文章目录
- 摘要
- abstract
- 一、无监督学习
-
- [1.1 推荐系统](#1.1 推荐系统)
- [1.2 协同过滤算法](#1.2 协同过滤算法)
-
- [1.2.1 线性回归](#1.2.1 线性回归)
- [1.2.2 逻辑回归](#1.2.2 逻辑回归)
- [1.3 基于内容推荐](#1.3 基于内容推荐)
- [1.4 基于神经网络的推荐](#1.4 基于神经网络的推荐)
- [1.5 简单对比](#1.5 简单对比)
- [1.6 代码](#1.6 代码)
- 总结
摘要
本周学习无监督学习中的推荐算法,涵盖协同过滤算法、基于内容推荐及神经网络推荐三大技术路径。在协同过滤算法分析了线性回归和逻辑回归,引出基于内容推荐算法,同时关注最新与深度神经网络相关的推荐系统基本内容。
abstract
This week, I studied recommendation algorithms in unsupervised learning, covering three main technical approaches: collaborative filtering algorithms, content-based recommendations, and neural network recommendations. In the collaborative filtering algorithms, I analyzed linear regression and logistic regression, which led to content-based recommendation algorithms, while also focusing on the basic concepts of the latest recommendation systems related to deep neural networks.
一、无监督学习
1.1 推荐系统
在日常中,推荐算法无处不在,是信息过滤系统,用于预测用户对物品的偏好或评分。广泛应用于电子商务、社交媒体、视频流媒体等领域。
举一个例子,用户对电影的喜爱偏好,如果能预测出用户对这个电影时感到满意的,那就可以推荐给用户促进用户消费。
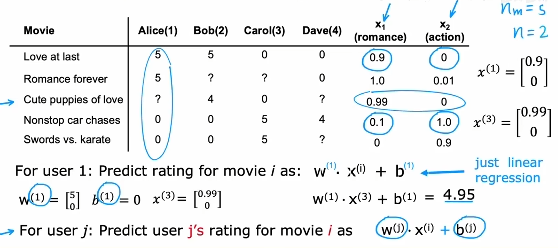
以上述为例子,收集到用户对一些电影的评价,以及对电影进行特征提取,然后根据每一个用户进行一个线性回归算法的神经网络训练与预测。
如果没有电影特征?如何进行训练?
协同过滤。
1.2 协同过滤算法
协同过滤是基于用户行为数据的推荐方法,核心思想是"物以类聚,人以群分"。分为两种:
基于用户的协同过滤:通过找到与目标用户兴趣相似的用户群体,将该群体喜欢的物品推荐给目标用户。
基于物品的协同过滤:通过计算物品之间的相似度,将用户喜欢过的物品相似的物品推荐给用户。
1.2.1 线性回归
在这个算法中,还是以上面电影推荐为例子,现在我们不知道电影的特征,但是有多个人对电影进行了评价,这个时候,根据这个评价我们训练出电影的特征(这里多个用户的w,b是已经训练后的)。然后根据训练出的特征,给其他用户进行推荐。有点绕,像左脚踩右脚。
下面是两个例子的综合:
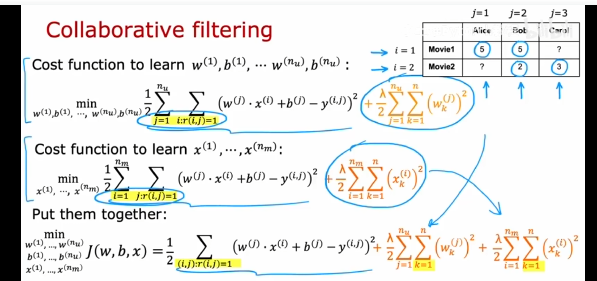
第一个代价函数正则化w,是为训练w,b,就是已知电影特征,训练用户的w,b参数。
第二个代价函数正则化x,是为训练x,就是已知一些用户的w,b参数,训练电影的特征,然后根据特征进行推荐。
第三个代价函数是两个一起,同时进行训练w,b,x,这就是协同过滤算法。同时对三个参数进行梯度下降,最小化代价函数。

1.2.2 逻辑回归
在实际中,可能不只有评分,还有用户的点击,点赞,收藏,讨论等情况,这个时候就包含多个标签,可以使用二进制标签进行说明,0表示看到没参与,1表示看到后参加了互动、点赞...,?表示未知。
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1

像前面线性回归转逻辑回归,使用sigmoid转化成逻辑回归,然后最小化代价函数。
1.3 基于内容推荐
基于内容的推荐:分析物品的内容特征(如文本、标签等)和用户的历史行为,推荐与用户过去喜欢的物品在内容上相似的物品。
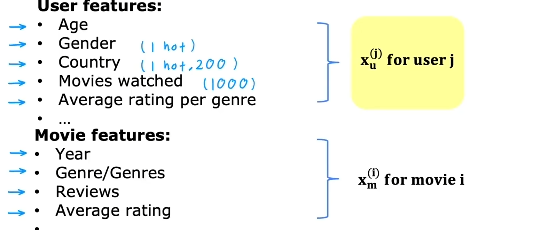
如上图,收集到用户的特征:年龄、国家、看过的电影...,收集到电影(物品)的特征:上映年份、评论、平均打分...,根据这些特征,进行一个预测评价。
这个时候使用两个向量分别表示用户和物品的特征,进行点积计算对物品的预测。
向量从哪来?利用神经网络,对用户和物品的特征进行拟合,生成两个相同大小的向量,如下图输出层为32神经元,表示有32维的向量输出。
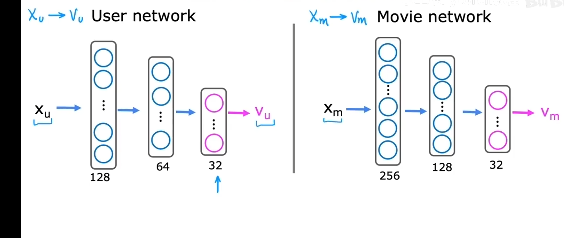
然后进行点积,计算出预测值。
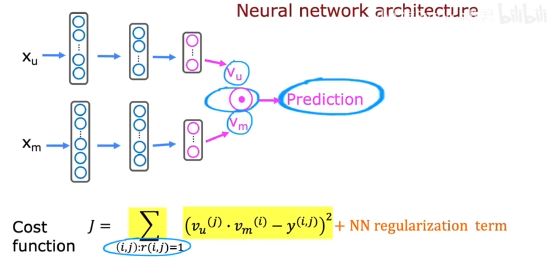
在上图中,代价函数中只选择r(i,j)=1表示有互动或者点赞的行为进行训练。
1.4 基于神经网络的推荐
核心逻辑是通过神经网络自动挖掘数据中的隐含模式,解决传统推荐(如协同过滤、矩阵分解)面临的数据稀疏、特征组合困难、泛化能力弱等问题。本质是从"人工特征工程"到"自动特征学习"的转变。
深度学习推荐的核心突破在于:
自动特征学习:无需人工设计特征(如"用户年龄+性别"),通过神经网络自动挖掘高维特征(如"年轻女性+夏季+连衣裙"的隐含关联);
