将MySQL中的数据通过Canal同步到Redis,是一种比较常见的数据库与缓存间增量数据同步 的方案,核心思路是利用Canal解析MySQL的binlog,捕获数据变更,然后更新到Redis 。这样做的好处是对业务代码侵入小,能较好地保证数据一致性。
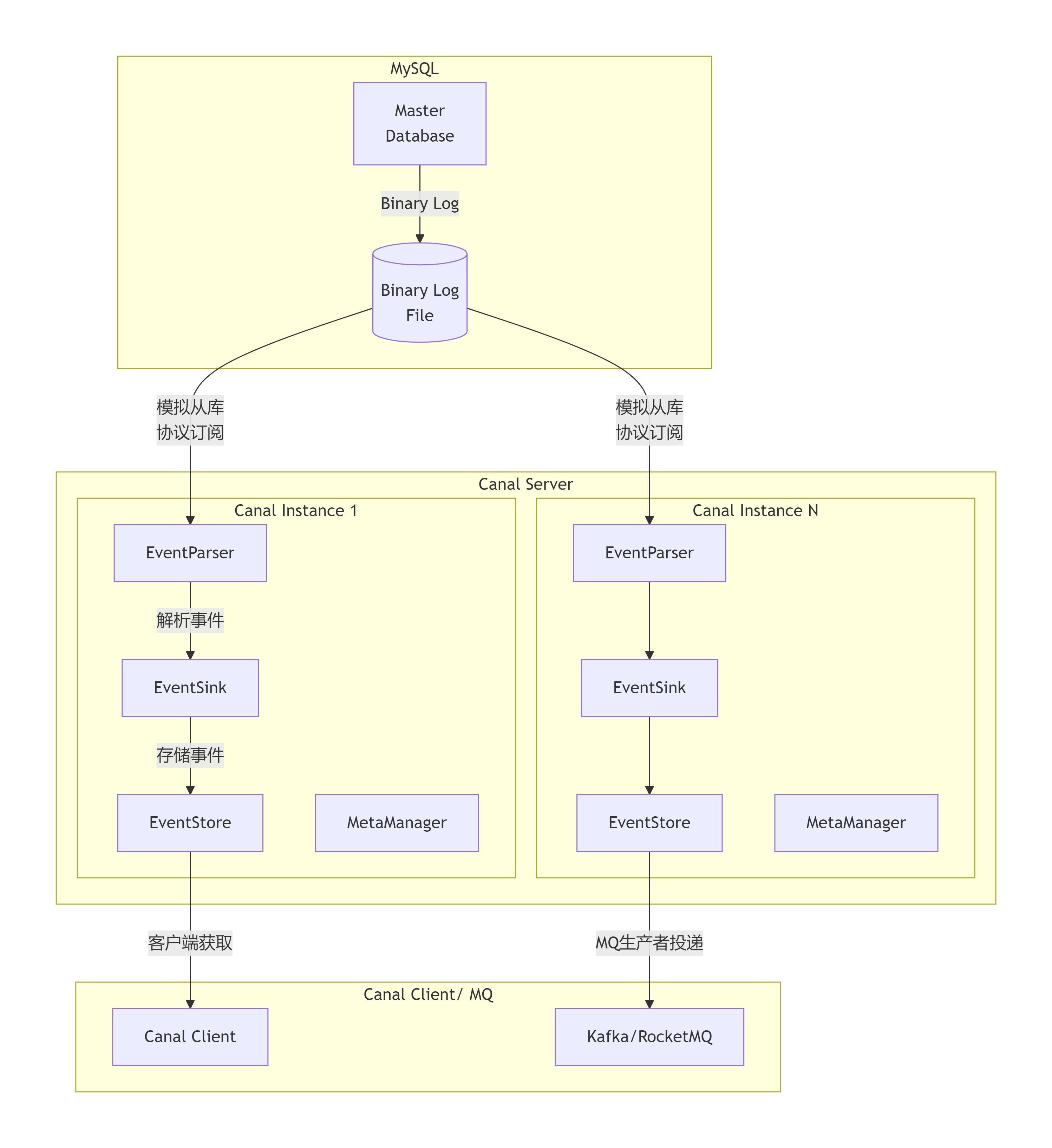
核心工作原理
Canal工作的核心是伪装成MySQL的从库(Slave)。
-
模拟从库交互 :Canal启动后,会模拟MySQL从库的行为,向MySQL主库(Master)发送一个
dump请求。 -
主库推送Binlog :MySQL主库接收到
dump请求后,会将自己的二进制日志(Binary Log)推送给Canal。 -
解析与转发:Canal接收到原始的二进制日志流后,会对其进行解析,转换成易于处理的对象,然后传递给下游模块进行存储和消费。
这个过程使得Canal能够实时 捕获数据库的变更(如INSERT、UPDATE、DELETE),从而实现数据的增量订阅与消费。
为了让你能快速把握核心流程,这里用一个表格来汇总主要步骤和关键点:
| 步骤 | 关键动作 | 说明/注意事项 |
|---|---|---|
| 1. 环境准备 | 开启MySQL Binlog | 必须设置为ROW模式 ,并配置server_id。 |
| 创建Canal数据库用户 | 授予SELECT, REPLICATION SLAVE, REPLICATION CLIENT权限。 |
|
| 准备Redis | 确保Canal服务器可访问Redis。 | |
| 2. 安装配置Canal | 部署Canal Server | 可从官方GitHub仓库下载发布版。 |
修改canal.properties |
配置Canal服务模式,例如指定使用tcp模式或者与RabbitMQ 、Kafka等消息队列集成。 |
|
修改instance.properties |
配置数据库连接信息(地址、用户名、密码等)和binlog订阅规则。 | |
| 3. 开发数据处理逻辑 | 接收并解析binlog | 使用Canal客户端或通过消息队列消费者(如监听Kafka)获取数据变更。 |
| 设计Redis数据格式 | 决定数据在Redis中的存储格式(如String、Hash等)。 | |
| 写入Redis | 根据解析出的数据操作类型(增、删、改),执行相应的Redis写入或删除命令。 | |
| 4. 启动与验证 | 启动Canel及客户端 | 先启动Canal Server,再启动你的客户端程序。 |
| 测试数据变更 | 在MySQL中执行增、删、改操作,观察Redis中数据是否按预期变化。 |
🔧 操作细节与要点
1. 环境准备:配置MySQL
-
mysqld log-bin=mysql-bin # 开启binlog binlog-format=ROW # 选择ROW模式citation:4 server_id=1 # 配置一个唯一的server_id
-
创建Canal用户并授权:在MySQL中执行以下命令:
CREATE USER 'canal'@'%' IDENTIFIED BY 'your_password'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; FLUSH PRIVILEGES;
2. Canal安装与配置
-
下载与解压:从Canal的GitHub Release页面下载所需版本的安装包,然后解压到目标目录。
Canal服务端口
canal.port = 11111
# 服务模式,如tcp, kafka, RocketMQ等[citation:6]
canal.serverMode = tcp
# 目的地集合,对应instance配置的文件夹名
canal.destinations = example 主库地址
canal.instance.master.address = 127.0.0.1:3306
# 数据库用户名
canal.instance.dbUsername = canal
