toString().substring(0, val.toString().length() \- 2);
}
} catch (NumberFormatException e) {
// 容错处理
}
}这不仅是简单的 try-catch,它体现了我们对数据准确性的极致追求:
- BigDecimal 保证精度: 避免了 Java double 类型本身的精度问题。
- toPlainString() 消除科学计数法: 将形如 1.2345E+18 的值还原为原始的长数字字符串。
- .0 修正: 考虑到 Excel 中整数 123 可能会被 POI 读成 123.0,我们进行了后处理,保证最终还原的字符串是干净的整数形式。
这一套组合拳,彻底解决了 Excel 导入中最隐蔽、最致命的精度问题。
核心亮点 III:优雅应对国际化与表头管理
问题: 业务需要支持多语言(例如中英文切换),但我们不可能为每种语言写一套导出代码。
我的思考与方案: 引入间接层------使用 titleKey 替代硬编码标题。
java
@ExcelField(titleKey \= "user.name") 告诉工具类,在导出时,不要直接使用 title,而是去外部传入的 translatedHeaders Map 中,用 user.name 作为 Key 查找翻译后的标题。
// exportExcel 接收的参数
Map\<String, String\> translatedHeaders; // Key=titleKey, Value=翻译后的表头
// ...
String lookupKey \= fieldInfo.annotation.titleKey();
if (translatedHeaders \!= null && translatedHeaders.containsKey(lookupKey)) {
headerTitle \= translatedHeaders.get(lookupKey); // 成功获取翻译标题
} else {
headerTitle \= fieldInfo.annotation.title(); // 否则使用默认标题
}这种设计将 "业务逻辑" (导出数据)与 "展示逻辑"(表头语言)彻底分离,项目只需在业务层负责组装正确的 translatedHeaders Map,工具类就能自动渲染出任何语言的表头。
写在最后:代码即思考,一次面向未来的复盘
为什么我们要造这个轮子?
究其根本,这个 ExcelUtils 并非仅仅是对 POI API 的一层封装,它是我对过去踩过的所有坑、面对的所有紧急故障的一次系统性复盘 。它是一个解决方案的固化,确保我或我的团队未来在处理 Excel 任务时,能够拥有内存稳定、数据精确、配置灵活这三个铁三角保障。
回顾总结,这三个核心设计点构成了这个工具类的灵魂:
- SXSSF: 搞定大数据的稳定性。
- BigDecimal Plain String: 搞定数字的精确性。
- Title Key: 搞定业务的国际化。
下一步思考(TODO List):
目前版本已能满足绝大多数业务场景,但面向未来,仍有可扩展和优化的方向:
- 数据校验前置: 考虑在 setFieldValue 之前,增加自定义注解(如 @ExcelRequired, @ExcelLength)驱动的前置校验机制,将数据清洗的责任也交给工具。
- 模板生成: 增加对下拉列表(Data Validation)的支持,让导出的 Excel 模板本身就具备录入规范,从源头控制数据质量。
- 样式策略化: 将 createHeaderStyle 等硬编码样式改为策略模式,允许外部通过配置接口灵活定制单元格颜色、字体等,以应对更复杂的品牌或财务报表需求。