高阶特征组合:通过多层神经网络(如MLP)学习特征间的非线性关系(如"用户喜欢科幻电影"与"近期观看太空纪录片"的组合);
泛化能力提升:通过学习大量用户行为数据,对未见过的新物品(冷启动)或新用户(冷启动)也能做出合理推荐。
深度学习推荐的效果依赖于数据处理、特征工程、模型训练三大关键技术:
- 数据处理:从"原始日志"到"高质量数据"
数据类型:包括用户行为数据(点击、购买、浏览时长)、用户属性数据(年龄、性别、地域)、物品属性数据(标题、类别、价格)、上下文数据(时间、地点、设备);
数据清洗:去除异常值(如观看时长<1秒的无效点击)、填充缺失值(如未记录年龄的用户赋中位数25岁);
数据划分:将数据分为训练集(70%)、验证集(20%)、测试集(10%),用于模型训练、调参与评估。 - 特征工程:从"原始特征"到"有效特征"
稀疏特征:如用户ID、物品ID,通过Embedding层转换为稠密向量(如128维),捕捉用户的"兴趣偏好";
数值特征:如用户年龄、物品价格,通过归一化(如Min-Max Scaling)或分桶(如将年龄分为"18-25""26-35"等桶)处理,提升模型稳定性;
序列特征:如用户历史行为序列(点击的视频ID列表),通过池化操作(如平均池化)生成用户兴趣向量(如512维),捕捉用户的"长期兴趣"。 - 模型训练:从"随机初始化"到"精准预测"
损失函数:对于点击率预估(CTR)任务,采用对数损失函数(Log Loss):
L o g L o s s = 1 N ∑ i = 1 N y i l o g ( p i ) + ( 1 − y i ) l o g h ( 1 − p i ) Log Loss=\frac{1}{N}\sum_{i=1}^Ny_ilog(p_i)+(1-y_i)logh(1-p_i) LogLoss=N1∑i=1Nyilog(pi)+(1−yi)logh(1−pi), y i y_i yi是真实标签(1表示点击,0表示未点击), p i p_i pi是模型输出的点击概率;
优化器:采用Adam或SGD(随机梯度下降)优化器,调整模型参数(如Embedding向量、MLP权重),最小化损失函数;
评估指标:采用AUC(Area Under Curve)(衡量模型区分正负样本的能力)、NDCG@10(衡量推荐列表的精准性,10表示前10个推荐)等指标,评估模型效果。
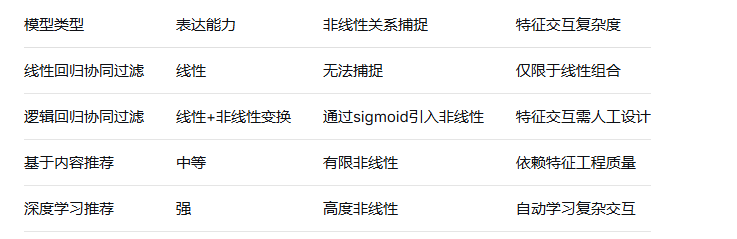
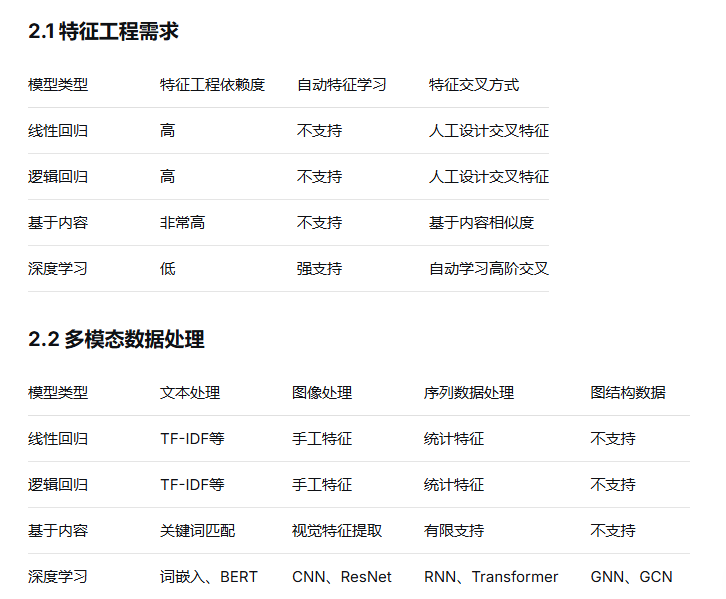
1.5 简单对比
深度学习推荐模型与基于内容推荐以及与传统基于线性回归、逻辑回归协同过滤算法的对比:
1.6 代码
协同过滤以及基于内容推荐(传统算法):
j
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('Agg') # 避免GUI后端问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 支持中文显示
plt.rcParams['axes.unicode_minus'] = False
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.decomposition import TruncatedSVD
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
class ContentBasedRecommender:
def __init__(self):
self.tfidf = TfidfVectorizer(stop_words='english')
self.items = None
self.item_features = None
self.tfidf_matrix = None
self.cosine_sim = None
def fit(self, items, item_features):
"""训练基于内容的推荐模型"""
self.items = items
self.item_features = item_features
# 创建TF-IDF矩阵
self.tfidf_matrix = self.tfidf.fit_transform(item_features)
# 计算物品相似度
self.cosine_sim = linear_kernel(self.tfidf_matrix, self.tfidf_matrix)
def recommend(self, item_idx, n_recommendations=10):
"""基于内容相似度推荐"""
sim_scores = list(enumerate(self.cosine_sim[item_idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 获取最相似的物品(排除自己)
sim_scores = sim_scores[1:n_recommendations + 1]
item_indices = [i[0] for i in sim_scores]
return [(self.items[i], float(sim_scores[j][1]))
for j, i in enumerate(item_indices)]
class CollaborativeFiltering:
def __init__(self, method='user_based', n_factors=50):