# 数据库密码
canal.instance.dbPassword = your_canal_password
# 要监听的表,支持正则表达式
canal.instance.filter.regex = .*\\..*3. 开发数据处理逻辑
Canal客户端示例(Java伪代码)展示了如何处理binlog并操作Redis:
java代码:
// Canal客户端监听Binlog(伪代码)
CanalConnector connector = CanalConnectors.newClusterConnector("127.0.0.1:2181", "example", "", "");
connector.connect();
connector.subscribe(".*\\..*");
while (true) {
Message message = connector.getWithoutAck(100);
for (CanalEntry.Entry entry : message.getEntries()) {
if (entry.getEntryType() == CanalEntry.EntryType.ROWDATA) {
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()) {
String tableName = entry.getHeader().getTableName();
// 根据表名和主键构造Redis Key,这里假设第一列为主键
String key = "cache:" + tableName + ":" + rowData.getBeforeColumns(0).getValue();
if (rowChange.getEventType() == CanalEntry.EventType.DELETE) {
redis.del(key); // 删除缓存[citation:6]
} else {
// 更新缓存:这里可以将rowData的AfterColumns序列化后存储
redis.set(key, serialize(rowData.getAfterColumnsList())); // 更新缓存[citation:6]
}
}
}
}
}4. 启动与验证
d /your/target/directory/bin
sh startup.sh-
验证:
-
检查Canal服务日志
logs/canal/canal.log,查看服务是否正常启动。 -
检查实例日志
logs/example/example.log,查看实例运行状态和是否有数据同步。 -
在MySQL中执行INSERT、UPDATE、DELETE操作,观察Redis中对应的key是否按预期变化。
-
⚠️ 常见问题与技巧
-
数据格式设计 :同步到Redis时,需合理设计Key和Value。Key通常包含表名和主键-6。Value可使用String存储JSON序列化后的整行数据,或用Hash存储字段和值的映射。
-
幂等性处理:在网络不稳定或客户端重启的情况下,可能会收到重复的binlog消息。确保数据同步逻辑具有幂等性。
-
处理DDL语句:Canal可以解析DDL(如ALTER TABLE)。如果表结构变更影响Redis中的数据格式,客户端需能处理或触发缓存重建。
-
性能考量 :直接通过Canal TCP客户端同步,在高并发下可能成为瓶颈。此时可引入消息队列(如Kafka、RocketMQ) 解耦-6,Canal将变更事件发送到MQ,由消费者异步处理并更新Redis。
-
使用现成平台 :除了自建Canal集群,也可考虑使用CloudCanal 这类数据平台,它提供了图形化界面,简化了MySQL到Redis同步链路的创建和管理-1。
💎 总结
利用Canal同步MySQL数据到Redis,关键在于正确配置MySQL的Binlog,合理部署和配置Canal,并编写可靠的数据处理和Redis写入逻辑。引入消息队列可以提升整体的可靠性和扩展性。同时,务必注意数据格式的设计和幂等性处理。