self.method = method
self.n_factors = n_factors
self.global_mean = None
def fit(self, user_item_matrix):
"""训练模型"""
self.user_item_matrix = user_item_matrix.values
self.users = user_item_matrix.index.tolist()
self.items = user_item_matrix.columns.tolist()
# 计算全局平均分
self.global_mean = np.mean(self.user_item_matrix[self.user_item_matrix > 0])
if self.method == 'user_based':
# 用户相似度矩阵
self.similarity = cosine_similarity(self.user_item_matrix)
elif self.method == 'item_based':
# 物品相似度矩阵
self.similarity = cosine_similarity(self.user_item_matrix.T)
elif self.method == 'matrix_factorization':
# 矩阵分解
self.svd = TruncatedSVD(n_components=self.n_factors, random_state=42)
self.user_factors = self.svd.fit_transform(self.user_item_matrix)
self.item_factors = self.svd.components_.T
def predict(self, user_idx, item_idx):
"""预测评分"""
if self.method == 'user_based':
return self._user_based_predict(user_idx, item_idx)
elif self.method == 'item_based':
return self._item_based_predict(user_idx, item_idx)
elif self.method == 'matrix_factorization':
return self._mf_predict(user_idx, item_idx)
def _user_based_predict(self, user_idx, item_idx):
"""基于用户的预测"""
user_ratings = self.user_item_matrix[:, item_idx]
user_similarity = self.similarity[user_idx]
# 找到对目标物品有评分的用户
rated_users = np.where(user_ratings > 0)[0]
if len(rated_users) == 0:
return self.global_mean
similarities = user_similarity[rated_users]
ratings = user_ratings[rated_users]
# 加权平均
weights = np.abs(similarities)
if np.sum(weights) == 0:
return np.mean(ratings)
return np.dot(similarities, ratings) / np.sum(weights)
def _item_based_predict(self, user_idx, item_idx):
"""基于物品的预测"""
item_ratings = self.user_item_matrix[user_idx]
item_similarity = self.similarity[item_idx]
# 找到用户评分过的物品
rated_items = np.where(item_ratings > 0)[0]
if len(rated_items) == 0:
return self.global_mean
similarities = item_similarity[rated_items]
ratings = item_ratings[rated_items]
weights = np.abs(similarities)
if np.sum(weights) == 0:
return np.mean(ratings)
return np.dot(similarities, ratings) / np.sum(weights)
def _mf_predict(self, user_idx, item_idx):
"""矩阵分解预测"""
# 处理缺失值情况
if self.user_item_matrix[user_idx, item_idx] == 0:
return self.global_mean
return np.dot(self.user_factors[user_idx], self.item_factors[item_idx])
def recommend(self, user_idx, n_recommendations=10):
"""为用户生成推荐"""
user_ratings = self.user_item_matrix[user_idx]
unrated_items = np.where(user_ratings == 0)[0]
predictions = []
for item_idx in unrated_items:
pred = self.predict(user_idx, item_idx)
predictions.append((item_idx, pred))
# 按预测评分排序
predictions.sort(key=lambda x: x[1], reverse=True)
return predictions[:n_recommendations]
class CompleteRecommenderSystem:
def __init__(self):
self.cf_model = None
self.content_model = None
self.hybrid_alpha = 0.7 # 协同过滤权重
self.ratings_df = None
self.user_item_matrix = None
self.users = None
self.items = None
self.item_features = None
def load_and_preprocess_data(self):
"""加载和预处理数据"""
np.random.seed(42)
n_users = 100
n_items = 50
# 创建用户-物品评分矩阵 (1-5分)
self.user_item_matrix = np.random.randint(1, 6, size=(n_users, n_items)).astype(float)
# 模拟20%的缺失值(用0表示)
mask = np.random.random((n_users, n_items)) < 0.2
self.user_item_matrix[mask] = 0
# 创建多样化的物品内容特征
self.item_features = [
'action adventure sci-fi future technology',
'comedy romance laugh love relationship',
'thriller horror mystery suspense dark',
'documentary biography history real story',
'animation family fantasy magic children',
'crime drama police detective investigation',
'romance comedy dating couple heartwarming',
'sci-fi action space alien galaxy',
'horror thriller ghost supernatural scary',
'drama romance life struggle emotional',
'western cowboy desert gunfight frontier',
'musical dance song performance stage',
'war battle soldier military historical',
'fantasy magic dragon kingdom quest',
'sports competition athlete training victory',
'superhero comic book power villain',
'noir detective shadow city crime',
'road trip journey adventure discovery',
'disaster survival nature catastrophe',
'coming-of-age youth school growing up',
'martial arts fight discipline master',
'vampire romance gothic immortal night',
'space opera epic interstellar empire',
'detective mystery clue puzzle solve',
'family comedy parenting children funny',
'historical epic ancient civilization war',
'psychological mind game perception reality',
'zombie apocalypse survival horror',
'cyberpunk dystopia high tech low life',
'post-apocalyptic wasteland rebuild society',
'slice of life daily routine ordinary',
'heist robbery plan strategy execution',
'supernatural ghost spirit paranormal',
'college campus friendship study party',
'spy secret agent mission international',
'time travel past future paradox change',
'cooking food recipe chef restaurant',
'environmental climate change wildlife',
'military combat strategy weapon equipment',
'teen high school friendship first love',
'gothic horror castle dark forest legend',
'adventure jungle treasure map explore',
'true crime investigative journalism',
'dystopian government control rebellion',
'kung fu martial arts tournament champion',
'ghost story haunted house spirit',
'sailor sea adventure pirate treasure',
'medical hospital doctor patient emergency',
'legal court lawyer judge jury trial',
'political intrigue government conspiracy'
]
self.users = [f'user_{i}' for i in range(n_users)]
self.items = [f'item_{i}' for i in range(n_items)]
# 转换为DataFrame
self.ratings_df = pd.DataFrame(
self.user_item_matrix,
index=self.users,
columns=self.items
)
def train_models(self):
"""训练所有模型"""
# 训练协同过滤模型
self.cf_model = CollaborativeFiltering(method='matrix_factorization', n_factors=10)
self.cf_model.fit(self.ratings_df)
# 训练基于内容的模型
self.content_model = ContentBasedRecommender()
self.content_model.fit(self.items, self.item_features)
def evaluate_model(self):
"""评估模型性能"""
# 创建测试集 (20%的已知评分)
known_mask = self.user_item_matrix > 0
known_indices = np.argwhere(known_mask)
n_test = int(len(known_indices) * 0.2)
test_indices = known_indices[np.random.choice(len(known_indices), n_test, replace=False)]
test_users, test_items = test_indices[:, 0], test_indices[:, 1]
true_ratings = self.user_item_matrix[test_users, test_items]
# 预测
cf_predictions = []
for u, i in zip(test_users, test_items):
cf_predictions.append(self.cf_model.predict(u, i))
cf_predictions = np.array(cf_predictions)
# 计算指标
mse = mean_squared_error(true_ratings, cf_predictions)
mae = mean_absolute_error(true_ratings, cf_predictions)
print(f"协同过滤模型评估:")
print(f"MSE: {mse:.4f}")
print(f"MAE: {mae:.4f}")
return mse, mae
def hybrid_recommend(self, user_idx, n_recommendations=10):
"""混合推荐"""
# 获取协同过滤推荐
cf_rec = self.cf_model.recommend(user_idx, n_recommendations * 2)
# 获取用户评分最高的物品
user_ratings = self.user_item_matrix[user_idx]
rated_items = np.where(user_ratings > 0)[0]
if len(rated_items) > 0:
# 找到评分最高的物品
best_rated_item_idx = rated_items[np.argmax(user_ratings[rated_items])]
# 获取基于内容的推荐
content_rec = self.content_model.recommend(best_rated_item_idx, n_recommendations * 2)
# 合并推荐结果
hybrid_scores = {}
# 添加协同过滤推荐 (归一化到0-1范围)
max_cf = max([score for _, score in cf_rec], default=1) or 1
for item_idx, cf_score in cf_rec:
item_name = self.items[item_idx]
norm_score = (cf_score - 1) / 4 # 将1-5分映射到0-1
hybrid_scores[item_name] = norm_score * self.hybrid_alpha
# 添加基于内容的推荐 (相似度已经是0-1范围)
for item_name, content_score in content_rec:
if item_name in hybrid_scores:
hybrid_scores[item_name] += content_score * (1 - self.hybrid_alpha)
else:
hybrid_scores[item_name] = content_score * (1 - self.hybrid_alpha)
# 排序并返回top N
final_recommendations = sorted(
hybrid_scores.items(),
key=lambda x: x[1],
reverse=True
)[:n_recommendations]
return final_recommendations
else:
# 新用户,返回热门推荐
return self.get_popular_items(n_recommendations)
def get_popular_items(self, n_recommendations=10):
"""获取热门物品"""
item_popularity = np.sum(self.user_item_matrix > 0, axis=0)
popular_indices = np.argsort(item_popularity)[::-1][:n_recommendations]
return [(self.items[i], float(item_popularity[i])) for i in popular_indices]
def visualize_recommendations(self, user_idx):
"""可视化推荐结果"""
# 获取各种推荐结果
cf_rec = self.cf_model.recommend(user_idx, 5)
hybrid_rec = self.hybrid_recommend(user_idx, 5)
popular_rec = self.get_popular_items(5)
# 准备数据用于可视化
methods = ['协同过滤', '混合推荐', '热门推荐']
recommendations = [cf_rec, hybrid_rec, popular_rec]
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for i, (method, recs) in enumerate(zip(methods, recommendations)):
# 处理不同推荐格式
if method == '协同过滤':
items = [self.items[idx] for idx, _ in recs]
scores = [float(score) for _, score in recs]
else:
items = [item for item, _ in recs]
scores = [float(score) for _, score in recs]
axes[i].barh(items, scores, color=['skyblue', 'lightgreen', 'salmon'][i])
axes[i].set_title(f'{method}推荐')
axes[i].set_xlabel('推荐分数')
axes[i].set_xlim(0, max(scores) * 1.2 if scores else 1)
plt.tight_layout()
plt.savefig('recommendations.png')
plt.close()
# 使用示例
def main():
# 创建推荐系统实例
recommender = CompleteRecommenderSystem()
# 加载数据
recommender.load_and_preprocess_data()
# 训练模型
recommender.train_models()
# 评估模型
recommender.evaluate_model()
# 为特定用户生成推荐
user_idx = 0
print(f"\n为用户 {recommender.users[user_idx]} 的推荐:")
# 混合推荐
hybrid_recommendations = recommender.hybrid_recommend(user_idx, 5)
print("混合推荐结果:")
for item, score in hybrid_recommendations:
print(f" {item}: {score:.4f}")
# 可视化
recommender.visualize_recommendations(user_idx)
print("\n推荐结果可视化已保存为 recommendations.png")
if __name__ == "__main__":
main()总结
传统推荐方法依赖人工特征设计,不能很好适应现如今的AI赋能;深度学习模型会通过自动特征学习和端到端训练,提升复杂模式挖掘能力。计划下周完成神经网络模型实践。